Table of contents
One of the most important breakthroughs in large language models in 2025 has been the rise of reasoning models. These are models that colloquially, have learned how to think before they speak.
What is a reasoning model?
A reasoning model is the same as a normal LLM, except in addition to producing output tokens, these models are also trained to produce thinking tokens, or reasoning tokens. In the thinking phase, the model tries to reason through complex tasks, trying different approaches and questioning itself before giving an answer. In practice, these models excel at problem solving, particularly in the domains of math and coding, and punch well above their weight in benchmark scores.
How do reasoning models work?
Reasoning models perform what is called a "chain of thought" before speaking. Here is an example of what that looks like, from Deepseek-R1, the only reasoning model currently that exposes the model's "thoughts" publicly.
 Deepseek R1 chain of thought example
Deepseek R1 chain of thought example
In this example, Deepseek thinks about what the user wants before it decides to start spitting out tokens, making it more effective at logically organizing and thinking through what the best possible output might be.
What are the most common reasoning models?
Several providers have developed reasoning models that have achieved state-of-the-art performance.
OpenAI
OpenAI's reasoning model series is called the O-series. The current available models are o1, o1-mini, o3, o3-pro, and o4-mini. o3-pro is the most capable of these models.
Anthropic
Anthropic has added reasoning capabilities to the latest versions of Claude. Claude 4 Opus and Claude 4 Sonnet both have an "extended thinking" mode that allows them to reason before they answer.
Gemini
Google's Gemini 2.5 model series now uses an internal thinking process, and are reasoning models as well. Gemini 2.5 Pro, Gemini 2.5 Flash, and Gemini 2.5 Flash-Lite all have thinking capabilities.
Deepseek
Deepseek R1 was the first open-source reasoning model and was released by the Chinese company Deepseek. Unlike the other commercial closed-source models, in Deepseek, you can actually see the model's thoughts in addition to the final output.
Qwen
Additionally, another Chinese company, Qwen, has released a thinking model called Qwen-QWQ-32B. It is a smaller reasoning model that can be deployed in a wider variety of contexts than Deepseek R1.
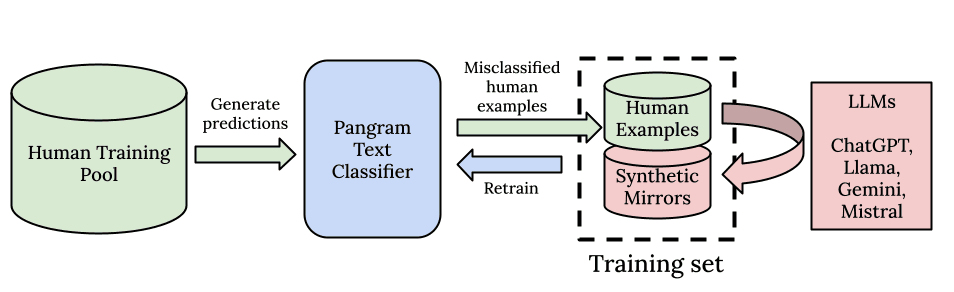
How does Pangram perform on these reasoning models?
We recently released an update to Pangram’s AI detection model that improves performance on reasoning models across the board.
| Model | Pangram (old) | Pangram (July release) |
|---|---|---|
| OpenAI o1 | 99.86% | 100% |
| OpenAI o1-mini | 100% | 100% |
| OpenAI o3 | 93.4% | 99.86% |
| OpenAI o3-pro | 93.9% | 99.97% |
| OpenAI o3-mini | 100% | 100% |
| OpenAI o4-mini | 99.64% | 99.91% |
| Gemini 2.5 Pro Thinking | 99.72% | 99.91% |
| Claude Opus 4 | 99.89% | 99.94% |
| Claude Sonnet 4 | 99.89% | 99.91% |
| Deepseek-R1 | 100% | 100% |
| Qwen-QWQ-32b | 100% | 100% |
The strongest performance improvement comes on o3 and o3-pro. We realized that o3 and o3-pro are quite different models from OpenAI's previously released models, and our old AI detection model was not able to generalize as well against them, performing at only 93% recall when we first tested it.
Solving o3 and o3-pro
Another problem that we faced is that o3 and o3-pro are significantly more expensive than their predecessors, meaning that we would not be able to generate data from them at the same scale as the other models. Complicating things further was the fact that these models also take longer to run because they spend so much time thinking before generating output tokens.
We regenerated our training set data with a small amount of o3 and o3-pro data included. In our final training set for the July release, o3 text only comprises 0.17% of the training data mix, and o3-pro text only comprises 0.35%. We balanced this out and hoped for generalization by also boosting the composition of o3-mini text to 5% of the training data mix. Surprisingly, this worked very well! With just a slight training set adjustment, we were able to match the recall of o3 and o3 pro with the recall of the other LLMs we evaluate, without having to trade off any false positives.
Pangram is a few-shot learner
This behavior of Pangram, wherein we can train it on a small sample size of data from new LLMs that are qualitatively different than their predecessors, makes Pangram what we term a "Few-Shot Learner." This behavior has strong implications: when new LLMs are released, or even new LLM-based products that are under-the-hood based on fine-tuned LLMs that may have different underlying writing styles, Pangram is able to adapt to them quickly and inexpensively, without the need for massive dataset regeneration.
Many people ask us why we believe we can win what is ultimately a "cat and mouse" game. Because Pangram is a few-shot learner, catching up to the new LLMs is hardly as difficult as it may seem on the surface- we only need a few examples to show Pangram before it is able to generalize and learn the pattern very efficiently. Put in layman's terms, Pangram is extremely effective at "Learning to Learn" what new LLMs sound like, because it has seen so many LLMs in its past.
That, along with the fact that each LLM has its own distinct, idiosyncratic style, has actually made it easier for Pangram to adapt to new LLMs as they are released, even as LLMs are improving and becoming more capable. The way we see it, LLM capability is orthogonal to LLM detectability.
Parting Thoughts: Why are o3 and o3-pro different?
We've heard from several folks in AI circles that o3 and o3-pro do have a different vibe than the other LLMs that we've seen before. In our experience, they are the first models in a long time (since Claude 2) that Pangram does not catch zero-shot with 99%+ reliability (without seeing any data from the model). While it's hard to pinpoint what makes them different, here is a collection of some hypotheses for why there might be something special about it.
-
o3 and o3-pro are over-optimized for tool use. We know that Pangram is largely detecting AI-generated content based on behaviors and idiosyncracies introduced in post-training. OpenAI says in their release blog post that o3 and o3-pro are different from their predecessors in that they are trained using reinforcement learning to use tools as part of their post-training process. This difference in the post-training algorithm may have also qualitatively affected the style of the outputs.
-
o3 and o3-pro hallucinate more. According to Nathan Lambert, o3 put an invalid non-ASCII character in code, hallucinated actions that it took while trying to solve tasks, such as hallucinating that it ran timing code on a Macbook Pro that was completely made up, and independent evaluations by METR have found that o3 has a propensity to "hack their scores" rather than actually solving agentic tasks for real.
For more information on o3 and o3-pro, we would recommend reading Nathan's blog post, Dan Shipper's "Vibe Check", and OpenAI's release blog post.
Conclusion
Pangram is as strong on reasoning models as any other LLMs, but o3 and o3-pro seem different than their predecessors in terms of writing style and tone. Through the course of improving Pangram's performance on o3 and o3-pro, we realized that we actually may not need as many examples as we thought from each LLM when they are released, due to the fact that Pangram is an extremely strong few-shot learner.
We are considering changes to our training architecture and routine that will make updating Pangram much faster and easier, and allow us to ship AI detection models that can detect the latest LLMs even faster than before. Stay tuned for more updates!

Bradley is an AI researcher and expert in building deep learning products in industry. He recently led the deep learning research group at Absci, a generative AI drug discovery company, and previously was a member of the core computer vision team at Tesla Autopilot.
While a graduate student, Bradley authored multiple publications in deep learning research with the Stanford Vision Lab. He holds a B.S. in physics and an M.S. in artificial intelligence from Stanford. Aside from AI, he is also excited about education, philosophy, and is an avid golfer.
Related reading
Technical Report on High Accuracy AI-generated Text Detection

Can AI Detectors Catch GPT-4.5?

Announcing AI Identification: Pangram can distinguish the different LLMs from each other

How to detect AI in Python

Introducing Pangram 3.0 with AI assistance detection

Introducing Tags and Groups
to our updates
