This blog post was cross-posted from the author's Substack. Follow him here!
Funding Disclosure: OpenRouter credits were supplied by Pangram to conduct this research, and the original idea for this research was suggested by Max Spero, CEO of Pangram. I have tried my best to remain impartial and the writing below reflects my genuine views.
Back when ChatGPT first came out, there were several high-profile stories where people attempted to use it as an AI detector - i.e., feeding it a piece of text and asking it point-blank whether or not it was AI-generated. The Washington Post reported on a Texas A&M professor who had given multiple students zeroes on the basis that ChatGPT claimed authorship of their papers. An assistant professor at the University of San Francisco told her colleagues that “All we have to do is ask ‘Did you write this?’” and then copy and paste the student work into the prompt box.” - only to then write a blog post about the absurd number of false positives this generated. More recently, when a Granta-published short-story competition winner was accused of using AI, Granta employed Claude to investigate whether the winning text was in fact AI-generated.
While these attempts may seem naive, and perhaps a bit amusing - after all, ChatGPT has no way to verify it generated a text and must guess based off vibes (just like a human would). But it’s not an irrational inference for a nontechnical person to make: ChatGPT can write stories like a human author, and human authors can recognize/remember their work, so why not ChatGPT? Furthermore, there exist other forms of AI-generation verification like SynthID for images, audio, and video. Why not one for text? The answer, that SynthID requires a detectable watermark, is non-obvious. Even more confusingly, if you ask Gemini whether an image is AI-generated, it simply says “Yes, most or all of this image was generated or edited using Google AI.” - obscuring the SynthID watermark verification, and giving the impression that Gemini can just deduce it visually on vibes. So, to clarify all this ambiguity:
- LLMs have no episodic memory of generating a piece of text, so they cannot identify it by virtue of having written it.
- Text watermarking does exist - such as Google’s SynthID Text - but requires the text to have been generated by a participatory AI system with watermarking enabled. Therefore, it isn’t a universal solution for arbitrary text.
- Thus, AI text detection must be done via intuition - either human intuition, trained machine learning algorithms (like Pangram), or the intuition of an LLM.
And historically, the intuitions of LLMs have been bad! This makes a ton of sense - the earliest generation of consumer-facing LLMs - GPT-3.5 & GPT-4, perhaps Claude 3 - were all trained on data prior to the AI-slopping of the internet. Their exposure to AI-generated text was likely limited if not nonexistent, so of course their zero-shot performance would be poor. But this raises the question: would more modern LLMs, trained on more recent data - perhaps have better intuition?
Adam Kucharski investigated this on his Substack, and the initial results are promising: Claude was able to tell apart two AI-generated story openings from 1 human-written one, identify ten GPT-5.5 written stories as AI-written with probability >80%, and gave no more than a 22% probability of being AI-written to ten stories sampled from Kucharski’s personal writings. Even more promisingly, Kucharski asked GPT-5.5 to “improve” each of his ten stories and five flipped from human-written to AI-generated. This is twenty-three successes on direct AI-classification, and five successes/five failures on AI-editing classification.
This raises the question: when did this AI-detection ability emerge? To test this, I used Pangram’s open editlens-iclr dataset, which contains ample examples of human passages and AI-generated mirrors of those same passages. To start, I sampled a pilot of 100 passages - 50 human and 50 AI - and evaluated a battery of models - both historical and current - for zero-shot accuracy. To maximize vibes-based classification - the intuition I was trying to detect - I conducted this experiment with reasoning off where available and strict instructions to respond only in one word. This resulted in the following zero-shot prompt format:
 Zero-shot prompt format
Zero-shot prompt format
The results are shown below, and are quite striking:
 Zero-shot performance by release date
Zero-shot performance by release date
We see that GPT-4 starts at 52% - no better than chance - corresponding to the 2023/2024 intuition of AI having no ability to detect its own writing (GPT-3.5-Turbo got 49%, and isn’t included on the above chart). Flash forward to Spring and Summer of 2025, and GPT-4.1 gets 71%, Sonnet 4 62%, and Opus 4 69%. What then follows is a rapid capability-climb from mid-summer of 2025 to Early 2026 - where both the GPT and Claude series reach accuracies above 90% on this 100-example slice. This jump also happens, albeit a bit later, to the Qwen Plus series, which skyrockets from 55% accuracy for the Qwen3.5 Plus release to 83% for Qwen3.6 Plus - released only two months later.
One may wonder whether this zero-shot advantage is mostly explained by familiarity with AI-generated content or simply a gap in intelligence - with smarter frontier models serving as better classifiers. To test this, we can see how inserting few-shot examples (drawn from the train set and randomized per-question, of course) into the context changes accuracy. This upgrades our prompt format to the following few-shot template:
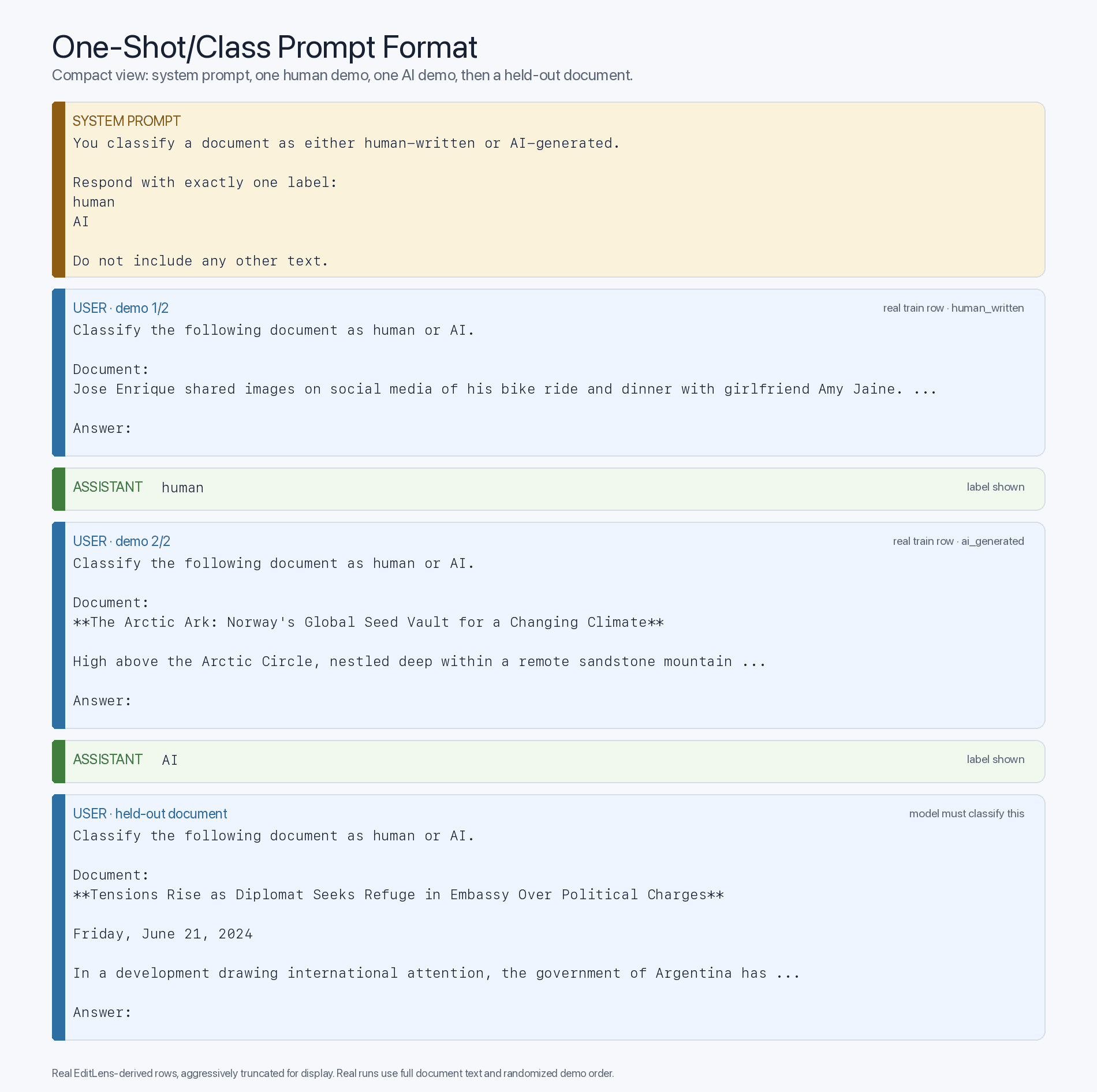
If, under this few-shot prompt format, older models dramatically improve with exposure to the proper input-label mappings, then the bottleneck is pretraining exposure, not intelligence. And that is exactly what we see:
 GPT per-question ICL chart
GPT per-question ICL chart
While GPT-4 zero-shot gets only 52%, at 4-shot1 it gets 85%. It’s clear GPT-4 can learn in-context to distinguish between AI-generated and human-written texts - it just doesn’t have the innate pretrained knowledge of how. This is underscored by zero-shot performance improving almost monotonically with respect to model generation, but few-shot performance staying nearly flat after ~GPT-5.1 and only noticeably ticking up to 99% at GPT-5.5. This evidence strongly suggests that the missing ingredient for LLMs to become half-decent zero-shot AI detectors was simply appropriate pre-training data (or gold in-context examples), not any intrinsic constraint of their nature or intelligence.
To further investigate the impact of few-shot in-context learning on ICL detection ability, I needed a harder set to extract more signal - after all, if modern frontier models score 95% on a 100-question evaluation, it ceases to be useful. To construct this hard set, I filtered the Pangram dataset to only keep examples that fooled Qwen 3.7 Plus twice (at temp=0.7). This gave me 3,503 AI-generated samples, and 763 human-written samples - which I then class-balanced (via uniform random sampling) to produce the final hard dataset of 763 AI-generated samples and 763 human-written samples.
I evaluate both Sonnet 4.6 and GPT-5.5 on this hard dataset, at 0, 1, 2, 4, and 8 shots, with reasoning off and with reasoning on (medium effort for GPT-5.5, simple extended thinking for Sonnet 4.6 for cost-effectiveness):
 Cleaned Sonnet 4.6 chart
Cleaned Sonnet 4.6 chart
 Cleaned GPT-5.5 chart
Cleaned GPT-5.5 chart
We see that GPT-5.5 far outclasses Sonnet 4.6 zero-shot - predictable from GPT-5.5 coming out in April 2026 and Sonnet 4.6 coming out in February 2026. Notable is that this gap vastly shrinks with ICL - while (with reasoning off) GPT-5.5 gets 86.8%zero-shot to Sonnet 4.6’s 72.9%, by 8 shots, GPT-5.5 gets 96.2% to Sonnet 4.6’s 93.8%. This further reinforces that a lot of AI-detection is an ability that, like almost any other type of text-classification, can be conferred in context.
Notable is that while reasoning results in a significant uplift of a few percentage points for GPT-5.5, it only really helps Sonnet 4.6 in the zero-shot regime (giving +2.2%) and either barely hurts or barely helps after. Statistical tests bear this out - after Bonferroni correction, GPT-5.5’s benefit from reasoning remains statistically significant at 0, 1, 2, and 8 shots, while Sonnet 4.6 only has a significant effect at zero shots.
This seems to suggest that while test-time compute can help for AI-writing classification, only some model families have the training/ability to apply it effectively relative to immediate intuition, and the gains aren’t huge, relative to simply giving more in-context examples to learn from. Future work could test GPT-5.5 at high or xhigh reasoning to see if gains continued.
In summary, we’ve seen that modern LLMs can successfully distinguish AI-generated writing from human writing, that this ability is likely due to more pretraining exposure to AI-generated content, and that it benefits slightly from test-time compute but greatly from more in-context examples (to the extent that older LLMs like GPT-4 can learn it from a zero-shot chance-level baseline). This cuts against the older narrative that ChatGPT was incapable of telling you whether a piece of text was AI-generated. However, I still wouldn’t use them as AI detectors in practice - on the hard set, the best-performing model - GPT-5.5 with medium reasoning gets a false positive rate of 4.59%, which is unacceptable for even casual use (for context, note a recent study found that the average false positive rate of five expert human annotators was 5.6%, but an ensemble of these annotators had an FPR of 0%). If you’re looking for a reliable detector, I would recommend Pangram, with the caveats discussed in my In Defense of Pangram article. Regardless, I still find this ability quite intriguing - and I thought it important to document, given the common wisdom for the past several years has been that LLMs are utterly incapable of detecting LLM-generated writing. Instead, it’s better to model LLMs as roughly “good-to-expert human” level at detecting AI-writing. They’re fairly accurate, but have single-percent false positive rates that make their accusations unactionable.
Footnotes
-
Note that here, 4-shot means 4 AI examples, 4 human examples - not 4 total examples. ↩

Nathan Breslow - online alias N8Programs - is an undergraduate student at Johns Hopkins studying applied mathematics. He additionally works on in-context learning in LLMs at the Intelligence Amplification Lab, contributes to local inference frameworks, and pretrains language models on exotic modalities. Views expressed here are his own.
Related reading

How to spot AI reviews

AI is Writing Prize-Winning Fiction

How Gradpilot uses Pangram to help students find their voice

Which AI Detector Is Most Accurate? 30 Tools Tested (2026)
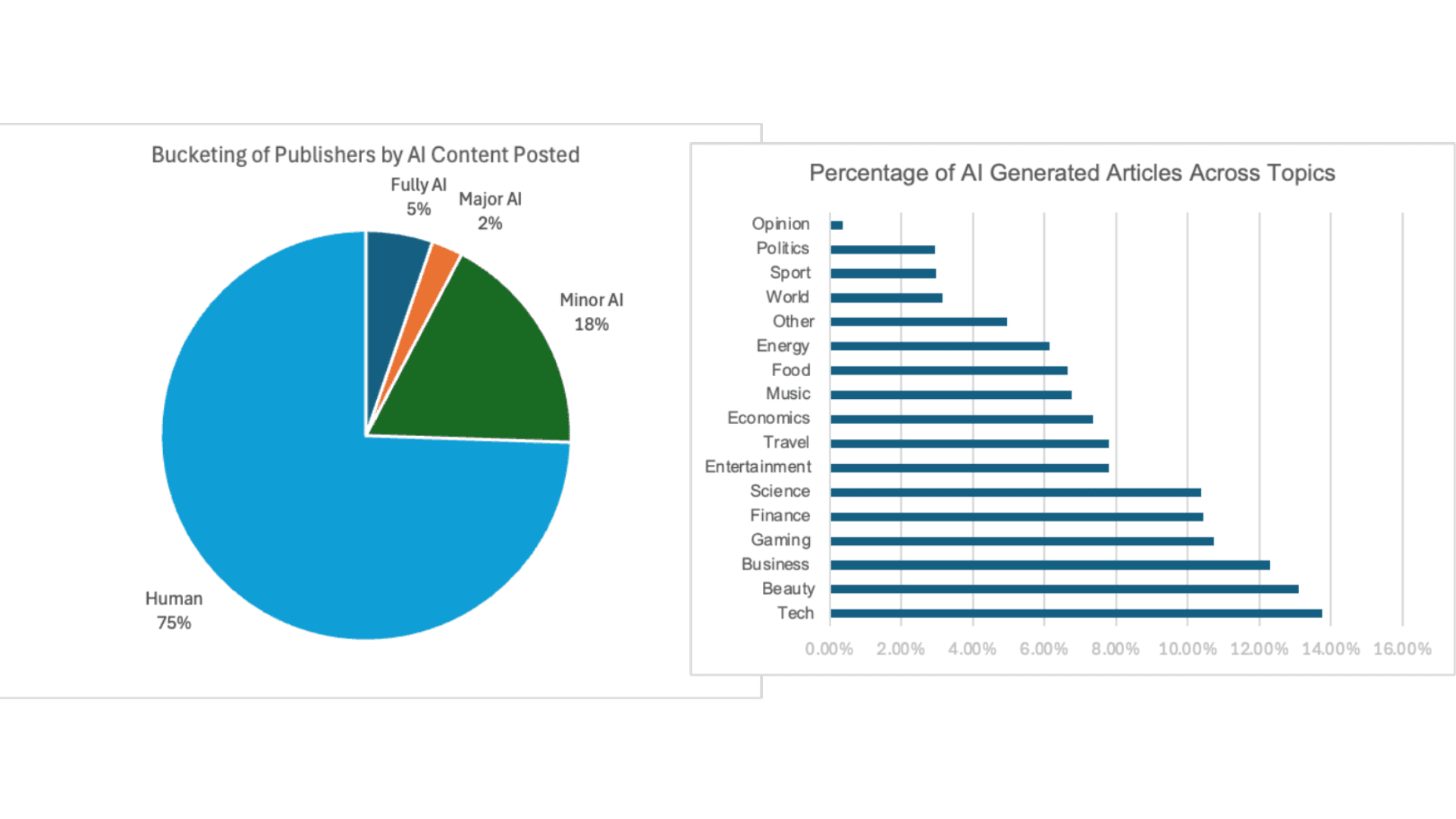
60,000 AI-generated news articles are published every day

How does Pangram compare against GPTZero?
to our updates
