I documenti presentati alle conferenze sull'IA sono sempre più spesso redatti dall'IA: +370% dal 2023
 Un grafico che illustra la percentuale di abstract generati dall'intelligenza artificiale inviati all'ICLR per anno, evidenziando una tendenza al rialzo a partire dal 2023.
Un grafico che illustra la percentuale di abstract generati dall'intelligenza artificiale inviati all'ICLR per anno, evidenziando una tendenza al rialzo a partire dal 2023.
Nel febbraio 2024, un articolo pubblicato su *Frontiers in Cell and Developmental Biology* presentava delle immagini che erano palesemente state generate dall'intelligenza artificiale. Questo articolo in particolare ha fatto scalpore perché una delle immagini ritraeva un ratto con testicoli di dimensioni assurde e un testo incomprensibile che non aveva assolutamente alcun senso.
Si tratta di un articolo scientifico pubblicato su *Frontiers in Cell and Developmental Biology*. Le figure sono chiaramente generate dall'intelligenza artificiale. Una di esse raffigura un ratto con testicoli di dimensioni assurde. Il testo nelle figure è incomprensibile. pic.twitter.com/4Acn2YZYwM
— Cliff Swan (@cliff_swan) 15 febbraio 2024
Sebbene la revisione tra pari (in teoria) dovrebbe essere sufficiente a individuare casi evidenti come questo, cosa succede quando il contenuto effettivo dell'articolo è generato dall'intelligenza artificiale? Persino gli esperti hanno difficoltà a distinguere le ricerche generate dall'intelligenza artificiale da quelle scritte da esseri umani.
Un recente articolo pubblicato su *Nature* mette in luce la crescente preoccupazione riguardo ai contenuti generati dall’intelligenza artificiale (IA) negli articoli accademici. L’articolo descrive uno studio in cui alcuni informatici hanno utilizzato Claude 3.5, uno dei più recenti modelli di linguaggio di grandi dimensioni (LLM), per generare idee di ricerca e redigere articoli, che sono stati poi sottoposti a revisori scientifici. Questi ultimi hanno valutato gli articoli in base a «novità, interesse, fattibilità ed efficacia prevista». In media, è emerso che i revisori hanno assegnato un punteggio più alto agli articoli generati dall’IA rispetto a quelli scritti da esseri umani! Ciò porta alla domanda: l'IA produce effettivamente idee di ricerca migliori rispetto agli esseri umani? Sebbene si sia tentati di credere che possa essere così, dei 4.000 articoli generati dall'IA studiati dai ricercatori, solo 200 (il 5%) contenevano effettivamente un'idea originale: la maggior parte degli articoli si limitava a riproporre idee già esistenti provenienti dal set di addestramento dell'LLM.
In definitiva, la ricerca generata dall'IA danneggia la comunità aggiungendo rumore e riducendo il segnale nel processo di revisione tra pari, per non parlare dello spreco di tempo e di energie da parte dei revisori che si impegnano a garantire il rispetto degli standard di ricerca. Inoltre, ciò che è ancora peggio è che la ricerca generata dall'IA spesso sembra convincente, ma in realtà il testo prodotto da un modello linguistico suona semplicemente fluido e può essere pieno di errori, allucinazioni e incongruenze logiche. La preoccupazione in questo caso è che spesso nemmeno i revisori esperti riescono a capire quando ciò che stanno leggendo è un'allucinazione generata da un modello linguistico di grandi dimensioni (LLM).
Gli organizzatori delle principali conferenze sul machine learning sono d'accordo con noi: nella scrittura scientifica non c'è spazio per i testi generati dai modelli di linguaggio di grandi dimensioni (LLM). La linea guida ufficiale dell'ICML (Conferenza internazionale sul machine learning) recita quanto segue:
Chiarimenti sulla politica relativa ai modelli linguistici di grandi dimensioni
Noi (i responsabili del programma) abbiamo inserito la seguente dichiarazione nel bando per la presentazione di articoli per l'ICML 2023:
Sono vietati gli articoli che includono testi generati da un modello linguistico su larga scala (LLM), come ChatGPT, a meno che il testo prodotto non sia presentato come parte dell'analisi sperimentale dell'articolo.
Questa dichiarazione ha suscitato una serie di domande da parte dei potenziali autori e ha spinto alcuni di loro a contattarci di propria iniziativa. Apprezziamo i vostri riscontri e commenti e vorremmo chiarire ulteriormente l'intento alla base di questa dichiarazione e come intendiamo attuare questa politica in occasione dell'ICML 2023.
TLDR;
La politica sui modelli linguistici di grandi dimensioni (LLM) per l'ICML 2023 vieta l'utilizzo di testi prodotti interamente da LLM (ovvero "generati"). Ciò non impedisce agli autori di ricorrere agli LLM per modificare o perfezionare testi da loro redatti. La politica sugli LLM si basa in gran parte sul principio di adottare un approccio prudente al fine di prevenire potenziali problemi legati all'uso degli LLM, compreso il plagio.
Nonostante questo avvertimento, constatiamo che un numero significativo e crescente di autori nel campo dell'apprendimento automatico sta violando la politica e continua comunque a utilizzare l'intelligenza artificiale per generare testi nei propri articoli.
Valutare la portata del problema
Noi di Pangram abbiamo voluto valutare la portata di questo problema nel nostro settore: l'intelligenza artificiale. Ci siamo quindi posti la seguente domanda: i ricercatori nel campo dell'IA utilizzano ChatGPT per redigere i propri lavori di ricerca?
Per analizzare questo problema, abbiamo utilizzato l'API di OpenReview per estrarre i contributi presentati dal 2018 al 2024 in occasione di due delle più importanti conferenze sull'intelligenza artificiale: ICLR e NeurIPS.
Abbiamo quindi applicato il rilevatore di IA di Pangram a tutti gli abstract inviati a queste conferenze. Ecco i risultati:
ICLR
Un grafico che illustra la percentuale di abstract generati dall'intelligenza artificiale inviati all'ICLR per anno, evidenziando una tendenza al rialzo a partire dal 2023.
NeurIPS
 Un grafico che illustra la percentuale di abstract generati dall'intelligenza artificiale inviati a Neurips per anno, evidenziando una tendenza al rialzo a partire dal 2023.
Un grafico che illustra la percentuale di abstract generati dall'intelligenza artificiale inviati a Neurips per anno, evidenziando una tendenza al rialzo a partire dal 2023.
I risultati
Possiamo considerare tutti i dati precedenti al 2022 come un set di validazione per il tasso di falsi positivi del nostro modello, poiché all'epoca i modelli linguistici di grandi dimensioni non esistevano ancora. Come mostrato nelle figure, prevediamo che ogni singolo abstract di conferenza del 2022 o precedente venga classificato dal nostro modello come scritto da un essere umano. Questo dovrebbe ispirare fiducia nell'accuratezza del nostro modello: il nostro tasso di falsi positivi è molto buono sugli abstract scientifici, quindi possiamo essere certi che ogni previsione positiva effettuata nel 2023 e nel 2024 sia un vero positivo.
Quello a cui assistiamo da allora è davvero preoccupante. Da quando ChatGPT è stato lanciato nel novembre 2022, si sono susseguiti tre cicli di conferenze.
Il primo ciclo si è svolto proprio in concomitanza con il lancio di ChatGPT (ICLR 2023). La scadenza per l'invio era in realtà precedente al lancio di ChatGPT, ma gli autori hanno avuto la possibilità di apportare modifiche prima che la conferenza avesse luogo, ovvero un paio di mesi dopo il lancio di ChatGPT. Quello che abbiamo riscontrato è in linea con le aspettative: solo una manciata di abstract è stata scritta dall'IA (in questo ciclo ne abbiamo individuati solo 2 su diverse migliaia) e probabilmente sono stati modificati dopo la scadenza.
Il secondo ciclo si è svolto circa sei mesi dopo, con NeuRIPS 2023, il cui termine per la presentazione era fissato all'estate del 2023 in vista della conferenza di dicembre. In questa conferenza abbiamo riferito che circa l'1,3% degli abstract inviati era stato generato dall'intelligenza artificiale: una percentuale modesta ma significativa.
Infine, nell'ultima edizione, l'ICLR 2024, tenutasi appena pochi mesi fa, abbiamo registrato un aumento fino al 4,9%: una crescita di quasi quattro volte rispetto alle recensioni generate dall'IA del NeuRIPS 2023!
Questi risultati mettono in luce una tendenza preoccupante: non solo sta aumentando il numero di articoli scientifici generati dall'intelligenza artificiale presentati ai principali convegni del settore, ma tale numero sta crescendo a un ritmo sempre più sostenuto; in altre parole, il ritmo con cui vengono presentati questi articoli sta accelerando.
Come sono gli abstract generati dall'intelligenza artificiale?
Date un'occhiata ad alcuni di questi abstract e valutate voi stessi se vi sembrano simili allo stile di scrittura a cui siete abituati nella letteratura scientifica tecnica:
-
Nel complesso panorama dei dati interconnessi, comprendere gli effetti causali degli interventi rappresenta una sfida fondamentale con implicazioni in vari ambiti. Le reti neurali grafiche (GNN) si sono affermate come uno strumento potente per cogliere dipendenze complesse, ma il potenziale del deep learning geometrico per l’inferenza causale di rete basata sulle GNN rimane ancora poco esplorato. Questo lavoro offre tre contributi chiave per colmare tale lacuna. In primo luogo, stabiliamo una connessione teorica tra la curvatura del grafo e l'inferenza causale, rivelando che le curvature negative pongono delle sfide nell'identificazione degli effetti causali. In secondo luogo, sulla base di questa intuizione teorica, presentiamo risultati computazionali che utilizzano la curvatura di Ricci per prevedere l'affidabilità delle stime degli effetti causali, dimostrando empiricamente che le regioni a curvatura positiva producono stime più accurate. Infine, proponiamo un metodo che utilizza il flusso di Ricci per migliorare la stima dell'effetto del trattamento sui dati in rete, mostrando prestazioni superiori grazie alla riduzione dell'errore ottenuta appiattendo i bordi della rete. I nostri risultati aprono nuove strade per sfruttare la geometria nella stima degli effetti causali, offrendo approfondimenti e strumenti che migliorano le prestazioni delle GNN nei compiti di inferenza causale.
-
Nel campo dei modelli linguistici, la codifica dei dati riveste un ruolo fondamentale, poiché influenza l'efficienza e l'efficacia dell'addestramento dei modelli. Il Byte Pair Encoding (BPE) è una tecnica consolidata di tokenizzazione a livello di sottounità lessicali che bilancia l'efficienza computazionale e l'espressività linguistica unendo coppie frequenti di byte o caratteri. Poiché l'addestramento dei modelli linguistici richiede notevoli risorse computazionali, proponiamo Fusion Token, un metodo che migliora sostanzialmente l'approccio convenzionale del Byte Pair Encoding (BPE) nella codifica dei dati per i modelli linguistici. Fusion Token impiega una strategia computazionale più aggressiva rispetto al BPE, espandendo i gruppi di token dai bi-grammi ai 10-grammi. È degno di nota il fatto che, con l'aggiunta di 1024 token al vocabolario, il tasso di compressione superi significativamente quello di un normale tokenizzatore BPE con un vocabolario di un milione di parole. Nel complesso, il metodo Fusion Token porta a notevoli miglioramenti delle prestazioni grazie a una maggiore portata dei dati per unità di calcolo. Inoltre, una compressione più elevata si traduce in tempi di inferenza più rapidi grazie al minor numero di token per una data stringa. Dedicando maggiori risorse di calcolo al processo di costruzione del tokenizer, Fusion Token massimizza il potenziale dei modelli linguistici come motori di compressione dati efficienti, consentendo sistemi di modellazione linguistica più efficaci.
-
Nel campo in rapida evoluzione della generazione del movimento, il potenziamento della semantica testuale è stato riconosciuto come una strategia altamente promettente per produrre movimenti più accurati e realistici. Tuttavia, le tecniche attuali dipendono spesso da modelli linguistici estesi per perfezionare le descrizioni testuali, senza garantire un allineamento preciso tra i dati testuali e quelli di movimento. Questo disallineamento porta spesso a una generazione di movimenti non ottimale, limitando il potenziale di questi metodi. Per affrontare questo problema, introduciamo un nuovo framework chiamato SemanticBoost, che mira a colmare il divario tra i dati testuali e quelli di movimento. La nostra soluzione innovativa integra informazioni semantiche supplementari derivate dai dati di movimento stessi, insieme a una rete dedicata alla riduzione del rumore, per garantire la coerenza semantica ed elevare la qualità complessiva della generazione del movimento. Attraverso esperimenti e valutazioni approfonditi, dimostriamo che SemanticBoost supera significativamente i metodi esistenti in termini di qualità del movimento, allineamento e realismo. Inoltre, i nostri risultati sottolineano il potenziale di sfruttare gli indizi semantici dai dati di movimento, aprendo nuove strade per una generazione del movimento più intuitiva e diversificata.
Notate qualche schema ricorrente? Innanzitutto, vediamo che tutti i testi iniziano con frasi molto simili: «Nel complesso panorama di», «Nel campo di», «Nel settore in rapida evoluzione di». È quello che chiamiamo linguaggio artificiosamente ampolloso. Abbiamo già scritto in precedenza di quanto spesso i modelli di linguaggio (LLM) utilizzino molte parole per produrre pochissimo contenuto effettivo. Sebbene ciò possa essere auspicabile per uno studente che cerca di raggiungere un numero minimo di parole in un compito a casa, per un lettore tecnico che cerca di approfondire una ricerca, questo tipo di linguaggio eccessivamente prolisso rende l'articolo più difficile e più lungo da leggere, rendendo al contempo meno chiaro il messaggio effettivo dell'articolo.
Gli articoli sull'intelligenza artificiale vengono effettivamente accettati alle conferenze?
Ci siamo chiesti se gli articoli generati dall'intelligenza artificiale vengano effettivamente filtrati in modo efficace dal processo di revisione tra pari o se alcuni di essi riescano a sfuggire al controllo.
Per rispondere a questa domanda, abbiamo analizzato la correlazione tra gli abstract generati dall'IA e le decisioni relative agli articoli presentati all'ICLR 2024. (Gli articoli delle categorie "Oral", "Spotlight" e "Poster" sono tutti articoli "Accettati"; le categorie "Oral" e "Spotlight" sono categorie di riconoscimento speciale). Ecco cosa abbiamo scoperto:
| Categoria | Percentuale generata dall'intelligenza artificiale |
|---|---|
| ICLR 2024 orale | 2.33% |
| Poster ICLR 2024 | 2.71% |
| ICLR 2024 sotto i riflettori | 1.36% |
| Rifiutato | 5.42% |
Sebbene la percentuale di articoli generati dall'intelligenza artificiale che sono stati accettati sia inferiore a quella degli articoli inviati, un numero significativo di essi è comunque riuscito a superare il processo di revisione tra pari. Ciò significa che, sebbene i revisori possano individuare alcuni contenuti generati dall'intelligenza artificiale, non riescono a individuarli tutti.
Abbiamo notato che persino alcuni interventi orali e articoli in primo piano presentano abstract generati dall'intelligenza artificiale! Interpretando la situazione con benevolenza, ciò che potremmo scoprire in futuro è che la ricerca potrebbe effettivamente essere di alta qualità e che gli autori stiano semplicemente ricorrendo a ChatGPT per presentare o rivedere al meglio il proprio lavoro.
In particolare, dato che gran parte della comunità scientifica non è di madrelingua inglese, uno degli impieghi sempre più diffusi dei modelli di linguaggio di grandi dimensioni (LLM) sarà quello di tradurre in inglese articoli scritti in altre lingue.
Conclusione
Nonostante la comunità dell'intelligenza artificiale abbia espressamente chiesto agli autori di non utilizzare ChatGPT, molti di loro ignorano questa linea guida e ricorrono comunque ai modelli di linguaggio di grandi dimensioni (LLM) per scrivere i propri articoli. Ciò che preoccupa maggiormente è che nemmeno gli esperti di IA, che in qualità di revisori hanno il compito di proteggere i convegni dagli articoli generati dagli LLM, riescono a individuarli!
ChatGPT sta avendo ripercussioni sempre più ampie su tutto il processo accademico. Un recente studio di caso dell'ICML ha rilevato che tra il 6 e il 16 per cento delle revisioni tra pari sono state generate dall'intelligenza artificiale, e che esiste una correlazione positiva tra le revisioni generate dall'intelligenza artificiale e la vicinanza della data di invio della revisione alla scadenza!
Chiediamo alla comunità dell'intelligenza artificiale di applicare con maggiore rigore queste linee guida e agli autori di assumersi la responsabilità di garantire che i loro articoli siano redatti da esseri umani.
L'ingresso dell'intelligenza artificiale nel mondo della scrittura non si limita alla ricerca: l'intelligenza artificiale sta conquistando anche premi letterari.

Bradley è un ricercatore nel campo dell'intelligenza artificiale ed è esperto nello sviluppo di prodotti basati sul deep learning per il settore industriale. Recentemente ha guidato il gruppo di ricerca sul deep learning presso Absci, un'azienda che si occupa di scoperta di farmaci tramite intelligenza artificiale generativa, mentre in precedenza ha fatto parte del team principale di visione artificiale di Tesla Autopilot.
Durante gli studi universitari, Bradley è stato autore di numerose pubblicazioni nel campo della ricerca sul deep learning presso lo Stanford Vision Lab. Ha conseguito una laurea in fisica e un master in intelligenza artificiale presso l'Università di Stanford. Oltre all'intelligenza artificiale, nutre un grande interesse per l'istruzione e la filosofia ed è un appassionato giocatore di golf.
Altre letture
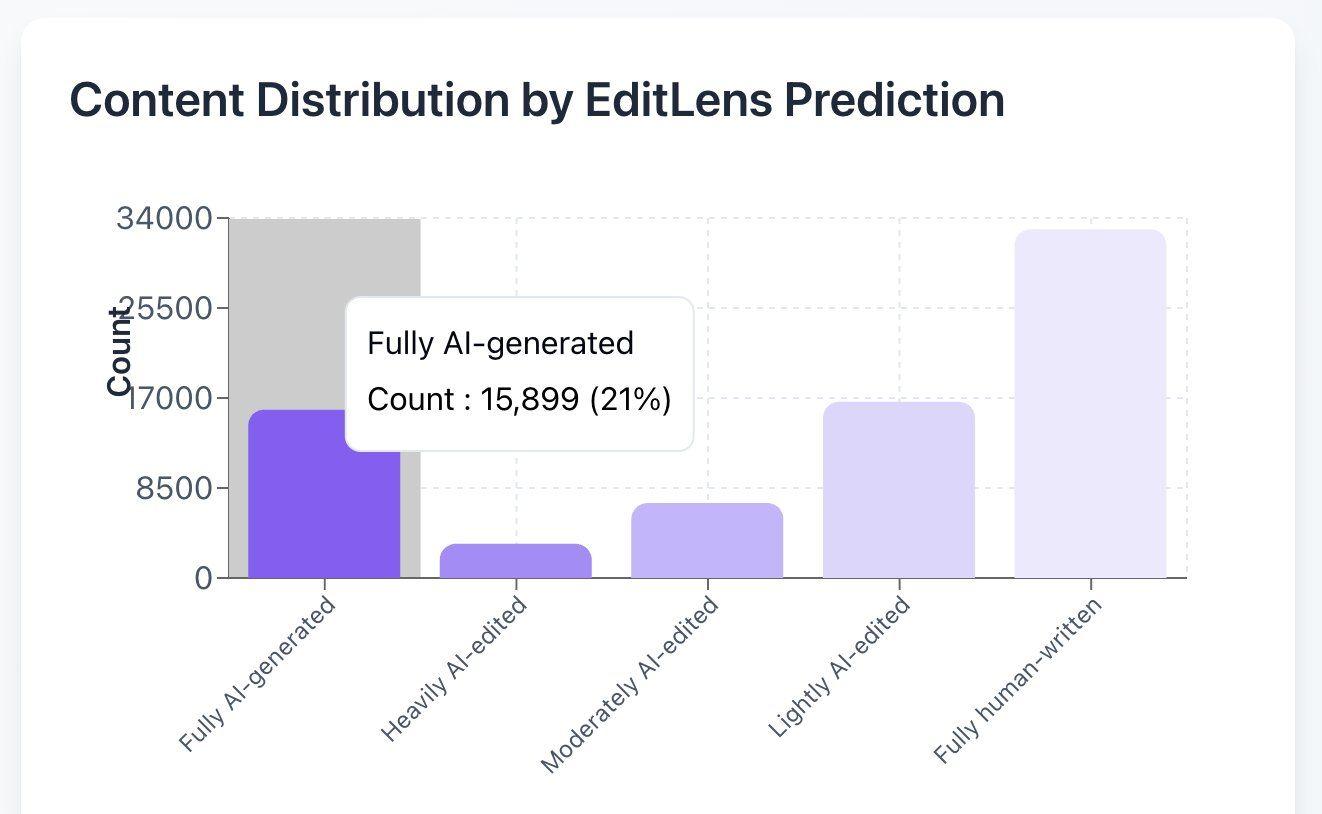
Pangram prevede che il 21% delle recensioni dell'ICLR sia generato dall'intelligenza artificiale
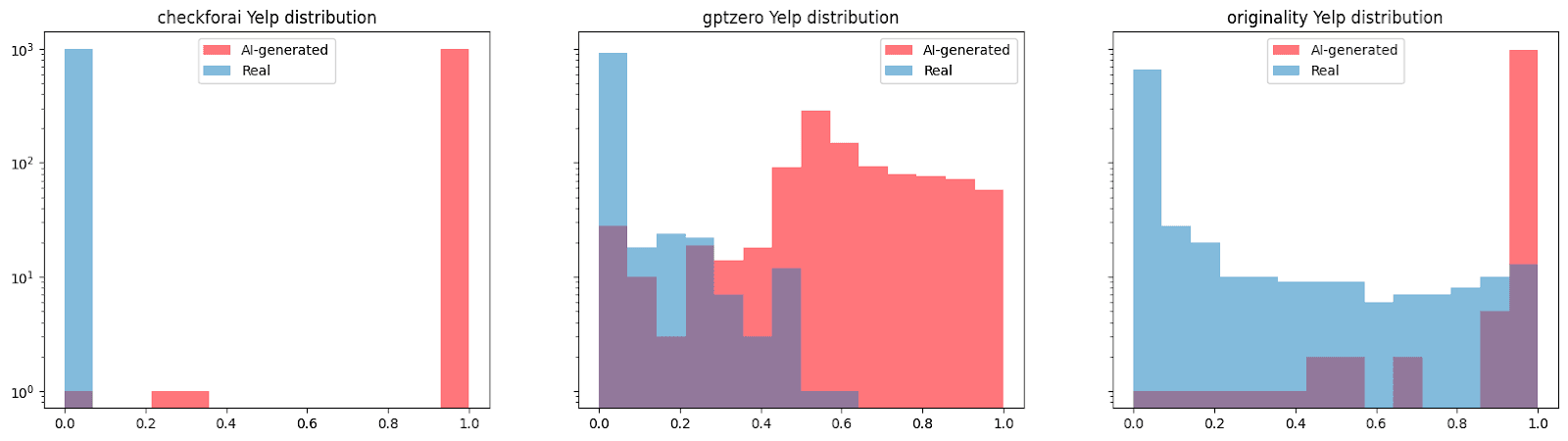
Analisi approfondita delle recensioni su Yelp

L'IA ha un occhio di riguardo per l'IA

Il 3% delle recensioni in prima pagina su Amazon è ora generato dall'intelligenza artificiale

Qual è il rilevatore di IA più preciso? 30 strumenti testati (2026)

Rendere la tua azienda a prova di LLM e GenAI
per ricevere i nostri aggiornamenti
