NOTA: Abbiamo cambiato il nostro nome in Pangram Labs! Per ulteriori dettagli, consulta il nostro post sul blog.
Noi di Checkfor.ai ci impegniamo per essere il miglior strumento di rilevamento di testi generati dall'IA, con l'obiettivo di promuovere la nostra missione: proteggere Internet dall'inquinamento causato dai contenuti di scarsa qualità generati dall'IA. Uno dei settori più importanti da difendere è quello delle piattaforme di recensioni degli utenti.
Le recensioni online false finiscono per danneggiare sia le aziende che i consumatori, e ChatGPT ha solo reso ancora più facile commettere frodi nelle recensioni su larga scala.
 Recensione generata da ChatGPT su Yelp
Recensione generata da ChatGPT su Yelp
Mantenere la fiducia degli utenti nelle recensioni online è una parte fondamentale della nostra missione in Checkfor.ai, volta a tutelare l'autenticità dei contenuti generati dagli utenti sul web.
Chi sono
Mi chiamo Bradley Emi e sono il CTO di Checkfor.ai. Ho lavorato come ricercatore nel campo dell’intelligenza artificiale a Stanford, ho realizzato modelli operativi in qualità di ML Scientist nel team Tesla Autopilot e ho guidato un gruppo di ricerca che ha sviluppato una piattaforma per la progettazione di farmaci utilizzando grandi reti neurali presso Absci. Nel campo delle auto a guida autonoma e della scoperta di farmaci, un'accuratezza del 99% semplicemente non è sufficiente. Un'accuratezza del 99% potrebbe significare che 1 pedone su 100 viene investito da un veicolo autonomo, oppure che 1 paziente su 100 subisce effetti collaterali potenzialmente letali a causa di un farmaco mal progettato.
Sebbene individuare i testi generati dall’IA non sia necessariamente una questione di vita o di morte, noi di Checkfor.ai vogliamo progettare modelli e sistemi software che rispettino gli stessi standard di qualità. Il nostro rilevatore deve resistere ad attacchi avversari quali la parafrasi, il prompt engineering avanzato e gli strumenti di elusione del rilevamento come undetectable.ai. Prendiamo molto sul serio la risoluzione di questo problema (ad esempio, non ci accontentiamo di arrivare al 99%) e, pertanto, una delle massime priorità del nostro team di ingegneri è sviluppare una piattaforma di valutazione estremamente robusta.
Filosofia di valutazione: i set di test sono test unitari
Un'azienda di sicurezza informatica di tipo "Software 1.0" non lancerebbe mai un prodotto senza test unitari. In quanto azienda di tipo "Software 2.0", abbiamo bisogno di qualcosa di equivalente ai test unitari, con la differenza che devono testare modelli di grandi dimensioni con milioni o addirittura miliardi di parametri, che possono comportarsi in modo stocastico e devono funzionare correttamente coprendo un'ampia distribuzione di casi limite. Non possiamo raggiungere una "precisione del 99% sul set di test" e considerare il lavoro concluso: abbiamo bisogno di valutazioni che testino specificamente i tipi di esempi che incontreremo nel mondo reale.
Una buona serie di test risponde a domande specifiche e riduce al minimo il numero di variabili confondenti.
Tra gli esempi di domande d'esame mirate e relative serie di test figurano:
- Il nostro modello funziona bene con le recensioni di Yelp? Abbiamo testato un campione composto da mille recensioni reali di Yelp e mille recensioni di Yelp generate dall'intelligenza artificiale.
- Il nostro modello funziona bene con i testi parafrasati? Abbiamo testato il modello su centinaia di saggi scritti da studenti reali, centinaia di saggi generati dall'IA e gli stessi identici saggi parafrasati tramite QuillBot o Undetectable.AI.
Ci sono diversi motivi per cui non è possibile limitarsi a mettere insieme tutti i dati del set di test e riportare un semplice numero.
- Ci sono troppe variabili di confondimento: non sappiamo se il test abbia avuto esito positivo o negativo a causa della distribuzione dei dati o del modello.
- Chiunque può gonfiare artificialmente il proprio punteggio di accuratezza semplicemente riempiendo il set di test di esempi facili.
- Senza una spiegazione trasparente e verificabile su come sia stato creato il set di test in modo imparziale, non possiamo sapere se qualcuno abbia semplicemente selezionato a proprio piacimento esempi su cui il proprio modello ha successo e su cui il modello di riferimento fallisce.
Ecco perché studi di benchmark come questi mancano completamente l'obiettivo. Sono vaghi e non mettono alla prova i comportamenti specifici che vorremmo che il modello mettesse in atto. I set di test distorti mettono in luce il modello solo quando questo dà il meglio di sé, non quando si trova ad affrontare esempi del mondo reale.
Un confronto imparziale su Yelp
Un esempio di applicazione pratica del rilevamento di testi generati dall'IA è l'individuazione delle recensioni create dall'IA su Yelp. Yelp si impegna a moderare rigorosamente la propria piattaforma di recensioni e, consultando il suo Rapporto sulla fiducia e la sicurezza del 2022, risulta evidente che Yelp attribuisce grande importanza alla lotta contro le recensioni fraudolente, pagate, incentivato o comunque in malafede.
Fortunatamente, Yelp ha anche pubblicato un eccellente set di dati open source. Abbiamo selezionato in modo casuale 1000 recensioni da questo set di dati e ne abbiamo generate altre 1000 sintetiche tramite ChatGPT, il modello di linguaggio di grandi dimensioni (LLM) più utilizzato.
È importante sottolineare che le recensioni di ChatGPT riguardano attività commerciali reali presenti su Yelp, tratte dal loro dataset Kaggle: in questo modo il modello non può "barare" adattandosi eccessivamente a dettagli quali, ad esempio, una diversa distribuzione delle attività commerciali. Durante la fase di valutazione, verifichiamo se il modello abbia effettivamente imparato a utilizzare le caratteristiche corrette presenti nel testo per distinguere le recensioni autentiche da quelle false.
Utilizziamo questo set di dati per capire quali modelli di rilevamento basati sull'intelligenza artificiale siano davvero in grado di distinguere le recensioni generate da ChatGPT da quelle autentiche!
Precisione dei modelli
Il nostro indicatore più semplice è l'accuratezza: quanti esempi è riuscito a classificare correttamente ciascun modello?
- Checkfor.ai: 99,85% (1997/2000)
- Originality.AI: 96,2% (1738/1806) (nota: Originality.AI non classifica i documenti con meno di 50 parole).
- GPTZero: 90,8% (1815/2000)
Sebbene una differenza tra il 99,85% e il 96% possa inizialmente non sembrare significativa, se si tiene conto del tasso di errore è possibile contestualizzare meglio questi dati.
Si prevede che Checkfor.ai dia un risultato errato solo una volta ogni 666 query, mentre Originality.AI dovrebbe farlo una volta ogni 26 query e GPTZero una volta ogni 11 query. Ciò significa che il nostro tasso di errore è oltre 25 volte migliore rispetto a quello di Originality.AI e 60 volte migliore rispetto a quello di GPTZero.
Falsi positivi e falsi negativi
Per analizzare i falsi positivi e i falsi negativi (nel gergo dell'apprendimento automatico, si tratterebbe delle statistiche molto simili denominate "precisione" e "richiamo"), possiamo esaminare la matrice di confusione: quali sono le percentuali relative di veri positivi, falsi positivi, veri negativi e falsi negativi?

Over all 2,000 examples, Checkfor.ai produces 0 false positives and 3 false negatives, exhibiting high precision and high recall. While admirably, GPTZero does not often predict false positives, with only 2 false positives, it comes at the expense of predicting 183 false negatives– an incredibly high false negative rate! We’d call this a model that exhibits high precision but low recall. Finally, Originality.AI predicts 60 false positives and 8 false negatives– and it refuses to predict a likelihood on short reviews (<50 words) — which are the hardest cases and most likely to be false positives. This high false positive rate means that this model is low precision, high recall.
Sebbene nel rilevamento di testi generati dall'IA sia più importante un basso tasso di falsi positivi (non vogliamo accusare ingiustamente persone reali di aver plagiato da ChatGPT), è necessario anche un basso tasso di falsi negativi: non possiamo permettere che oltre il 10-20% dei contenuti generati dall'IA sfugga ai controlli.
Fiducia nel modello
In definitiva, vorremmo che il nostro modello esprimesse un alto livello di sicurezza quando è chiaro che il testo è stato scritto da un essere umano o da ChatGPT.
Seguendo una strategia di visualizzazione simile a quella adottata nell'eccellente articolo accademico DetectGPT di Mitchell et al., tracciamo gli istogrammi delle previsioni dei modelli sia per le recensioni generate dall'IA che per quelle reali, per tutti e tre i modelli. Poiché tutti e tre i modelli hanno un'accuratezza superiore al 90%, una scala logaritmica sull'asse y risulta la più utile per visualizzare le caratteristiche del livello di confidenza di ciascun modello.

In questo grafico, l'asse x rappresenta la probabilità che il modello preveda che la recensione inserita sia stata generata dall'IA. L'asse y rappresenta la frequenza con cui il modello prevede quella particolare probabilità per i testi reali (barre blu) o generati dall'IA (barre rosse). Osservando queste previsioni "soft", anziché limitarsi a un semplice sì o no, Checkfor.ai è molto più efficace nel tracciare un confine decisionale chiaro e nel fornire previsioni più affidabili rispetto a GPTZero o Originality.AI.
GPTZero tende a prevedere un numero eccessivo di esempi nell'intervallo di probabilità compreso tra 0,4 e 0,6, con una moda proprio intorno a 0,5. D'altra parte, il problema dei falsi positivi di Originality.AI diventa ancora più evidente quando si esaminano le previsioni "soft". Molte recensioni reali rischiano di essere classificate come generate dall'IA, anche se non superano la soglia di 0,5. Ciò rende difficile per un utente fidarsi della capacità del modello di prevedere in modo affidabile i testi generati dall'IA, poiché piccole modifiche alla recensione possono consentire a un malintenzionato di aggirare il rilevatore modificando ripetutamente la recensione fino a quando non scende al di sotto della soglia di rilevamento.
Il nostro modello, invece, è solitamente molto deciso. In genere siamo in grado di prendere decisioni con sicurezza. Per i lettori con una formazione nel campo del deep learning o della teoria dell'informazione, la nostra entropia incrociata/divergenza di KL tra la distribuzione reale e quella prevista è la più bassa.
È indubbiamente utile riuscire a identificare con elevata certezza i testi autentici come tali (si veda questa divertente immagine tratta da Twitter). Sebbene sia evidente che questo docente abbia frainteso la probabilità indicata dall'IA come la percentuale di testo scritto dall'IA, quando i sistemi di rilevamento non sono certi dell'autenticità di un testo, si crea il rischio di interpretazioni errate.
 https://twitter.com/rustykitty_/status/1709316764868153537
https://twitter.com/rustykitty_/status/1709316764868153537
Dei 3 errori segnalati da Checkfor.ai, purtroppo due risultano piuttosto certi. Il nostro sistema di rilevamento non è perfetto e stiamo lavorando attivamente alla calibrazione del modello per evitare che si verifichino errori di questo tipo.
Conclusione
Stiamo rendendo disponibili in open source i set di dati utilizzati per questa valutazione delle recensioni su Yelp, sia autentiche che false, in modo che i modelli futuri possano avvalersi di questo importante punto di riferimento per verificare l'accuratezza dei propri sistemi di rilevamento.
I punti salienti sono i seguenti:
Checkfor.ai presenta sia un basso tasso di falsi positivi che un basso tasso di falsi negativi. Checkfor.ai è in grado di distinguere le recensioni autentiche da quelle generate dall'intelligenza artificiale non solo con elevata precisione, ma anche con un alto grado di affidabilità. In futuro pubblicheremo altri articoli di questo tipo sul blog e condivideremo pubblicamente le nostre valutazioni sincere sul nostro modello man mano che acquisiremo maggiori informazioni. Restate sintonizzati e fateci sapere cosa ne pensate!

Bradley è un ricercatore nel campo dell'intelligenza artificiale ed è esperto nello sviluppo di prodotti basati sul deep learning per il settore industriale. Recentemente ha guidato il gruppo di ricerca sul deep learning presso Absci, un'azienda che si occupa di scoperta di farmaci tramite intelligenza artificiale generativa, mentre in precedenza ha fatto parte del team principale di visione artificiale di Tesla Autopilot.
Durante gli studi universitari, Bradley è stato autore di numerose pubblicazioni nel campo della ricerca sul deep learning presso lo Stanford Vision Lab. Ha conseguito una laurea in fisica e un master in intelligenza artificiale presso l'Università di Stanford. Oltre all'intelligenza artificiale, nutre un grande interesse per l'istruzione e la filosofia ed è un appassionato giocatore di golf.
Altre letture

Come si posiziona Pangram rispetto a GPTZero?
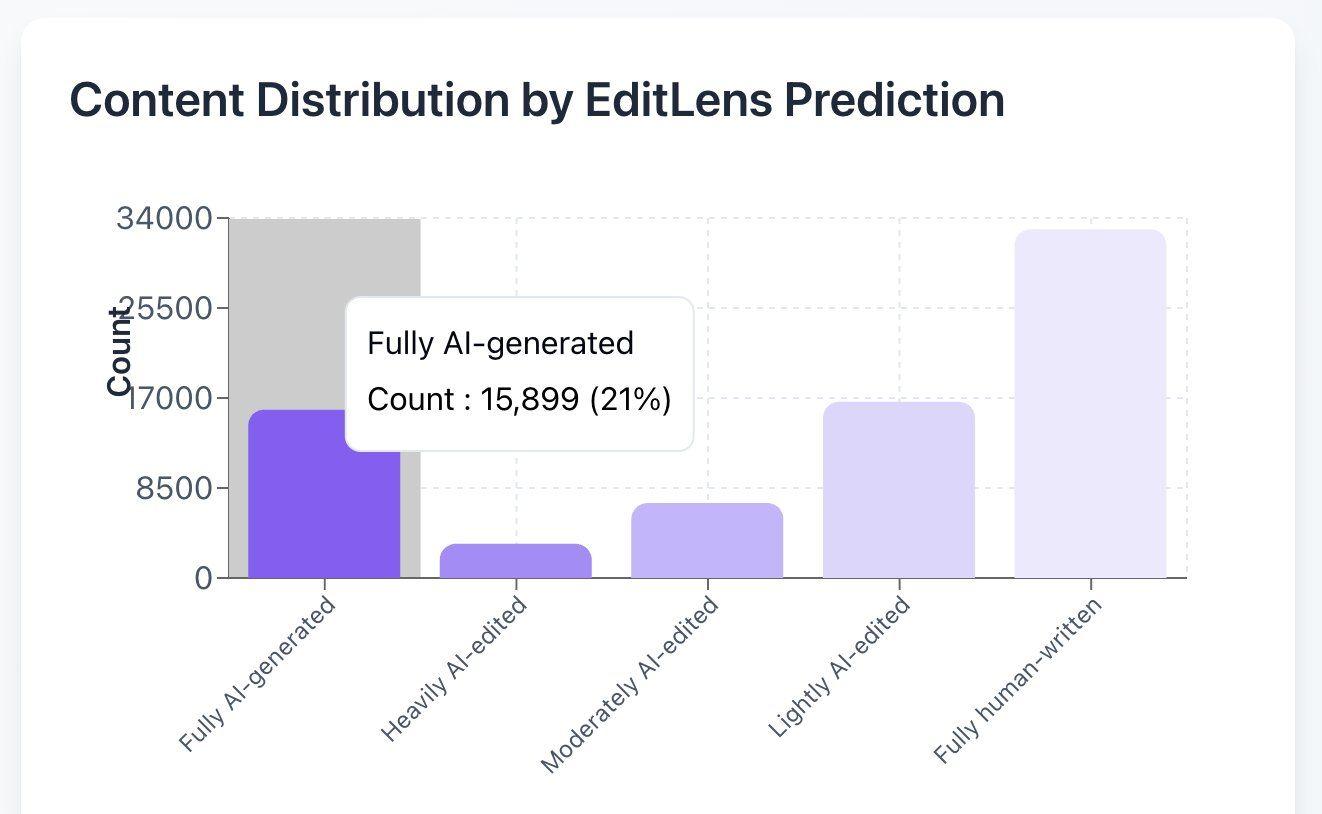
Pangram prevede che il 21% delle recensioni dell'ICLR sia generato dall'intelligenza artificiale

Come riconoscere le recensioni generate dall'intelligenza artificiale

Valutazioni di pangrammi effettuate da terzi

Rendere la tua azienda a prova di LLM e GenAI

L'intelligenza artificiale sta scrivendo romanzi premiati
per ricevere i nostri aggiornamenti
