
Seeing in Pangram Space
Exploring the internal representations of Pangram 3.3.2
By Elyas Masrour, Katherine Thai, and Bradley Emi
June 2026
Introduction
Since ChatGPT’s debut in 2022, AI-assisted writing has expanded at a staggering pace. Because AI-generated text now appears across so much of what we read, it has become obvious that some forms of writing lose their value when produced by a machine. In academia, essays are meant to cultivate student reasoning. In the marketplace, product reviews are valuable because they reflect the experiences of other people.
Pangram is a research company that builds state-of-the-art AI detection models for this problem. Our flagship product is an AI text detection model with industry-leading low false positive rates, multilingual capabilities, and differentiation between AI-generation and AI-assistance.
Since the launch of our first whitepaper in 2024, we’ve had a unique seat to watch wave after wave of AI advancements. Our researchers have wrestled with overly strict content filters, seen our fair share of mode collapse, and dodged waves of em-dashes and the word “delve”.
Our flagship model is an LLM that is fine-tuned to this sequence classification task. We do not use custom metrics like perplexity or burstiness. We do not do any manual feature extraction. We do have a customer-facing product called AI Phrases, where we provide information to our users about phrases that appear more frequently in AI text. But these are not directly used as features for the model. After a while, one gets curious. What does the model see?
For us as researchers, this question matters. We are highly incentivized to prevent shortcutting, fix unintended model behavior, and understand this problem deeply. In this post, we will outline our initial interpretability efforts using document-level analysis.
Data
We built an interpretability dataset from in-domain held-out samples from our production training set. The interactive explorer on this page uses a balanced 5,000-document subset, evenly split between human and AI, across 20 even-numbered layers. The AI samples span the model variants below across the six model families used for the classifier probe.
Models
- Claude 3.7 Sonnet
- Claude Sonnet 4
- Claude Sonnet 4.5
- Claude Opus 4
- Claude Opus 4.1
- Claude Opus 4.5
- GPT-3.5 Turbo (Nov ’23)
- GPT-3.5 Turbo (Jan ’24)
- GPT-4 (Mar ’23)
- GPT-4 (Jun ’23)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- Qwen 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
Source domains
- News
- Scientific Abstracts
- Product Reviews
- Business Reviews
- Reddit Creative Writing
- Reddit ELI5
- Books (Self-Published)
- Books (Project Gutenberg)
- Wikipedia (English)
- Wikipedia (Multilingual)
- Lang-8 (ESL)
Pangram 3.3.2 Overview
Pangram 3.3.2 is an AI detection model released by Pangram Labs in 2026. It uses the same underlying model as Pangram 3.3, with later bug fixes that improve performance. Pangram 3.3 succeeded Pangram 3.2 and improved recall on newer LLM outputs, humanized text, and long-form AI-generated content, while reducing false positives on non-native English writing.
Model cardRead the Pangram 3.3 model cardSee the release details behind Pangram 3.3.2.Read articleInterpretability work is ongoing. Throughout this article, we also apply our methods retroactively to Pangram 3.2 and Pangram 3.1.
Methods
Activations
The EditLens architecture is a bucket-based classification system that collapses into a single ai_assistance_score. For this project, we discard the model’s final readout, and instead focus on the internal representations the model learns. To probe these, we collect activations by completing a forward pass of a model with a given input document, and saving the model’s hidden representation at multiple internal layers. For this project, we extracted activations for every document, for every even layer throughout the network.
Dimensionality Reduction
Each extracted activation vector was 5,120-dimensional. To gain a better understanding of the representations, we employ a number of dimensionality reduction techniques.
PCA
Principal Component Analysis (PCA) is the simplest linear projection: it finds directions of maximum variance in the activation space. In this project, we find that towards the end of the network, most variance is contained within principal components 1 and 2, and as such we plot them against each other.
UMAP
UMAP gives a nonlinear view designed to preserve neighborhood structure. If two documents are close together in the model’s internal space, UMAP tries to keep them close in 2D space. However, the exact axes and distances between clusters should not be over-interpreted.
t-SNE
t-SNE is another nonlinear projection method that is good at revealing local clusters. For the purposes in this project, we use t-SNE to ask whether groups that matter semantically, such as model families or human/AI labels, become visibly clustered as the network deepens.
Linear Probes
We use linear probes to quantify the qualitative results we observe from our dimensionality reduction methods. For each layer, we ask whether a simple classifier can recover a target label from that layer’s activation vectors. High probe accuracy means the relevant distinction is already encoded in a linearly accessible direction of the representation space.
The AI Detection Task
Binary Accuracy
To understand how the final class separation is achieved over the course of the network, we train linear probes at each layer. We train on 500 samples, evenly split between human and AI, with an 80:20 train/test split. We find that, even early on in the network, performance is already strong: we achieve a 0.83 accuracy directly after layer 2. This matches our intuition, as “bag-of-words” models are often serviceable baselines for the AI detection task. Throughout the network, the accuracy strengthens until topping out at 1.0 at layer 24.
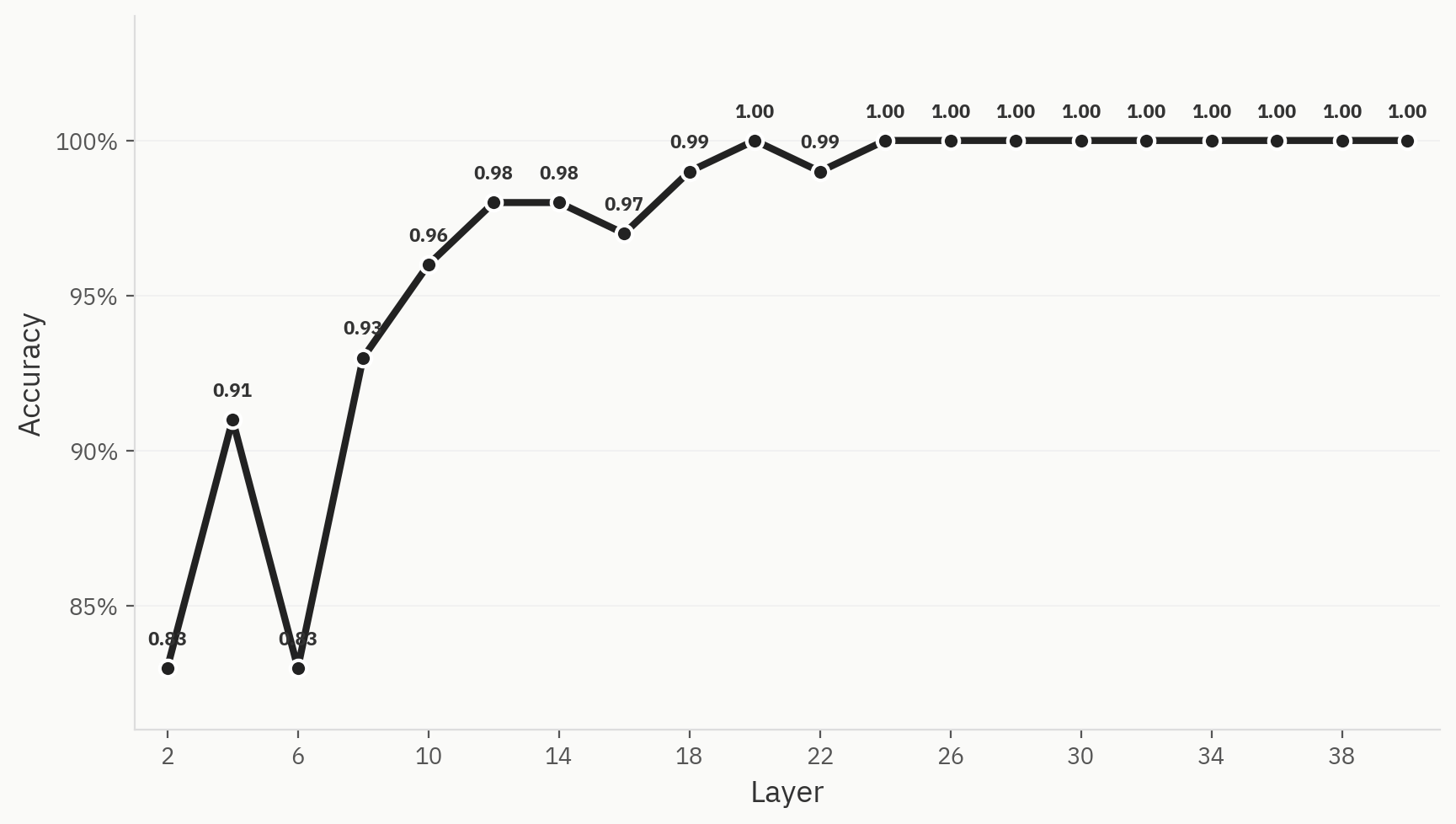
Fig. 3 This separation is clearly visible in all three dimensionality reduction methods.
LLM Classification
In the t-SNE and UMAP plots, we noticed that documents appeared to cluster by the model that generated them. This was a surprise to us. Old iterations of Pangram had a separate LLM-classifier head, but that particular task had long been dropped. In its training process, Pangram 3.3.2 is given no labels corresponding to the originating model of an AI document.
Even so, clusters formed around the originating model family. Even more interesting, the clusters seem to emerge throughout the layers of the network.
Model Cluster Emergence
Color the same embeddings by model family to see provider-level geometry appear across layers.
Fig. 4 Layer 2-40 embeddings colored by model family. Provider-level clusters become more visible across later layers.
Probe
To quantify this phenomenon, we train a classifier across six model families (Anthropic, OpenAI, Google, Qwen, Llama, DeepSeek) on 500 samples per model family, and 3,000 samples overall, at an 80:20 train/test split. We find that we can indeed train a probe capable of classifying the originating model family of a particular document using Pangram activations only, with a maximum top-1 accuracy of 91%.
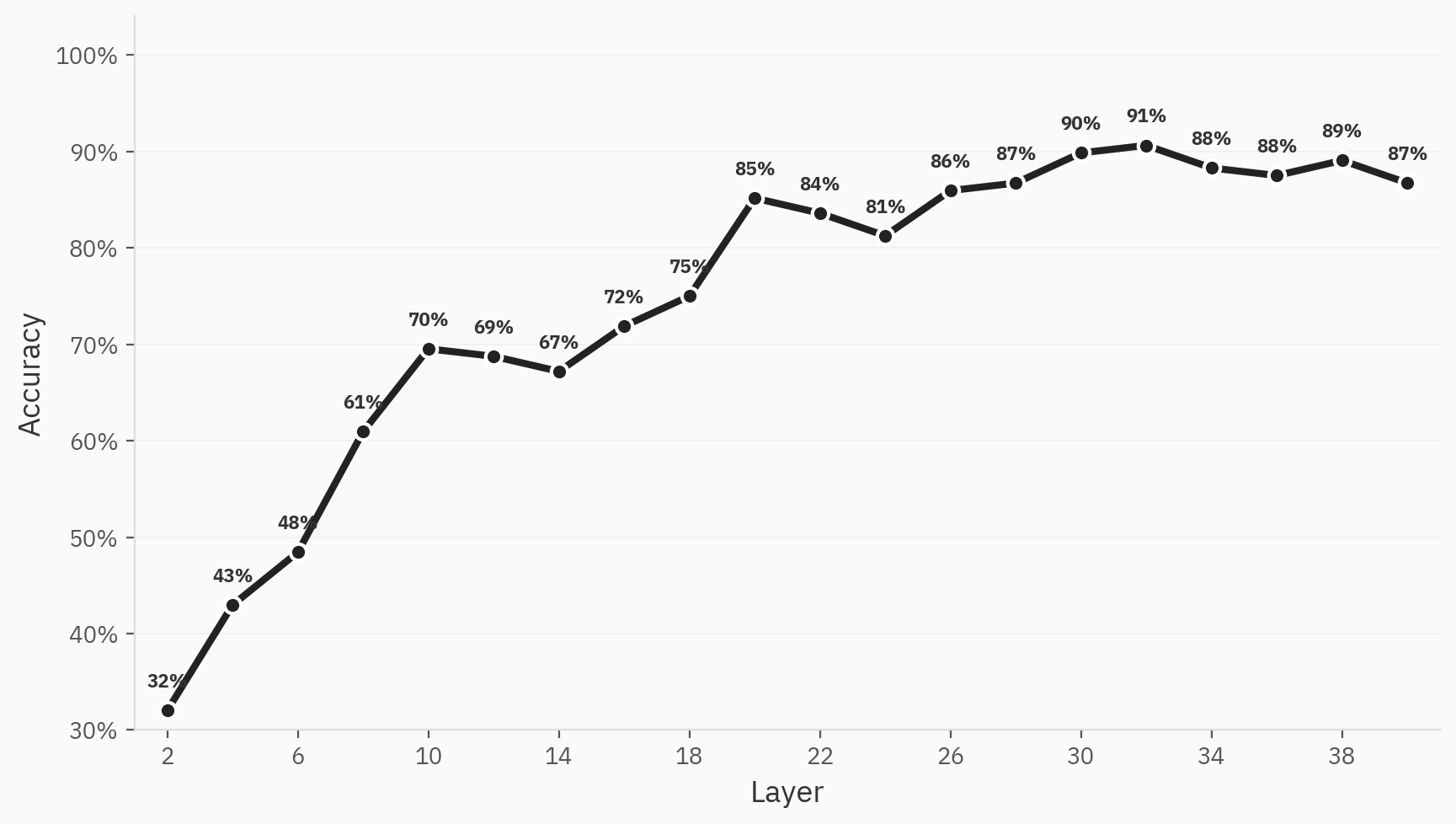
Emergence is Not Guaranteed
Our initial interpretability experiments included testing with a number of models. To our surprise, the emergence of an “LLM classification” ability was one of the only findings from this project that materially differed across models.
The figure below compares the clustering behavior of Pangram 3.1, 3.2, and 3.3.2. Despite the model performing better than 3.1 on the binary human-AI task in our internal signoff evals, the model clusters in general are less defined on Pangram 3.2 than in Pangram 3.1 or 3.3.2.
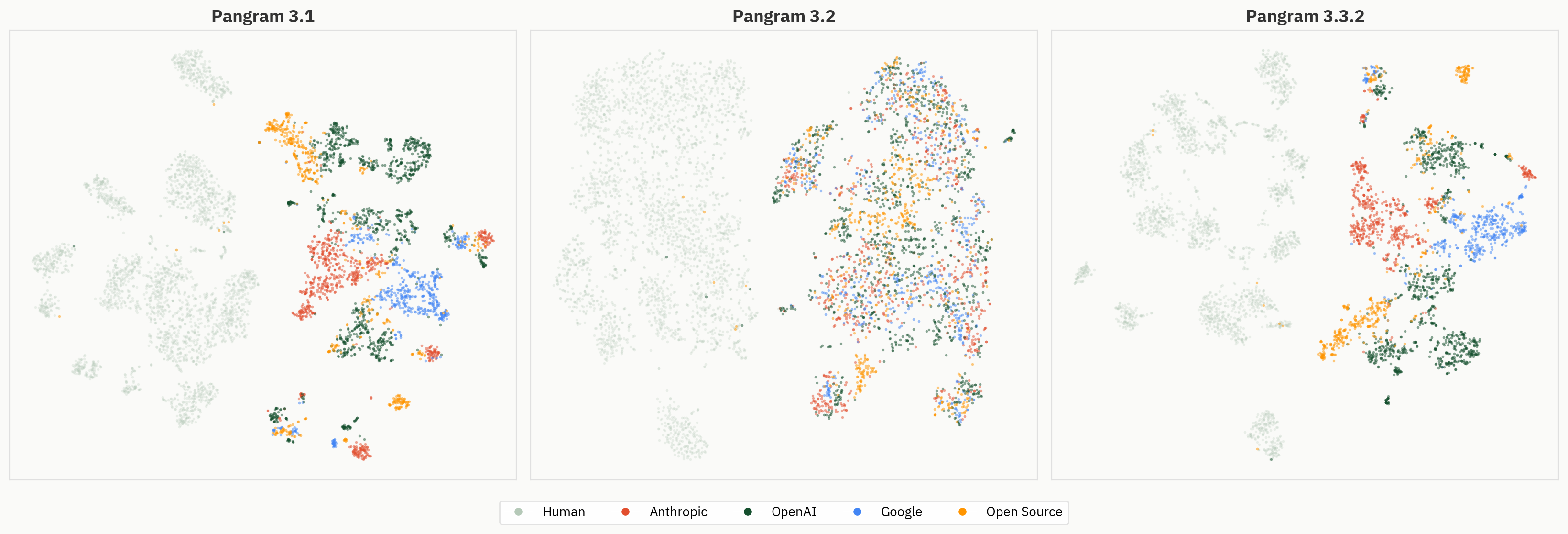
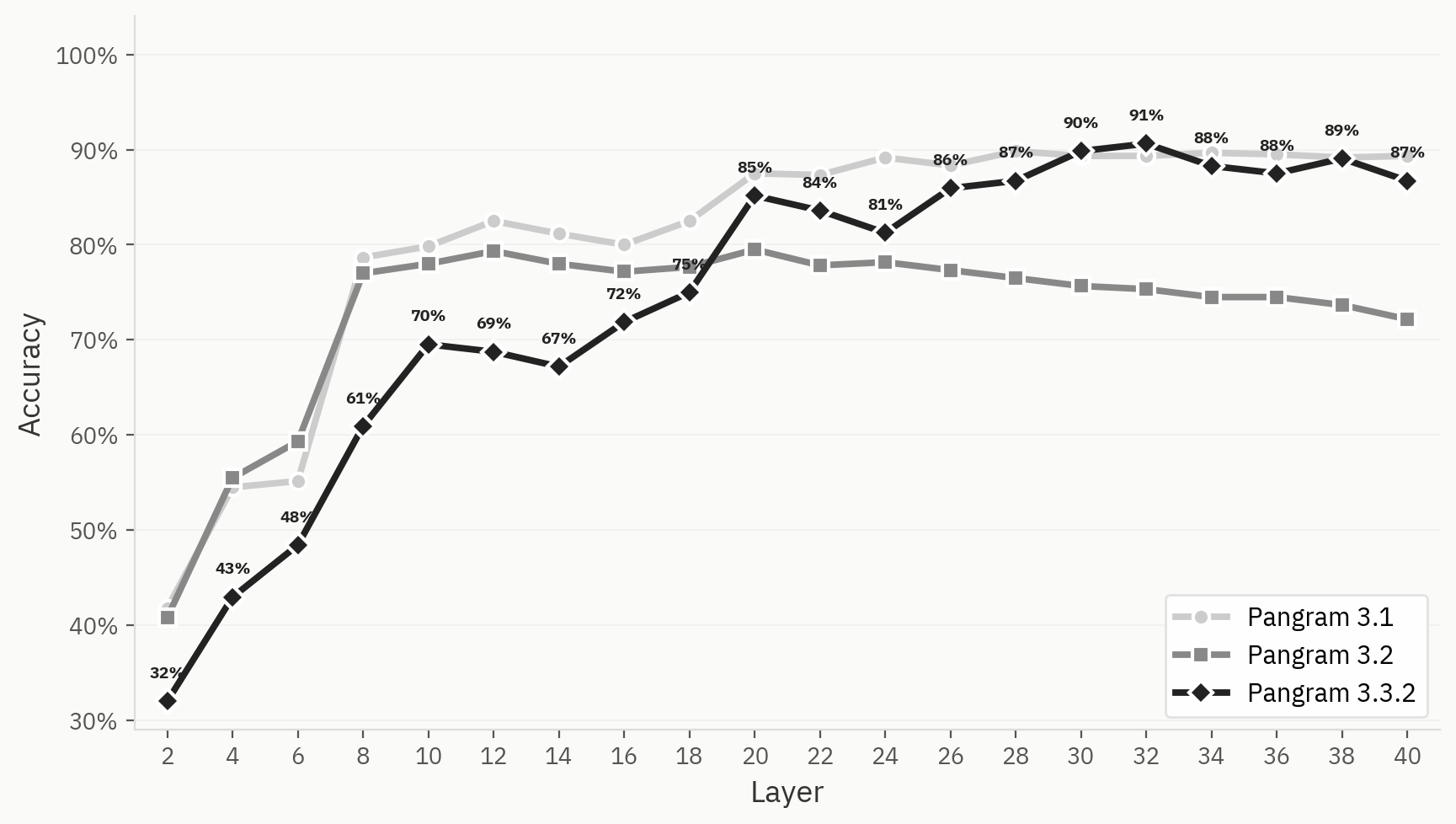
To further illustrate this difference, we compare the LLM classifier probe across Pangram 3.1, 3.2, and 3.3.2. All three improve their top-1 accuracy in early layers, but the probe for Pangram 3.2 starts to decay after layer 12 while Pangram 3.1 and 3.3.2 remain high.
Humanizers
Humanizers are a class of adversarial tools designed to modify AI-generated text in a manner that evades AI detectors. To see where humanized text sits relative to human and AI text in activation space, we created a separate humanizers dataset, which consists of roughly 1,900 samples, roughly balanced across three generative models (Claude Sonnet 4.5, Gemini 2.5 Pro, and GPT-5), ten different humanizer services, and the same source domains as the original interpretability dataset. Because of the adversarial risks, we do not disclose which services we use.
How the Model Reads Out Humanizers
Certain samples from our humanizer dataset are indeed challenging for our model to detect. Here, we use the same linear probe for the human/AI task, except with humanized text labelled as AI, as we do in the original training setup. We see that even from the first layer, humanized text is consistently read out as more human than its direct AI counterpart.
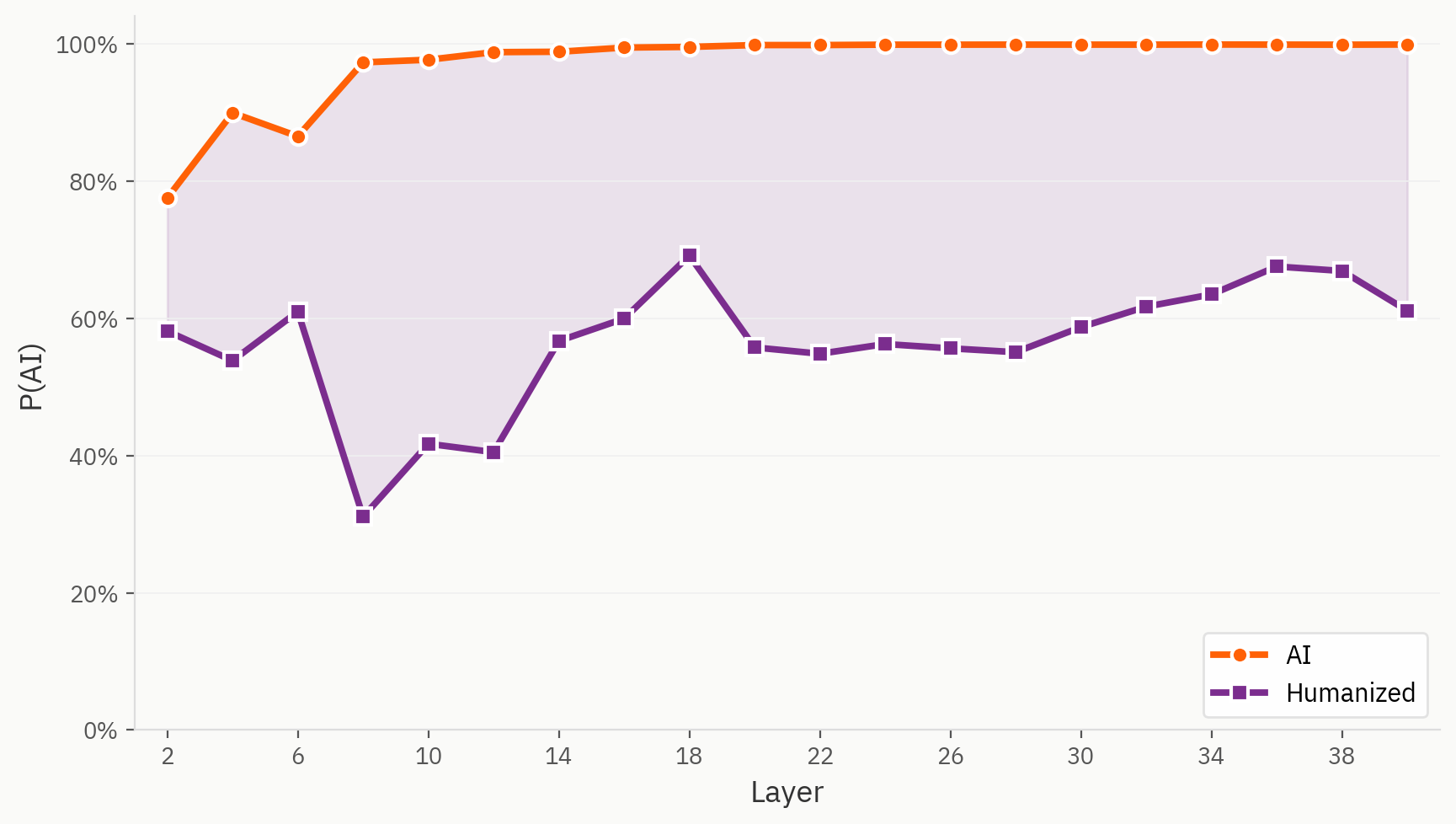
Where Humanizers Exist in Embedding Space
However, when we look beneath the final readout, we find a much richer representation of humanized text. Below, we apply our dimensionality reduction methods to the human, AI, and humanized texts. Qualitatively, we can observe that humanizers tend to occupy separate parts of activation space, and form clusters outside of the human and AI regions.
Our hypothesis is that despite not having labels for humanized text, the model is capable of distinguishing between humanized, human, and AI text. However, in the final readout, the model is forced to collapse that signal and does so inconsistently.
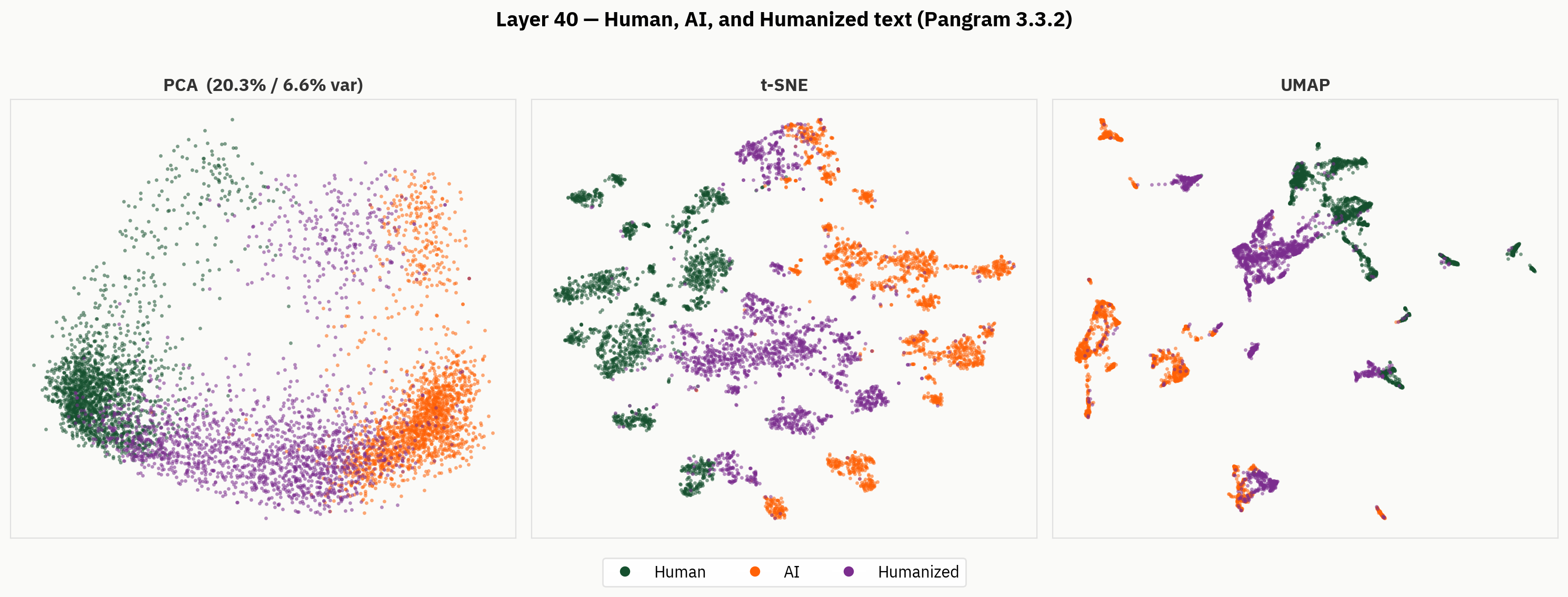
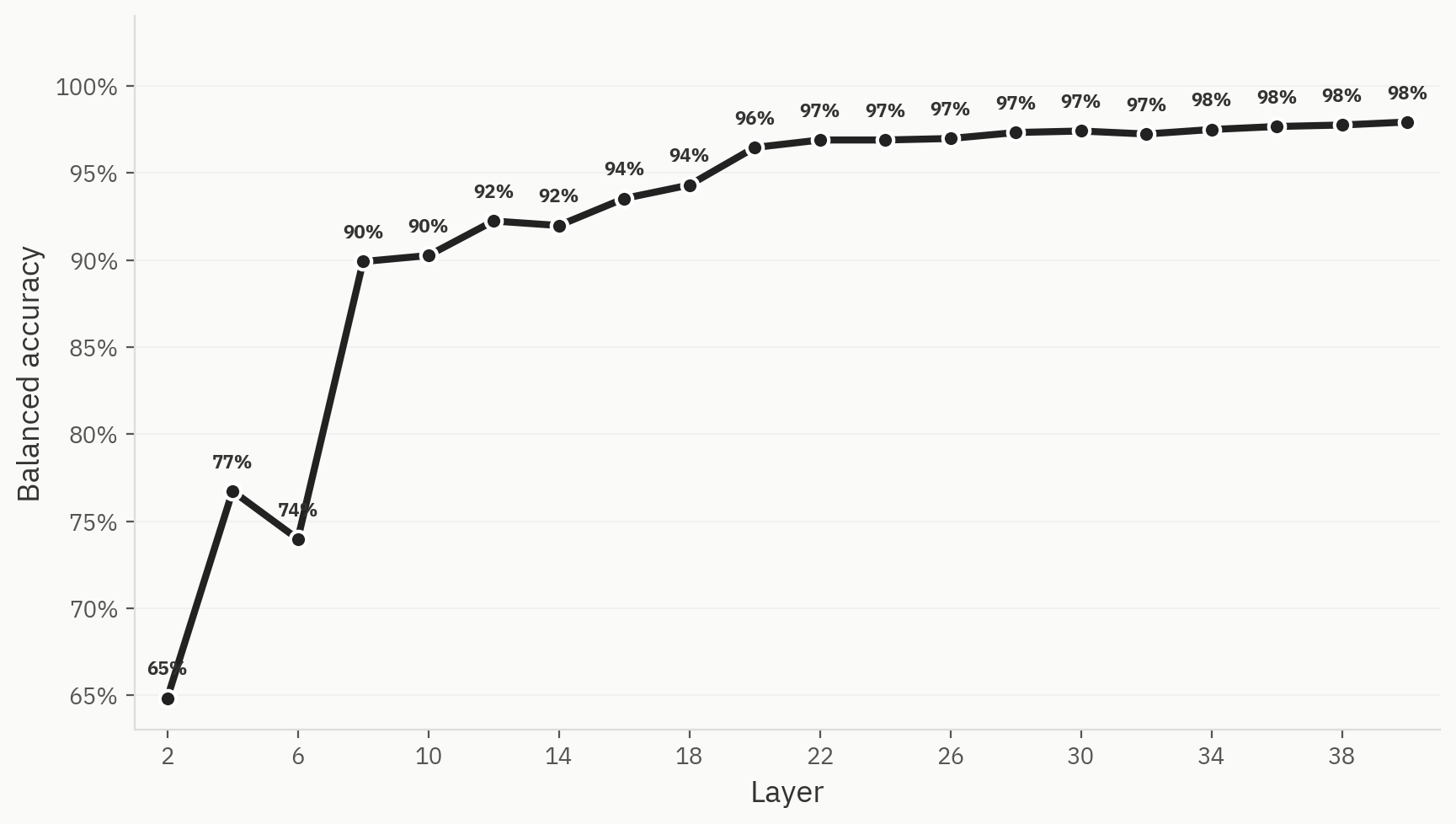
Probe
To validate this hypothesis, we train a three-way linear probe with labels for AI, human, and humanized text. The probe reaches high top-1 accuracy early in the network and eventually flattens out at 98%.
Conclusion
Our work here suggests that Pangram’s internal representations contain more structure than the final binary readout alone reveals. Across layers, we see human and AI documents separate, model-family information emerge, and humanized text occupy its own region of activation space. These findings are early, but they give us a useful map for understanding what the model learns before it collapses everything into a single detection score.
This post shows just the first steps in our interpretability efforts, but internally, we are excited and interested in this research direction.
Our vision for interpretability and explainability with Pangram models is that it can:
- Provide better internal understanding of model behavior.
- Provide supporting evidence and clearer explanations for individual Pangram results.
If you are a researcher interested in interpretability, AI detection research, or anything else in this work, please reach out to elyas@pangram.com.
