Os artigos para conferências sobre IA são cada vez mais redigidos por IA: um aumento de 370 % desde 2023
 Um gráfico que ilustra a percentagem de resumos gerados por IA submetidos à ICLR por ano, revelando uma tendência ascendente desde 2023.
Um gráfico que ilustra a percentagem de resumos gerados por IA submetidos à ICLR por ano, revelando uma tendência ascendente desde 2023.
Em fevereiro de 2024, um artigo publicado na revista «Frontiers in Cell and Developmental Biology» apresentava imagens que eram claramente geradas por IA. Este artigo em particular ganhou destaque na imprensa, uma vez que uma das imagens mostrava um rato com testículos absurdamente grandes e um texto sem sentido que não fazia qualquer sentido.
Este é um artigo científico publicado na revista «Frontiers in Cell and Developmental Biology». As figuras foram, obviamente, geradas por IA. Uma delas mostra um rato com testículos absurdamente grandes. O texto nas figuras é incompreensível. pic.twitter.com/4Acn2YZYwM
— Cliff Swan (@cliff_swan) 15 de fevereiro de 2024
Embora a revisão por pares (em teoria) deva ser suficiente para detectar casos óbvios como este, o que acontece quando o próprio conteúdo do artigo é gerado por IA? Até mesmo os especialistas têm dificuldade em distinguir a investigação gerada por IA da investigação escrita por humanos.
Uma reportagem recente da revista *Nature* destaca a crescente preocupação em relação ao conteúdo gerado por IA em artigos académicos. O artigo aborda um estudo em que cientistas da computação utilizaram o Claude 3.5, um dos mais recentes modelos de linguagem de grande escala (LLM), para gerar ideias de investigação e redigir artigos, que foram posteriormente apresentados a revisores científicos. Estes revisores avaliaram os artigos com base em «novidade, interesse, viabilidade e eficácia esperada». Em média, verificou-se que os revisores atribuíram pontuações mais elevadas aos artigos gerados por IA do que aos artigos escritos por humanos! Isto leva à questão: será que a IA realmente apresenta melhores ideias de investigação do que os humanos? Embora seja tentador acreditar que este possa ser o caso, dos 4.000 artigos gerados por IA estudados pelos investigadores, apenas 200 deles (5%) continham realmente alguma ideia original: a maioria dos artigos limitava-se a repetir ideias já existentes do conjunto de treino do LLM.
Em última análise, a investigação gerada por IA prejudica a comunidade ao introduzir ruído e reduzir a qualidade do sinal no processo de revisão por pares, para não falar do desperdício de tempo e esforço dos revisores que se empenham em defender os padrões da investigação. Além disso, o que é ainda pior é que a investigação gerada por IA muitas vezes parece convincente, mas, na realidade, o texto produzido por um modelo de linguagem apenas soa fluente e pode estar repleto de erros, alucinações e inconsistências lógicas. A preocupação aqui é que mesmo os revisores especialistas muitas vezes não conseguem sequer perceber quando o que estão a ler é uma alucinação de um LLM.
Os organizadores das principais conferências sobre aprendizagem automática concordam connosco: não há lugar para textos gerados por modelos de linguagem de grande escala (LLM) na escrita científica. A política oficial da ICML (Conferência Internacional sobre Aprendizagem Automática) é a seguinte:
Esclarecimentos sobre a política relativa aos modelos de linguagem de grande dimensão
Nós (os Coordenadores do Programa) incluímos a seguinte declaração na convocatória de trabalhos para a ICML de 2023:
São proibidos os artigos que incluam texto gerado a partir de um modelo de linguagem em grande escala (LLM), como o ChatGPT, a menos que o texto produzido seja apresentado como parte da análise experimental do artigo.
Esta declaração suscitou uma série de questões por parte de potenciais autores e levou alguns a contactar-nos de forma proativa. Agradecemos o vosso feedback e comentários e gostaríamos de esclarecer melhor a intenção subjacente a esta declaração e a forma como tencionamos implementar esta política para o ICML 2023.
TLDR;
A política relativa aos Modelos de Linguagem de Grande Dimensão (LLM) para a ICML 2023 proíbe textos produzidos inteiramente por LLM (ou seja, «gerados»). Isto não impede os autores de utilizarem LLM para editar ou aperfeiçoar textos escritos por si próprios. A política relativa aos LLM baseia-se, em grande medida, no princípio da cautela no que diz respeito à prevenção de potenciais problemas decorrentes da utilização de LLM, incluindo o plágio.
Apesar deste aviso, constatamos que um número significativo e crescente de autores na área da aprendizagem automática está a violar a política e a utilizar a IA para gerar texto nos seus artigos, mesmo assim.
Avaliar a dimensão do problema
Na Pangram, quisemos avaliar a dimensão deste problema no nosso próprio domínio: a Inteligência Artificial. Propusemo-nos a responder à seguinte questão: os investigadores de IA estão a utilizar o ChatGPT para redigir os seus próprios trabalhos de investigação?
Para estudar este problema, utilizámos a API do OpenReview para extrair os trabalhos submetidos entre 2018 e 2024 em duas das maiores conferências de IA: a ICLR e a NeurIPS.
Em seguida, aplicámos o Detector de IA da Pangram a todos os resumos submetidos a estas conferências. Eis as nossas conclusões:
ICLR
Um gráfico que ilustra a percentagem de resumos gerados por IA submetidos à ICLR por ano, revelando uma tendência ascendente desde 2023.
NeurIPS
 Um gráfico que ilustra a percentagem de resumos gerados por IA submetidos à Neurips por ano, revelando uma tendência ascendente desde 2023.
Um gráfico que ilustra a percentagem de resumos gerados por IA submetidos à Neurips por ano, revelando uma tendência ascendente desde 2023.
Os resultados
Podemos considerar todos os dados anteriores a 2022 como um conjunto de validação para a taxa de falsos positivos do nosso modelo, uma vez que, naquela altura, ainda não existiam modelos de linguagem de grande dimensão. Conforme mostrado nas figuras, prevemos que todos os resumos de conferências de 2022 ou anteriores serão classificados pelo nosso modelo como escritos por humanos. Isto deve inspirar confiança na precisão do nosso modelo: a nossa taxa de falsos positivos é muito boa em resumos científicos, pelo que podemos ter a certeza de que todas as previsões positivas feitas em 2023 e 2024 são verdadeiros positivos.
O que temos visto desde então é extremamente preocupante. Já se realizaram três ciclos de conferências desde o lançamento do ChatGPT, em novembro de 2022.
O primeiro ciclo ocorreu precisamente por volta do lançamento do ChatGPT (ICLR 2023). O prazo de submissão terminou, na verdade, antes do lançamento do ChatGPT, mas os autores tiveram a oportunidade de fazer alterações antes da própria conferência, que decorreu alguns meses após o lançamento do ChatGPT. O que constatámos era o esperado: apenas um punhado de resumos foi escrito por IA (apenas identificámos 2 em vários milhares como tendo sido escritos por IA neste ciclo) e provavelmente foram modificados após o prazo.
O segundo ciclo ocorreu cerca de seis meses depois, o NeuRIPS 2023, cujo prazo de submissão terminou no verão de 2023, para uma conferência a realizar-se em dezembro. Nesta conferência, relatamos que cerca de 1,3% dos resumos submetidos foram gerados por IA: uma fração pequena, mas significativa.
Por fim, no ciclo mais recente, o ICLR 2024, que decorreu há apenas alguns meses, observámos um aumento que chegou aos 4,9%: um crescimento de quase quatro vezes nas revisões geradas por IA em relação ao NeuRIPS 2023!
Estes resultados revelam uma tendência preocupante: não só o número de artigos de conferências gerados por IA submetidos aos principais eventos da área da IA está a aumentar, como esse número cresce a um ritmo cada vez mais acelerado; por outras palavras, o ritmo a que os artigos gerados por IA são submetidos está a acelerar.
Como são os resumos gerados por IA?
Dê uma vista de olhos a alguns destes resumos e veja por si mesmo se parecem com o tipo de texto a que está habituado a ler na literatura científica técnica:
-
No panorama complexo dos dados em rede, compreender os efeitos causais das intervenções constitui um desafio crucial com implicações em vários domínios. As Redes Neurais de Grafos (GNNs) surgiram como uma ferramenta poderosa para captar dependências complexas; no entanto, o potencial da aprendizagem profunda geométrica para a inferência causal em redes baseadas em GNN continua a ser pouco explorado. Este trabalho apresenta três contribuições fundamentais para colmatar esta lacuna. Em primeiro lugar, estabelecemos uma ligação teórica entre a curvatura do grafo e a inferência causal, revelando que as curvaturas negativas colocam desafios na identificação de efeitos causais. Em segundo lugar, com base nesta perspetiva teórica, apresentamos resultados computacionais utilizando a curvatura de Ricci para prever a fiabilidade das estimativas de efeitos causais, demonstrando empiricamente que as regiões de curvatura positiva produzem estimativas mais precisas. Por último, propomos um método que utiliza o fluxo de Ricci para melhorar a estimativa do efeito do tratamento em dados em rede, demonstrando um desempenho superior ao reduzir o erro através do achatamento das arestas na rede. As nossas descobertas abrem novos caminhos para a utilização da geometria na estimativa de efeitos causais, oferecendo insights e ferramentas que melhoram o desempenho das GNNs em tarefas de inferência causal.
-
No domínio dos modelos linguísticos, a codificação de dados é fundamental, influenciando a eficiência e a eficácia do treino dos modelos. A codificação por pares de bytes (BPE) é uma técnica de tokenização de subpalavras bem estabelecida que equilibra a eficiência computacional e a expressividade linguística através da fusão de pares frequentes de bytes ou caracteres. Uma vez que o treino de modelos linguísticos requer recursos computacionais substanciais, propomos o Fusion Token, um método que melhora significativamente a abordagem convencional de codificação por pares de bytes (BPE) na codificação de dados para modelos linguísticos. O Fusion Token emprega uma estratégia computacional mais agressiva em comparação com o BPE, expandindo os grupos de tokens de bigramas para 10-gramas. Notavelmente, com a adição de 1024 tokens ao vocabulário, a taxa de compressão ultrapassa significativamente a de um tokenizador BPE regular com um vocabulário de um milhão. Em geral, o método Fusion Token conduz a melhorias notáveis no desempenho devido a um maior âmbito de dados por unidade de computação. Além disso, uma maior compressão resulta em tempos de inferência mais rápidos devido a um menor número de tokens por cada cadeia de caracteres. Ao dedicar mais recursos computacionais ao processo de construção do tokenizador, o Fusion Token maximiza o potencial dos modelos de linguagem como motores eficientes de compressão de dados, permitindo sistemas de modelação de linguagem mais eficazes.
-
No domínio da geração de movimentos, que evolui rapidamente, o aprimoramento da semântica textual tem sido reconhecido como uma estratégia altamente promissora para a produção de movimentos mais precisos e realistas. No entanto, as técnicas atuais dependem frequentemente de modelos linguísticos extensos para refinar as descrições textuais, sem garantir um alinhamento preciso entre os dados textuais e os dados de movimento. Este desalinhamento conduz frequentemente a uma geração de movimento subótima, limitando o potencial destes métodos. Para resolver esta questão, apresentamos uma nova estrutura denominada SemanticBoost, que visa colmatar a lacuna entre os dados textuais e os dados de movimento. A nossa solução inovadora integra informação semântica suplementar derivada dos próprios dados de movimento, juntamente com uma rede dedicada de redução de ruído, para garantir a coerência semântica e elevar a qualidade geral da geração de movimento. Através de extensas experiências e avaliações, demonstramos que o SemanticBoost supera significativamente os métodos existentes em termos de qualidade de movimento, alinhamento e realismo. Além disso, as nossas conclusões enfatizam o potencial de aproveitar pistas semânticas a partir dos dados de movimento, abrindo novos caminhos para uma geração de movimento mais intuitiva e diversificada.
Reparou em algum padrão? Em primeiro lugar, vemos que todos começam com frases muito semelhantes: «No complexo panorama de», «No domínio de», «No campo em rápida evolução de». Chamamos a isto linguagem artificialmente rebuscada. Já escrevemos anteriormente sobre a frequência com que os LLMs utilizam muitas palavras para produzir muito pouco conteúdo real. Embora isto possa ser desejável para um aluno que tenta atingir um número mínimo de palavras num trabalho de casa, para um leitor técnico que procura consumir investigação, este tipo de linguagem excessivamente prolixa torna o artigo mais difícil e demorado de ler, ao mesmo tempo que torna a mensagem real do artigo menos clara.
Os artigos sobre IA são realmente aceites nas conferências?
Perguntámo-nos se os artigos gerados por IA são efetivamente filtrados pelo processo de revisão por pares ou se alguns deles acabam por escapar.
Para responder a esta questão, analisámos a correlação entre os resumos gerados por IA e as decisões relativas aos artigos na ICLR 2024. (Os artigos de apresentação oral, spotlight e de cartaz são todos considerados «aceites»; as apresentações orais e spotlight são categorias de reconhecimento especial). Eis o que descobrimos:
| Categoria | Porcentagem gerada por IA |
|---|---|
| ICLR 2024 oral | 2.33% |
| Poster da ICLR 2024 | 2.71% |
| Destaque do ICLR 2024 | 1.36% |
| Rejeitado | 5.42% |
Embora a percentagem de artigos gerados por IA que foram aceites seja inferior à percentagem de artigos submetidos, um número significativo conseguiu passar pelo processo de revisão por pares. Isto significa que, embora os revisores possam estar a detetar parte do conteúdo gerado por IA, não estão a detetar tudo.
Notamos que até mesmo algumas comunicações orais e artigos em destaque têm resumos gerados por IA! Interpretando a situação com benevolência, o que poderemos constatar no futuro é que a investigação pode, na verdade, ser de alta qualidade, e que os autores estão simplesmente a recorrer ao ChatGPT para os ajudar a apresentar ou rever melhor o trabalho.
É importante referir que, uma vez que grande parte da comunidade científica não é de língua inglesa, uma das principais aplicações dos LLMs será a tradução de artigos escritos noutras línguas para inglês.
Conclusão
Apesar do pedido explícito da comunidade de IA para que os autores não utilizem o ChatGPT, muitos autores estão a ignorar essa política e a recorrer a modelos de linguagem de grande escala (LLMs) para os ajudar a escrever os seus artigos. O que é ainda mais preocupante é que nem mesmo os especialistas em IA, que atuam como revisores para proteger as conferências contra artigos gerados por LLMs, conseguem detetá-los!
O ChatGPT está a ter repercussões ainda mais amplas em todo o processo académico. Um estudo de caso recente da ICML revelou que entre 6 % e 16 % das próprias revisões por pares foram geradas por IA, e que existe uma correlação positiva entre as revisões por pares geradas por IA e a proximidade da data de envio da revisão em relação ao prazo!
Apelamos à comunidade de IA para que aplique melhor estas políticas e aos autores para que assumam a responsabilidade de garantir que os seus artigos são da autoria humana.
A incursão da IA na escrita literária não se limita à investigação — a IA também está a ganhar prémios de ficção.

Bradley é investigador na área da IA e especialista no desenvolvimento de produtos de aprendizagem profunda no setor industrial. Recentemente, liderou o grupo de investigação em aprendizagem profunda da Absci, uma empresa de descoberta de medicamentos que utiliza IA generativa, e, anteriormente, integrou a equipa principal de visão computacional do Tesla Autopilot.
Enquanto estudante de pós-graduação, Bradley foi autor de várias publicações na área da investigação sobre aprendizagem profunda no Stanford Vision Lab. É licenciado em Física e mestre em Inteligência Artificial pela Universidade de Stanford. Para além da IA, interessa-se também por educação e filosofia, e é um ávido jogador de golfe.
Leitura relacionada
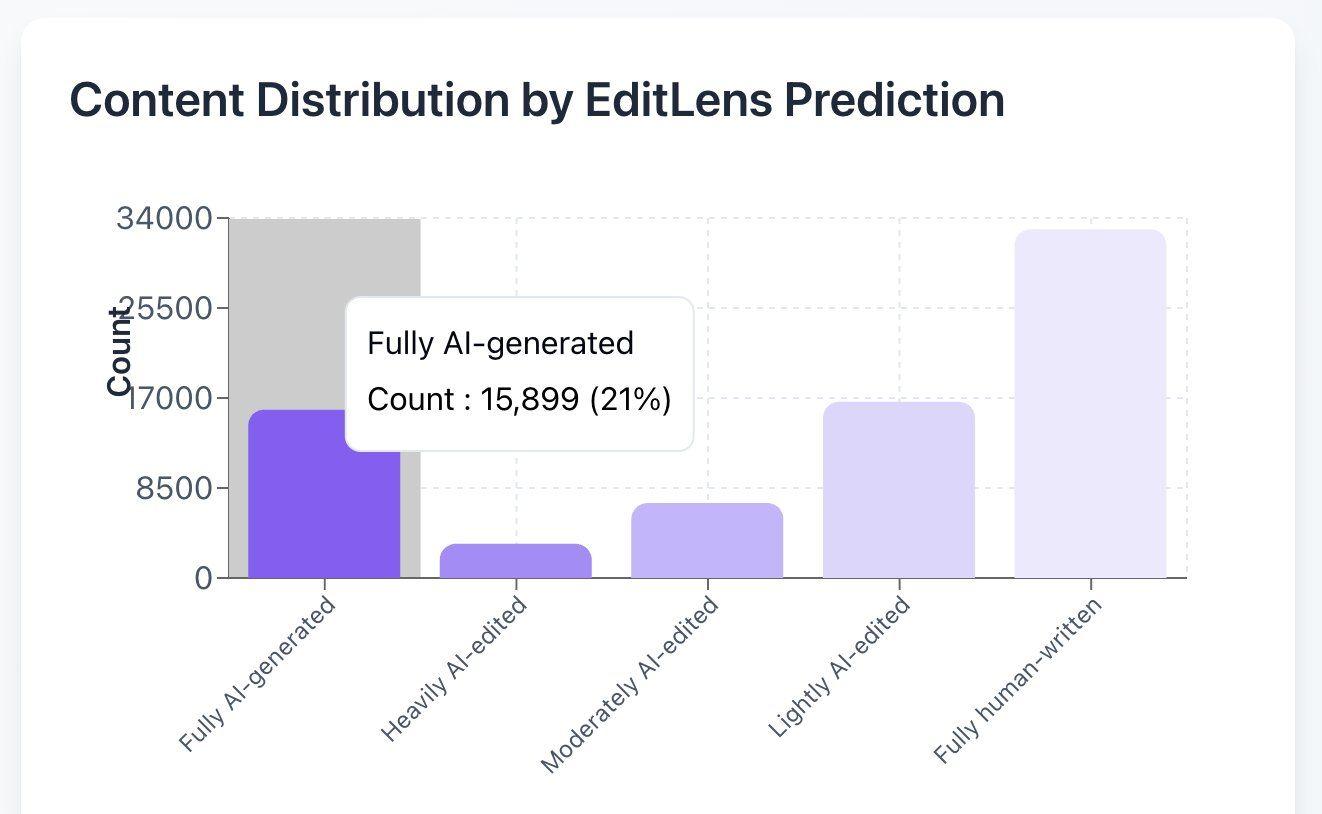
A Pangram prevê que 21% das revisões da ICLR são geradas por IA
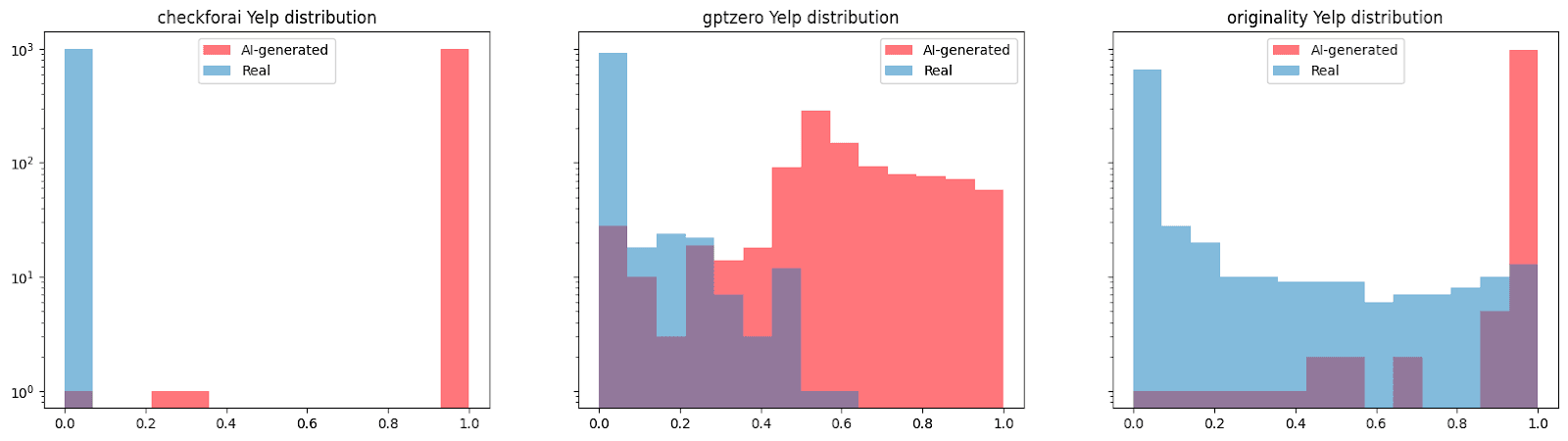
Análise aprofundada das avaliações no Yelp

A IA tem olho para a IA

Três por cento das críticas na primeira página da Amazon são agora geradas por IA

Qual é o detetor de IA mais preciso? 30 ferramentas testadas (2026)

Como preparar a sua empresa para o LLM e a IA Gerativa
para receber as nossas atualizações
