NOTA: Mudámos o nosso nome para Pangram Labs! Consulte a nossa publicação no blogue para mais detalhes.
Na Checkfor.ai, esforçamo-nos por ser o melhor detetor de texto gerado por IA do mercado, com o objetivo de promover a nossa missão de proteger a Internet da poluição causada por conteúdos de baixa qualidade gerados por IA. Uma das áreas mais importantes a defender são as plataformas de avaliações de utilizadores.
As avaliações falsas online acabam por prejudicar tanto as empresas como os consumidores, e o ChatGPT apenas tornou a fraude nas avaliações ainda mais fácil de cometer em grande escala.
 Comentário gerado pelo ChatGPT no Yelp
Comentário gerado pelo ChatGPT no Yelp
Manter a confiança dos utilizadores nas avaliações online é uma parte importante da nossa missão na Checkfor.ai para proteger a autenticidade do conteúdo gerado por pessoas na Internet.
Sobre mim
Chamo-me Bradley Emi e sou o Diretor Técnico (CTO) da Checkfor.ai. Trabalhei como investigador de IA em Stanford, implementei modelos de produção enquanto cientista de aprendizagem automática na equipa do Autopilot da Tesla e liderei uma equipa de investigação que desenvolveu uma plataforma para conceber medicamentos com grandes redes neurais na Absci. Nos carros autónomos e na descoberta de medicamentos, uma precisão de 99% simplesmente não é suficiente. Uma precisão de 99% pode significar que 1 em cada 100 peões é atropelado por um veículo autónomo, ou que 1 em cada 100 doentes sofre efeitos secundários potencialmente fatais devido a um medicamento mal concebido.
Embora a deteção de texto gerado por IA não seja necessariamente uma questão de vida ou morte, queremos conceber, aqui na Checkfor.ai, modelos e sistemas de software que cumpram os mesmos padrões de qualidade. O nosso detetor deve resistir a ataques adversários, tais como a parafraseação, a engenharia avançada de prompts e ferramentas de evasão de deteção, como o undetectable.ai. Levamos a sério a resolução deste problema (ou seja, não nos contentamos em atingir apenas 99%) e, por isso, uma das principais prioridades da nossa equipa de engenharia é desenvolver uma plataforma de avaliação extremamente robusta.
Filosofia de avaliação: os conjuntos de testes são testes unitários
Uma empresa de cibersegurança do tipo «Software 1.0» nunca lançaria um produto sem testes unitários. Como empresa do tipo «Software 2.0», precisamos do equivalente aos testes unitários, só que estes têm de testar modelos de grande dimensão com milhões ou mesmo milhares de milhões de parâmetros, que podem comportar-se de forma estocástica, e que devem funcionar corretamente ao abranger uma ampla distribuição de casos extremos. Não podemos atingir uma «precisão de 99% no conjunto de testes» e dar o assunto por encerrado: precisamos de avaliações que testem especificamente os tipos de exemplos que iremos encontrar no mundo real.
Um bom conjunto de testes responde a perguntas específicas e minimiza o número de variáveis de confusão.
Exemplos de perguntas de teste específicas e dos conjuntos de testes correspondentes incluem:
- Qual é o desempenho do nosso modelo nas avaliações do Yelp? Conjunto de teste composto por mil avaliações reais do Yelp e mil avaliações do Yelp geradas por IA.
- Qual é o desempenho do nosso modelo em textos parafraseados? Conjunto de teste composto por centenas de ensaios reais de estudantes, centenas de ensaios gerados por IA e esses mesmos ensaios parafraseados através do QuillBot ou do Undetectable.AI.
Existem várias razões pelas quais não se pode simplesmente juntar tudo no conjunto de testes e apresentar um número.
- Existem demasiadas variáveis de confusão — não sabemos se o teste foi aprovado ou reprovado devido à distribuição dos dados ou ao modelo.
- Qualquer pessoa pode inflar artificialmente o seu índice de precisão simplesmente enchendo o conjunto de teste com exemplos fáceis.
- Sem uma explicação clara e verificável sobre como o conjunto de testes foi criado de forma imparcial, não podemos saber se alguém simplesmente selecionou exemplos nos quais o seu modelo tem sucesso e a linha de base falha.
É por isso que estudos comparativos como estes falham completamente o alvo. São pouco específicos e não testam comportamentos concretos que pretendemos que o modelo exiba. Conjuntos de testes tendenciosos mostram o modelo no seu melhor, mas não quando este se depara com exemplos do mundo real.
Uma análise comparativa imparcial do Yelp
Um exemplo de aplicação prática da deteção de texto gerado por IA é a deteção de comentários gerados por IA no Yelp. O Yelp está empenhado numa moderação rigorosa da sua plataforma de comentários e, se consultar o seu Relatório de Confiança e Segurança de 2022, poderá constatar que o Yelp se preocupa profundamente com o combate a comentários fraudulentos, pagos, incentivados ou de outra forma desonestos.
Felizmente, o Yelp também disponibilizou um excelente conjunto de dados de código aberto. Selecionámos aleatoriamente 1000 avaliações desse conjunto de dados e gerámos 1000 avaliações sintéticas com o ChatGPT, o LLM mais utilizado.
É importante referir que as avaliações do ChatGPT dizem respeito a empresas reais do Yelp, provenientes do seu conjunto de dados do Kaggle: desta forma, o modelo não pode «fazer batota» ao ajustar-se excessivamente a detalhes como, por exemplo, uma diferença na distribuição das empresas. Durante a avaliação, testamos se o modelo aprendeu realmente a utilizar as características corretas do texto para distinguir o que é real do que é falso.
Utilizamos este conjunto de dados para descobrir quais dos modelos de deteção por IA conseguem realmente distinguir as avaliações geradas pelo ChatGPT das avaliações reais!
Precisão dos modelos
A nossa métrica mais simples é a precisão: quantos exemplos cada modelo classificou corretamente?
- Checkfor.ai: 99,85% (1997/2000)
- Originality.AI: 96,2% (1738/1806) (nota: o Originality.AI não classifica documentos com menos de 50 palavras).
- GPTZero: 90,8% (1815/2000)
Embora uma diferença de 99,85 % em comparação com 96 % possa, à primeira vista, não parecer significativa, quando consideramos a taxa de erro, conseguimos contextualizar melhor estes números.
Estima-se que o Checkfor.ai falhe apenas uma vez em cada 666 consultas, enquanto o Originality.AI falha uma vez em cada 26 consultas e o GPTZero falha uma vez em cada 11 consultas. Isto significa que a nossa taxa de erro é mais de 25 vezes melhor do que a do Originality.AI e 60 vezes melhor do que a do GPTZero.
Falsos positivos e falsos negativos
Para analisar os falsos positivos e os falsos negativos (na terminologia do aprendizado de máquina, consideraríamos as estatísticas muito semelhantes de precisão e recall), podemos examinar a matriz de confusão: quais são as taxas relativas de verdadeiros positivos, falsos positivos, verdadeiros negativos e falsos negativos?

Over all 2,000 examples, Checkfor.ai produces 0 false positives and 3 false negatives, exhibiting high precision and high recall. While admirably, GPTZero does not often predict false positives, with only 2 false positives, it comes at the expense of predicting 183 false negatives– an incredibly high false negative rate! We’d call this a model that exhibits high precision but low recall. Finally, Originality.AI predicts 60 false positives and 8 false negatives– and it refuses to predict a likelihood on short reviews (<50 words) — which are the hardest cases and most likely to be false positives. This high false positive rate means that this model is low precision, high recall.
Embora na deteção de texto por IA seja mais importante uma baixa taxa de falsos positivos (não queremos acusar injustamente pessoas reais de plagiar o ChatGPT), uma baixa taxa de falsos negativos também é necessária — não podemos permitir que mais de 10 a 20 % do conteúdo gerado por IA passe despercebido.
Confiança do modelo
Em última análise, gostaríamos que o nosso modelo demonstrasse um elevado nível de confiança quando for evidente que o texto foi escrito por um ser humano ou pelo ChatGPT.
Seguindo uma estratégia de visualização semelhante à do excelente artigo académico DetectGPT, de Mitchell et al., representamos graficamente os histogramas das previsões dos modelos, tanto para as avaliações geradas por IA como para as avaliações reais, para os três modelos. Uma vez que os três modelos apresentam uma precisão superior a 90%, uma escala logarítmica no eixo Y é a mais útil para visualizar as características da confiança de cada modelo.

Neste gráfico, o eixo x representa a probabilidade de o modelo prever que a crítica introduzida foi gerada por IA. O eixo y representa a frequência com que o modelo prevê essa probabilidade específica para texto real (barras azuis) ou texto gerado por IA (barras vermelhas). Vemos que, ao analisar estas previsões «suaves», em vez de apenas um sim ou um não, o Checkfor.ai é muito mais eficaz a traçar um limite de decisão claro e a fazer previsões mais confiáveis do que o GPTZero ou o Originality.AI.
O GPTZero tende a prever demasiados exemplos na faixa de probabilidade de 0,4–0,6, com um modo mesmo em torno de 0,5. Por outro lado, o problema dos falsos positivos do Originality.AI torna-se ainda mais evidente quando se analisam as previsões menos evidentes. Muitas avaliações reais estão muito perto de serem previstas como geradas por IA, mesmo que não ultrapassem o limiar de 0,5. Isto torna difícil para um utilizador confiar que o modelo pode prever de forma fiável texto gerado por IA, uma vez que pequenas alterações na avaliação podem permitir que um adversário contorne o detetor, editando a avaliação iterativamente até que esta fique abaixo do limiar de deteção.
O nosso modelo, por outro lado, costuma ser muito decisivo. Em geral, conseguimos tomar decisões com segurança. Para os leitores com conhecimentos de aprendizagem profunda ou teoria da informação, apresentamos a menor entropia cruzada/divergência de KL entre a distribuição real e a distribuição prevista.
É evidente a importância de identificar com elevada confiança o texto autêntico como tal (veja esta imagem humorística do Twitter). Embora seja evidente que este educador interpretou erroneamente a probabilidade indicada pela IA como a quantidade de texto escrito por IA, quando os detectores não têm a certeza de que o texto autêntico é realmente autêntico, isso abre margem para interpretações erradas.
 https://twitter.com/rustykitty_/status/1709316764868153537
https://twitter.com/rustykitty_/status/1709316764868153537
Dos três erros previstos pelo Checkfor.ai, infelizmente, dois deles são bastante fiáveis. O nosso detetor não é perfeito e estamos a trabalhar ativamente na calibração do modelo para evitar previsões erradas com tal grau de confiança.
Conclusão
Estamos a disponibilizar em código aberto os conjuntos de dados utilizados nesta avaliação de comentários reais e falsos do Yelp, para que os modelos futuros possam utilizar este importante ponto de referência para testar a precisão dos seus detectores.
As nossas principais conclusões são:
O Checkfor.ai apresenta uma baixa taxa de falsos positivos e uma baixa taxa de falsos negativos. O Checkfor.ai consegue distinguir entre comentários reais e comentários gerados por IA, não só com elevada precisão, mas também com elevada confiança. Iremos publicar mais artigos deste tipo no futuro e partilhar publicamente as nossas avaliações sinceras sobre o nosso modelo à medida que formos aprendendo mais. Fique atento e diga-nos o que pensa!

Bradley é investigador na área da IA e especialista no desenvolvimento de produtos de aprendizagem profunda no setor industrial. Recentemente, liderou o grupo de investigação em aprendizagem profunda da Absci, uma empresa de descoberta de medicamentos que utiliza IA generativa, e, anteriormente, integrou a equipa principal de visão computacional do Tesla Autopilot.
Enquanto estudante de pós-graduação, Bradley foi autor de várias publicações na área da investigação sobre aprendizagem profunda no Stanford Vision Lab. É licenciado em Física e mestre em Inteligência Artificial pela Universidade de Stanford. Para além da IA, interessa-se também por educação e filosofia, e é um ávido jogador de golfe.
Leitura relacionada

Como se compara o Pangram com o GPTZero?
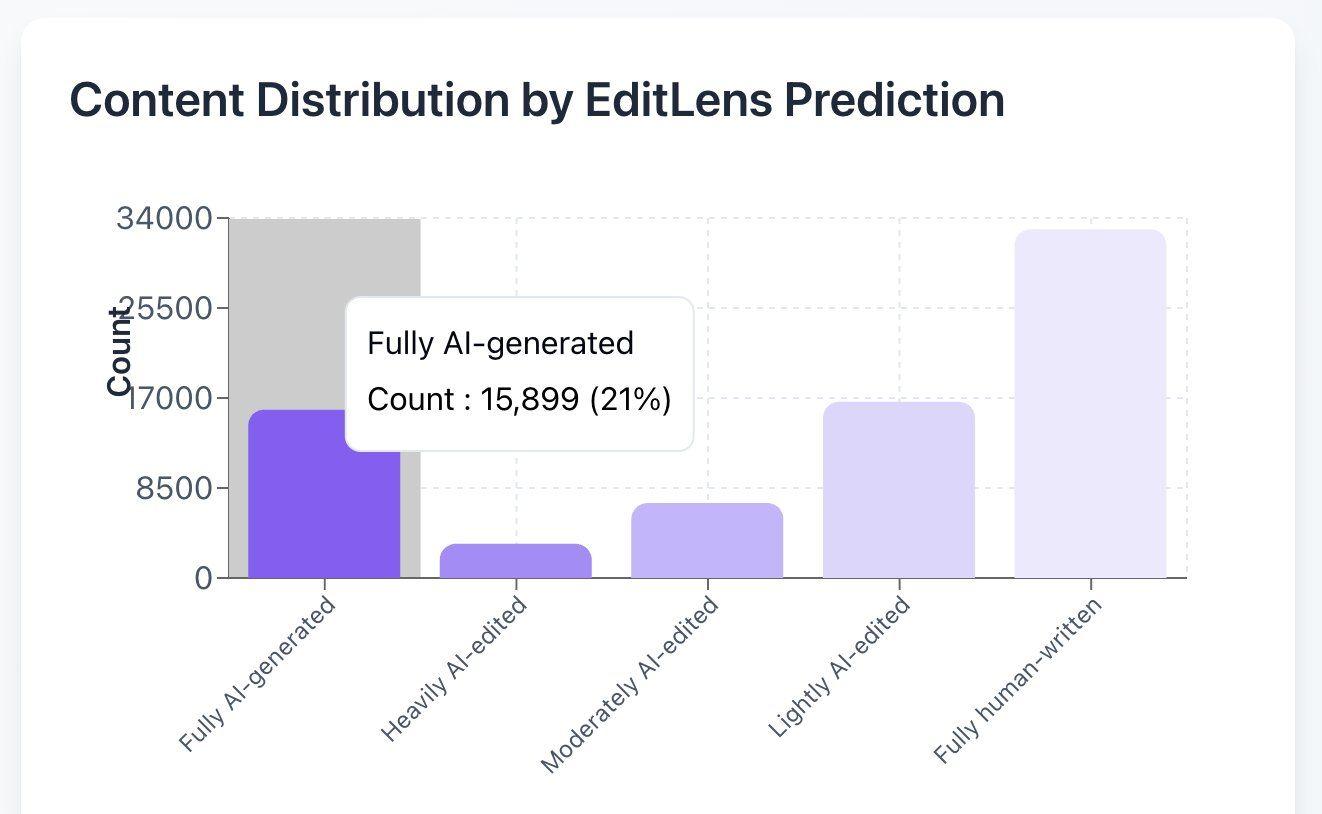
A Pangram prevê que 21% das revisões da ICLR são geradas por IA

Como identificar comentários gerados por IA

Avaliações de pangramas realizadas por terceiros

Como preparar a sua empresa para o LLM e a IA Gerativa

A IA está a escrever obras de ficção premiadas
para receber as nossas atualizações
