Pangram è l'unico strumento di rilevamento dell'IA che supera gli esperti umani nell'identificazione dei contenuti generati dall'IA
Siamo entusiasti di presentare la nuova ricerca di Jenna Russell, Marzena Karpinksa e Mohit Iyyer, ricercatori dell'Università del Maryland e di Microsoft, che dimostra come Pangram sia il rilevatore di contenuti generati dall'IA più performante in un confronto e l'unico sistema in grado di superare le prestazioni di esperti umani addestrati nell'individuazione di tali contenuti. Leggi l'articolo completo qui.

Oltre a studiare l'efficacia dei sistemi di rilevamento automatizzati basati sull'intelligenza artificiale, i ricercatori hanno anche approfondito il modo in cui gli esperti umani qualificati individuano i segnali che li aiutano a riconoscere gli indizi rivelatori dei contenuti generati dall'intelligenza artificiale. Riteniamo che questa ricerca rappresenti un enorme passo avanti in termini di spiegabilità e interpretabilità nel campo del rilevamento basato sull'intelligenza artificiale e siamo entusiasti di approfondire ulteriormente questa linea di ricerca.
In questo articolo del blog illustreremo i punti salienti della ricerca e cosa comportano per il futuro del rilevamento dei modelli di linguaggio di grandi dimensioni (LLM).
Formare le persone affinché diventino rilevatori di IA
In passato abbiamo già parlato di come individuare i testi generati dall'IA e del test di riferimento umano, e di come li utilizziamo per acquisire preziose intuizioni sui testi generati dall'IA che ci aiutano a sviluppare modelli migliori.
Di solito, quando iniziamo ad allenarci a individuare recensioni, saggi, post di blog o notizie generati dall’IA, all’inizio non siamo molto bravi. Ci vuole un po’ prima di riuscire a cogliere i segnali rivelatori che indicano che un testo è stato generato da ChatGPT o da un altro modello linguistico. Ad esempio, quando abbiamo iniziato a studiare le recensioni, abbiamo imparato col tempo, osservando molti dati, che ChatGPT ama iniziare una recensione con la frase "Recentemente ho avuto il piacere di", oppure, quando abbiamo iniziato a leggere racconti di fantascienza generati dall'IA, questi spesso iniziano con la frase "Nell'anno in cui". Tuttavia, col tempo, iniziamo a interiorizzare questi schemi e riusciamo a riconoscerli.
I ricercatori si sono inoltre chiesti se fosse possibile addestrare degli esperti a individuare gli articoli generati dall'intelligenza artificiale con lo stesso metodo. Hanno formato cinque revisori su Upwork per individuare i contenuti generati dall'intelligenza artificiale e hanno confrontato la loro capacità di individuarli a occhio nudo con quella di persone non esperte.
Sebbene ci si potesse aspettare una differenza nella capacità di questi due gruppi di individuare i testi scritti dall'IA, ciò che i ricercatori hanno riscontrato è stato un divario sostanziale. I non esperti ottengono risultati simili al caso nel rilevare i testi generati dall'IA, mentre gli esperti dimostrano un'elevata precisione (con un tasso di veri positivi superiore al 90%, in media).

Una delle sezioni che abbiamo trovato più interessante è stata quella intitolata "Cosa vedono gli annotatori esperti che sfugge ai non esperti?". I ricercatori hanno chiesto ai partecipanti di spiegare perché, secondo loro, un testo fosse stato generato dall'intelligenza artificiale oppure no, e poi hanno analizzato i loro commenti.
Ecco alcune analisi tratte direttamente dall'articolo:
"I non esperti spesso si fissano erroneamente su determinate caratteristiche linguistiche rispetto agli esperti. Un esempio è la scelta lessicale: i non esperti interpretano l'uso di parole "sofisticate" o comunque poco frequenti come indizi di un testo generato dall'IA; al contrario, gli esperti hanno molta più familiarità con le parole e le espressioni specifiche che l'IA tende a usare in modo eccessivo (ad esempio, "testamento", "cruciale"). I non esperti credono inoltre che gli autori umani siano più propensi a formare frasi grammaticalmente corrette e quindi attribuiscono le frasi troppo lunghe all'IA, ma è vero il contrario: gli esseri umani sono più propensi dell'IA a usare frasi non grammaticali o troppo lunghe. Infine, i non esperti attribuiscono all'IA qualsiasi testo scritto in tono neutro, il che porta a molti falsi positivi poiché anche la scrittura umana formale è spesso di tono neutro." (Russell, Karpinska, & Iyyer, 2025).
Nell'appendice, gli autori forniscono un elenco del "vocabolario dell'IA" comunemente utilizzato da ChatGPT: una funzionalità che abbiamo recentemente introdotto nella dashboard di Pangram e che mette in evidenza le espressioni più ricorrenti nell'ambito dell'IA!

In base alla nostra esperienza, abbiamo constatato che, nonostante molti pensino che l'IA utilizzi un vocabolario sofisticato e "sofisticato", nella pratica tendiamo invece a notare che l'IA ricorre a un linguaggio più banale e metaforico, che spesso non ha alcun senso. In parole povere, potremmo dire che i modelli di linguaggio di grandi dimensioni (LLM) sono un po' come persone che cercano di sembrare intelligenti, ma in realtà si limitano a usare frasi che credono possano farle sembrare tali.
Robustezza dei rilevatori di IA rispetto ai modelli all'avanguardia
Una delle domande che ci viene posta più spesso qui a Pangram è: come fate a stare al passo con i modelli all'avanguardia? Quando i modelli linguistici migliorano, significa che Pangram non funzionerà più? Si tratta di un gioco al gatto e al topo in cui i laboratori all'avanguardia come OpenAI finiranno per batterci?
Anche i ricercatori si sono posti questa domanda e hanno analizzato le prestazioni di diversi metodi di rilevamento basati sull'intelligenza artificiale rispetto a o1-pro di OpenAI, il modello più avanzato rilasciato fino ad oggi.
I ricercatori hanno scoperto che Pangram ha un'accuratezza del 100% nel rilevare i risultati generati da o1-pro, e che il nostro sistema raggiunge comunque un'accuratezza del 96,7% nel rilevare i risultati "umanizzati" di o1-pro (di cui parleremo tra poco)! In confronto, nessun altro rilevatore automatico supera nemmeno il 76,7% sui risultati di base generati da o1-pro.
Come fa Pangram a generalizzare in questo modo? Dopotutto, al momento dello studio, nel nostro set di addestramento non c'erano nemmeno dati o1-pro.
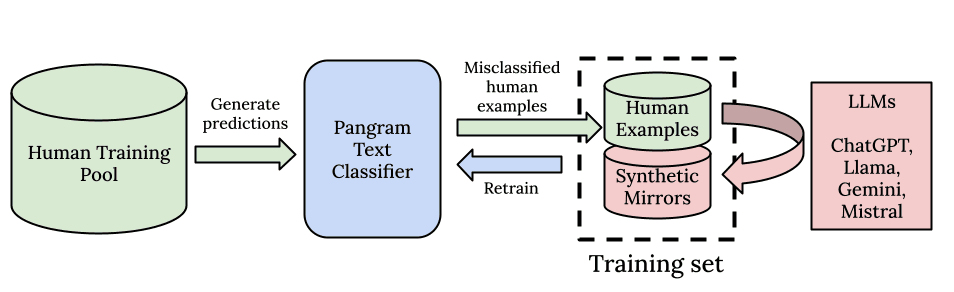
Come tutti i modelli di deep learning, crediamo nel potere della scalabilità e della potenza di calcolo. Innanzitutto, partiamo da un potente modello di base preaddestrato su un enorme corpus di addestramento, proprio come gli stessi LLM. In secondo luogo, abbiamo creato una pipeline di dati pensata per la scalabilità. Pangram è in grado di riconoscere modelli sottili grazie al suo corpus di addestramento composto da 100 milioni di documenti scritti da esseri umani.
Non ci limitiamo a creare un set di dati per saggi, notizie o recensioni: cerchiamo di raccogliere la più ampia rete possibile di tutti i dati scritti dall'uomo esistenti, in modo che il modello possa imparare da una distribuzione di dati della massima qualità e diversificata e acquisire conoscenze su tutti i tipi di scrittura umana. Riteniamo che questo approccio generale al rilevamento dell'IA funzioni molto meglio dell'approccio specializzato che consiste nel costruire un modello per ogni dominio testuale.
A completamento del nostro dataset umano, estremamente ampio e di alta qualità, vi sono la nostra pipeline di dati sintetici e l'algoritmo di ricerca basato sull'apprendimento attivo. Per procurarci i dati di IA necessari al nostro algoritmo, utilizziamo una libreria esaustiva di prompt e tutti i principali modelli di IA, sia open source che closed source, per generare dati sintetici. Utilizziamo prompt speculari sintetici, di cui abbiamo parlato nel nostro rapporto tecnico, e l'hard negative mining, che cerca gli esempi nel nostro pool di dati con il più alto errore e crea esempi di IA molto simili a quelli umani, rieducando il modello fino a quando non vediamo più errori. In questo modo riusciamo a ridurre in modo molto efficiente a zero i tassi di falsi positivi e falsi negativi del nostro modello.
In sintesi, la nostra generalizzazione deriva dalla mole dei dati utilizzati per il pre-addestramento, dalla varietà dei prompt e dei modelli di linguaggio di grandi dimensioni (LLM) impiegati per la generazione di dati sintetici, nonché dall’efficienza dei dati ottenuta grazie al nostro approccio basato sull’apprendimento attivo e sull’estrazione di esempi negativi difficili.
Inoltre, non solo puntiamo a ottenere ottime prestazioni fuori distribuzione, ma vogliamo anche assicurarci che il maggior numero possibile di modelli LLM comuni sia il più possibile in distribuzione. Abbiamo quindi realizzato una solida pipeline automatizzata per estrarre dati dai modelli più recenti, in modo da poter avviare l'addestramento sui nuovi modelli LLM non appena vengono rilasciati e rimanere sempre aggiornati. Abbiamo scoperto che non si tratta di un compromesso tra il bilanciamento delle prestazioni su modelli diversi: ogni volta che introduciamo un nuovo LLM nel set di addestramento, la generalizzazione del modello migliora.
Con il nostro sistema attuale, non stiamo riscontrando che, man mano che i modelli migliorano, diventino più difficili da individuare. In molti casi, il modello di nuova generazione è in realtà più facile da individuare. Ad esempio, abbiamo riscontrato una maggiore precisione nell’individuare Claude 3 al momento del suo lancio rispetto a Claude 2.
Attacchi di Paraphraser e Humanizer
Nella nostra recente serie di post sul blog abbiamo spiegato cos'è un "humanizer" per l'IA e abbiamo anche pubblicato un modello con prestazioni notevolmente migliorate nella produzione di testi di IA dal tono più umano. Siamo lieti di constatare che una terza parte abbia già confermato le nostre affermazioni utilizzando un set di dati composto da articoli o1-pro dal tono più umano.
Sul testo umanizzato o1-pro, raggiungiamo una precisione del 96,7%, mentre il modello automatizzato che segue nella classifica riesce a rilevare solo il 46,7% del testo umanizzato.
Inoltre, garantiamo una precisione del 100% sui testi generati da GPT-4o che sono stati parafrasati frase per frase.
Conclusione
Siamo entusiasti dei risultati eccellenti ottenuti da Pangram in uno studio indipendente sulle capacità di rilevamento dell'IA. Siamo sempre lieti di sostenere la ricerca accademica e mettiamo a disposizione un accesso libero a tutti i ricercatori che desiderino studiare il nostro sistema di rilevamento.
Oltre a valutare le prestazioni dei sistemi di rilevamento automatizzato, siamo entusiasti di vedere che la ricerca sta iniziando ad affrontare anche i temi della spiegabilità e dell'interpretabilità del rilevamento basato sull'IA: non solo per stabilire se un testo sia stato scritto dall'IA, ma anche per capire perché. Non vediamo l'ora di approfondire come questi risultati possano aiutare insegnanti ed educatori a individuare a occhio nudo i testi generati dall'IA, e come intendiamo integrare ulteriormente questa ricerca in strumenti di rilevamento automatizzato più spiegabili.
Per ulteriori informazioni, visita il nostro sito web pangram.com o contattaci all'indirizzo info@pangram.com.

Bradley è un ricercatore nel campo dell'intelligenza artificiale ed è esperto nello sviluppo di prodotti basati sul deep learning per il settore industriale. Recentemente ha guidato il gruppo di ricerca sul deep learning presso Absci, un'azienda che si occupa di scoperta di farmaci tramite intelligenza artificiale generativa, mentre in precedenza ha fatto parte del team principale di visione artificiale di Tesla Autopilot.
Durante gli studi universitari, Bradley è stato autore di numerose pubblicazioni nel campo della ricerca sul deep learning presso lo Stanford Vision Lab. Ha conseguito una laurea in fisica e un master in intelligenza artificiale presso l'Università di Stanford. Oltre all'intelligenza artificiale, nutre un grande interesse per l'istruzione e la filosofia ed è un appassionato giocatore di golf.
Altre letture

Nuovi livelli di prodotti Pangram

In che misura Pangram è in grado di individuare i modelli di ragionamento?

Vi presentiamo la nuova pagina dei risultati

I rilevatori di IA funzionano con GPT-5?
Relazione tecnica sul rilevamento di testi generati dall'intelligenza artificiale con elevata precisione

Come rilevare l'intelligenza artificiale in Python
per ricevere i nostri aggiornamenti
