تتزايد نسبة الأوراق البحثية في مؤتمرات الذكاء الاصطناعي التي تُكتب بواسطة الذكاء الاصطناعي: بزيادة قدرها 370% منذ عام 2023
 رسم بياني يوضح النسبة المئوية للملخصات التي تم إنشاؤها بواسطة الذكاء الاصطناعي والمقدمة إلى مؤتمر ICLR حسب السنة، ويُظهر اتجاهاً تصاعدياً منذ عام 2023.
رسم بياني يوضح النسبة المئوية للملخصات التي تم إنشاؤها بواسطة الذكاء الاصطناعي والمقدمة إلى مؤتمر ICLR حسب السنة، ويُظهر اتجاهاً تصاعدياً منذ عام 2023.
في فبراير 2024، نشرت مجلة «Frontiers in Cell and Developmental Biology» مقالاً تضمن رسومات من الواضح أنها من إنتاج الذكاء الاصطناعي. وقد احتل هذا المقال عناوين الأخبار، حيث أظهرت إحدى الصور فأراً بخصيتين ضخمتين بشكل سخيف ونصاً غير مفهوم لا معنى له على الإطلاق.
هذه ورقة بحثية حقيقية نُشرت في مجلة «Frontiers in Cell and Developmental Biology». ومن الواضح أن الأشكال الواردة فيها تم إنشاؤها بواسطة الذكاء الاصطناعي. ويظهر في إحدى هذه الأشكال فأر ذو خصيتين كبيرتين بشكل سخيف. أما النص الموجود في الأشكال فهو مجرد هراء. pic.twitter.com/4Acn2YZYwM
— كليف سوان (@cliff_swan) 15 فبراير 2024
ورغم أن المراجعة النظيرة (نظريًّا) ينبغي أن تكون كافية للكشف عن حالات واضحة كهذه، فماذا لو كان محتوى الورقة البحثية نفسه من إنتاج الذكاء الاصطناعي؟ فحتى الخبراء يجدون صعوبة في التمييز بين الأبحاث التي أنتجها الذكاء الاصطناعي وتلك التي كتبها البشر.
سلط تقرير إخباري نُشر مؤخرًا في مجلة «نيتشر» الضوء على القلق المتزايد بشأن المحتوى الذي تولده الذكاء الاصطناعي في الأوراق البحثية الأكاديمية. وتناولت المقالة دراسة استخدم فيها علماء الحاسوب «كلود 3.5»، وهو أحد أحدث نماذج اللغات الكبيرة (LLMs)، لتوليد أفكار بحثية وكتابة أوراق بحثية، تم تقديمها بعد ذلك إلى محكمين علميين. وقام هؤلاء المحكمون بتقييم الأوراق البحثية بناءً على «الحداثة، والإثارة، والجدوى، والفعالية المتوقعة». وتبين في المتوسط أن المحكمين منحوا الأوراق البحثية التي أنتجها الذكاء الاصطناعي درجات أعلى من تلك التي كتبها البشر! وهذا يطرح السؤال التالي: هل يبتكر الذكاء الاصطناعي فعلاً أفكاراً بحثية أفضل من البشر؟ ورغم أن من المغري الاعتقاد بأن هذا قد يكون صحيحاً، إلا أنه من بين 4000 ورقة بحثية تم إنشاؤها بواسطة الذكاء الاصطناعي والتي درسها الباحثون، لم تحتوي سوى 200 منها (5%) فعلاً على أي فكرة أصلية: فمعظم الأوراق كانت مجرد تكرار لأفكار موجودة بالفعل في مجموعة تدريب نماذج اللغة الكبيرة.
في نهاية المطاف، تضر الأبحاث التي يُنتجها الذكاء الاصطناعي بالمجتمع العلمي من خلال إضافة «ضوضاء» وتقليل «الإشارات» في عملية المراجعة النظيرة، ناهيك عن إهدار وقت وجهد المراجعين الذين يحرصون على الحفاظ على معايير البحث العلمي. علاوة على ذلك، والأسوأ من ذلك هو أن الأبحاث التي تولدها الذكاء الاصطناعي غالبًا ما تبدو مقنعة، ولكن في الواقع، النص الذي ينتجه نموذج اللغة يبدو فقط سلسًا، وقد يكون مليئًا بالأخطاء والهلوسة والتناقضات المنطقية. والمخاوف هنا هي أنه حتى المراجعين الخبراء غالبًا ما لا يستطيعون حتى معرفة متى يكون ما يقرؤونه هو هلوسة نموذج اللغة الكبير (LLM).
يتفق منظمو المؤتمرات الكبرى في مجال التعلم الآلي معنا: لا مكان للنصوص التي تولدها نماذج اللغة الكبيرة (LLM) في الكتابة العلمية. وفيما يلي السياسة الرسمية لمؤتمر ICML (المؤتمر الدولي للتعلم الآلي):
توضيح بشأن سياسة نماذج اللغة الكبيرة
لقد أدرجنا (رؤساء البرنامج) البيان التالي في دعوة تقديم الأوراق البحثية لمؤتمر ICML لعام 2023:
يُحظر تقديم الأوراق البحثية التي تتضمن نصوصًا تم إنشاؤها باستخدام نموذج لغوي واسع النطاق (LLM) مثل ChatGPT، ما لم يتم عرض النص الناتج كجزء من التحليل التجريبي للورقة البحثية.
أثار هذا البيان عددًا من الأسئلة من قبل المؤلفين المحتملين، ودفع البعض منهم إلى التواصل معنا بشكل استباقي. ونحن نقدر ملاحظاتكم وتعليقاتكم، ونود أن نوضح بشكل أوضح الهدف من هذا البيان وكيف نعتزم تطبيق هذه السياسة في مؤتمر ICML 2023.
باختصار؛
تحظر سياسة نماذج اللغة الكبيرة (LLM) الخاصة بمؤتمر ICML 2023 النصوص التي تم إنتاجها بالكامل بواسطة نماذج اللغة الكبيرة (أي «المولدة»). ولا يمنع هذا المؤلفين من استخدام نماذج اللغة الكبيرة لتحرير النصوص التي كتبوها بأنفسهم أو صقلها. وتستند سياسة نماذج اللغة الكبيرة بشكل كبير إلى مبدأ توخي الحذر فيما يتعلق بالوقاية من المشكلات المحتملة الناجمة عن استخدام نماذج اللغة الكبيرة، بما في ذلك الانتحال.
على الرغم من هذا التحذير، نجد أن عددًا كبيرًا ومتزايدًا من المؤلفين في مجال التعلم الآلي ينتهكون هذه السياسة ويستخدمون الذكاء الاصطناعي لإنشاء نصوص في أبحاثهم على أي حال.
تحديد حجم المشكلة
في Pangram، أردنا قياس حجم هذه المشكلة في مجالنا: الذكاء الاصطناعي. وقد شرعنا في الإجابة عن السؤال التالي: هل يستخدم باحثو الذكاء الاصطناعي ChatGPT لكتابة أبحاثهم؟
لدراسة هذه المشكلة، استخدمنا واجهة برمجة تطبيقات OpenReview لاستخراج الأوراق المقدمة للمؤتمرات في الفترة من 2018 إلى 2024 في اثنين من أكبر مؤتمرات الذكاء الاصطناعي: ICLR وNeurIPS.
ثم قمنا بتشغيل أداة "AI Detector" من Pangram على جميع الملخصات التي قُدمت إلى هذه المؤتمرات. وفيما يلي النتائج التي توصلنا إليها:
ICLR
رسم بياني يوضح النسبة المئوية للملخصات التي تم إنشاؤها بواسطة الذكاء الاصطناعي والمقدمة إلى مؤتمر ICLR حسب السنة، ويُظهر اتجاهاً تصاعدياً منذ عام 2023.
NeurIPS
 رسم بياني يوضح النسبة المئوية للملخصات التي تم إنشاؤها بواسطة الذكاء الاصطناعي والمقدمة إلى Neurips حسب السنة، ويُظهر اتجاهاً تصاعدياً منذ عام 2023.
رسم بياني يوضح النسبة المئوية للملخصات التي تم إنشاؤها بواسطة الذكاء الاصطناعي والمقدمة إلى Neurips حسب السنة، ويُظهر اتجاهاً تصاعدياً منذ عام 2023.
النتائج
يمكننا اعتبار كل البيانات التي تسبق عام 2022 بمثابة مجموعة التحقق الخاصة بمعدل الإيجابيات الخاطئة لنموذجنا، لأن نماذج اللغة الضخمة لم تكن موجودة في ذلك الوقت. كما هو موضح في الأشكال، نتوقع أن كل ملخص مؤتمر من عام 2022 أو قبله سيتم توقع أنه مكتوب بواسطة الإنسان من قبل نموذجنا. وهذا من شأنه أن يوحي بالثقة في دقة نموذجنا: فمعدل الإيجابيات الخاطئة لدينا جيد جدًا في الملخصات العلمية، لذا يمكننا أن نثق في أن كل توقع إيجابي يتم إجراؤه في عامي 2023 و2024 هو إيجابي حقيقي.
ما نشهده منذ ذلك الحين يبعث على القلق الشديد. فقد انقضت ثلاث دورات مؤتمرات منذ إطلاق ChatGPT في نوفمبر 2022.
حدثت الدورة الأولى في وقت قريب جدًا من إطلاق ChatGPT (ICLR 2023). كان الموعد النهائي لتقديم الملخصات في الواقع قبل إطلاق ChatGPT، لكن المؤلفين لديهم فرصة لإجراء تعديلات قبل انعقاد المؤتمر نفسه، الذي عقد بعد بضعة أشهر من إطلاق ChatGPT. ما وجدناه كان متوقعًا: لم تكن سوى حفنة من الملخصات مكتوبة بواسطة الذكاء الاصطناعي (لم نجد سوى ملخصين من بين عدة آلاف مكتوبين بواسطة الذكاء الاصطناعي في هذه الدورة) ومن المرجح أنهما تم تعديلهما بعد الموعد النهائي.
أما الدورة الثانية، التي عُقدت بعد حوالي 6 أشهر، وهي مؤتمر NeuRIPS 2023، فقد كان الموعد النهائي لتقديم الملخصات في صيف عام 2023، على أن يُعقد المؤتمر في ديسمبر. وفي هذا المؤتمر، أفدنا بأن حوالي 1.3% من الملخصات المقدمة كانت من إنتاج الذكاء الاصطناعي: وهي نسبة صغيرة لكنها ذات دلالة.
وأخيرًا، في الدورة الأخيرة، ICLR 2024، التي انعقدت قبل بضعة أشهر فقط، لاحظنا ارتفاعًا وصل إلى 4.9٪: وهو ما يمثل نموًا يقارب أربعة أضعاف في عدد المراجعات التي أنشأتها الذكاء الاصطناعي مقارنةً بـ NeuRIPS 2023!
تُسلط هذه النتائج الضوء على اتجاه مثير للقلق: فليس فقط عدد الأوراق البحثية التي تم إنشاؤها بواسطة الذكاء الاصطناعي والمقدمة إلى المؤتمرات الكبرى في مجال الذكاء الاصطناعي آخذًا في الازدياد، بل إن هذا العدد ينمو بمعدل متسارع أيضًا؛ وبعبارة أخرى، فإن وتيرة تقديم الأوراق البحثية التي تم إنشاؤها بواسطة الذكاء الاصطناعي آخذة في التسارع.
كيف تبدو الملخصات التي يُنتجها الذكاء الاصطناعي؟
ألقِ نظرة على بعض هذه الملخصات وانظر بنفسك ما إذا كانت تبدو لك كنوع الكتابة التي اعتدت قراءتها في الأدبيات العلمية التقنية:
-
في المشهد المعقد للبيانات الشبكية، يمثل فهم الآثار السببية للتدخلات تحديًا حاسمًا له انعكاسات على مختلف المجالات. وقد برزت الشبكات العصبية البيانية (GNNs) كأداة قوية لالتقاط الترابطات المعقدة، إلا أن إمكانات التعلم العميق الهندسي في مجال الاستدلال السببي للشبكات القائمة على الشبكات العصبية البيانية لا تزال غير مستكشفة بالشكل الكافي. ويقدم هذا العمل ثلاث مساهمات رئيسية لسد هذه الفجوة. أولاً، نؤسس صلة نظرية بين انحناء الرسم البياني والاستدلال السببي، ونكشف أن الانحناءات السلبية تشكل تحديات في تحديد الآثار السببية. ثانياً، استناداً إلى هذه الرؤية النظرية، نقدم نتائج حسابية باستخدام انحناء ريتشي للتنبؤ بموثوقية تقديرات الآثار السببية، ونثبت تجريبياً أن مناطق الانحناء الإيجابي تنتج تقديرات أكثر دقة. أخيرًا، نقترح طريقة تستخدم تدفق ريتشي لتحسين تقدير تأثير العلاج على البيانات الشبكية، مما يُظهر أداءً فائقًا من خلال تقليل الخطأ عن طريق تسطيح الحواف في الشبكة. تفتح نتائجنا آفاقًا جديدة للاستفادة من الهندسة في تقدير التأثير السببي، وتقدم رؤى وأدوات تعزز أداء شبكات GNN في مهام الاستدلال السببي.
-
في مجال نماذج اللغة، يُعد ترميز البيانات أمرًا محوريًا، حيث يؤثر على كفاءة وفعالية تدريب النموذج. ويُعد ترميز أزواج البايتات (BPE) تقنية راسخة لتقطيع النص إلى وحدات أصغر من الكلمة، توازن بين الكفاءة الحسابية والتعبير اللغوي من خلال دمج أزواج البايتات أو الأحرف المتكررة. ونظرًا لأن تدريب نماذج اللغة يتطلب موارد حسابية ضخمة، فإننا نقترح «Fusion Token»، وهي طريقة تعزز بشكل كبير نهج ترميز أزواج البايتات (BPE) التقليدي في ترميز البيانات لنماذج اللغة. تستخدم Fusion Token استراتيجية حسابية أكثر قوة مقارنة بـ BPE، حيث توسع مجموعات الرموز من ثنائيات الأحرف إلى عشرة أحرف. واللافت للنظر أنه مع إضافة 1024 رمزًا إلى المفردات، يتجاوز معدل الضغط بشكل كبير معدل ضاغط الرموز BPE العادي الذي يحتوي على مليون كلمة. بشكل عام، تؤدي طريقة Fusion Token إلى تحسينات ملحوظة في الأداء بسبب زيادة نطاق البيانات لكل وحدة حسابية. بالإضافة إلى ذلك، يؤدي الضغط الأعلى إلى أوقات استدلال أسرع بسبب قلة الرموز لكل سلسلة معينة. من خلال تخصيص المزيد من موارد الحوسبة لعملية بناء أداة الترميز، تعمل Fusion Token على تعظيم إمكانات نماذج اللغة كمحركات ضغط بيانات فعالة، مما يتيح أنظمة نمذجة لغوية أكثر فعالية.
-
في مجال توليد الحركة الذي يشهد تطوراً سريعاً، يُعتبر تحسين الدلالات النصية استراتيجية واعدة للغاية لإنتاج حركات أكثر دقة وواقعية. ومع ذلك، تعتمد التقنيات الحالية في كثير من الأحيان على نماذج لغوية شاملة لتحسين الأوصاف النصية، دون ضمان التوافق الدقيق بين البيانات النصية وبيانات الحركة. وغالبًا ما يؤدي هذا عدم التوافق إلى توليد حركة دون المستوى الأمثل، مما يحد من إمكانات هذه الأساليب. لمعالجة هذه المشكلة، نقدم إطار عمل جديدًا يسمى SemanticBoost، والذي يهدف إلى سد الفجوة بين البيانات النصية وبيانات الحركة. تدمج حلولنا المبتكرة معلومات دلالية تكميلية مستمدة من بيانات الحركة نفسها، إلى جانب شبكة مخصصة لإزالة الضوضاء، لضمان التماسك الدلالي ورفع الجودة الإجمالية لتوليد الحركة. من خلال تجارب وتقييمات مكثفة، نثبت أن SemanticBoost يتفوق بشكل كبير على الأساليب الحالية من حيث جودة الحركة والتوافق والواقعية. علاوة على ذلك، تؤكد نتائجنا على إمكانية الاستفادة من الإشارات الدلالية المستمدة من بيانات الحركة، مما يفتح آفاقًا جديدة لتوليد حركات أكثر بديهية وتنوعًا.
هل لاحظت أي أنماط؟ أولاً، نلاحظ أن جميعها تبدأ بعبارات متشابهة جداً: "في المشهد المعقد لـ"، "في مجال"، "في المجال الذي يشهد تطوراً سريعاً". نسمي هذا "اللغة المزخرفة بشكل مصطنع". لقد كتبنا من قبل عن مدى تكرار استخدام نماذج اللغة الكبيرة (LLMs) للكثير من الكلمات لإنتاج محتوى فعلي قليل جدًا. في حين أن هذا قد يكون مرغوبًا بالنسبة لطالب يحاول الوصول إلى الحد الأدنى لعدد الكلمات في واجب منزلي، فإن هذا النوع من اللغة المفرطة في الإسهاب يجعل الورقة البحثية أصعب وأكثر استهلاكًا للوقت بالنسبة للقارئ التقني الذي يحاول استيعاب البحث، بينما يجعل الرسالة الفعلية للورقة أقل وضوحًا.
هل تُقبل الأوراق البحثية في مجال الذكاء الاصطناعي فعلاً في المؤتمرات؟
تساءلنا عما إذا كانت الأوراق البحثية التي تم إنتاجها بواسطة الذكاء الاصطناعي تُستبعد فعليًّا من خلال عملية المراجعة النظيرة، أم أن بعضها يمر دون أن يُلاحظ.
للإجابة على هذا السؤال، قمنا بتحليل العلاقة بين الملخصات التي تم إنشاؤها بواسطة الذكاء الاصطناعي وقرارات قبول الأوراق البحثية في مؤتمر ICLR 2024. (تُعتبر الأوراق البحثية المُقدَّمة في جلسات العروض الشفوية و"السبوتلايت" والملصقات جميعها أوراقًا "مقبولة"؛ وتُعد جلسات العروض الشفوية و"السبوتلايت" فئتين خاصتين للتكريم). وإليكم ما توصلنا إليه:
| الفئة | النسبة المئوية الناتجة عن الذكاء الاصطناعي |
|---|---|
| ICLR 2024 شفوي | 2.33% |
| ملصق ICLR 2024 | 2.71% |
| أضواء على ICLR 2024 | 1.36% |
| مرفوض | 5.42% |
ورغم أن نسبة الأوراق البحثية التي تم إنشاؤها بواسطة الذكاء الاصطناعي والتي تم قبولها أقل من نسبة الأوراق المقدمة، إلا أن عددًا كبيرًا منها نجح في اجتياز عملية المراجعة من قبل الأقران. وهذا يعني أنه على الرغم من أن المراجعين قد يكتشفون بعض المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي، إلا أنهم لا يكتشفونه كله.
نلاحظ أن حتى بعض العروض الشفوية والأوراق البحثية المميزة تحتوي على ملخصات تم إنشاؤها بواسطة الذكاء الاصطناعي! وإذا نظرنا إلى الأمر بعيون متسامحة، فقد نجد في المستقبل أن هذه الأبحاث قد تكون في الواقع عالية الجودة، وأن المؤلفين يكتفون باستخدام ChatGPT كطريقة مختصرة لمساعدتهم على عرض أعمالهم أو تنقيحها بشكل أفضل.
والجدير بالذكر أنه نظراً لأن غالبية أعضاء المجتمع البحثي ليسوا من الناطقين باللغة الإنجليزية، فإن أحد الاستخدامات المتزايدة لنماذج اللغة الكبيرة سيكون ترجمة الأوراق البحثية المكتوبة بلغات أخرى إلى اللغة الإنجليزية.
الخلاصة
على الرغم من الطلب الصريح الذي وجهته مجتمع الذكاء الاصطناعي إلى المؤلفين بعدم استخدام ChatGPT، فإن العديد منهم يتجاهلون هذه السياسة ويستخدمون نماذج اللغة الكبيرة (LLMs) لمساعدتهم في كتابة أبحاثهم على أي حال. والأمر الأكثر إثارة للقلق هو أن خبراء الذكاء الاصطناعي أنفسهم، الذين يعملون كمراجعين نظراء لحماية المؤتمرات من الأبحاث التي تم إنشاؤها بواسطة نماذج اللغة الكبيرة، لا يستطيعون اكتشافها!
تتسبب ChatGPT في تأثيرات متتالية أوسع نطاقاً في جميع مراحل العملية الأكاديمية. فقد كشفت دراسة حالة حديثة أجرتها ICML أن ما بين 6 و16 في المائة من مراجعات الأقران نفسها تم إنشاؤها بواسطة الذكاء الاصطناعي، وهناك علاقة إيجابية بين مراجعات الأقران التي أنشأها الذكاء الاصطناعي ومدى قرب موعد تقديم المراجعة من الموعد النهائي!
ندعو مجتمع الذكاء الاصطناعي إلى تطبيق هذه السياسات بشكل أفضل، كما ندعو المؤلفين إلى تحمل مسؤوليتهم للتأكد من أن أبحاثهم من إعداد بشري.
لا يقتصر دخول الذكاء الاصطناعي إلى عالم الكتابة الأدبية على مجال الأبحاث فحسب — بل إن الذكاء الاصطناعي يفوز أيضًا بجوائز في مجال الأدب الخيالي.

برادلي باحث في مجال الذكاء الاصطناعي وخبير في تطوير منتجات التعلم العميق في القطاع الصناعي. وقد تولى مؤخرًا قيادة مجموعة أبحاث التعلم العميق في شركة «أبسكي» (Absci)، وهي شركة متخصصة في اكتشاف الأدوية باستخدام الذكاء الاصطناعي التوليدي، وكان قبل ذلك عضوًا في الفريق الأساسي للرؤية الحاسوبية في نظام «تيسلا أوتوبيلوت» (Tesla Autopilot).
أثناء دراسته للدراسات العليا، ألف برادلي العديد من المنشورات البحثية في مجال التعلم العميق بالتعاون مع مختبر ستانفورد للرؤية. وهو حاصل على بكالوريوس في الفيزياء وماجستير في الذكاء الاصطناعي من جامعة ستانفورد. وبالإضافة إلى الذكاء الاصطناعي، يهتم برادلي أيضًا بمجالي التعليم والفلسفة، كما أنه لاعب غولف شغوف.
مقالات ذات صلة
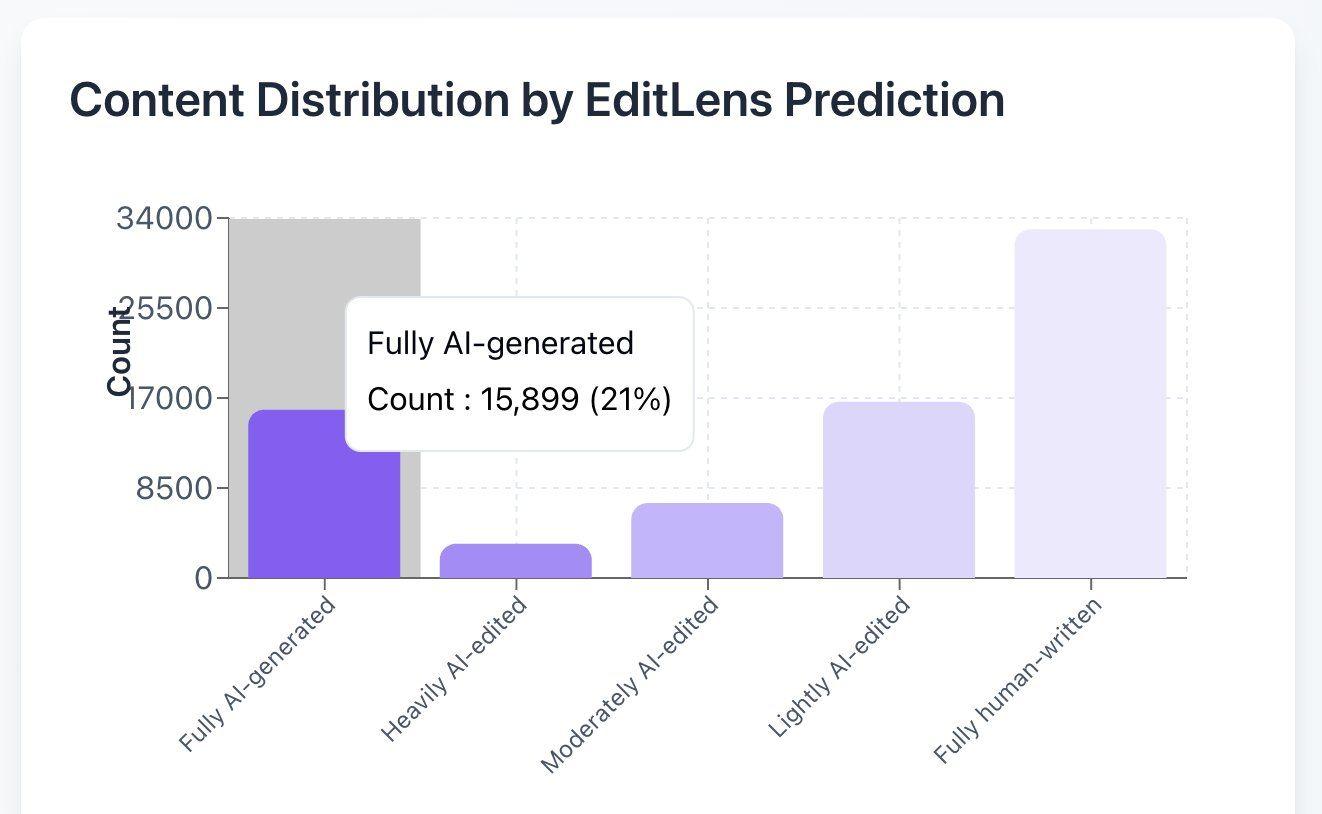
تتوقع Pangram أن 21% من المراجعات في مؤتمر ICLR تم إنشاؤها بواسطة الذكاء الاصطناعي
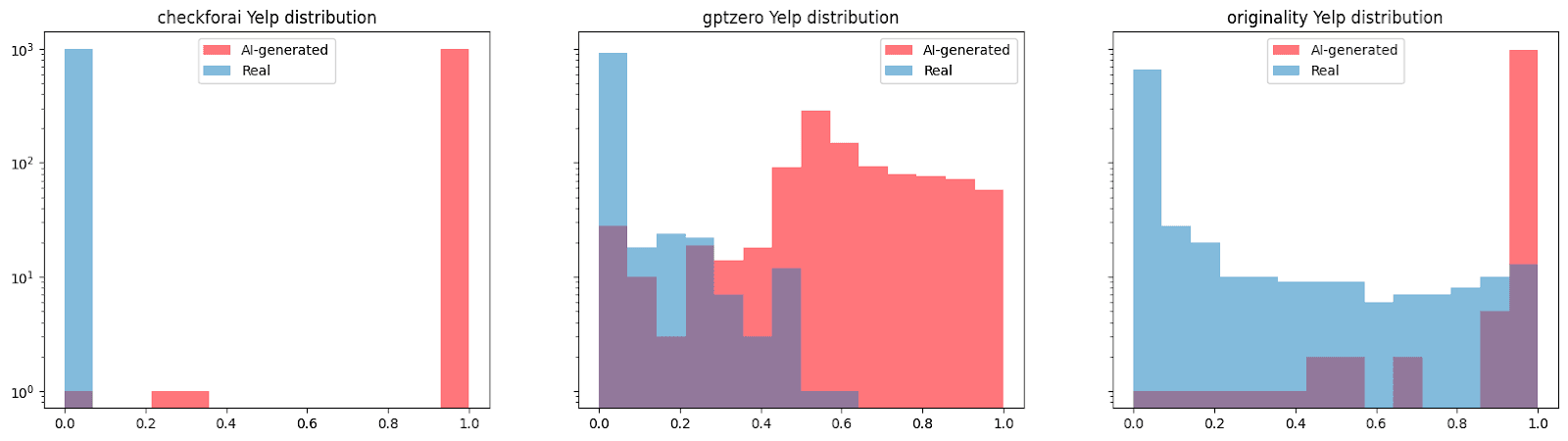
تحليل متعمق لتعليقات يلب

الذكاء الاصطناعي لديه عين للذكاء الاصطناعي

أصبحت 3% من التعليقات التي تظهر على الصفحة الرئيسية لموقع أمازون من إنتاج الذكاء الاصطناعي

ما هو أكثر أدوات الكشف عن الذكاء الاصطناعي دقةً؟ اختبار 30 أداة (2026)

تحضير شركتك لمواجهة تحديات LLM والذكاء الاصطناعي العام
لتلقي آخر أخبارنا
