ملاحظة: لقد غيرنا اسمنا إلى Pangram Labs! اقرأ منشورنا على المدونة لمزيد من التفاصيل.
في Checkfor.ai، نسعى جاهدين لنكون أفضل أداة للكشف عن النصوص المكتوبة بواسطة الذكاء الاصطناعي في فئتها، وذلك لتعزيز مهمتنا المتمثلة في حماية الإنترنت من التلوث الناتج عن النصوص منخفضة الجودة التي يُنتجها الذكاء الاصطناعي. وتُعد منصات تقييمات المستخدمين من أهم المجالات التي يجب الدفاع عنها.
إن التعليقات المزيفة على الإنترنت تضر في نهاية المطاف بكل من الشركات والمستهلكين، وقد أدى ChatGPT إلى تسهيل ارتكاب عمليات التزوير في التعليقات على نطاق واسع.
 تقييم تم إنشاؤه بواسطة ChatGPT على موقع Yelp
تقييم تم إنشاؤه بواسطة ChatGPT على موقع Yelp
يُعد الحفاظ على ثقة المستخدمين في التقييمات عبر الإنترنت جزءًا مهمًا من مهمتنا في Checkfor.ai لحماية مصداقية المحتوى الذي ينشئه البشر على الإنترنت.
نبذة عني
اسمي برادلي إيمي، وأنا المدير التقني لشركة Checkfor.ai. عملت باحثًا في مجال الذكاء الاصطناعي في جامعة ستانفورد، وقمت بتطوير نماذج إنتاجية بصفتي عالمًا في التعلم الآلي ضمن فريق "تيسلا أوتوبيلوت"، كما قمت بقيادة فريق بحثي في شركة Absci قام ببناء منصة لتصميم الأدوية باستخدام الشبكات العصبية الضخمة. في مجال السيارات ذاتية القيادة واكتشاف الأدوية، فإن دقة بنسبة 99% ليست كافية على الإطلاق. فقد تعني دقة بنسبة 99% أن 1 من كل 100 من المشاة قد يصدمه مركبة ذاتية القيادة، أو أن 1 من كل 100 مريض قد يعاني من آثار جانبية تهدد حياته بسبب دواء سيئ التصميم.
على الرغم من أن الكشف عن النصوص التي تولدها الذكاء الاصطناعي لا يمثل بالضرورة مسألة حياة أو موت، فإننا نسعى في Checkfor.ai إلى تصميم نماذج وأنظمة برمجية تلتزم بنفس معايير الجودة. يجب أن يتحمل كاشفنا الهجمات العدائية مثل إعادة الصياغة، وهندسة المطالبات المتقدمة، وأدوات التهرب من الكشف مثل undetectable.ai. نحن جادون في حل هذه المشكلة (على سبيل المثال، لا نكتفي بالوصول إلى نسبة 99٪)، وبالتالي، فإن إحدى الأولويات القصوى لفريق الهندسة لدينا هي تطوير منصة تقييم قوية للغاية.
فلسفة التقييم: مجموعات الاختبارات هي اختبارات وحدة
لن تقوم شركة للأمن السيبراني تعمل بنظام «البرمجيات 1.0» أبدًا بطرح منتج دون إجراء اختبارات وحدة. وبصفتنا شركة تعمل بنظام «البرمجيات 2.0»، فإننا بحاجة إلى ما يعادل اختبارات الوحدة، إلا أن هذه الاختبارات يجب أن تشمل نماذج ضخمة تحتوي على ملايين أو حتى مليارات المعلمات، والتي قد تتصرف بشكل عشوائي، ويجب أن تعمل بشكل صحيح مع تغطية نطاق واسع من الحالات النادرة. لا يمكننا تحقيق "دقة مجموعة اختبار بنسبة 99٪" واعتبار الأمر منتهياً: نحن بحاجة إلى تقييمات تختبر على وجه التحديد أنواع الأمثلة التي سنواجهها في العالم الحقيقي.
تُجيب مجموعة الاختبار الجيدة على أسئلة محددة وتقلل من عدد المتغيرات المُشوشة.
ومن أمثلة أسئلة الاختبار الموجهة ومجموعات الاختبارات المقابلة لها ما يلي:
- ما مدى فعالية نموذجنا في تحليل تقييمات Yelp؟ مجموعة اختبار مكونة من ألف تقييم حقيقي على Yelp، وألف تقييم تم إنشاؤها بواسطة الذكاء الاصطناعي على Yelp.
- ما مدى فعالية نموذجنا في التعامل مع النصوص المعاد صياغتها؟ مجموعة اختبار تضم مئات المقالات الحقيقية للطلاب، ومئات المقالات التي أنتجتها الذكاء الاصطناعي، بالإضافة إلى تلك المقالات نفسها بعد إعادة صياغتها باستخدام QuillBot أو Undetectable.AI.
هناك عدة أسباب تمنعك من مجرد دمج كل العناصر الموجودة في مجموعة الاختبار الخاصة بك والإبلاغ عن رقم واحد.
- هناك عدد كبير جدًا من المتغيرات المُشوشة — فنحن لا نعرف ما إذا كان الاختبار قد نجح أم فشل بسبب توزيع البيانات أم بسبب النموذج.
- يمكن لأي شخص أن يضخم رقم الدقة بشكل مصطنع بمجرد إغراق مجموعة الاختبار بأمثلة سهلة.
- وبدون تفسير واضح وقابل للتكرار حول كيفية إنشاء مجموعة الاختبار بطريقة غير متحيزة، لا يمكننا معرفة ما إذا كان أحدهم قد اختار بعناية أمثلة ينجح فيها نموذجه بينما يفشل فيها النموذج المرجعي.
ولهذا السبب، فإن الدراسات المعيارية من هذا النوع تخطئ الهدف تمامًا. فهي تفتقر إلى التركيز، ولا تختبر السلوكيات المحددة التي نريد أن يؤديها النموذج. فمجموعات الاختبار المتحيزة تُظهر النموذج في أفضل حالاته، وليس عندما يواجه أمثلة من العالم الواقعي.
مقياس موضوعي من Yelp
ومن الأمثلة على التطبيقات العملية لتقنية الكشف عن النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي، الكشف عن التعليقات التي تم إنشاؤها بواسطة الذكاء الاصطناعي على موقع Yelp. يلتزم موقع Yelp بإدارة صارمة لمنصة التعليقات الخاصة به، وإذا اطلعت على «تقرير الثقة والأمان» الخاص به لعام 2022، فستلاحظ بوضوح أن Yelp يولي اهتمامًا كبيرًا لمكافحة التعليقات الاحتيالية أو المدفوعة أو التي يتم تحفيزها أو غير النزيهة بأي شكل من الأشكال.
لحسن الحظ، أطلقت Yelp أيضًا مجموعة بيانات مفتوحة المصدر ممتازة. وقد قمنا بأخذ عينة عشوائية من 1000 تقييم من هذه المجموعة، بالإضافة إلى إنشاء 1000 تقييم اصطناعي باستخدام ChatGPT، وهو نموذج اللغة الكبيرة (LLM) الأكثر استخدامًا.
من المهم الإشارة إلى أن تقييمات ChatGPT تتعلق بشركات حقيقية مسجلة على Yelp مستمدة من قاعدة بيانات Kaggle الخاصة بهم؛ وبهذه الطريقة لا يمكن للنموذج التلاعب بالنتائج من خلال الإفراط في التكيف مع تفاصيل مثل الاختلاف في توزيع الشركات. وأثناء التقييم، نجري اختبارات للتأكد مما إذا كان النموذج قد تعلم بالفعل استخدام السمات الصحيحة في النص لتمييز الحقيقي من المزيف.
نستخدم مجموعة البيانات هذه لمعرفة أي من نماذج الكشف التي تعتمد على الذكاء الاصطناعي يمكنها فعلاً التمييز بين التعليقات التي أنشأها ChatGPT والتعليقات الحقيقية!
دقة النماذج
أبسط مقياس لدينا هو الدقة: كم عدد الأمثلة التي صنفها كل نموذج بشكل صحيح؟
- Checkfor.ai: 99.85% (1997/2000)
- Originality.AI: 96.2% (1738/1806) (ملاحظة: يرفض Originality.AI تصنيف المستندات التي يقل عدد كلماتها عن 50 كلمة).
- GPTZero: 90.8% (1815/2000)
ورغم أن الفارق بين 99.85% و96% قد لا يبدو كبيرًا في البداية، إلا أنه عند النظر إلى معدل الخطأ، يمكننا وضع هذه الأرقام في سياق أوضح.
من المتوقع أن يفشل Checkfor.ai مرة واحدة فقط من بين كل 666 استعلام، في حين يُتوقع أن يفشل Originality.AI مرة واحدة من بين كل 26 استعلامًا، ويفشل GPTZero مرة واحدة من بين كل 11 استعلامًا. وهذا يعني أن معدل الخطأ لدينا أفضل بأكثر من 25 ضعفًا من Originality.AI، وأفضل بـ 60 ضعفًا من GPTZero.
النتائج الإيجابية الكاذبة والنتائج السلبية الكاذبة
من أجل دراسة حالات الإيجابية الكاذبة والسلبية الكاذبة (في مصطلحات التعلم الآلي، نعتبر الإحصائيات المشابهة جدًّا، وهي الدقة والاسترجاع)، يمكننا النظر إلى مصفوفة الخلط – ما هي النسب النسبية للإيجابية الحقيقية، والإيجابية الكاذبة، والسلبية الحقيقية، والسلبية الكاذبة؟

Over all 2,000 examples, Checkfor.ai produces 0 false positives and 3 false negatives, exhibiting high precision and high recall. While admirably, GPTZero does not often predict false positives, with only 2 false positives, it comes at the expense of predicting 183 false negatives– an incredibly high false negative rate! We’d call this a model that exhibits high precision but low recall. Finally, Originality.AI predicts 60 false positives and 8 false negatives– and it refuses to predict a likelihood on short reviews (<50 words) — which are the hardest cases and most likely to be false positives. This high false positive rate means that this model is low precision, high recall.
في حين أن انخفاض معدل الإيجابيات الخاطئة يعد أكثر أهمية في مجال الكشف عن النصوص باستخدام الذكاء الاصطناعي (فنحن لا نريد أن نتهم أشخاصًا حقيقيين زورًا بالسرقة الأدبية من ChatGPT)، فإن انخفاض معدل السلبيات الخاطئة يعد أمرًا ضروريًا أيضًا – فلا يمكننا السماح بتسرب ما يزيد عن 10 إلى 20% من المحتوى الذي يولده الذكاء الاصطناعي دون أن يتم اكتشافه.
ثقة النموذج
في النهاية، نود أن يُظهر نموذجنا درجة عالية من الثقة عندما يكون من الواضح أن النص من تأليف بشري، أو كُتب بواسطة ChatGPT.
واتباعًا لاستراتيجية عرض بيانية مشابهة لتلك المستخدمة في الورقة البحثية المتميزة «DetectGPT» التي أعدها ميتشل وزملاؤه، قمنا برسم الرسوم البيانية التوزيعية لتنبؤات النماذج لكل من التقييمات التي أنشأتها الذكاء الاصطناعي والتقييمات الحقيقية بالنسبة لجميع النماذج الثلاثة. ونظرًا لأن دقة جميع النماذج الثلاثة تتجاوز 90٪، فإن استخدام مقياس لوغاريتمي على المحور الصادي هو الأكثر فائدة لتوضيح خصائص درجة الثقة لكل نموذج.

في هذا الرسم البياني، يمثل المحور السيني احتمالية توقع النموذج أن تكون المراجعة المدخلة من إنتاج الذكاء الاصطناعي. أما المحور الصادي فيمثل عدد المرات التي يتنبأ فيها النموذج بهذه الاحتمالية بالنسبة للنصوص الحقيقية (الأشرطة الزرقاء) أو النصوص التي أنتجها الذكاء الاصطناعي (الأشرطة الحمراء). نلاحظ أنه عند النظر إلى هذه التوقعات "الناعمة"، بدلاً من مجرد نعم أو لا، فإن Checkfor.ai أفضل بكثير في رسم حدود واضحة للقرار وتقديم توقعات أكثر ثقة مقارنةً بـ GPTZero أو Originality.AI.
يميل GPTZero إلى توقع عدد كبير جدًا من الأمثلة في نطاق احتمالية يتراوح بين 0.4 و0.6، مع وجود قيمة متكررة حول 0.5. من ناحية أخرى، تظهر مشكلة النتائج الإيجابية الخاطئة في Originality.AI بشكل أوضح عند فحص التوقعات غير المؤكدة. تقترب العديد من المراجعات الحقيقية جدًا من أن يتم توقعها على أنها من إنشاء الذكاء الاصطناعي، حتى لو لم تتجاوز عتبة 0.5. وهذا يجعل من الصعب على المستخدم أن يثق في قدرة النموذج على توقع النصوص التي أنشأها الذكاء الاصطناعي بشكل موثوق، حيث إن التغييرات الطفيفة في المراجعة يمكن أن تسمح لمهاجم بتجاوز الكاشف عن طريق تعديل المراجعة بشكل متكرر حتى تصبح أقل من عتبة الكشف.
من ناحية أخرى، فإن نموذجنا عادةً ما يكون حاسماً للغاية. فنحن قادرون عموماً على اتخاذ قرارات واثقة. وبالنسبة للقراء الذين لديهم خلفية في مجال التعلم العميق أو نظرية المعلومات، فإننا نحقق أدنى قيمة لـ«الانتروبيا المتقاطعة» أو «تباعد KL» بين التوزيع الحقيقي والتوزيع المتوقع.
هناك فائدة واضحة في التنبؤ بأن النص الحقيقي هو نص حقيقي بدرجة عالية من الثقة (انظر هذا الشكل المضحك من تويتر). ورغم أنه من الواضح أن هذا المعلم أخطأ في تفسير احتمالية الذكاء الاصطناعي على أنها نسبة النص الذي كتبته الذكاء الاصطناعي، إلا أن عدم ثقة أدوات الكشف في أن النص الحقيقي هو نص حقيقي بالفعل، يترك مجالاً لسوء التفسير.
 https://twitter.com/rustykitty_/status/1709316764868153537
https://twitter.com/rustykitty_/status/1709316764868153537
من بين الأخطاء الثلاثة التي تنبأ بها Checkfor.ai، للأسف، هناك خطأان منها يتمتعان بدرجة عالية من الثقة. إن أداة الكشف لدينا ليست مثالية، ونحن نعمل جاهدين على معايرة النموذج لتجنب مثل هذه التنبؤات الخاطئة التي تتمتع بدرجة عالية من الثقة.
الخلاصة
نحن نتيح مجموعات البيانات المستخدمة في هذا التقييم لكل من تقييمات Yelp الحقيقية والمزيفة كمصدر مفتوح ، حتى تتمكن النماذج المستقبلية من استخدام هذا المعيار المهم لاختبار دقة أدوات الكشف الخاصة بها.
أهم النقاط التي استخلصناها هي:
يتميز Checkfor.ai بمعدل منخفض لكل من النتائج الإيجابية الخاطئة والنتائج السلبية الخاطئة. يستطيع Checkfor.ai التمييز بين التعليقات الحقيقية وتلك التي تم إنشاؤها بواسطة الذكاء الاصطناعي، ليس فقط بدقة عالية، بل وبثقة كبيرة أيضًا. سننشر المزيد من المقالات من هذا النوع في المستقبل، وسنشارك تقييماتنا الصادقة لنموذجنا مع تزايد معرفتنا به. تابعونا، وأخبرونا برأيكم!

برادلي باحث في مجال الذكاء الاصطناعي وخبير في تطوير منتجات التعلم العميق في القطاع الصناعي. وقد تولى مؤخرًا قيادة مجموعة أبحاث التعلم العميق في شركة «أبسكي» (Absci)، وهي شركة متخصصة في اكتشاف الأدوية باستخدام الذكاء الاصطناعي التوليدي، وكان قبل ذلك عضوًا في الفريق الأساسي للرؤية الحاسوبية في نظام «تيسلا أوتوبيلوت» (Tesla Autopilot).
أثناء دراسته للدراسات العليا، ألف برادلي العديد من المنشورات البحثية في مجال التعلم العميق بالتعاون مع مختبر ستانفورد للرؤية. وهو حاصل على بكالوريوس في الفيزياء وماجستير في الذكاء الاصطناعي من جامعة ستانفورد. وبالإضافة إلى الذكاء الاصطناعي، يهتم برادلي أيضًا بمجالي التعليم والفلسفة، كما أنه لاعب غولف شغوف.
مقالات ذات صلة

كيف يقارن موقع Pangram بموقع GPTZero؟
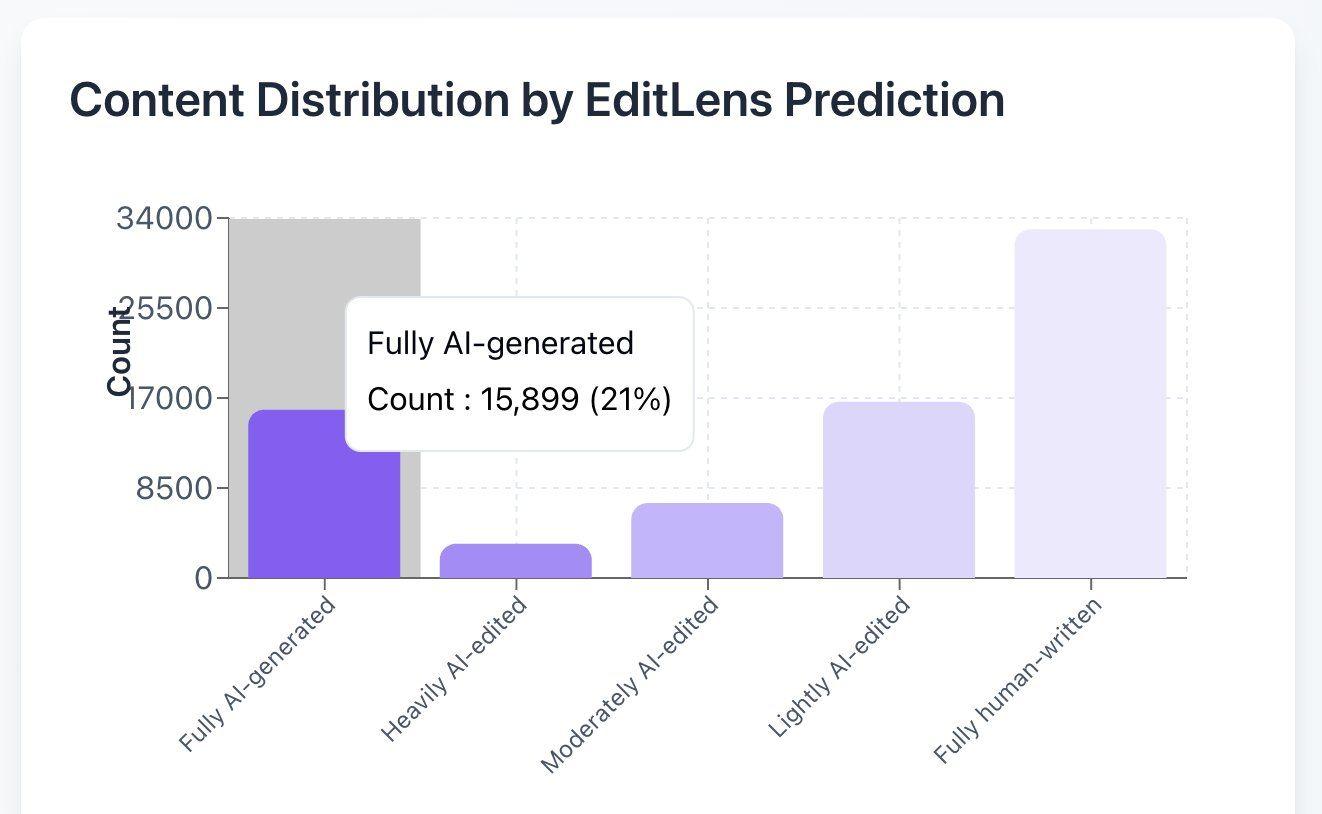
تتوقع Pangram أن 21% من المراجعات في مؤتمر ICLR تم إنشاؤها بواسطة الذكاء الاصطناعي

كيفية التعرف على التعليقات المزيفة باستخدام الذكاء الاصطناعي

تقييمات البانغرام من قبل أطراف ثالثة

تحضير شركتك لمواجهة تحديات LLM والذكاء الاصطناعي العام

الذكاء الاصطناعي يكتب روايات حائزة على جوائز
لتلقي آخر أخبارنا
