Cada vez son más los artículos de congresos sobre IA redactados por la propia IA: un aumento del 370 % desde 2023
 Un gráfico que muestra el porcentaje de resúmenes generados por IA presentados a la ICLR por año, lo que revela una tendencia al alza desde 2023.
Un gráfico que muestra el porcentaje de resúmenes generados por IA presentados a la ICLR por año, lo que revela una tendencia al alza desde 2023.
En febrero de 2024, un artículo publicado en la revista *Frontiers in Cell and Developmental Biology* incluía unas ilustraciones que, evidentemente, habían sido generadas por inteligencia artificial. Este artículo en concreto saltó a los titulares porque una de las imágenes mostraba una rata con testículos de un tamaño absurdo y un texto sin sentido que no tenía ninguna lógica.
Este es un artículo real publicado en «Frontiers in Cell and Developmental Biology». Las figuras están generadas, evidentemente, por IA. En una de ellas aparece una rata con testículos absurdamente grandes. El texto de las figuras es un galimatías. pic.twitter.com/4Acn2YZYwM
— Cliff Swan (@cliff_swan) 15 de febrero de 2024
Aunque la revisión por pares (en teoría) debería ser suficiente para detectar casos evidentes como este, ¿qué ocurre cuando el contenido real del artículo ha sido generado por IA? Incluso a los expertos les cuesta distinguir entre los trabajos de investigación generados por IA y los escritos por personas.
Un reciente reportaje de Nature pone de relieve la creciente preocupación por el contenido generado por IA en los artículos académicos. El artículo analiza un estudio en el que unos informáticos utilizaron Claude 3.5, uno de los modelos de lenguaje grande (LLM) más recientes, para generar ideas de investigación y redactar artículos, que posteriormente se presentaron a revisores científicos. A continuación, estos revisores evaluaron los artículos en función de «novedad, interés, viabilidad y eficacia prevista». En promedio, se observó que los revisores otorgaban una puntuación más alta a los artículos generados por IA que a los escritos por humanos. Esto lleva a la pregunta: ¿se le ocurren realmente a la IA mejores ideas de investigación que a los humanos? Aunque es tentador creer que este podría ser el caso, de los 4000 artículos generados por IA estudiados por los investigadores, solo 200 de ellos (el 5 %) contenían realmente alguna idea original: la mayoría de los artículos simplemente repetían ideas ya existentes del conjunto de entrenamiento del LLM.
En definitiva, la investigación generada por IA perjudica a la comunidad al añadir ruido y reducir la señal en el proceso de revisión por pares, por no hablar del tiempo y el esfuerzo que desperdician los revisores que se esmeran en mantener los estándares de la investigación. Además, lo que es aún peor es que la investigación generada por IA a menudo parece convincente, pero, en realidad, el texto producido por un modelo de lenguaje solo suena fluido y puede estar plagado de errores, alucinaciones e incoherencias lógicas. La preocupación aquí es que incluso los revisores expertos a menudo no pueden distinguir cuándo lo que están leyendo es una alucinación del modelo de lenguaje grande (LLM).
Los organizadores de las principales conferencias sobre aprendizaje automático coinciden con nosotros: el texto generado por modelos de lenguaje grande (LLM) no tiene cabida en la redacción científica. La política oficial de la ICML (Conferencia Internacional sobre Aprendizaje Automático) es la siguiente:
Aclaración sobre la política relativa a los modelos de lenguaje a gran escala
Nosotros (los coordinadores del programa) hemos incluido la siguiente declaración en la convocatoria de ponencias para la ICML de 2023:
Quedan prohibidos los artículos que incluyan texto generado a partir de un modelo de lenguaje a gran escala (LLM), como ChatGPT, a menos que dicho texto se presente como parte del análisis experimental del artículo.
Esta declaración ha suscitado una serie de preguntas por parte de posibles autores y ha llevado a algunos a ponerse en contacto con nosotros de forma proactiva. Agradecemos sus opiniones y comentarios, y nos gustaría aclarar con mayor detalle la intención que subyace a esta declaración y cómo tenemos previsto aplicar esta política en la ICML 2023.
En resumen:
La política sobre modelos de lenguaje a gran escala (LLM) para ICML 2023 prohíbe el uso de textos generados íntegramente por LLM (es decir, «generados»). Esto no impide que los autores utilicen LLM para editar o pulir textos redactados por ellos mismos. La política sobre LLM se basa en gran medida en el principio de actuar con cautela a la hora de prevenir posibles problemas derivados del uso de LLM, incluido el plagio.
A pesar de esta advertencia, observamos que un número considerable y cada vez mayor de autores del ámbito del aprendizaje automático está incumpliendo la política y utilizando la IA para generar texto en sus artículos de todos modos.
Evaluar la magnitud del problema
En Pangram, queríamos evaluar el alcance de este problema en nuestro propio campo: la inteligencia artificial. Nos propusimos responder a la siguiente pregunta: ¿están utilizando los investigadores en IA ChatGPT para redactar sus propios trabajos de investigación?
Para estudiar este problema, utilizamos la API de OpenReview para extraer las propuestas presentadas entre 2018 y 2024 en dos de las conferencias más importantes sobre inteligencia artificial: ICLR y NeurIPS.
A continuación, aplicamos el detector de IA de Pangram a todos los resúmenes presentados a estas conferencias. Estos son nuestros resultados:
ICLR
Un gráfico que muestra el porcentaje de resúmenes generados por IA presentados a la ICLR por año, lo que revela una tendencia al alza desde 2023.
NeurIPS
 Un gráfico que muestra el porcentaje de resúmenes generados por IA enviados a Neurips por año, lo que revela una tendencia al alza desde 2023.
Un gráfico que muestra el porcentaje de resúmenes generados por IA enviados a Neurips por año, lo que revela una tendencia al alza desde 2023.
Los resultados
Podemos considerar todo lo anterior a 2022 como un conjunto de validación de la tasa de falsos positivos de nuestro modelo, ya que en aquella época aún no existían los modelos de lenguaje a gran escala. Como se muestra en las figuras, nuestro modelo predice que todos y cada uno de los resúmenes de conferencias de 2022 o anteriores han sido escritos por humanos. Esto debería inspirar confianza en la precisión de nuestro modelo: nuestra tasa de falsos positivos es muy buena en los resúmenes científicos, por lo que podemos estar seguros de que todas las predicciones positivas realizadas en 2023 y 2024 son verdaderos positivos.
Lo que hemos visto desde entonces es muy preocupante. Se han celebrado tres ciclos de conferencias desde que se lanzó ChatGPT en noviembre de 2022.
El primer ciclo tuvo lugar justo en torno al lanzamiento de ChatGPT (ICLR 2023). La fecha límite de envío era, en realidad, anterior al lanzamiento de ChatGPT, pero los autores tenían la oportunidad de realizar modificaciones antes de que se celebrara la conferencia, que tuvo lugar un par de meses después del lanzamiento de ChatGPT. Lo que encontramos es lo esperado: solo un puñado de resúmenes fueron redactados por IA (solo encontramos 2 de varios miles redactados por IA en este ciclo) y probablemente fueron modificados después de la fecha límite.
El segundo ciclo tuvo lugar unos seis meses después, en NeuRIPS 2023, cuya fecha límite para la presentación de trabajos era el verano de 2023, con vistas a la celebración de la conferencia en diciembre. En esta conferencia, informamos de que alrededor del 1,3 % de los resúmenes presentados habían sido generados por IA: una proporción pequeña, pero significativa.
Por último, en la última edición, ICLR 2024, celebrada hace apenas unos meses, observamos un aumento hasta alcanzar el 4,9 %: ¡un crecimiento de casi cuatro veces en las revisiones generadas por IA con respecto a NeuRIPS 2023!
Estos resultados ponen de manifiesto una tendencia preocupante: no solo está aumentando el número de artículos de congresos generados por IA que se presentan en los principales eventos del sector, sino que además ese número crece a un ritmo cada vez mayor; en otras palabras, el ritmo al que se presentan estos artículos generados por IA se está acelerando.
¿Cómo son los resúmenes generados por IA?
Echa un vistazo a algunos de estos resúmenes y comprueba por ti mismo si te parecen del tipo de texto al que estás acostumbrado en la literatura científica técnica:
-
En el complejo panorama de los datos en red, comprender los efectos causales de las intervenciones supone un reto fundamental con implicaciones en diversos ámbitos. Las redes neuronales de grafos (GNN) se han revelado como una herramienta poderosa para captar dependencias complejas; sin embargo, el potencial del aprendizaje profundo geométrico para la inferencia causal en redes basada en GNN sigue sin explorarse en profundidad. Este trabajo aporta tres contribuciones clave para salvar esta brecha. En primer lugar, establecemos una conexión teórica entre la curvatura de los grafos y la inferencia causal, revelando que las curvaturas negativas plantean dificultades a la hora de identificar los efectos causales. En segundo lugar, basándonos en esta perspectiva teórica, presentamos resultados computacionales que utilizan la curvatura de Ricci para predecir la fiabilidad de las estimaciones de los efectos causales, demostrando empíricamente que las regiones de curvatura positiva producen estimaciones más precisas. Por último, proponemos un método que utiliza el flujo de Ricci para mejorar la estimación del efecto del tratamiento en datos en red, mostrando un rendimiento superior al reducir el error mediante el aplanamiento de los bordes de la red. Nuestros hallazgos abren nuevas vías para aprovechar la geometría en la estimación de efectos causales, ofreciendo conocimientos y herramientas que mejoran el rendimiento de las GNN en tareas de inferencia causal.
-
En el ámbito de los modelos de lenguaje, la codificación de datos es fundamental, ya que influye en la eficiencia y la eficacia del entrenamiento de los modelos. La codificación por pares de bytes (BPE) es una técnica de tokenización de subpalabras bien consolidada que equilibra la eficiencia computacional y la expresividad lingüística mediante la fusión de pares frecuentes de bytes o caracteres. Dado que el entrenamiento de modelos de lenguaje requiere importantes recursos computacionales, proponemos Fusion Token, un método que mejora sustancialmente el enfoque convencional de codificación por pares de bytes (BPE) en la codificación de datos para modelos de lenguaje. Fusion Token emplea una estrategia computacional más agresiva en comparación con BPE, ampliando los grupos de tokens de bigramas a decagramas. Cabe destacar que, con la incorporación de 1024 tokens al vocabulario, la tasa de compresión supera significativamente a la de un tokenizador BPE estándar con un vocabulario de un millón de términos. En general, el método Fusion Token conduce a mejoras notables en el rendimiento debido a un mayor alcance de datos por unidad de cálculo. Además, una mayor compresión da lugar a tiempos de inferencia más rápidos debido al menor número de tokens por cadena dada. Al dedicar más recursos de cálculo al proceso de construcción del tokenizador, Fusion Token maximiza el potencial de los modelos de lenguaje como motores eficientes de compresión de datos, lo que permite sistemas de modelado de lenguaje más eficaces.
-
En el ámbito de la generación de movimiento, que avanza a pasos agigantados, se ha reconocido que la mejora de la semántica textual constituye una estrategia muy prometedora para producir movimientos más precisos y realistas. Sin embargo, las técnicas actuales suelen depender de modelos lingüísticos extensos para refinar las descripciones textuales, sin garantizar una alineación precisa entre los datos textuales y los de movimiento. Esta falta de alineación suele dar lugar a una generación de movimiento subóptima, lo que limita el potencial de estos métodos. Para abordar este problema, presentamos un marco novedoso llamado SemanticBoost, cuyo objetivo es salvar la brecha entre los datos textuales y los de movimiento. Nuestra innovadora solución integra información semántica complementaria derivada de los propios datos de movimiento, junto con una red dedicada a la eliminación de ruido, para garantizar la coherencia semántica y elevar la calidad general de la generación de movimiento. A través de extensos experimentos y evaluaciones, demostramos que SemanticBoost supera significativamente a los métodos existentes en términos de calidad de movimiento, alineación y realismo. Además, nuestros hallazgos ponen de relieve el potencial de aprovechar las pistas semánticas de los datos de movimiento, abriendo nuevas vías para una generación de movimiento más intuitiva y diversa.
¿Notas algún patrón? En primer lugar, vemos que todos comienzan con frases muy similares: «En el complejo panorama de», «En el ámbito de», «En el campo en rápida evolución de». A esto lo llamamos lenguaje artificialmente rebuscado. Ya hemos escrito anteriormente sobre la frecuencia con la que los modelos de lenguaje grande (LLM) utilizan muchas palabras para producir muy poco contenido real. Si bien esto puede resultar deseable para un estudiante que intenta alcanzar un número mínimo de palabras en un trabajo, para un lector técnico que intenta asimilar una investigación, este tipo de lenguaje excesivamente prolijo hace que el artículo sea más difícil y lento de leer, al tiempo que solo consigue que el mensaje real del artículo resulte menos claro.
¿De verdad se aceptan los artículos sobre IA en las conferencias?
Nos preguntábamos si los artículos generados por IA son realmente filtrados de manera eficaz por el proceso de revisión por pares, o si algunos de ellos se cuelan entre las grietas.
Para responder a esta pregunta, analizamos la correlación entre los resúmenes generados por IA y las decisiones sobre la aceptación de los artículos en ICLR 2024. (Las ponencias orales, las ponencias destacadas y los pósteres son todos artículos «aceptados»; las ponencias orales y las ponencias destacadas son categorías de reconocimiento especial). Esto es lo que descubrimos:
| Categoría | Porcentaje generado por IA |
|---|---|
| ICLR 2024 oral | 2.33% |
| Póster de ICLR 2024 | 2.71% |
| ICLR 2024 en primer plano | 1.36% |
| Rechazado | 5.42% |
Aunque el porcentaje de artículos generados por IA que fueron aceptados es inferior al porcentaje de los presentados, un número considerable logró superar el proceso de revisión por pares. Esto implica que, si bien es posible que los revisores detecten parte del contenido generado por IA, no lo detectan en su totalidad.
¡Nos hemos dado cuenta de que incluso algunas ponencias orales y artículos destacados tienen resúmenes generados por IA! Si interpretamos la situación con benevolencia, lo que podríamos encontrar en el futuro es que la investigación sea, de hecho, de gran calidad, y que los autores simplemente estén recurriendo a atajos con ChatGPT para presentar o revisar mejor su trabajo.
Cabe destacar que, dado que gran parte de la comunidad investigadora no es de habla inglesa, uno de los usos cada vez más frecuentes de los modelos de lenguaje grande (LLM) será la traducción al inglés de artículos escritos en otros idiomas.
Conclusión
A pesar de la petición explícita de la comunidad de IA a los autores de que no utilicen ChatGPT, muchos de ellos están haciendo caso omiso de esta norma y recurren a los modelos de lenguaje grande (LLM) para que les ayuden a redactar sus artículos. Y lo que es más preocupante, ¡ni siquiera los expertos en IA, que actúan como revisores para proteger a las conferencias de los artículos generados por LLM, son capaces de detectarlos!
ChatGPT está teniendo un impacto cada vez mayor en todo el proceso académico. Un estudio de caso reciente de la ICML reveló que entre el 6 % y el 16 % de las revisiones por pares fueron generadas por IA, ¡y existe una correlación positiva entre las revisiones generadas por IA y lo cerca que se presentó la revisión de la fecha límite!
Hacemos un llamamiento a la comunidad de IA para que aplique mejor estas políticas, y a los autores para que asuman la responsabilidad de garantizar que sus artículos hayan sido redactados por personas.
La incursión de la IA en la escritura literaria no se limita a la investigación: la IA también está ganando premios de ficción.

Bradley es investigador en inteligencia artificial y experto en el desarrollo de productos de aprendizaje profundo para el sector industrial. Recientemente ha dirigido el grupo de investigación en aprendizaje profundo de Absci, una empresa dedicada al descubrimiento de fármacos mediante IA generativa, y anteriormente formó parte del equipo principal de visión artificial de Tesla Autopilot.
Durante sus estudios de posgrado, Bradley fue autor de varias publicaciones sobre investigación en aprendizaje profundo en el Stanford Vision Lab. Es licenciado en Física y tiene un máster en Inteligencia Artificial por la Universidad de Stanford. Además de la IA, le apasionan la educación y la filosofía, y es un ávido golfista.
Lecturas relacionadas
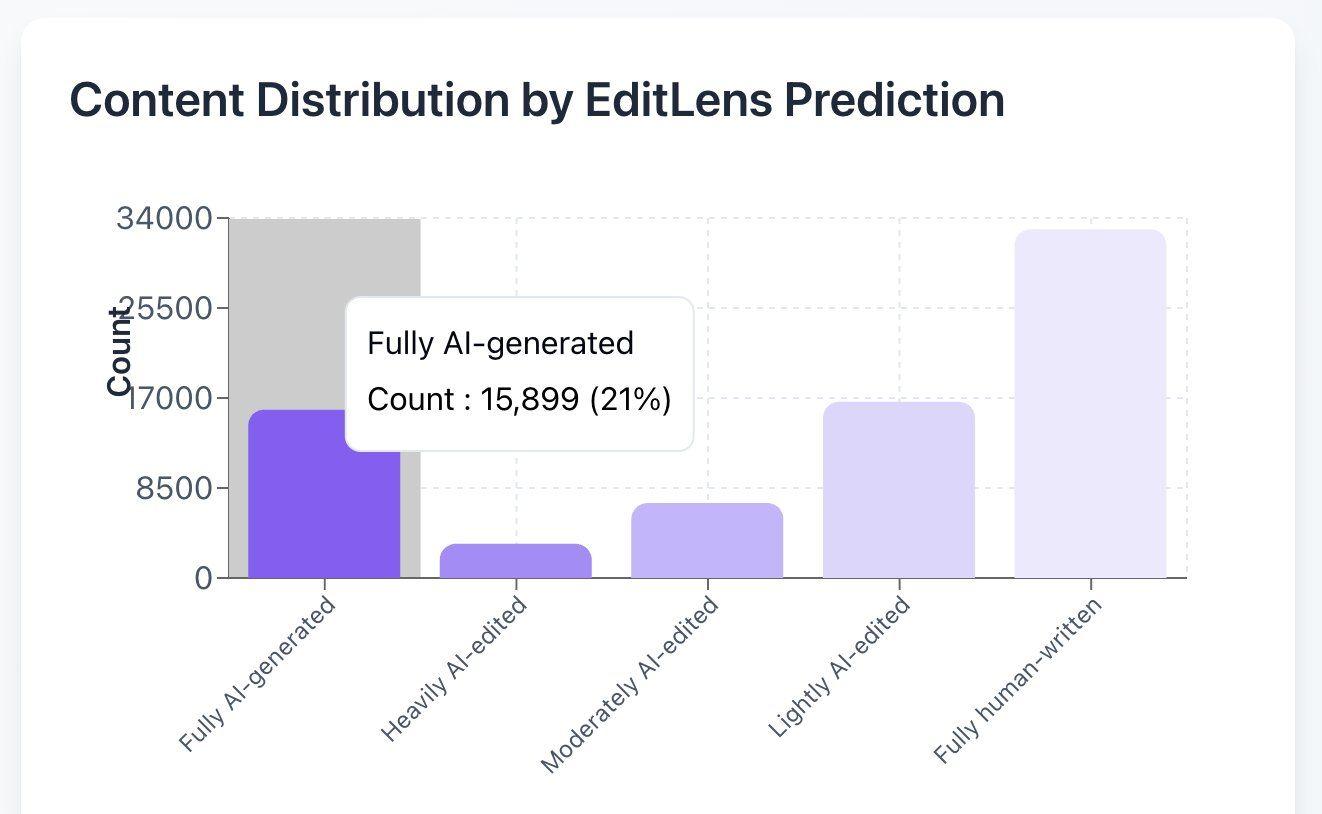
Pangram prevé que el 21 % de las reseñas de la ICLR sean generadas por IA
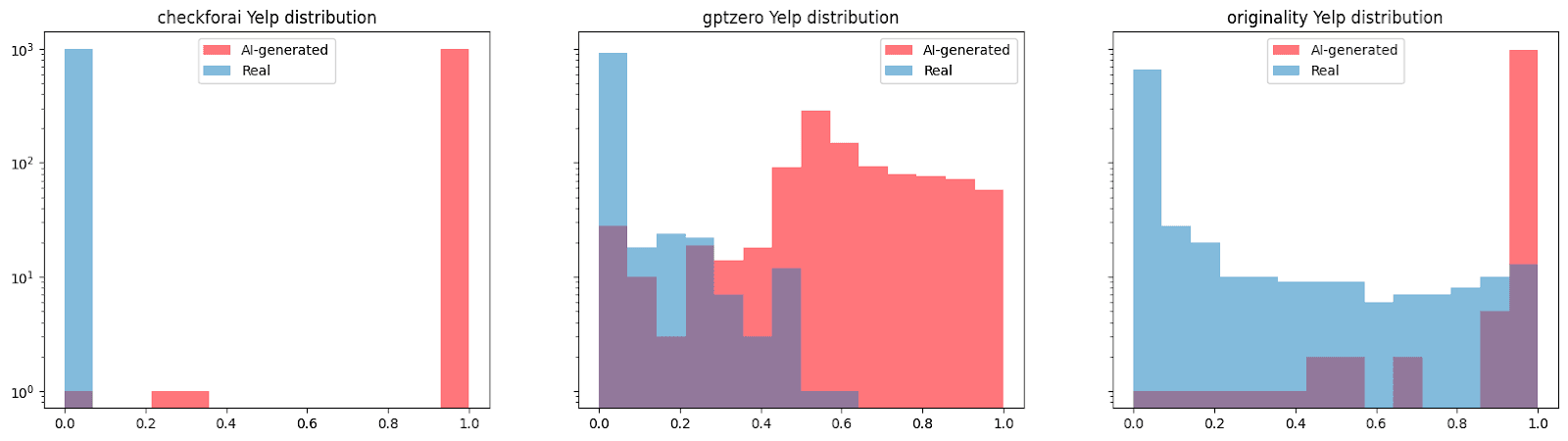
Análisis en profundidad de las reseñas de Yelp

La IA tiene buen ojo para la IA

El tres por ciento de las reseñas que aparecen en la primera página de Amazon están generadas por IA

¿Qué detector de IA es el más preciso? 30 herramientas analizadas (2026)

Cómo preparar tu empresa para el LLM y la IA general
