NOTA: ¡Hemos cambiado nuestro nombre a Pangram Labs! Consulta nuestra entrada del blog para obtener más detalles.
En Checkfor.ai, nos esforzamos por ser el mejor detector de texto generado por IA del mercado, con el fin de promover nuestra misión de proteger Internet de la contaminación que supone el contenido de baja calidad generado por IA. Uno de los ámbitos más importantes que hay que defender son las plataformas de opiniones de usuarios.
Las reseñas falsas en Internet perjudican, en última instancia, tanto a las empresas como a los consumidores, y ChatGPT no ha hecho más que facilitar aún más el fraude en las reseñas a gran escala.
 Opinión generada por ChatGPT en Yelp
Opinión generada por ChatGPT en Yelp
Mantener la confianza de los usuarios en las reseñas en línea es una parte importante de nuestra misión en Checkfor.ai para proteger la autenticidad del contenido generado por personas en Internet.
Acerca de mí
Me llamo Bradley Emi y soy el director técnico de Checkfor.ai. He trabajado como investigador en inteligencia artificial en Stanford, he implementado modelos en producción como científico de aprendizaje automático en el equipo de Autopilot de Tesla y he dirigido un equipo de investigación que desarrolló una plataforma para diseñar fármacos con grandes redes neuronales en Absci. En el ámbito de los coches autónomos y el descubrimiento de fármacos, una precisión del 99 % simplemente no es suficiente. Una precisión del 99 % podría significar que 1 de cada 100 peatones es atropellado por un vehículo autónomo, o que 1 de cada 100 pacientes sufre efectos secundarios potencialmente mortales a causa de un fármaco mal diseñado.
Aunque detectar texto generado por IA no es necesariamente una cuestión de vida o muerte, en Checkfor.ai queremos diseñar modelos y sistemas de software que cumplan con los mismos estándares de calidad. Nuestro detector debe resistir ataques adversarios como la paráfrasis, la ingeniería avanzada de prompts y herramientas de evasión de detección como undetectable.ai. Nos tomamos muy en serio la resolución de este problema (es decir, no nos conformamos con alcanzar el 99 %), por lo que una de las principales prioridades de nuestro equipo de ingeniería es desarrollar una plataforma de evaluación extremadamente robusta.
Filosofía de evaluación: los conjuntos de pruebas son pruebas unitarias
Una empresa de ciberseguridad de «Software 1.0» nunca lanzaría un producto sin pruebas unitarias. Como empresa de «Software 2.0», necesitamos el equivalente a las pruebas unitarias, salvo que estas deben evaluar modelos de gran tamaño con millones o incluso miles de millones de parámetros, que pueden comportarse de forma estocástica, y deben funcionar correctamente al tiempo que abarcan una amplia distribución de casos extremos. No podemos conformarnos con una «precisión del 99 % en el conjunto de pruebas» y dar el tema por zanjado: necesitamos evaluaciones que prueben específicamente el tipo de ejemplos con los que nos encontraremos en el mundo real.
Un buen conjunto de pruebas responde a preguntas concretas y reduce al mínimo el número de variables de confusión.
Entre los ejemplos de preguntas de examen específicas y los conjuntos de preguntas correspondientes se incluyen:
- ¿Qué tal funciona nuestro modelo con las reseñas de Yelp? Conjunto de prueba compuesto por mil reseñas reales de Yelp y mil reseñas de Yelp generadas por IA.
- ¿Qué tal funciona nuestro modelo con textos parafraseados? Conjunto de prueba compuesto por cientos de redacciones reales de estudiantes, cientos de redacciones generadas por IA y esas mismas redacciones parafraseadas mediante QuillBot o Undetectable.AI.
Hay varias razones por las que no basta con combinar todos los datos del conjunto de pruebas y dar una cifra.
- Hay demasiadas variables de confusión: no sabemos si la prueba ha dado resultado positivo o negativo debido a la distribución de los datos o al modelo.
- Cualquiera puede inflar artificialmente su índice de precisión simplemente llenando el conjunto de prueba con ejemplos fáciles.
- Sin una explicación clara y reproducible de cómo se creó el conjunto de pruebas de forma imparcial, no podemos saber si alguien simplemente ha seleccionado ejemplos en los que su modelo funciona bien y el modelo de referencia falla.
Por eso los estudios comparativos como estos no dan en el blanco. Carecen de enfoque y no evalúan los comportamientos específicos que queremos que el modelo realice. Los conjuntos de pruebas sesgados muestran el modelo en su mejor momento, no cuando se enfrenta a ejemplos del mundo real.
Una evaluación imparcial de Yelp
Un ejemplo de aplicación práctica de la detección de texto generado por IA es la detección de reseñas generadas por IA en Yelp. Yelp se compromete a moderar rigurosamente su plataforma de reseñas y, si se consulta su Informe de Confianza y Seguridad de 2022, queda claro que Yelp se toma muy en serio la lucha contra las reseñas fraudulentas, pagadas, incentivadas o deshonestas de cualquier otro tipo.
Afortunadamente, Yelp también ha publicado un excelente conjunto de datos de código abierto. Hemos seleccionado al azar 1000 reseñas de este conjunto de datos y hemos generado otras 1000 reseñas sintéticas con ChatGPT, el modelo de lenguaje grande (LLM) más utilizado.
Es importante señalar que las reseñas de ChatGPT corresponden a negocios reales de Yelp extraídos de su conjunto de datos de Kaggle: de este modo, el modelo no puede «hacer trampa» adaptándose excesivamente a detalles como las diferencias en la distribución de los negocios. Durante la evaluación, comprobamos si el modelo realmente ha aprendido a utilizar las características correctas del texto para distinguir lo auténtico de lo falso.
¡Utilizamos este conjunto de datos para averiguar cuáles de los modelos de detección basados en IA son realmente capaces de distinguir las reseñas generadas por ChatGPT de las auténticas!
Precisión de los modelos
Nuestro indicador más sencillo es la precisión: ¿cuántos ejemplos clasificó correctamente cada modelo?
- Checkfor.ai: 99,85 % (1997/2000)
- Originality.AI: 96,2 % (1738/1806) (nota: Originality.AI no clasifica los documentos de menos de 50 palabras).
- GPTZero: 90,8 % (1815/2000)
Aunque una diferencia entre el 99,85 % y el 96 % pueda no parecer muy grande a primera vista, si tenemos en cuenta la tasa de error, podemos situar estas cifras en un contexto más adecuado.
Se prevé que Checkfor.ai falle solo una vez de cada 666 consultas, mientras que se espera que Originality.AI falle una vez de cada 26 consultas y que GPTZero falle una vez de cada 11 consultas. Esto significa que nuestra tasa de error es más de 25 veces mejor que la de Originality.AI y 60 veces mejor que la de GPTZero.
Falsos positivos y falsos negativos
Para analizar los falsos positivos y los falsos negativos (en la jerga del aprendizaje automático, nos referiríamos a los conceptos muy similares de precisión y recuperación), podemos examinar la matriz de confusión: ¿cuáles son las tasas relativas de verdaderos positivos, falsos positivos, verdaderos negativos y falsos negativos?

Over all 2,000 examples, Checkfor.ai produces 0 false positives and 3 false negatives, exhibiting high precision and high recall. While admirably, GPTZero does not often predict false positives, with only 2 false positives, it comes at the expense of predicting 183 false negatives– an incredibly high false negative rate! We’d call this a model that exhibits high precision but low recall. Finally, Originality.AI predicts 60 false positives and 8 false negatives– and it refuses to predict a likelihood on short reviews (<50 words) — which are the hardest cases and most likely to be false positives. This high false positive rate means that this model is low precision, high recall.
Aunque en la detección de texto generado por IA es más importante que la tasa de falsos positivos sea baja (no queremos acusar erróneamente a personas reales de plagiar a ChatGPT), también es necesario que la tasa de falsos negativos sea baja: no podemos permitir que se nos escape entre el 10 % y el 20 % del contenido generado por IA.
Confianza en el modelo
En definitiva, nos gustaría que nuestro modelo mostrara un alto nivel de confianza cuando esté claro que el texto es de autoría humana o ha sido escrito por ChatGPT.
Siguiendo una estrategia de visualización similar a la del excelente artículo académico «DetectGPT», de Mitchell et al., representamos gráficamente los histogramas de las predicciones de los tres modelos, tanto para las reseñas generadas por IA como para las reseñas reales. Dado que los tres modelos tienen una precisión superior al 90 %, una escala logarítmica en el eje Y resulta la más útil para visualizar las características del nivel de confianza de cada modelo.

En este gráfico, el eje X representa la probabilidad de que el modelo prediga que la reseña introducida ha sido generada por IA. El eje Y representa la frecuencia con la que el modelo predice esa probabilidad concreta para texto real (barras azules) o generado por IA (barras rojas). Observamos que, al analizar estas predicciones «suaves», en lugar de limitarse a un sí o un no, Checkfor.ai es mucho más eficaz a la hora de trazar una línea divisoria clara y realizar predicciones con mayor seguridad que GPTZero u Originality.AI.
GPTZero tiende a predecir demasiados ejemplos en el rango de probabilidad de 0,4 a 0,6, con un modo situado justo en torno a 0,5. Por otro lado, el problema de los falsos positivos de Originality.AI se hace aún más evidente al examinar las predicciones «suaves». Muchas reseñas reales están muy cerca de ser predichas como generadas por IA, aunque no superen el umbral de 0,5. Esto hace que al usuario le resulte difícil confiar en que el modelo pueda predecir de forma fiable el texto generado por IA, ya que pequeñas modificaciones en la reseña pueden permitir a un atacante eludir el detector editando la reseña de forma iterativa hasta que quede por debajo del umbral de detección.
Por el contrario, nuestro modelo suele ser muy decisivo. Por lo general, somos capaces de tomar decisiones con seguridad. Para los lectores con conocimientos de aprendizaje profundo o teoría de la información, presentamos la entropía cruzada o la divergencia KL más baja entre la distribución real y la distribución prevista.
Es evidente el valor que tiene identificar con un alto grado de certeza el texto real como tal (véase esta divertida imagen de Twitter). Aunque está claro que este educador malinterpretó la probabilidad indicada por la IA como la cantidad de texto escrito por la IA, cuando los detectores no están seguros de que el texto real sea realmente auténtico, se abre la puerta a interpretaciones erróneas.
 https://twitter.com/rustykitty_/status/1709316764868153537
https://twitter.com/rustykitty_/status/1709316764868153537
De los tres errores detectados por Checkfor.ai, lamentablemente dos de ellos tienen un alto grado de certeza. Nuestro detector no es perfecto, y estamos trabajando activamente en la calibración del modelo para evitar este tipo de predicciones erróneas con un alto grado de certeza.
Conclusión
Vamos a publicar en código abierto los conjuntos de datos utilizados para esta evaluación de reseñas reales y falsas de Yelp, con el fin de que los modelos futuros puedan utilizar este importante punto de referencia para comprobar la precisión de sus detectores.
Las principales conclusiones son:
Checkfor.ai presenta una baja tasa tanto de falsos positivos como de falsos negativos. Checkfor.ai es capaz de distinguir entre reseñas reales y generadas por IA no solo con gran precisión, sino también con un alto grado de fiabilidad. En el futuro publicaremos más entradas de blog de este tipo y compartiremos públicamente nuestras valoraciones sinceras sobre nuestro modelo a medida que aprendamos más. ¡Estad atentos y contadnos qué os parece!

Bradley es investigador en inteligencia artificial y experto en el desarrollo de productos de aprendizaje profundo para el sector industrial. Recientemente ha dirigido el grupo de investigación en aprendizaje profundo de Absci, una empresa dedicada al descubrimiento de fármacos mediante IA generativa, y anteriormente formó parte del equipo principal de visión artificial de Tesla Autopilot.
Durante sus estudios de posgrado, Bradley fue autor de varias publicaciones sobre investigación en aprendizaje profundo en el Stanford Vision Lab. Es licenciado en Física y tiene un máster en Inteligencia Artificial por la Universidad de Stanford. Además de la IA, le apasionan la educación y la filosofía, y es un ávido golfista.
Lecturas relacionadas

¿En qué se diferencia Pangram de GPTZero?
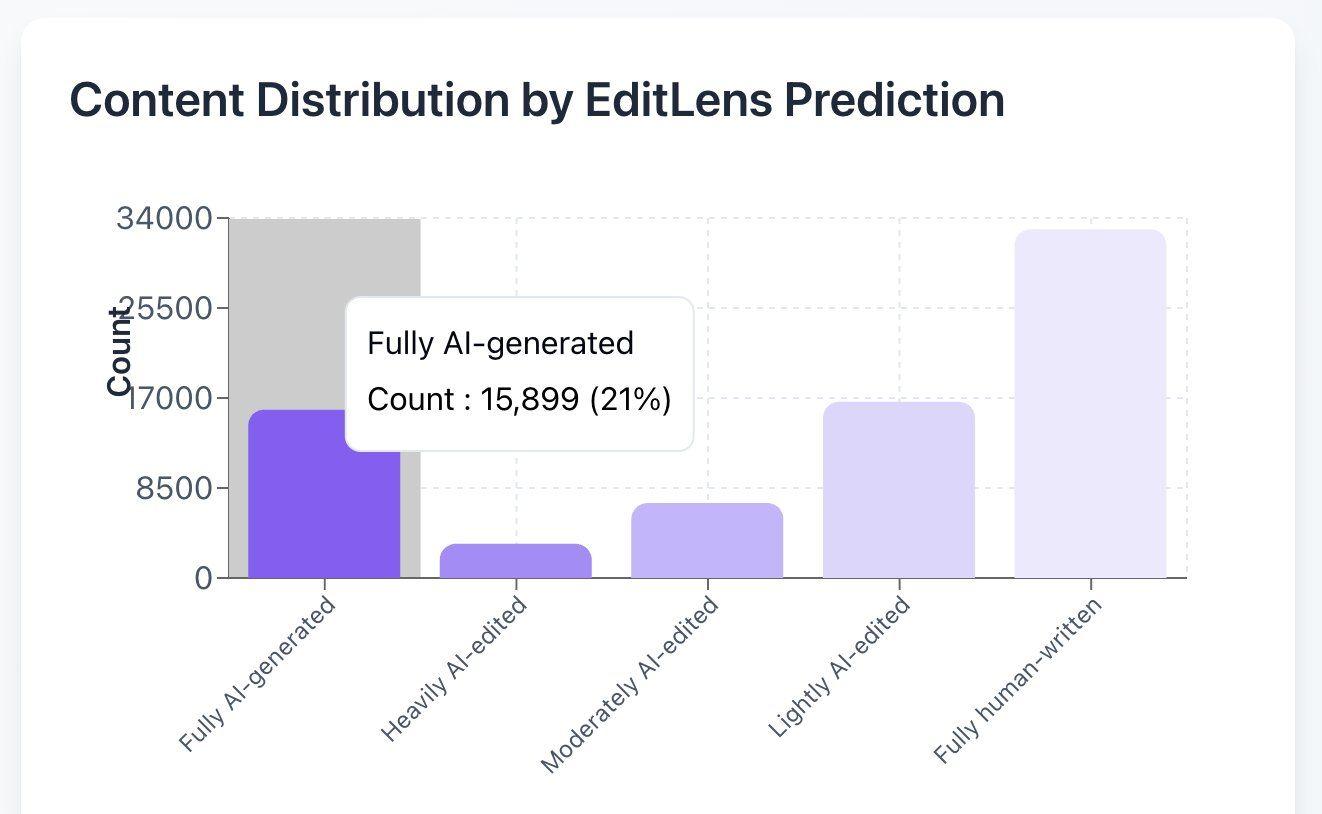
Pangram prevé que el 21 % de las reseñas de la ICLR sean generadas por IA

Cómo detectar las reseñas generadas por IA

Evaluaciones de pangramas realizadas por terceros

Cómo preparar tu empresa para el LLM y la IA general

La IA está escribiendo obras de ficción galardonadas
