A Pangram prevê que 21% das revisões da ICLR são geradas por IA
Índice
- Por que razão se deve analisar as comunicações apresentadas na ICLR?
- É permitido o uso de IA nas submissões e na revisão por pares da ICLR?
- Metodologia
- Resultados
- Análise
- A utilização da IA em artigos está associada a avaliações menos favoráveis
- As avaliações feitas por IA têm pontuações mais elevadas
- As avaliações da IA são mais longas
- Existem falsas acusações?
- Como é que se sabe se se recebeu uma revisão por pares feita por IA?
- Por que razão os artigos sobre IA e as revisões por pares na área da IA são prejudiciais ao processo científico?
- Conclusão
Os autores estão a utilizar modelos de linguagem de grande escala (LLMs) para escrever artigos de investigação sobre IA? Os revisores estão a subcontratar a redação das suas revisões desses artigos a ferramentas de IA generativa? Para descobrir, analisámos todos os 19 000 artigos e 70 000 revisões da Conferência Internacional sobre Representações de Aprendizagem (ICLR), um dos fóruns de publicação de investigação em IA mais importantes e prestigiados. Graças ao OpenReview e ao processo de revisão pública da ICLR, todos os artigos e as respetivas revisões foram disponibilizados publicamente online, e este processo de revisão aberta tornou possível esta análise.
Disponibilizámos todos os resultados ao público em iclr.pangram.com.
Por que razão se deve analisar as comunicações apresentadas na ICLR?
Bem, para começar, ofereceram-nos uma recompensa!
 O tweet de Graham Neubig a oferecer uma recompensa pela análise das propostas apresentadas ao ICLR
O tweet de Graham Neubig a oferecer uma recompensa pela análise das propostas apresentadas ao ICLR
Falando com toda a seriedade, muitos autores e revisores da ICLR têm vindo a constatar alguns casos de má conduta científica flagrante relacionada com a IA, tais como um artigo gerado por um LLM com referências totalmente inventadas, e muitos autores que afirmam ter recebido revisões inteiramente geradas por IA.
Um autor chegou mesmo a relatar que um revisor fez 40 perguntas geradas por IA na sua revisão por pares!
Queríamos avaliar a dimensão deste problema em geral: será que estes exemplos de mau comportamento são incidentes isolados, ou serão indicativos de um padrão mais alargado? Foi por isso que aceitámos a proposta do Graham!
É permitido o uso de IA nas submissões e na revisão por pares da ICLR?
A ICLR tem uma política muito clara e detalhada sobre o que é permitido e o que não é permitido no que diz respeito à utilização de modelos de linguagem de grande escala (LLM), tanto em artigos como em revisões.
Política 1. Qualquer utilização de um LLM deve ser divulgada, em conformidade com as disposições do Código de Ética que estabelecem que «todas as contribuições para a investigação devem ser reconhecidas» e que os colaboradores «devem esperar… receber o devido reconhecimento pelo seu trabalho».
Política 2. Os autores e revisores da ICLR são os responsáveis finais pelas suas contribuições, em conformidade com o Código de Ética, segundo o qual «os investigadores não devem, deliberadamente, fazer afirmações falsas ou enganosas, inventar ou falsificar dados, nem deturpar resultados».
O ICLR também dispõe de diretrizes que os autores devem seguir ao utilizarem modelos de linguagem de grande escala (LLMs) nos seus artigos e revisões. Em resumo:
- Os autores podem utilizar modelos de linguagem de grande escala (LLMs) para auxiliar na redação dos seus artigos e como assistentes de investigação, mas devem divulgar essa utilização e são responsáveis pela integridade científica dos seus artigos.
- Os autores podem recorrer a modelos de linguagem de grande escala (LLM) para obter ajuda com a ortografia e a gramática nas suas revisões de artigos sobre LLM; no entanto, a utilização de um LLM para redigir a revisão na íntegra constitui potencialmente uma violação do Código de Ética, tanto por apresentar falsamente uma opinião ou perspetiva externa sobre o artigo como se fosse sua, como por violar a confidencialidade.
Por isso, não realizamos este estudo com o objetivo de denunciar infratores individuais — uma vez que os LLMs são, de facto, permitidos tanto na submissão de artigos como no processo de revisão por pares. Em vez disso, pretendemos chamar a atenção para a frequência com que a IA é utilizada nos artigos e na revisão por pares, e salientar que as revisões inteiramente geradas por IA (que, na verdade, são suscetíveis de constituir violações do Código de Ética) são um problema muito mais generalizado do que muitos imaginam.
Metodologia
Primeiro, descarregámos todos os ficheiros PDF das submissões ao ICLR utilizando a API do OpenReview. Também descarregámos todas as notas, o que nos permitiu extrair a revisão.
Constatámos que a utilização de um analisador de PDF comum, como o PyMuPDF, era insuficiente para os artigos da ICLR, uma vez que os números de linha, as imagens e as tabelas muitas vezes não eram processados corretamente. Por isso, para extrair o texto principal do artigo, utilizámos o Mistral OCR para analisar o texto principal do artigo a partir do PDF como Markdown. Como a IA também tende a preferir resultados em Markdown, para mitigar os falsos positivos decorrentes apenas da formatação, reformatámos então o Markdown como texto simples.
Em seguida, aplicámos o classificador de texto alargado de Pangram ao texto simples analisado proveniente destes PDFs. A versão alargada do classificador divide primeiro o texto em segmentos e aplica o modelo de deteção de IA a cada segmento individualmente. O resultado é uma percentagem que indica quantos segmentos deram positivo para texto gerado por IA, pelo que o resultado pode indicar que um artigo foi escrito inteiramente por humanos, gerado inteiramente por IA ou misto, com alguns segmentos a darem positivo e outros a darem negativo.
Também analisámos as revisões por pares relativas à IA utilizando o nosso novo modelo EditLens. O EditLens é capaz não só de detetar a presença de IA, como também de descrever o grau de envolvimento da IA no processo de edição. O EditLens consegue prever que um texto se enquadra numa de cinco categorias:
- Totalmente escrito por pessoas
- Ligeiramente editado por IA ou com assistência de IA
- Editado por IA ou com assistência de IA
- Com edição ou assistência intensiva por IA
- Totalmente gerado por IA
O EditLens está atualmente disponível apenas para clientes na nossa versão beta privada, mas será disponibilizado ao público no início de dezembro. Teremos mais a dizer sobre este modelo nas próximas semanas, mas na pré-publicação da nossa investigação, descrevemos o seu desempenho como sendo de ponta na geração de texto em coautoria e, em testes de desempenho internos, apresenta uma precisão semelhante à do nosso modelo atual quando avaliado como um classificador binário, bem como uma taxa de falsos positivos excepcionalmente baixa de 1 em 10 000 em texto escrito inteiramente por humanos.
Resultados
Na nossa análise anterior de artigos de conferências sobre IA, constatámos que o Pangram apresenta uma taxa de falsos positivos de 0% em todos os artigos disponíveis da ICLR e da NeurIPS publicados antes de 2022. Embora alguns desses artigos façam efetivamente parte do conjunto de treino, nem todos estão incluídos; por isso, acreditamos que o verdadeiro desempenho do Pangram no conjunto de teste seja, na realidade, muito próximo de 0%.
E quanto às revisões por pares? Realizámos uma experiência adicional de controlo negativo, na qual aplicámos o modelo EditLens mais recente a todas as revisões por pares de 2022. Constatámos uma taxa de erro de cerca de 1 em 1000 na comparação entre «Ligeiramente editado» e «Totalmente humano», uma taxa de erro de 1 em 5000 na comparação entre «Médio editado» e «Totalmente humano» e uma taxa de erro de 1 em 10 000 na comparação entre «Fortemente editado» e «Totalmente humano». Não constatámos confusões entre «Totalmente gerado por IA» e «Totalmente humano».
 Distribuição das previsões do EditLens nas revisões do ICLR 2022 (controlo negativo)
Distribuição das previsões do EditLens nas revisões do ICLR 2022 (controlo negativo)
Para a experiência em si, aplicámos o Pangram a todos os artigos e revisões por pares. Eis as principais conclusões:
Constatámos que 21 %, ou seja, 15 899 avaliações, foram inteiramente geradas por IA. Verificámos que mais de metade das avaliações contou com algum tipo de intervenção da IA, seja na edição, na assistência ou na geração total por IA.
 Distribuição das previsões do EditLens nas revisões da ICLR 2026
Distribuição das previsões do EditLens nas revisões da ICLR 2026
Por outro lado, os artigos submetidos continuam a ser, na sua maioria, redigidos por humanos (61 % foram redigidos principalmente por humanos). No entanto, identificámos várias centenas de artigos totalmente gerados por IA, embora pareçam ser casos isolados, e 9 % das submissões apresentavam mais de 50 % de conteúdo gerado por IA. É importante referir que alguns artigos totalmente gerados por IA já tinham sido rejeitados à primeira vista e removidos do OpenReview antes de termos tido oportunidade de realizar a análise.
 Distribuição do conteúdo relacionado com IA nas submissões de artigos para a ICLR 2026
Distribuição do conteúdo relacionado com IA nas submissões de artigos para a ICLR 2026
Análise
Identificámos algumas tendências interessantes nos resultados que esclarecem a forma como a IA está a ser utilizada tanto na submissão de artigos como nas revisões por pares, bem como quais são os efeitos decorrentes dessa utilização no próprio processo de revisão.
A utilização da IA em artigos está associada a avaliações menos favoráveis
Ao contrário de um estudo anterior que demonstrou que os LLMs tendem a preferir os seus próprios resultados à escrita humana quando utilizados como avaliadores, constatamos o contrário: quanto maior for a presença de texto gerado por IA numa submissão, piores são as avaliações.
 Pontuações médias das avaliações por conteúdo de IA em artigos
Pontuações médias das avaliações por conteúdo de IA em artigos
Isto pode dever-se a várias razões. Uma delas é que, quanto mais se recorre à IA num artigo, menos bem pensado e executado esse artigo é, em geral. É possível que, quando a IA é utilizada na redação científica, seja mais frequentemente utilizada para descarregar trabalho e tomar atalhos, em vez de ser utilizada como um auxiliar complementar. Além disso, o facto de os artigos totalmente gerados por IA receberem pontuações mais baixas indica potencialmente que a investigação gerada por IA ainda é de baixa qualidade e não constitui (ainda) uma contribuição real para a ciência.
As avaliações feitas por IA têm pontuações mais elevadas
 Pontuação média das avaliações por nível de envolvimento da IA
Pontuação média das avaliações por nível de envolvimento da IA
Constatamos que, quanto maior for a presença da IA numa revisão, mais elevada é a pontuação. Isto é problemático: significa que, em vez de reformularem a sua própria opinião utilizando a IA como estrutura (se fosse esse o caso, esperaríamos que a pontuação média fosse a mesma para as revisões feitas por IA e pelas feitas por humanos), os revisores estão, na verdade, a delegar também o julgamento do artigo à IA. Apresentar a opinião do LLM como se fosse a opinião real do revisor constitui uma clara violação do Código de Ética. Sabemos que a IA tende a ser bajuladora, o que significa que diz coisas que as pessoas querem ouvir e que são agradáveis, em vez de dar uma opinião imparcial: uma característica totalmente indesejável quando aplicada à revisão por pares! Isto poderia explicar o viés positivo nas pontuações das revisões feitas por IA.
As avaliações da IA são mais longas
 Duração média das avaliações por nível de envolvimento da IA
Duração média das avaliações por nível de envolvimento da IA
Anteriormente, uma crítica mais longa significava que a crítica tinha sido bem pensada e era de maior qualidade, mas na era dos LLMs, isso pode muitas vezes significar o contrário. As críticas geradas por IA são mais longas e contêm muito «conteúdo de preenchimento». De acordo com Shaib et al., num artigo de investigação intitulado «Measuring AI Slop in Text», uma das características do «slop» da IA é a sua baixa densidade de informação — o que significa que a IA utiliza muitas palavras para dizer muito pouco em termos de conteúdo real.
Constatamos que o mesmo se verifica nas revisões feitas por modelos de linguagem de grande escala (LLM): a IA utiliza muitas palavras, mas não fornece, na verdade, um feedback com grande densidade de informação. Consideramos que isto é problemático porque os autores têm de perder tempo a analisar uma revisão longa e a responder a perguntas vazias que, na verdade, não contêm feedback muito útil. Vale também a pena mencionar que a maioria dos autores provavelmente pedirá a um modelo de linguagem de grande dimensão uma revisão do seu trabalho antes de o submeterem efetivamente. Nestes casos, o feedback de uma revisão do LLM é, em grande parte, redundante e inútil, porque o autor já viu as críticas óbvias que um LLM irá fazer.
Existem falsas acusações?
Embora a taxa de falsos positivos do Pangram seja extremamente baixa, não é nula e, por isso, temos a responsabilidade de quantificar a fiabilidade da ferramenta antes de a recomendarmos para tomar decisões concretas sobre o destino de um artigo (como uma rejeição à primeira vista) ou para punir um revisor. Medimos diretamente a taxa de falsos positivos no domínio específico utilizando os estudos de controlo negativo descritos acima, mas e em outros conjuntos de dados, benchmarks e em textos gerais?
Documentámos a taxa de falsos positivos do Pangram nesta publicação anterior do blogue.
- A taxa global de falsos positivos do Pangram é de 1 em cada 10 000 nos documentos do conjunto de teste.
- A taxa de falsos positivos do Pangram em artigos científicos não incluídos na análise, provenientes do ArXiV, é de 1 em 100 000.
- A taxa de falsos positivos do Pangram em artigos médicos da PubMed utilizados como amostra de validação é de 0 (com uma precisão de 3 casas decimais).
A precisão do Pangram também foi comprovada por vários estudos independentes, incluindo estudos recentes realizados pela UChicago Booth e pela Associação Americana para a Investigação do Cancro.
Para contextualizar estes números, a taxa de falsos positivos do Pangram é comparável à taxa de falsos positivos dos testes de ADN ou dos testes de despistagem de drogas: um falso positivo verdadeiro, em que um texto inteiramente gerado por IA é confundido com um texto inteiramente escrito por humanos, não é nulo, mas é extremamente raro.
Como é que se sabe se se recebeu uma revisão por pares feita por IA?
Se é um autor e suspeita que recebeu uma crítica gerada por IA, existem vários sinais reveladores a que pode estar atento. Embora o Pangram consiga detetar texto gerado por IA, também é possível identificar os sinais de críticas geradas por IA a olho nu.
Elaborámos um guia geral para identificar padrões de escrita da IA a olho nu, mas constatamos a presença de alguns sinais e indicadores adicionais especificamente nas revisões por pares realizadas por IA.
Alguns dos «sinais» que observamos nas revisões por pares de IA:
- Estilos de cabeçalho: as revisões por pares geradas por IA tendem a criar cabeçalhos de secção em negrito com tags de resumo de 2 a 3 palavras, seguidas de dois pontos. Por exemplo:
Pontos fortes: Formulação clara do problema: O artigo aborda um problema real — os sistemas de OCR baseados em VLM produzem resultados errados em documentos danificados sem sinalizar a incerteza, o que é pior do que os sistemas de OCR clássicos, que produzem resultados visivelmente distorcidos. A motivação está bem articulada. Metodologia sistemática: A abordagem de treino em duas fases (arranque a frio com pseudo-rotulagem + GRPO) é razoável e bem descrita. O desenho de recompensa multi-objetivo com salvaguardas contra a manipulação da recompensa (especialmente o fator de amortecimento η para a incompatibilidade de comprimento) demonstra uma engenharia cuidadosa.
Questões: 1. Generalização para degradações reais: Os autores podem realizar uma avaliação em documentos degradados do mundo real (por exemplo, conjuntos de dados de documentos históricos) para demonstrar que a abordagem se generaliza para além do pipeline específico de degradação sintética? 2. Comparação com os sistemas MinerU: O MinerU e o MinerU2.5 [2,3] representam avanços recentes na análise de documentos. Como se compara o método proposto com estes sistemas no Blur-OCR? Se estes sistemas não conseguirem produzir estimativas de incerteza, poderão ser combinados com a abordagem de etiquetagem proposta?
-
Pequenas críticas superficiais em vez de uma análise genuína: as revisões geradas por IA tendem a centrar-se em questões superficiais, em vez de preocupações reais com a integridade científica do artigo. As críticas típicas da IA podem incluir a necessidade de mais ablações muito semelhantes às apresentadas, o pedido de aumento do tamanho do conjunto de teste ou do número de controlos, ou a solicitação de mais esclarecimentos ou exemplos.
-
Muitas palavras para dizer muito pouco: as críticas de IA apresentam frequentemente uma baixa densidade de informação, recorrendo a uma linguagem prolixa para transmitir ideias que poderiam ser expressas de forma mais concisa. Esta prolixidade cria trabalho adicional aos autores, que têm de analisar críticas extensas para extrair as críticas de fundo.
Por que razão os artigos sobre IA e as revisões por pares na área da IA são prejudiciais ao processo científico?
No início deste ano, investigadores da UNIST, na Coreia, publicaram um documento de posição no qual expõem algumas das razões para o declínio da qualidade do processo de revisão por pares. À medida que a IA continua a crescer como área de estudo, a pressão sobre os recursos do sistema de revisão por pares está, em última análise, a começar a revelar fissuras. Simplesmente, há um número limitado de revisores qualificados para fazer face ao aumento explosivo do número de artigos.
O maior problema dos artigos de fraca qualidade gerados por IA é que estes simplesmente desperdiçam tempo e recursos que são limitados. De acordo com a nossa análise, os artigos gerados por IA simplesmente não são tão bons quanto os escritos por humanos e, o que é ainda mais problemático, podem ser produzidos a baixo custo por revisores desonestos e por «fábricas de artigos» que adotam a estratégia de «spray and pray» (enviar um grande volume de submissões a uma conferência na esperança de que uma delas seja aceite por acaso). Se se permitir que os artigos gerados por IA inundem o sistema de revisão por pares, a qualidade da revisão continuará a diminuir e os revisores ficarão menos motivados por terem de ler artigos «de má qualidade» em vez de investigação a sério.
Compreender por que razão as revisões geradas por IA podem ser prejudiciais é um pouco mais complexo. Concordamos com a ICLR que a IA pode ser utilizada de forma positiva como ferramenta de apoio para ajudar os revisores a articular melhor as suas ideias, especialmente quando o inglês não é a língua materna do revisor. Além disso, a IA pode frequentemente fornecer feedback genuinamente útil, e é muitas vezes produtivo para os autores simular o processo de revisão por pares com LLMs, para que estes critiquem e apontem falhas na investigação, e identifiquem erros e falhas que o autor possa não ter detetado inicialmente.
No entanto, a questão permanece: se a IA é capaz de gerar feedback útil, por que razão deveríamos proibir as revisões geradas inteiramente por IA? O economista Alex Imas, da Universidade de Chicago, resume a questão central num tweet recente: a resposta depende de querermos ou não que o julgamento humano faça parte da revisão por pares científica.
 Tweet de Alex Imas sobre críticas geradas por IA
Tweet de Alex Imas sobre críticas geradas por IA
Se acreditarmos que os modelos atuais de IA são suficientes para substituir totalmente o julgamento humano, então as conferências deveriam simplesmente automatizar todo o processo de revisão — submeter os artigos a um LLM e atribuir pontuações automaticamente. Mas se acreditarmos que o julgamento humano deve continuar a fazer parte do processo, então o conteúdo gerado inteiramente por IA deve ser sancionado. Imas identifica dois problemas principais: em primeiro lugar, um equilíbrio de aglomeração em que o conteúdo gerado por IA (sendo mais fácil de produzir) irá rapidamente suplantar o julgamento humano no espaço de alguns ciclos de revisão; e, em segundo lugar, um problema de verificação em que determinar se uma revisão feita por IA é realmente boa requer o mesmo esforço que revisar o artigo pessoalmente — por isso, se os LLMs conseguem gerar revisões melhores do que os humanos, por que não automatizar todo o processo?
Na minha opinião, as avaliações humanas são complementares, mas acrescentam um valor distinto às análises da IA. Muitas vezes, os seres humanos conseguem apresentar comentários fora do padrão que podem não ser imediatamente evidentes. As opiniões de especialistas são mais úteis do que os modelos de linguagem de grande escala (LLMs), porque são moldadas pela experiência, pelo contexto e por uma perspetiva que é aperfeiçoada e refinada ao longo do tempo. Os LLMs são poderosos, mas as suas análises carecem frequentemente de bom gosto e discernimento, pelo que parecem «sem graça».
Talvez, no futuro, as conferências possam apresentar a análise do LLM SOTA a par das análises humanas, para garantir que estas últimas não se limitem a reiterar as críticas «óbvias» que podem ser apontadas por um LLM.
Conclusão
O aumento do conteúdo gerado por IA na revisão por pares académica representa um desafio crucial para a comunidade científica. A nossa análise mostra que as revisões por pares inteiramente geradas por IA representam uma proporção significativa do conjunto total de revisões da ICLR, e o número de artigos gerados por IA também está a aumentar. No entanto, estes artigos gerados por IA são, na maioria das vezes, trabalhos de má qualidade, em vez de verdadeiras contribuições para a investigação.
Consideramos que esta tendência é problemática e prejudicial para a ciência, e apelamos às conferências e às editoras para que adotem a deteção por IA como solução para dissuadir abusos e preservar a integridade científica.

Bradley é investigador na área da IA e especialista no desenvolvimento de produtos de aprendizagem profunda no setor industrial. Recentemente, liderou o grupo de investigação em aprendizagem profunda da Absci, uma empresa de descoberta de medicamentos que utiliza IA generativa, e, anteriormente, integrou a equipa principal de visão computacional do Tesla Autopilot.
Enquanto estudante de pós-graduação, Bradley foi autor de várias publicações na área da investigação sobre aprendizagem profunda no Stanford Vision Lab. É licenciado em Física e mestre em Inteligência Artificial pela Universidade de Stanford. Para além da IA, interessa-se também por educação e filosofia, e é um ávido jogador de golfe.
Leitura relacionada

Como o Gradpilot utiliza o Pangram para ajudar os alunos a encontrar a sua voz

Qual é o detetor de IA mais preciso? 30 ferramentas testadas (2026)
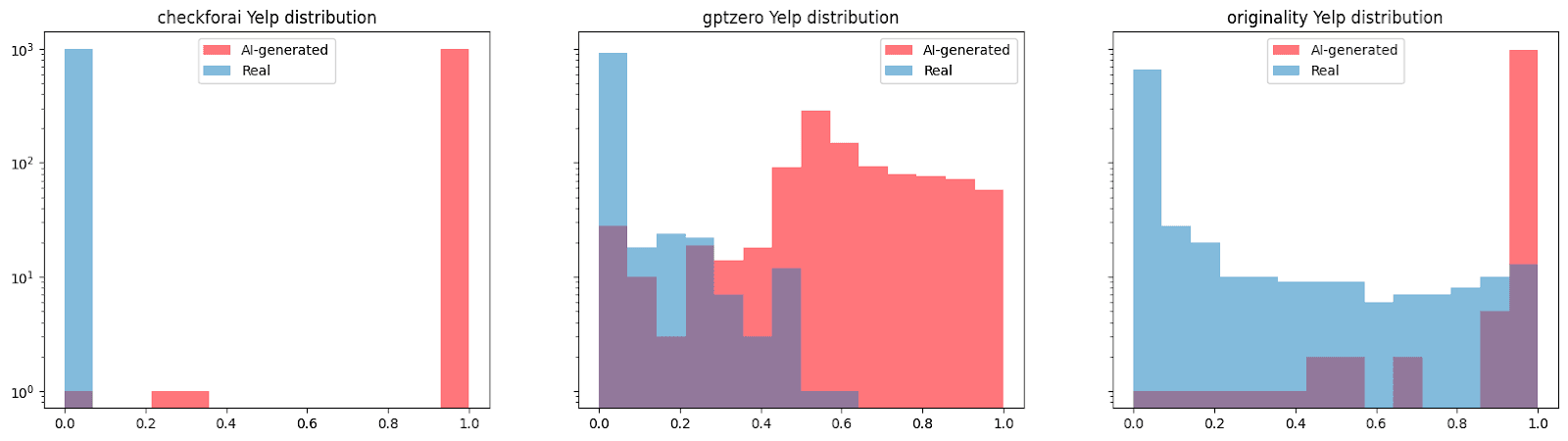
Análise aprofundada das avaliações no Yelp

Como se compara o Pangram com o GPTZero?

Como o Quora utiliza o Pangram para gerir respostas escritas por IA

Três por cento das críticas na primeira página da Amazon são agora geradas por IA
para receber as nossas atualizações
