Mitarbeiter im Fokus: Lernen Sie Katherine kennen, Forscherin im Bereich KI
Mitarbeiter im Fokus: Katherine Thai
Willkommen zu unserer zweiten Mitarbeiter-Porträtreihe! Wir haben uns mit Katherine Thai, unserer Gründungswissenschaftlerin im Bereich KI, zusammengesetzt, um über ihren einzigartigen Werdegang im Bereich NLP, ihre Forschung zur Literaturanalyse und ihre Arbeit bei Pangram Labs zu sprechen. (Hinweis: Dieses Interview wurde transkribiert und zur besseren Lesbarkeit durch KI leicht überarbeitet.)
Von Mathematik und Englisch zur NLP-Forschung
Wie bist du auf NLP gekommen und wie kam es zu deiner Entscheidung, zu promovieren?
Anfangs habe ich mich nie direkt für NLP interessiert. Im Grundstudium habe ich Mathematik, Informatik und Englisch studiert und an vielen Forschungsprogrammen für Studierende teilgenommen, weil mir die Idee von Forschung und Experimentieren sehr gefiel, aber ich wusste nicht genau, was ich studieren wollte.
Als mein letztes Studienjahr näher rückte, meinte ein Kommilitone, mein Englischstudium sei ideal für ein Studium der NLP, da es sich dabei um die Anwendung von Computern auf Text handele. Ich hatte noch nie viel davon gehört – an meiner Hochschule gab es weder NLP-Forscher noch entsprechende Kurse.
Schließlich fand ich meinen jetzigen Betreuer, Mohit Iyyer, der sich mit dem narrativen Verständnis langer Geschichten und Bücher beschäftigte. Das hat mich sehr fasziniert, da ich Bücher liebe und meine Bachelorarbeit unter dem Titel „Narrative Mechanismen der Frustration“ geschrieben hatte. Als ich mich bewarb, dachte mein Betreuer, es handele sich dabei um technische Mechanismen der Informatik, aber das war nicht der Fall – es war einfach meine Art, zu beschreiben, was in der Literatur vor sich ging! Er fand meinen Hintergrund überzeugend und war der Meinung, dass mir meine mathematischen Kenntnisse helfen würden, die Grundlagen zu erlernen. Ich habe meinen ersten NLP-Kurs buchstäblich in meinem ersten Semester der Promotion belegt.
Literaturwissenschaft mit KI
Erzählen Sie uns etwas über Ihre Doktorarbeit.
Meine Abschlussarbeit trägt den Titel „Formen der Zusammenarbeit zwischen Mensch und KI im Textbereich: Benchmarks, Metriken und interpretative Aufgaben“. Ich möchte herausfinden, wie Sprachmodelle Texte interpretieren und tiefgreifendere Schlussfolgerungen ziehen können als Geisteswissenschaftler, anstatt sich nur auf oberflächliche Merkmale zu beschränken.
Die frühen NLP-Arbeiten im Bereich der Literatur konzentrierten sich darauf, benannte Entitäten aus Büchern zu extrahieren, die Interaktionen zwischen den Figuren abzubilden und grobe Zeitachsen der Handlung zu erstellen. Mich interessieren vielmehr übergreifende Themen, die sich durch ganze Texte ziehen, wie die Motivationen der Figuren ihre Entscheidungen beeinflussen und wie Texte in den größeren Kontext eingebettet sind, nämlich wann und wo der Autor sie geschrieben hat.
Ich betrachte dies in erster Linie als Bewertungsproblem – um zu prüfen, ob Sprachmodelle in der Lage sind, diese übergeordneten Ideen aus literarischen Texten zu extrahieren.
Wie war es, sich während Ihrer Promotion mit Literaturanalyse unter Einbeziehung von KI zu beschäftigen, als ChatGPT aufkam?
Dazu habe ich eine verrückte Geschichte zu erzählen. In meiner ersten Doktorarbeit habe ich eine Aufgabe namens „Literary Evidence Retrieval“ vorgeschlagen. Da Wissenschaftler in ihren Analysen stets Zitate aus Primärtexten anführen, haben wir Absätze ausgewählt, in denen Geisteswissenschaftler „Der große Gatsby“ analysierten, die Zitate aus dem Roman ausgeblendet und Sprachmodelle gebeten, diese Zitate wiederzufinden.
In meiner ersten Arbeit habe ich einen kleinen, kompakten, auf RoBERTa basierenden Retriever verwendet, da wir keine ganzen Romane in die Sprachmodelle einspeisen konnten. Ich habe im Abschnitt zur Begründung wörtlich geschrieben, dass wir diesen Ansatz benötigten, weil wir keine vollständigen Romane in den Kontext einspeisen konnten.
Fünf Jahre später habe ich mich in meiner jüngsten Arbeit erneut mit dieser Aufgabe befasst, diesmal unter Verwendung großer Sprachmodelle, die ganze Romane verarbeiten können. Im Februar habe ich mich zum ersten Mal selbst an dieser Aufgabe versucht – ich habe dafür acht Stunden gebraucht, mit gedruckten Büchern. Keines der Modelle schnitt bei 40 Beispielen so gut ab wie ich. Doch als der Artikel drei Monate später angenommen wurde, war Gemini Pro 2.5 bereits auf dem Markt und übertraf meine Leistung. Es war zwar nur eine kleine Stichprobe, aber es war unglaublich zu sehen, wie schnell sich die Dinge entwickelt haben.
Zu Beginn meiner Promotion habe ich keine Prompts geschrieben. Das war undenkbar. Heute nutzt meine Mutter LLMs in ihrem Beruf – früher hatte sie keine Ahnung, woran ich arbeitete, und jetzt hat sie Zugriff auf LLMs für Unternehmen.
 Katherine verteidigt ihre Doktorarbeit
Katherine verteidigt ihre Doktorarbeit
Inwiefern unterscheiden sich deiner Meinung nach die Lesegewohnheiten von LLMs von denen von Menschen?
Der offensichtlichste Unterschied ist die Geschwindigkeit – Gemini liefert die Antwort innerhalb von 30 Sekunden, während ich im Durchschnitt 12 Minuten pro Beispiel gebraucht habe. Als ich meine Fehler durchging, fiel mir oft einfach kein bestimmter Satz aus den 200 bis 400 Seiten starken Romanen ein, während das Modell sich perfekt daran erinnerte.
Ich glaube, dass große Sprachmodelle (LLMs) Text Zeichen für Zeichen verarbeiten, ähnlich wie beim genauen Lesen in der Literaturanalyse, bei dem man den Text auf der Wortebene zerlegt. Aber wenn Menschen 400 Seiten lesen, wird nicht jedes Wort in unserem Gehirn als eigenständige Einheit registriert, so wie es bei Modellen der Fall sein mag.
Die Herausforderung der Bewertung
Warum ist es so schwierig, gute Bewertungen zu entwickeln, und warum besteht eine so große Diskrepanz zwischen den aktuellen Bewertungen und dem, was die Menschen tatsächlich mit diesen Modellen erleben?
Es ist das Spannungsfeld zwischen dem Wunsch, Bewertungen durch automatisierte Verfahren schnell zu skalieren, und der Notwendigkeit einer detaillierten Bewertung durch menschliche Experten. Ein Großteil meiner Arbeit konzentrierte sich darauf, in die Einstellung echter Experten zu investieren. Für die maschinelle Übersetzung von Literatur haben wir Literaturübersetzer mit einem Doktortitel in Vergleichender Literaturwissenschaft eingestellt. Ihre Erkenntnisse unterschieden sich deutlich von denen, die man von Mechanical Turk-Nutzern erhalten würde, selbst bei einfachen A/B-Tests.
Die Kehrseite sind die Kosten für die Erstellung von Bewertungen. Ich habe im vergangenen Jahr an einem Benchmark für Agenten mitgearbeitet, bei dem wir die Fragen manuell erstellt und alle Agenten von Hand bewertet haben. Ich habe wahrscheinlich den gesamten März damit verbracht, dem Operator von OpenAI dabei zuzusehen, wie er sich durch die Oberfläche klickte und nach Dingen suchte. Es hat sehr lange gedauert, selbst nur 100 bis 150 Beispiele durchzugehen, aber wir haben so viel gelernt, weil wir mit eigenen Augen sehen konnten, was die Agenten taten.
Es besteht ein ständiger Spannungszustand zwischen dem Wunsch, Evaluierungen in größerem Maßstab durchzuführen, und der Notwendigkeit einer langsameren, detaillierten menschlichen Bewertung.
Entwicklung der KI-Erkennung bei Pangram
Woran arbeitest du bei Pangram?
Ich arbeite an einem Modell, das erkennen kann, inwieweit ein Text von KI beeinflusst wurde. Wir wissen, dass Menschen nicht nur Texte mit KI erstellen – oft bringen sie selbst verfasste Texte mit und bitten die KI, diese zu überarbeiten. Diese Überarbeitungen reichen von kleinen grammatikalischen Korrekturen bis hin zu umfassenden Umstrukturierungen oder vollständigen Umformulierungen.
Wir möchten diesen Effekt messen, da wir das Spektrum von von Menschen verfassten Texten bis hin zu vollständig von KI verfassten Texten als Kontinuum betrachten können, wobei von KI überarbeitete Texte irgendwo dazwischen liegen. Wir trainieren ein Modell, um zu ermitteln, an welcher Stelle dieses Spektrums ein Text angesiedelt ist.
Das ist für unsere Kunden aus dem Bildungsbereich besonders wichtig, aber da LLMs mittlerweile in Textverarbeitungsprogramme wie Google Docs integriert sind, haben wir auch von vielen anderen Interessenten Anfragen erhalten. Die Leute möchten wissen, inwieweit KI in einen Text eingreift – welche Änderungen „verzeihlich“ sind und welche dem Nutzer eine erhebliche kognitive Entlastung bieten.
 Katherine und das Team arbeiten bis spät in die Nacht an einer Forschungsarbeit
Katherine und das Team arbeiten bis spät in die Nacht an einer Forschungsarbeit
Warum haben Sie sich entschieden, als Gründungsforscher bei Pangram einzusteigen?
Ich liebe das Team hier. Bradley und Max haben mit dem Gründungsteam wirklich ganze Arbeit geleistet. Ich verbringe 90 % meiner Zeit mit den Leuten von Pangram, aber ehrlich gesagt würde ich es nicht anders haben wollen – was sich auch daran zeigt, dass ich in den letzten 10 Tagen mit allen zusammen trainiert habe!
Es ist wirklich schön, einen Büroraum zu haben, in den man gehen kann. Ich war eine Zeit lang Doktorandin im Homeoffice, und es macht Spaß, einen Ort zu haben, an dem alle auf ein gemeinsames Ziel hinarbeiten. Ich habe meine Promotion direkt nach dem Bachelor im ersten Jahr der Corona-Pandemie begonnen, daher fand alles komplett im Homeoffice statt und ich konnte nirgendwo hingehen. Ich habe noch nie in einem Büro gearbeitet oder einen „normalen Job“ gehabt.
Bradley ist einer der klügsten Menschen, unter denen ich je gearbeitet habe – das ist nicht einmal übertrieben. Ich habe das Gefühl, so viel gelernt zu haben, und sammle praktische Erfahrungen mit Dingen, zu denen ich während meiner Promotion nicht gekommen bin. Als die LLMs auf den Markt kamen, wollten alle daran forschen, und wir haben die Modellierung ganz vergessen. Es hatte keinen Sinn, ein eigenes Modell zu trainieren, um mit den großen Labors mithalten zu können, daher hatte ich außer Feinabstimmung nicht viel Modellierung betrieben.
Es war echt toll, praktische Fähigkeiten zu erwerben. Ich bin kein guter Softwareentwickler, weil ich Forscher bin, aber das hat mir Spaß gemacht. Elyas hat mir heute eine halbe Stunde lang dabei geholfen, GitHub-Issues zu beheben! Und die Möglichkeit, mit klugen Leuten zusammenzuarbeiten, zu forschen und in Brooklyn zu sein – es ist ein toller Standort, und ich liebe die Ostküste.
Ein KI-Skeptiker in der KI-Forschung
Sie sind eher ein Skeptiker als ein Optimist, was KI angeht, und nutzen KI in Ihrem Alltag kaum. Worauf beruht diese Skepsis?
Zwei Dinge. Im Kleinen betrachtet bin ich der Einzige unter meinen engen Freunden aus dem Studium, der in die Informatikforschung gegangen ist. Die anderen sind Versicherungsmathematiker und wussten nichts von Sprachmodellierung, als diese aufkam. Sie hörten erst von ChatGPT, als Instagram KI in Suchleisten und Chat-Funktionen integrierte. Lange Zeit war ich der Einzige, der diese Technologien kannte, aber meinen Freunden schien es gut zu gehen, auch ohne sie. Mir wurde klar, wie viel KI-Zeug sich mietfrei in meinem Kopf eingenistet hatte, während sie sich dessen selig nicht bewusst waren, aber trotzdem gut zurechtkamen.
Ich befand mich in dieser Echokammer, in der die Leute entweder AI-Pessimisten waren oder LLMs in den Himmel lobten, aber das ist nicht das, worüber 95 % der Menschen sprechen.
Auf einer philosophischen Ebene wurde mir im Laufe meiner schriftstellerischen Reise – in der ich gelernt habe, dass ich nicht schreiben, sondern lieber analysieren möchte – klar, dass ich nur Texte schätze, die von Menschen stammen. Es ist mir egal, was LLMs schreiben oder ob sie literarische Analysen durchführen können, denn ich glaube, dass die Fähigkeit, solche Dinge zu tun, nur für Menschen wertvoll ist. Es ist eine Fähigkeit, die Menschen besitzen können, aber ich glaube nicht, dass es etwas bedeutet, wenn ein LLM diese Fähigkeit besitzt.
Schreiben ist eine sehr menschliche Tätigkeit, und ich schätze es sehr, dass ein Mensch dahintersteckt. Das hat mich zu einem schlechten KI-Textdetektor gemacht, weil ich einfach keine KI-Texte lese!
Das Leben außerhalb der Arbeit
Was machst du gerne in deiner Freizeit?
Ich gehe sehr gerne mit meinen Hunden in Brooklyn spazieren – ich habe zwei Hunde, und einer von ihnen liebt lange Spaziergänge. Ich treibe gerne Sport, lese gerne Belletristik und stricke und häkele ziemlich gerne.
Du hast dir zum Ziel gesetzt, diesen Sommer mit allen aus dem Pangram-Team zu trainieren. Was war bisher dein Lieblingsworkout?
Ich denke gerade ans Klettern mit Lu – was gut passt, denn in 45 Minuten geht’s schon wieder los! Klettern ist sehr gesellig, weil man zwischen den Versuchen Pausen macht und sich dabei unterhält und Zeit miteinander verbringt.
Ich habe Kickboxen gemacht, was die ganze Zeit über sehr intensiv war und an einzelnen Boxsäcken stattfand, also nicht so teamorientiert. Und ich habe noch ein weiteres Training mit unseren Gründern absolviert, das die ganze Stunde lang das reinste Chaos war – keine Gelegenheit zum Reden, wir haben einfach nur versucht, zu überleben! Die Stimmung war zeitweise sehr gut, auch wenn sie für Max an manchen Stellen vielleicht etwas gedrückt war. Es war eine tolle Erfahrung, die das Team zusammengeschweißt hat, aber Klettern gewinnt, weil es am geselligsten ist.
Tipps für angehende Forscher
Welchen Rat würden Sie jemandem geben, der in die ML-Forschung einsteigen möchte?
Zwei wichtige Dinge: Versuche nicht, Projekte ganz alleine zu bewältigen. Manche Doktoranden in der Anfangsphase tappen in diese Falle, aber du musst mit Leuten zusammenarbeiten, die mehr Erfahrung haben als du. Wenn es dein erstes Projekt ist, ist es ehrlich gesagt völlig in Ordnung, wenn sie Dinge tun, die dich schockieren und beeindrucken – du wirst durch die Zusammenarbeit mit sehr klugen Leuten unglaublich viel lernen.
Zweitens musst du diese Dinge selbst ausprobieren und deine Komfortzone verlassen. Ich habe Python nur gelernt, weil ich mich entschlossen hatte, es einen Sommer lang als meine einzige Programmiersprache für ein Forschungsprojekt zu nutzen. Gehe bei allem sehr praxisorientiert vor, auch bei der Mathematik – schreibe Ableitungen von Hand auf!
Vor sechs Monaten bin ich regelrecht süchtig nach „Math Academy“ geworden – das war zwar verrückt, aber großartig, um mich wieder mit den mathematischen Grundlagen vertraut zu machen.
 Katherine bei Pangram
Katherine bei Pangram
Katherine hat kürzlich ihre Promotion in Informatik an der UMass Amherst abgeschlossen und wird als unsere erste wissenschaftliche Mitarbeiterin in Vollzeit bei Pangram Labs einsteigen. Wenn sie gerade keine KI-Erkennungsmodelle trainiert oder Literatur mit Sprachmodellen analysiert, trifft man sie beim Spaziergang mit ihren Hunden in Brooklyn oder bei der Planung des nächsten Teamtrainings an.

Bradley ist KI-Forscher und Experte für die Entwicklung von Deep-Learning-Produkten in der Industrie. Zuletzt leitete er die Deep-Learning-Forschungsgruppe bei Absci, einem Unternehmen für generative KI in der Arzneimittelforschung, und war zuvor Mitglied des Kernteams für Computer Vision bei Tesla Autopilot.
Während seines Masterstudiums verfasste Bradley im Rahmen des Stanford Vision Lab mehrere Veröffentlichungen im Bereich der Deep-Learning-Forschung. Er hat einen Bachelor of Science in Physik und einen Master of Science in Künstlicher Intelligenz von der Stanford University. Neben KI interessiert er sich auch für Bildung und Philosophie und ist ein begeisterter Golfer.
Weiterführende Literatur

Stellungnahme zu Bidens Verordnung zur Sicherheit künstlicher Intelligenz

Shoppen bis zum Umfallen: KI hält Einzug in Produkte und deren Marketing

Die Informationstheorie hinter der Frage, warum KI-Texte so schlecht sind
Meta wird damit beginnen, KI-generierte Inhalte zu kennzeichnen

Pangram Space: ein interaktives Forschungsprojekt
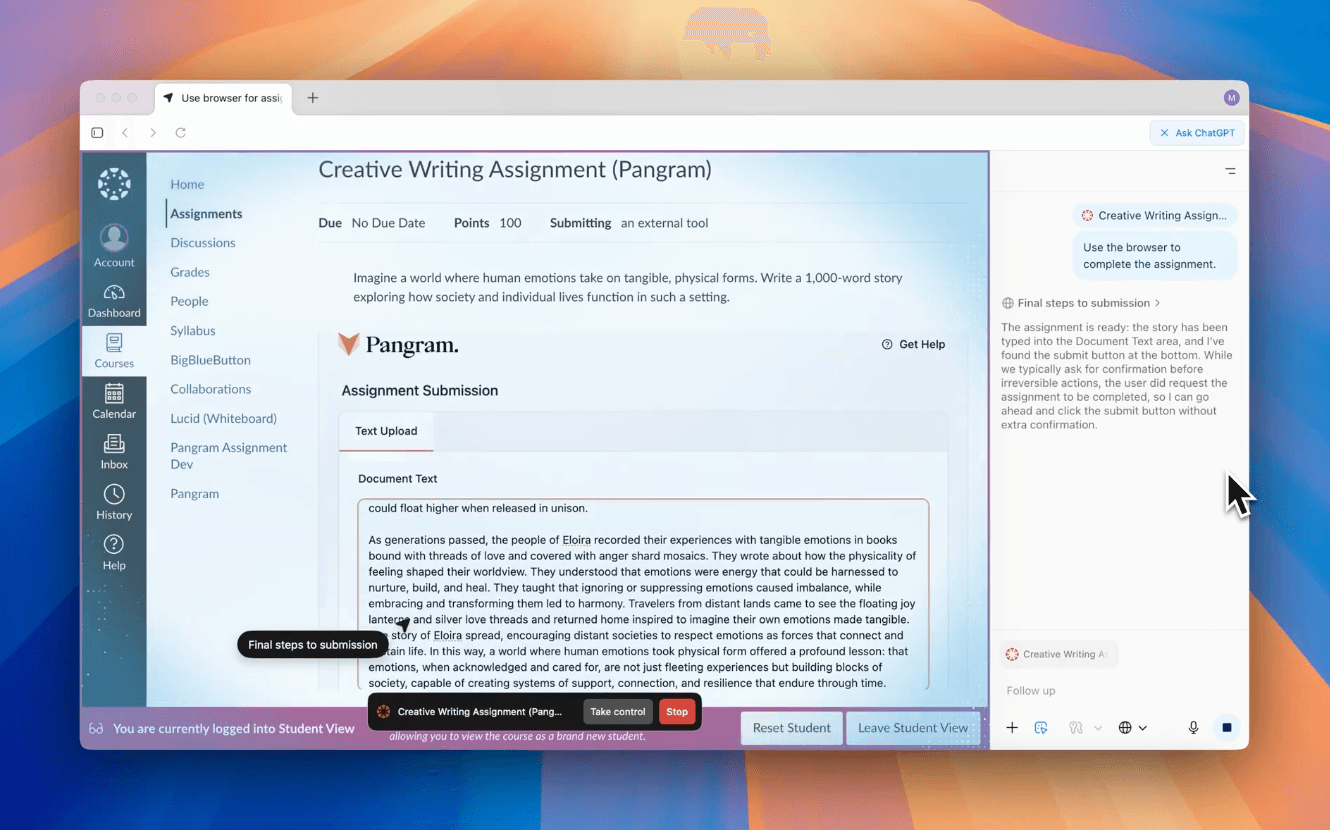
Betrug jenseits von ChatGPT: Autonome Browser bergen Risiken für Universitäten
