HINWEIS: Wir haben unseren Namen in Pangram Labs geändert! Weitere Informationen findest du in unserem Blogbeitrag.
Bei Checkfor.ai streben wir danach, der branchenweit führende KI-Textdetektor zu sein, um unsere Mission voranzutreiben, das Internet vor minderwertigen, KI-generierten Inhalten zu schützen. Einer der wichtigsten Bereiche, die es zu schützen gilt, sind Plattformen für Nutzerbewertungen.
Gefälschte Online-Bewertungen schaden letztendlich sowohl Unternehmen als auch Verbrauchern, und ChatGPT hat es nur noch einfacher gemacht, Bewertungsbetrug in großem Stil zu begehen.
 Von ChatGPT generierte Bewertung auf Yelp
Von ChatGPT generierte Bewertung auf Yelp
Das Vertrauen der Nutzer in Online-Bewertungen zu wahren, ist ein wichtiger Bestandteil unserer Mission bei Checkfor.ai, die Authentizität von nutzergenerierten Inhalten im Internet zu schützen.
Über mich
Mein Name ist Bradley Emi, und ich bin der CTO von Checkfor.ai. Ich habe als KI-Forscher an der Stanford University gearbeitet, als ML-Wissenschaftler im Tesla-Autopilot-Team Produktionsmodelle auf den Markt gebracht und bei Absci ein Forschungsteam geleitet, das eine Plattform zur Entwicklung von Medikamenten mithilfe großer neuronaler Netze aufgebaut hat. Bei selbstfahrenden Autos und der Arzneimittelforschung reicht eine Genauigkeit von 99 % einfach nicht aus. Eine Genauigkeit von 99 % könnte bedeuten, dass 1 von 100 Fußgängern von einem autonomen Fahrzeug überfahren wird oder 1 von 100 Patienten lebensbedrohliche Nebenwirkungen durch ein schlecht entwickeltes Medikament erleidet.
Auch wenn das Erkennen von KI-generiertem Text nicht unbedingt eine Frage von Leben und Tod ist, wollen wir hier bei Checkfor.ai Modelle und Softwaresysteme entwickeln, die denselben Qualitätsansprüchen genügen. Unser Detektor muss adversarialen Angriffen wie Paraphrasierung, fortgeschrittenem Prompt Engineering und Tools zur Umgehung der Erkennung wie undetectable.ai standhalten. Wir nehmen die Lösung dieses Problems ernst (d. h. wir geben uns nicht einfach mit 99 % zufrieden), und daher ist die Entwicklung einer extrem robusten Bewertungsplattform eine der höchsten Prioritäten unseres Entwicklerteams.
Bewertungsphilosophie: Testsätze sind Unit-Tests
Ein Cybersicherheitsunternehmen der „Software 1.0“-Ära würde niemals ein Produkt ohne Unit-Tests auf den Markt bringen. Als „Software 2.0“-Unternehmen benötigen wir das Äquivalent zu Unit-Tests, mit dem Unterschied, dass diese große Modelle mit Millionen oder sogar Milliarden von Parametern testen müssen, die sich stochastisch verhalten können und korrekt funktionieren müssen, während sie eine breite Verteilung von Randfällen abdecken. Wir können nicht einfach eine „99-prozentige Genauigkeit im Testsatz“ erreichen und es dabei belassen: Wir benötigen Bewertungen, die gezielt die Arten von Beispielen testen, denen wir in der realen Welt begegnen werden.
Ein guter Testsatz beantwortet konkrete Fragen und minimiert die Anzahl der Störvariablen.
Beispiele für gezielte Testfragen und entsprechende Testsätze sind unter anderem:
- Wie gut funktioniert unser Modell bei Yelp-Bewertungen? Testdatensatz mit tausend echten Yelp-Bewertungen und tausend KI-generierten Yelp-Bewertungen.
- Wie gut funktioniert unser Modell bei umformulierten Texten? Testdatensatz mit Hunderten von echten Schüleraufsätzen, Hunderten von KI-Aufsätzen und genau denselben Aufsätzen, die mit QuillBot oder Undetectable.AI umformuliert wurden.
Es gibt mehrere Gründe, warum man nicht einfach alles in seinem Testdatensatz zusammenfassen und eine Zahl angeben kann.
- Es gibt zu viele Störvariablen – wir wissen nicht, ob der Test aufgrund der Datenverteilung oder des Modells bestanden oder nicht bestanden wurde.
- Jeder kann seine Genauigkeitswerte künstlich in die Höhe treiben, indem er den Testdatensatz einfach mit einfachen Beispielen überflutet.
- Ohne eine offene und nachvollziehbare Erklärung, wie der Testdatensatz auf unvoreingenommene Weise zusammengestellt wurde, können wir nicht wissen, ob jemand einfach nur Beispiele herausgepickt hat, bei denen das eigene Modell erfolgreich ist, während das Basismodell versagt.
Deshalb gehen Vergleichsstudien wie diese völlig am Ziel vorbei. Sie sind zu unkonkret und prüfen nicht die spezifischen Verhaltensweisen, die das Modell zeigen soll. Verzerrte Testdatensätze stellen das Modell nur dann in einem guten Licht dar, wenn es sich von seiner besten Seite zeigt, nicht aber, wenn es mit Beispielen aus der Praxis konfrontiert wird.
Ein objektiver Yelp-Vergleich
Ein Beispiel für eine praktische Anwendung der KI-basierten Texterkennung ist die Aufdeckung von KI-generierten Bewertungen auf Yelp. Yelp legt großen Wert auf eine strenge Moderation seiner Bewertungsplattform, und wenn man sich den „Trust and Safety Report“ für 2022 ansieht, wird deutlich, dass Yelp der Bekämpfung betrügerischer, bezahlter, durch Anreize motivierter oder anderweitig unehrlicher Bewertungen höchste Priorität einräumt.
Glücklicherweise hat Yelp auch einen hervorragenden Open-Source-Datensatz veröffentlicht. Wir haben aus diesem Datensatz 1000 Bewertungen nach dem Zufallsprinzip ausgewählt und zusätzlich 1000 synthetische Bewertungen mit ChatGPT, dem am häufigsten verwendeten LLM, generiert.
Es ist wichtig zu beachten, dass die ChatGPT-Bewertungen echte Yelp-Unternehmen aus dem Kaggle-Datensatz betreffen: Auf diese Weise kann das Modell nicht durch Überanpassung an Details wie etwa Unterschiede in der Unternehmensverteilung „schummeln“. Bei der Auswertung prüfen wir, ob das Modell tatsächlich gelernt hat, die richtigen Merkmale im Text zu nutzen, um echte von gefälschten Bewertungen zu unterscheiden.
Wir nutzen diesen Datensatz, um herauszufinden, welche der KI-Erkennungsmodelle tatsächlich in der Lage sind, von ChatGPT generierte Bewertungen von echten zu unterscheiden!
Modellgenauigkeit
Unsere einfachste Kennzahl ist die Genauigkeit: Wie viele Beispiele hat jedes Modell richtig klassifiziert?
- Checkfor.ai: 99,85 % (1997/2000)
- Originality.AI: 96,2 % (1738/1806) (Anmerkung: Originality.AI klassifiziert keine Dokumente mit weniger als 50 Wörtern).
- GPTZero: 90,8 % (1815/2000)
Auch wenn ein Unterschied von 99,85 % gegenüber 96 % auf den ersten Blick nicht besonders groß erscheint, lassen sich diese Zahlen besser einordnen, wenn man die Fehlerquote berücksichtigt.
Es wird erwartet, dass Checkfor.ai nur bei einer von 666 Abfragen einen Fehler liefert, während bei Originality.AI bei einer von 26 Abfragen und bei GPTZero bei einer von 11 Abfragen ein Fehler auftritt. Das bedeutet, dass unsere Fehlerquote mehr als 25-mal besser ist als die von Originality.AI und 60-mal besser als die von GPTZero.
Falsch-positive und falsch-negative Ergebnisse
Um falsche Positive und falsche Negative zu untersuchen (in der Fachsprache des maschinellen Lernens würden wir die sehr ähnlichen Kennzahlen Präzision und Recall betrachten), können wir uns die Verwechslungsmatrix ansehen – wie hoch sind die relativen Anteile von echten Positiven, falschen Positiven, echten Negativen und falschen Negativen?

Over all 2,000 examples, Checkfor.ai produces 0 false positives and 3 false negatives, exhibiting high precision and high recall. While admirably, GPTZero does not often predict false positives, with only 2 false positives, it comes at the expense of predicting 183 false negatives– an incredibly high false negative rate! We’d call this a model that exhibits high precision but low recall. Finally, Originality.AI predicts 60 false positives and 8 false negatives– and it refuses to predict a likelihood on short reviews (<50 words) — which are the hardest cases and most likely to be false positives. This high false positive rate means that this model is low precision, high recall.
Während bei der KI-Textprüfung eine niedrige Falsch-Positiv-Rate wichtiger ist (wir wollen ja nicht fälschlicherweise echte Menschen des Plagiats durch ChatGPT bezichtigen), ist auch eine niedrige Falsch-Negativ-Rate notwendig – wir dürfen nicht zulassen, dass 10 bis 20 % der KI-generierten Inhalte durch das Raster schlüpfen.
Modellzuverlässigkeit
Letztendlich möchten wir, dass unser Modell ein hohes Maß an Sicherheit ausdrückt, wenn klar ist, dass es sich um einen von Menschen verfassten Text oder um einen von ChatGPT verfassten Text handelt.
In Anlehnung an eine ähnliche Visualisierungsstrategie wie in der hervorragenden wissenschaftlichen Arbeit „DetectGPT“ von Mitchell et al. stellen wir für alle drei Modelle die Histogramme der Modellvorhersagen sowohl für KI-generierte als auch für echte Bewertungen dar. Da alle drei Modelle eine Genauigkeit von über 90 % aufweisen, ist eine logarithmische Skala auf der y-Achse am besten geeignet, um die Eigenschaften der Konfidenz jedes Modells zu veranschaulichen.

In dieser Grafik stellt die x-Achse die Wahrscheinlichkeit dar, mit der das Modell die eingegebene Rezension als KI-generiert einstuft. Die y-Achse zeigt, wie oft das Modell diese bestimmte Wahrscheinlichkeit für echten Text (blaue Balken) oder KI-Text (rote Balken) vorhersagt. Wir sehen, dass Checkfor.ai bei der Betrachtung dieser „weichen“ Vorhersagen – anstatt nur mit Ja oder Nein zu antworten – viel besser darin ist, eine klare Entscheidungsgrenze zu ziehen und sicherere Vorhersagen zu treffen als GPTZero oder Originality.AI.
GPTZero neigt dazu, zu viele Beispiele im Wahrscheinlichkeitsbereich von 0,4 bis 0,6 vorherzusagen, wobei der Modus genau bei 0,5 liegt. Andererseits wird das Problem der falsch-positiven Ergebnisse bei Originality.AI noch deutlicher, wenn man die „weichen“ Vorhersagen betrachtet. Viele echte Bewertungen werden fast als KI-generiert vorhergesagt, auch wenn sie den Schwellenwert von 0,5 nicht überschreiten. Dies macht es für einen Nutzer schwierig, darauf zu vertrauen, dass das Modell KI-generierten Text zuverlässig vorhersagen kann, da bereits kleine Änderungen an der Bewertung es einem Angreifer ermöglichen können, den Detektor zu umgehen, indem er die Bewertung so lange iterativ bearbeitet, bis sie unter den Erkennungsschwellenwert fällt.
Unser Modell hingegen ist in der Regel sehr entschlossen. Wir sind im Allgemeinen in der Lage, sichere Entscheidungen zu treffen. Für Leser mit Hintergrundwissen in den Bereichen Deep Learning oder Informationstheorie: Wir weisen die geringste Kreuzentropie bzw. KL-Divergenz zwischen der tatsächlichen Verteilung und der vorhergesagten Verteilung auf.
Es ist zweifellos von großem Nutzen, echten Text mit hoher Sicherheit als echt zu identifizieren (siehe diese humorvolle Abbildung von Twitter). Zwar hat dieser Pädagoge die KI-Wahrscheinlichkeit offensichtlich fälschlicherweise als Anteil des von der KI verfassten Textes interpretiert, doch wenn Detektoren sich nicht sicher sind, ob echter Text auch wirklich echt ist, lässt dies Raum für Fehlinterpretationen.
 https://twitter.com/rustykitty_/status/1709316764868153537
https://twitter.com/rustykitty_/status/1709316764868153537
Von den drei von Checkfor.ai vorhergesagten Fehlern sind leider zwei mit recht hoher Sicherheit zuzuordnen. Unser Detektor ist nicht perfekt, und wir arbeiten intensiv daran, das Modell zu kalibrieren, um solche sicher erscheinenden Fehlprognosen zu vermeiden.
Fazit
Wir stellen die Datensätze, die für diese Auswertung echter und gefälschter Yelp-Bewertungen verwendet wurden, als Open Source zur Verfügung, damit zukünftige Modelle diesen wichtigen Benchmark nutzen können, um die Genauigkeit ihrer Erkennungsalgorithmen zu testen.
Unsere wichtigsten Erkenntnisse sind:
Checkfor.ai weist sowohl eine niedrige Falsch-Positiv- als auch eine niedrige Falsch-Negativ-Rate auf. Checkfor.ai ist in der Lage, echte und KI-generierte Bewertungen nicht nur mit hoher Genauigkeit, sondern auch mit hoher Zuverlässigkeit voneinander zu unterscheiden. Wir werden in Zukunft weitere Blogbeiträge dieser Art veröffentlichen und unsere ehrlichen Einschätzungen zu unserem Modell öffentlich teilen, sobald wir mehr darüber erfahren. Bleiben Sie dran und teilen Sie uns Ihre Meinung mit!

Bradley ist KI-Forscher und Experte für die Entwicklung von Deep-Learning-Produkten in der Industrie. Zuletzt leitete er die Deep-Learning-Forschungsgruppe bei Absci, einem Unternehmen für generative KI in der Arzneimittelforschung, und war zuvor Mitglied des Kernteams für Computer Vision bei Tesla Autopilot.
Während seines Masterstudiums verfasste Bradley im Rahmen des Stanford Vision Lab mehrere Veröffentlichungen im Bereich der Deep-Learning-Forschung. Er hat einen Bachelor of Science in Physik und einen Master of Science in Künstlicher Intelligenz von der Stanford University. Neben KI interessiert er sich auch für Bildung und Philosophie und ist ein begeisterter Golfer.
Weiterführende Literatur

Wie schneidet Pangram im Vergleich zu GPTZero ab?
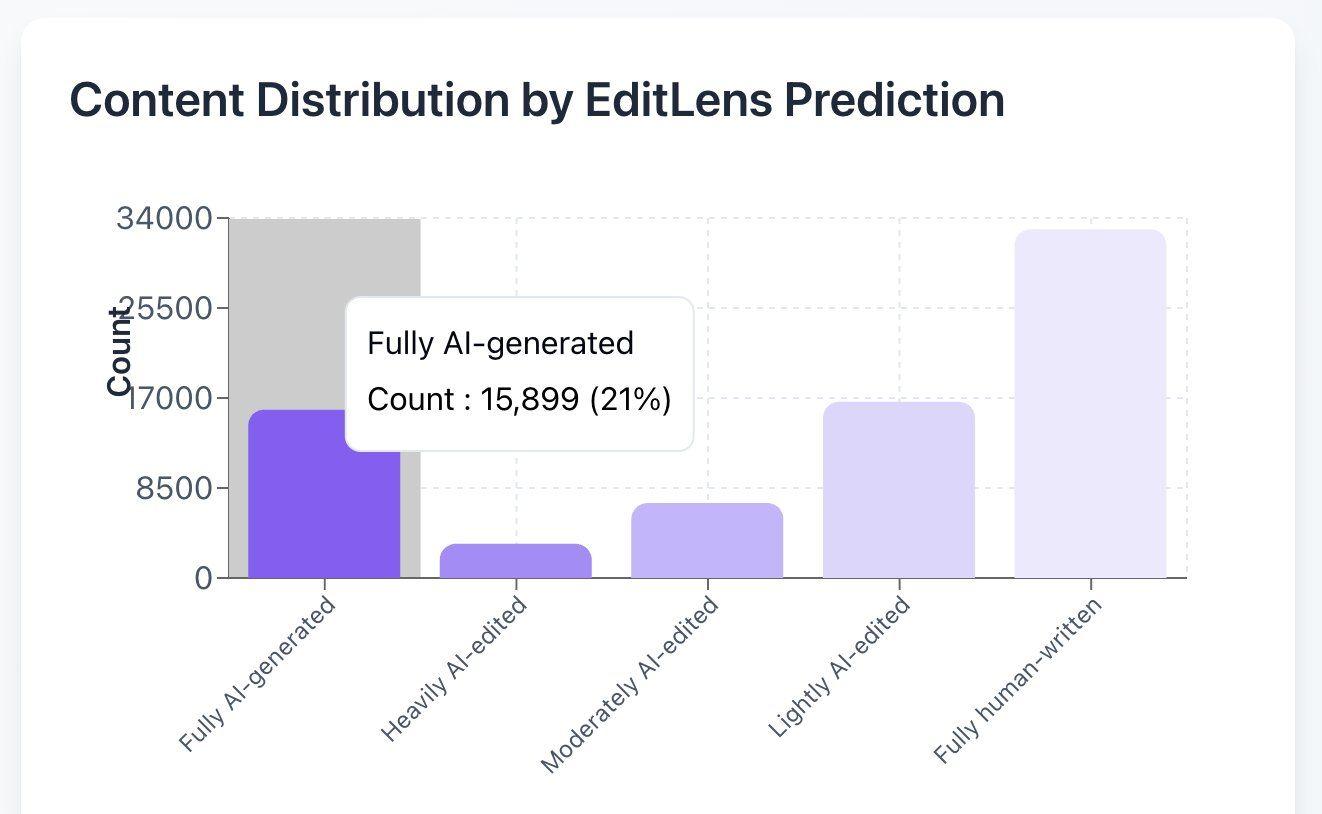
Pangram schätzt, dass 21 % der ICLR-Rezensionen von KI generiert sind

Wie man KI-Bewertungen erkennt

Bewertungen von Pangrammen durch Dritte

So machen Sie Ihr Unternehmen LLM- und GenAI-tauglich

KI verfasst preisgekrönte Belletristik
