Pangram es el único detector de IA que supera a los expertos humanos a la hora de identificar contenidos generados por IA
Nos complace dar a conocer el nuevo estudio de Jenna Russell, Marzena Karpinksa y Mohit Iyyer, investigadores de la Universidad de Maryland y Microsoft, que demuestra que Pangram es el detector de IA con mejor rendimiento en una comparativa, y el único sistema capaz de superar a expertos humanos cualificados en la detección de contenido generado por IA. Lee el artículo completo aquí.

Además de estudiar la eficacia de los detectores automáticos basados en IA, los investigadores también analizan cómo los expertos humanos con experiencia detectan las señales que les ayudan a identificar los indicios reveladores del contenido generado por IA. Creemos que esta investigación supone un gran avance en materia de explicabilidad e interpretabilidad en la detección de IA, y estamos deseando seguir explorando esta línea de investigación.
En esta entrada del blog, explicaremos los aspectos más destacados de la investigación y lo que esto supone para la detección de modelos de lenguaje grande (LLM) en el futuro.
Formar a personas para que se conviertan en detectores de IA
Ya hemos hablado en otras ocasiones sobre cómo detectar los textos generados por IA y la prueba de referencia humana, así como sobre cómo utilizamos estos datos para obtener una valiosa intuición sobre los textos generados por IA que nos ayuda a desarrollar mejores modelos.
Normalmente, cuando empezamos a intentar entrenarnos para detectar reseñas, ensayos, entradas de blog o noticias generadas por IA, al principio no se nos da muy bien. Se tarda un tiempo en empezar a captar las señales reveladoras de que un texto ha sido generado por ChatGPT u otro modelo de lenguaje. Por ejemplo, cuando empezamos a estudiar reseñas, aprendimos con el tiempo, al analizar una gran cantidad de datos, que a ChatGPT le encanta comenzar una reseña con la frase «Recientemente tuve el placer de», o cuando empezamos a leer relatos de ciencia ficción generados por IA, estos suelen comenzar con la frase «En el año de». Sin embargo, con el tiempo, empezamos a interiorizar estos patrones y podemos empezar a reconocerlos.
Los investigadores también se preguntaron si se puede formar a los expertos para que detecten los artículos generados por IA de la misma manera. Formaron a cinco revisores de Upwork para que detectaran contenidos generados por IA y compararon su capacidad para identificar la IA a simple vista con la de personas sin conocimientos especializados.
Aunque cabría esperar que existiera una diferencia en la capacidad de estos dos grupos para identificar el texto escrito por IA, lo que los investigadores descubrieron fue una diferencia considerable. Los no expertos obtienen resultados similares a los del azar a la hora de detectar el texto generado por IA, mientras que los expertos muestran una gran precisión (con una tasa de verdaderos positivos superior al 90 %, de media).

Una de las secciones que nos pareció más interesante fue la titulada «¿Qué ven los anotadores expertos que los no expertos no ven?». Los investigadores pidieron a los participantes que explicaran por qué creían que un texto había sido generado por IA o no, y luego analizaron los comentarios de los participantes.
A continuación se presenta un análisis extraído directamente del artículo:
«A menudo, los legos se fijan erróneamente en ciertas propiedades lingüísticas, a diferencia de los expertos. Un ejemplo es la elección del vocabulario: los legos interpretan la inclusión de cualquier palabra «sofisticada» o de baja frecuencia como un indicio de que el texto ha sido generado por IA; por el contrario, los expertos están mucho más familiarizados con las palabras y frases concretas que la IA utiliza en exceso (por ejemplo, «testamento» o «crucial»). Los no expertos también creen que los autores humanos son más propensos a formar oraciones gramaticalmente correctas y, por lo tanto, atribuyen las oraciones encadenadas a la IA, pero ocurre lo contrario: los humanos son más propensos que la IA a utilizar oraciones gramaticalmente incorrectas o encadenadas. Por último, los no expertos atribuyen a la IA cualquier texto escrito en un tono neutro, lo que da lugar a muchos falsos positivos, ya que la escritura formal humana también suele ser de tono neutro» (Russell, Karpinska e Iyyer, 2025).
En el apéndice, los autores ofrecen una lista del «vocabulario de IA» que suele emplear ChatGPT, una función que hemos incorporado recientemente al panel de control de Pangram y que destaca las expresiones de IA más habituales.

Según nuestra experiencia, hemos observado que, aunque mucha gente piensa que la IA utiliza un vocabulario sofisticado y «elegante», en la práctica vemos que, por el contrario, tiende a emplear un vocabulario más manido y metafórico que a menudo no tiene ningún sentido. En términos coloquiales, diríamos que los modelos de lenguaje grande (LLM) se parecen más a personas que intentan parecer inteligentes, pero que en realidad solo utilizan frases que creen que les harán parecer inteligentes.
Resistencia de los detectores de IA frente a los modelos más avanzados
Una de las preguntas que nos hacen a menudo en Pangram es: ¿cómo os mantenéis al día con los modelos más avanzados? Cuando los modelos de lenguaje mejoran, ¿significa eso que Pangram dejará de funcionar? ¿Es un juego del gato y el ratón en el que los laboratorios punteros como OpenAI nos ganarán?
Los investigadores también se lo preguntaron y analizaron el rendimiento de varios métodos de detección de IA frente al modelo «o1-pro» de OpenAI, el más avanzado publicado hasta la fecha.
Los investigadores descubrieron que Pangram tiene una precisión del 100 % a la hora de detectar resultados de o1-pro, ¡y seguimos teniendo una precisión del 96,7 % en la detección de resultados «humanizados» de o1-pro (de los que hablaremos en un momento)! En comparación, ningún otro detector automático supera siquiera el 76,7 % en los resultados básicos de o1-pro.
¿Cómo es posible que Pangram pueda generalizar de esta manera? Al fin y al cabo, en el momento del estudio ni siquiera contábamos con datos de o1-pro en nuestro conjunto de entrenamiento.
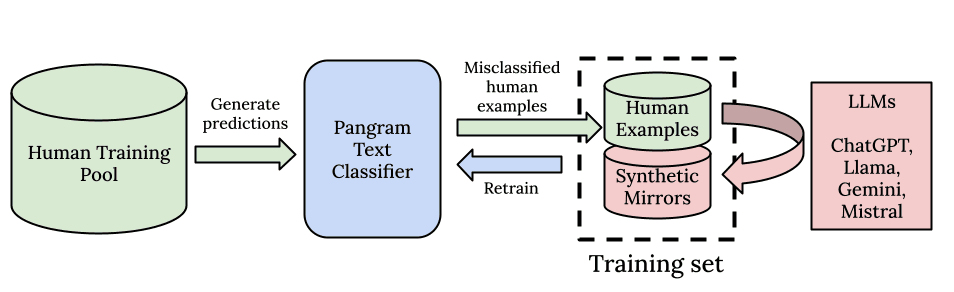
Al igual que todos los modelos de aprendizaje profundo, creemos en el poder de la escala y la potencia de cálculo. En primer lugar, partimos de un potente modelo base preentrenado con un enorme corpus de entrenamiento, al igual que los propios modelos de lenguaje a gran escala (LLM). En segundo lugar, hemos creado un flujo de datos diseñado para la escala. Pangram es capaz de reconocer patrones sutiles a partir de su corpus de entrenamiento, compuesto por 100 millones de documentos escritos por humanos.
No nos limitamos a crear un conjunto de datos para ensayos, noticias o reseñas: intentamos recopilar la red más amplia posible de todos los datos escritos por humanos que existen, para que el modelo pueda aprender a partir de una distribución de datos de la más alta calidad y más diversa, y conocer todo tipo de escritos humanos. Consideramos que este enfoque general para la detección de IA funciona mucho mejor que el enfoque especializado de crear un modelo por cada dominio de texto.
Como complemento a nuestro conjunto de datos humanos, extremadamente amplio y de alta calidad, contamos con nuestro proceso de generación de datos sintéticos y un algoritmo de búsqueda basado en el aprendizaje activo. Para obtener los datos de IA que necesita nuestro algoritmo, utilizamos una exhaustiva biblioteca de indicaciones y todos los principales modelos de IA, tanto de código abierto como cerrado, con el fin de generar datos sintéticos. Utilizamos indicaciones sintéticas especulares, sobre las que hemos escrito en nuestro informe técnico, y la minería de negativos duros, que busca los ejemplos de nuestro conjunto de datos con mayor error y crea ejemplos de IA muy similares a los humanos, reentrenando el modelo hasta que no se detecten más errores. Esto nos permite reducir de forma muy eficiente a cero las tasas de falsos positivos y falsos negativos de nuestro modelo.
En pocas palabras, nuestra generalización se debe a la magnitud de nuestros datos de preentrenamiento, a la diversidad de indicaciones y modelos de lenguaje grande (LLM) utilizados para la generación de datos sintéticos, y a la eficiencia de los datos que se deriva de nuestro enfoque de aprendizaje activo y de extracción de datos negativos difíciles.
Además, no solo nos esforzamos por lograr un excelente rendimiento fuera de la distribución, sino que también queremos asegurarnos de que el mayor número posible de modelos de lenguaje grande (LLM) comunes se ajusten lo más posible a la distribución. Por ello, hemos creado un sólido proceso automatizado para extraer datos de los modelos más recientes, de modo que podamos empezar a entrenar con nuevos LLM tan pronto como se publiquen y mantenernos al día. Hemos constatado que no se trata de una disyuntiva entre equilibrar el rendimiento en diferentes modelos: observamos que cada vez que introducimos un nuevo LLM en el conjunto de entrenamiento, la generalización del modelo mejora.
Con nuestro sistema actual, no observamos que, a medida que los modelos mejoran, resulten más difíciles de detectar. En muchos casos, los modelos de última generación son, de hecho, más fáciles de detectar. Por ejemplo, constatamos que nuestra detección de Claude 3 fue más precisa en el momento de su lanzamiento que la de Claude 2.
Ataques contra Paraphraser y Humanizer
En nuestra reciente serie de entradas de blog, describimos en qué consiste un «humanizador de IA» y también lanzamos un modelo con un rendimiento notablemente mejorado en la humanización de textos generados por IA. Nos complace comprobar que una entidad externa ya ha validado nuestras afirmaciones con un conjunto de datos de artículos humanizados de o1-pro.
En el texto humanizado de o1-pro, alcanzamos una precisión del 96,7 %, mientras que el siguiente mejor modelo automatizado solo es capaz de detectar el 46,7 % del texto humanizado.
Además, nuestra precisión es del 100 % en el texto generado por GPT-4o que se ha parafraseado frase por frase.
Conclusión
Nos complace enormemente comprobar el excelente rendimiento de Pangram en un estudio independiente sobre las capacidades de detección de la IA. Siempre estamos dispuestos a apoyar la investigación académica y ofrecemos acceso abierto a cualquier investigador que desee estudiar nuestro detector.
Además de evaluar el rendimiento de los detectores automáticos, nos entusiasma ver que la investigación también empieza a abordar la explicabilidad y la interpretabilidad de la detección basada en la IA: no solo si un texto ha sido escrito por la IA, sino también por qué. Esperamos poder seguir escribiendo sobre cómo estos resultados pueden ayudar a los profesores y educadores a identificar a simple vista los textos generados por la IA, y cómo tenemos previsto incorporar esta investigación a herramientas de detección automática más explicables.
Para obtener más información, visite nuestro sitio web pangram.com o póngase en contacto con nosotros en info@pangram.com.

Bradley es investigador en inteligencia artificial y experto en el desarrollo de productos de aprendizaje profundo para el sector industrial. Recientemente ha dirigido el grupo de investigación en aprendizaje profundo de Absci, una empresa dedicada al descubrimiento de fármacos mediante IA generativa, y anteriormente formó parte del equipo principal de visión artificial de Tesla Autopilot.
Durante sus estudios de posgrado, Bradley fue autor de varias publicaciones sobre investigación en aprendizaje profundo en el Stanford Vision Lab. Es licenciado en Física y tiene un máster en Inteligencia Artificial por la Universidad de Stanford. Además de la IA, le apasionan la educación y la filosofía, y es un ávido golfista.
Lecturas relacionadas

Nuevos niveles de productos de Pangram

¿Qué eficacia tiene Pangram a la hora de detectar modelos de razonamiento?

Presentamos la nueva página de resultados

¿Funcionan los detectores de IA contra GPT-5?
Informe técnico sobre la detección de textos generados por IA con alta precisión

Cómo detectar la IA en Python
