Coup de projecteur sur une collaboratrice : Rencontre avec Katherine, chercheuse en intelligence artificielle
Table des matières
Coup de projecteur sur une collaboratrice : Katherine Thai
Bienvenue dans notre deuxième édition de « Pleins feux sur nos collaborateurs » ! Nous avons rencontré Katherine Thai, notre chercheuse en IA fondatrice, pour discuter de son parcours atypique vers le traitement du langage naturel (NLP), de ses recherches en analyse littéraire et de ce qu’elle développe actuellement chez Pangram Labs. (Remarque : cette interview a été transcrite et légèrement révisée par une IA pour en faciliter la lecture.)
Des mathématiques et de l'anglais à la recherche en traitement du langage naturel
Comment vous êtes-vous intéressé à la PNL et avez-vous décidé de faire un doctorat ?
Au départ, je ne m'intéressais pas vraiment à la PNL. À l'université, j'ai étudié les mathématiques, l'informatique et l'anglais, et j'ai participé à de nombreux programmes de recherche de premier cycle, car j'adorais l'idée de faire de la recherche et des expériences, mais je ne savais pas exactement ce que je voulais étudier.
À l'approche de ma dernière année d'études, un camarade de classe m'a suggéré que ma licence d'anglais me permettrait de me lancer dans le traitement du langage naturel (NLP), car il s'agit de l'application de l'informatique au traitement des textes. Je n'en avais jamais vraiment entendu parler : mon université ne comptait ni chercheurs ni cours dans ce domaine.
J'ai fini par trouver mon directeur de thèse actuel, Mohit Iyyer, qui menait des recherches sur la compréhension narrative des récits longs et des livres. Cela m'a vraiment intrigué, car j'adore les livres et j'avais rédigé un mémoire de licence intitulé « Mécanismes narratifs de la frustration ». Lorsque j’ai postulé, mon directeur de thèse pensait qu’il s’agissait de mécanismes techniques en informatique, mais ce n’était pas le cas : c’était simplement ma façon de décrire ce qui se passait en littérature ! Il a trouvé mon parcours fascinant et a estimé que mes connaissances en mathématiques m’aideraient à acquérir les bases. J’ai littéralement suivi mon premier cours de TALN dès mon premier semestre de doctorat.
Étudier la littérature avec l'IA
Parlez-nous de votre thèse de doctorat.
Ma thèse s'intitule « Modes de collaboration entre l'humain et l'IA dans le domaine du texte : repères, indicateurs et tâches d'interprétation ». Je cherche à comprendre comment les modèles linguistiques pourraient interpréter un texte et en tirer des conclusions plus approfondies que celles d'un chercheur en sciences humaines, plutôt que de se limiter à des caractéristiques superficielles.
Les premiers travaux en TALN consacrés à la littérature visaient principalement à extraire des entités nommées des livres, à cartographier les interactions entre les personnages et à établir des chronologies sommaires de l'intrigue. Je m'intéresse bien davantage aux thèmes généraux qui traversent l'ensemble des textes, à la manière dont les motivations des personnages influencent leurs décisions, ainsi qu'à la façon dont les textes s'inscrivent dans le contexte plus large de l'époque et du lieu où l'auteur les a écrits.
Je m'intéresse principalement à cette question sous l'angle de l'évaluation, c'est-à-dire pour déterminer si les modèles linguistiques sont capables d'extraire ces concepts de haut niveau à partir de textes littéraires.
Comment s'est passée votre formation en analyse littéraire avec l'IA, alors que ChatGPT faisait son apparition pendant votre doctorat ?
J'ai une anecdote incroyable à ce sujet. Dans le cadre de mes premiers travaux de doctorat, j'avais proposé un exercice intitulé « recherche de preuves littéraires ». Les chercheurs citent toujours des extraits de textes originaux dans leurs analyses ; nous avons donc sélectionné des paragraphes dans lesquels des spécialistes des sciences humaines analysaient *Gatsby le Magnifique*, masqué les citations tirées du roman, puis demandé à des modèles linguistiques de retrouver ces citations.
Dans mes premiers travaux, j'ai utilisé un petit moteur de recherche dense basé sur RoBERTa, car nous ne pouvions pas intégrer des romans entiers dans les modèles linguistiques. J'ai littéralement écrit dans la section « Motivation » que nous avions besoin de cette approche, car nous ne pouvions pas intégrer des romans complets dans le contexte.
Cinq ans plus tard, mes travaux les plus récents ont revisité cette tâche à l'aide de grands modèles linguistiques capables de traiter des romans entiers. En février, j’ai moi-même tenté l’expérience pour la première fois : cela m’a pris huit heures avec des exemplaires papier des livres. Aucun des modèles n’a obtenu d’aussi bons résultats que moi sur 40 exemples. Mais au moment où l’article a été accepté, trois mois plus tard, Gemini Pro 2.5 était sorti et m’avait surpassé. C’était un échantillon si restreint, mais c’était fou de voir à quelle vitesse les choses évoluaient.
Au début de mon doctorat, je ne rédigeais aucune instruction. C'était du jamais vu. Aujourd'hui, ma mère utilise des modèles de langage (LLM) dans le cadre de son travail : avant, elle ne savait jamais sur quoi je travaillais, et maintenant, elle a accès à des modèles de langage d'entreprise.
 Katherine soutient sa thèse de doctorat
Katherine soutient sa thèse de doctorat
Selon vous, en quoi la lecture des grands modèles de langage (LLM) diffère-t-elle de celle des humains ?
La différence la plus flagrante réside dans la rapidité : Gemini répond en 30 secondes, alors qu'il me fallait en moyenne 12 minutes par exemple. Lorsque j'ai analysé mes erreurs, je me rendais souvent compte que je ne me souvenais tout simplement pas de phrases précises tirées de romans de 200 à 400 pages, alors que le modèle avait une mémoire parfaite.
Je pense que les grands modèles de langage (LLM) traitent le texte token par token, d'une manière qui s'apparente à la lecture attentive pratiquée en analyse littéraire, où l'on décortique le texte mot à mot. Mais lorsque les humains lisent 400 pages, chaque mot n'est pas perçu par notre cerveau comme une unité distincte, contrairement à ce qui peut être le cas pour les modèles.
Le défi de l'évaluation
Pourquoi est-il si difficile de concevoir de bonnes évaluations, et pourquoi y a-t-il un tel décalage entre les évaluations actuelles et ce que les gens vivent réellement avec ces modèles ?
C'est le dilemme entre, d'une part, le désir d'étendre rapidement les évaluations grâce à l'automatisation et, d'autre part, la nécessité d'une évaluation humaine approfondie par des experts. Une grande partie de mon travail a consisté à investir dans le recrutement d'experts confirmés. Pour la traduction automatique d'œuvres littéraires, nous avons embauché des traducteurs littéraires titulaires d'un doctorat en littérature comparée. Leurs analyses étaient nettement différentes de celles que l'on obtiendrait auprès de contributeurs de Mechanical Turk, même pour de simples tests A/B.
L'autre aspect concerne le coût de la mise en place des évaluations. J'ai participé cette année à l'élaboration d'un test de performance pour les agents, dans le cadre duquel nous avons rédigé manuellement les questions et évalué tous les agents à la main. J'ai probablement passé tout le mois de mars à observer l'opérateur d'OpenAI cliquer ici et là et chercher des éléments. Il a fallu énormément de temps pour traiter ne serait-ce que 100 à 150 exemples, mais le fait d'avoir un œil humain pour observer ce que faisaient les agents nous a beaucoup appris.
Il existe une tension permanente entre la volonté d'étendre les évaluations à plus grande échelle et la nécessité d'un travail d'évaluation humain, plus lent et plus minutieux.
Développement d'un système de détection par IA chez Pangram
Sur quoi travaillez-vous chez Pangram ?
Je travaille actuellement sur un modèle capable de déterminer dans quelle mesure l'IA a été utilisée dans un texte. Nous savons que les utilisateurs ne se contentent pas de générer du texte à l'aide de l'IA : ils lui soumettent souvent des textes qu'ils ont eux-mêmes rédigés et lui demandent de les modifier. Ces modifications vont de simples corrections grammaticales à des restructurations importantes, voire à une reformulation complète.
Nous souhaitons mesurer cet effet, car nous pouvons considérer l'échelle allant d'un texte entièrement rédigé par l'homme à un texte entièrement rédigé par l'IA comme un spectre, le texte révisé par l'IA se situant quelque part entre les deux. Nous entraînons un modèle pour déterminer à quel endroit de ce spectre un texte pourrait se situer.
C'est un aspect particulièrement important pour nos clients du secteur de l'éducation, mais nous avons également reçu des manifestations d'intérêt de la part de nombreux autres acteurs, car les grands modèles de langage (LLM) sont désormais intégrés à des éditeurs de texte tels que Google Docs. Les utilisateurs souhaitent savoir dans quelle mesure l'IA est intervenue dans un texte : quelles modifications peuvent être considérées comme « acceptables » et lesquelles allègent considérablement la charge cognitive de l'utilisateur.
 Katherine et son équipe travaillent tard sur un article de recherche
Katherine et son équipe travaillent tard sur un article de recherche
Pourquoi avez-vous décidé de rejoindre Pangram en tant que chercheur fondateur ?
J'adore l'équipe ici. Bradley et Max ont vraiment frappé fort avec l'équipe fondatrice. Je passe 90 % de mon temps avec les gens de Pangram, mais honnêtement, je ne voudrais pas qu'il en soit autrement — comme en témoigne le fait que j'ai fait du sport avec tout le monde ces dix derniers jours !
C'est vraiment agréable d'avoir un bureau où aller. J'ai fait mon doctorat à distance pendant un certain temps, et c'est sympa d'avoir un espace où tout le monde travaille vers un objectif commun. J'ai commencé mon doctorat juste après ma licence, pendant la première année de la pandémie de COVID, donc tout se faisait à distance et je n'avais nulle part où aller. Je n'ai jamais eu l'occasion de travailler dans un bureau ni d'avoir un « travail normal ».
Bradley est l'une des personnes les plus brillantes avec lesquelles j'ai jamais travaillé — et ce n'est pas une exagération. J'ai l'impression d'avoir énormément appris et d'acquérir une expérience pratique dans des domaines que je n'ai pas pu aborder pendant mon doctorat. Lorsque les LLM sont apparus, tout le monde voulait faire de la recherche sur eux et nous avons délaissé la modélisation. Ça ne servait à rien d'essayer de former son propre modèle pour rivaliser avec les grands laboratoires, donc je n'avais pas beaucoup travaillé sur la modélisation, à part un peu de réglage fin.
C'était vraiment génial d'acquérir des compétences pratiques. Je ne suis pas un bon ingénieur logiciel, car je suis chercheur, alors ça m'a beaucoup plu. Elyas m'a aidé à résoudre des tickets GitHub pendant une demi-heure aujourd'hui ! Et puis, pouvoir travailler avec des gens brillants, faire de la recherche et vivre à Brooklyn… C'est un endroit formidable et j'adore la côte Est.
Un sceptique de l'IA dans la recherche sur l'IA
Vous êtes plutôt sceptique qu'optimiste en matière d'IA et vous ne l'intégrez pas beaucoup dans votre quotidien. Qu'est-ce qui motive ce scepticisme ?
Deux choses. À petite échelle, je suis le seul parmi mes amis proches de l'université à m'être orienté vers la recherche en informatique. Les autres sont actuaires et ne connaissaient pas la modélisation du langage quand elle a fait son apparition. Ils ont commencé à entendre parler de ChatGPT quand Instagram a intégré l'IA dans ses barres de recherche et ses fonctionnalités de chat. Pendant longtemps, j'étais le seul à connaître ces technologies, mais mes amis semblaient très bien s'en passer. J'ai réalisé à quel point l'IA occupait une place importante dans mon esprit, alors qu'ils en ignoraient tout et s'en sortaient très bien.
Je me suis retrouvé dans cette bulle où tout le monde était soit des pessimistes sur l'IA, soit des fervents défenseurs des grands modèles de langage, mais ce n'est pas de ça que parle 95 % des gens.
D'un point de vue philosophique, au fil de mon parcours d'écriture — en apprenant que je ne veux pas écrire mais que j'adore analyser —, j'ai pris conscience que je n'accorde de valeur qu'aux textes issus de l'esprit humain. Peu m'importe ce que les modèles de langage grand public (LLM) écrivent ou s'ils sont capables d'effectuer des tâches d'analyse littéraire, car je pense que cette capacité n'a de valeur que lorsqu'elle est le fait d'un être humain. C'est une compétence que les humains peuvent posséder, mais je ne pense pas que cela ait la moindre importance si un LLM en est doté.
L'écriture est une activité profondément humaine, et j'apprécie vraiment le fait qu'un être humain en soit l'auteur. Cela fait de moi un piètre détecteur de textes générés par l'IA, car je ne lis tout simplement pas ce genre de textes !
La vie en dehors du travail
Qu'est-ce que tu aimes faire pour te détendre en dehors du travail ?
J'adore promener mes chiens à Brooklyn : j'en ai deux, et l'un d'eux adore les longues balades. J'aime faire du sport, lire des romans, et je suis assez passionnée par le tricot et le crochet.
Tu t'es fixé comme objectif pour cet été de faire du sport avec toute l'équipe de Pangram. Quelle a été ta séance préférée jusqu'à présent ?
Je pense à l'escalade avec Lu, ce qui tombe bien, car on va recommencer dans 45 minutes ! L'escalade est une activité très conviviale, car on fait des pauses entre les tentatives, ce qui permet de discuter et de passer un bon moment ensemble.
J'ai fait du kickboxing, une activité très intense du début à la fin avec des sacs individuels, donc pas vraiment axée sur le travail d'équipe. Et j'ai participé à une autre séance d'entraînement avec nos fondateurs qui a été un véritable chaos pendant toute l'heure : impossible de parler, on essayait juste de tenir le coup ! Le moral était au beau fixe par moments, même si Max a peut-être eu quelques baisses de régime. Ça a été une super expérience pour souder l'équipe, mais l'escalade remporte la palme de l'activité la plus conviviale.
Conseils aux futurs chercheurs
Quels conseils donneriez-vous à quelqu'un qui souhaite se lancer dans la recherche en apprentissage automatique ?
Deux points essentiels : n'essayez pas de mener vos projets tout seul. Certains doctorants débutants tombent dans ce piège, mais vous devez collaborer avec des personnes plus expérimentées que vous. S'il s'agit de votre premier projet, ce n'est vraiment pas grave s'ils font des choses qui vous surprennent et vous impressionnent : vous apprendrez énormément en travaillant avec des gens très brillants.
Deuxièmement, vous devez vous lancer et sortir de votre zone de confort. J'ai appris Python simplement en décidant de n'utiliser que ce langage pendant un été, dans le cadre d'un projet de recherche. Mettez-vous vraiment à la pratique pour tout, y compris les maths : calculez vos dérivées à la main !
En fait, je suis devenu accro à Math Academy il y a six mois, ce qui était complètement fou, mais génial pour me remettre aux bases des maths.
 Katherine chez Pangram
Katherine chez Pangram
Katherine vient de terminer son doctorat en informatique à l'université du Massachusetts à Amherst et va rejoindre Pangram Labs à temps plein en tant que première chercheuse fondatrice. Lorsqu'elle n'est pas en train d'entraîner des modèles de détection par IA ou d'analyser des textes à l'aide de modèles linguistiques, on peut la croiser en train de promener ses chiens dans Brooklyn ou de planifier la prochaine séance d'entraînement de l'équipe.

Bradley est chercheur en intelligence artificielle et spécialiste du développement de produits basés sur l'apprentissage profond dans le secteur industriel. Il a récemment dirigé le groupe de recherche sur l'apprentissage profond chez Absci, une entreprise spécialisée dans la découverte de médicaments par l'IA générative, et faisait auparavant partie de l'équipe principale chargée de la vision par ordinateur chez Tesla Autopilot.
Pendant ses études supérieures, Bradley a rédigé plusieurs articles de recherche sur l'apprentissage profond au sein du Stanford Vision Lab. Il est titulaire d'une licence en physique et d'un master en intelligence artificielle de l'université de Stanford. Outre l'IA, il s'intéresse également à l'éducation et à la philosophie, et est un passionné de golf.
Lectures complémentaires

Déclaration concernant le décret présidentiel de Joe Biden sur la sécurité de l'IA

Faites du shopping jusqu'à plus soif : l'IA s'immisce dans les produits et leur marketing

La théorie de l'information qui explique pourquoi les textes générés par l'IA sont médiocres
Meta va commencer à identifier les contenus générés par l'IA

Pangram Space : un projet de recherche interactif
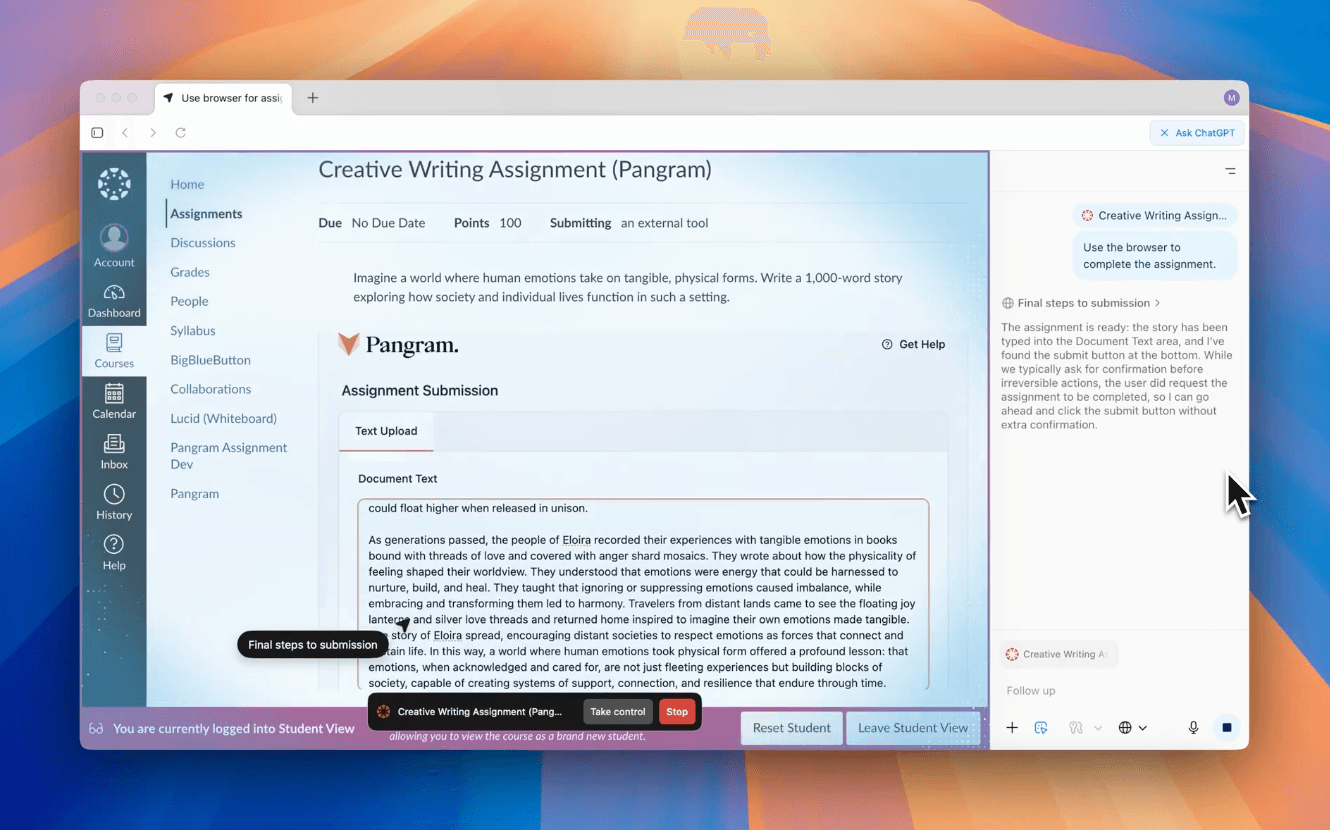
Au-delà de ChatGPT : les navigateurs autonomes présentent des risques pour les universités
