Rapport technique sur la détection de textes générés par l'IA avec une grande précision
Table des matières
- Introduction
- En bref
- Introduction aux textes générés par l'IA
- Pourquoi Pangram Labs accorde une importance particulière à la précision
- Comparaison des outils de détection basés sur l'IA
- Analyser les résultats en détail
- Robustesse
- L'anglais comme deuxième langue
- L'approche de Pangram Labs en matière de détection de l'IA
- Miroirs synthétiques
- Exploitation minière « hard negative »
- Quelle est la prochaine étape pour Pangram Labs ?
 Processus d'entraînement du classificateur de textes générés par IA de Pangram Labs
Processus d'entraînement du classificateur de textes générés par IA de Pangram Labs
Introduction
Chez Pangram Labs, nous développons le meilleur modèle d'IA de détection de texte afin de protéger Internet contre l'inondation de contenus inauthentiques, trompeurs et de mauvaise qualité. Nous sommes convaincus que, dans un monde où les grands modèles linguistiques (LLM) occupent une place centrale, les humains devront disposer des meilleurs outils pour discerner la vérité, et nous souhaitons fournir la technologie adéquate pour répondre à ce besoin.
Pangram Labs a développé un classificateur performant capable de détecter les textes générés par l'IA susceptibles d'être utilisés à grande échelle dans le cadre de spams ou de contenus frauduleux. Dans quelle mesure notre modèle est-il plus performant que les autres solutions existantes ? Dans cet article de blog, nous présentons une analyse approfondie des performances de notre modèle, accompagnée de notre tout premier livre blanc technique accessible au public.
Cet article de blog abordera plusieurs sujets :
- Pourquoi la détection des textes générés par l'IA est-elle un enjeu important ?
- Quel est le meilleur outil de détection de contenu généré par l'IA ?
- Pourquoi une grande précision est-elle importante ?
- Quels types de contenus Pangram Labs est-il capable de détecter ?
- Comment Pangram Labs s'est-il attaqué à ce problème ?
Pour une analyse plus approfondie et technique, notamment sur la méthodologie, consultez notre rapport technique sur le classificateur de textes générés par IA « Pangram ».
En bref
Nous avons réalisé une analyse comparative de la concurrence à partir de près de 2 000 documents afin de déterminer les principaux indicateurs de précision, notamment la précision globale, le taux de faux positifs et le taux de faux négatifs.
Our text classifier outperforms academic methods and shows significantly lower error rates in a comprehensive benchmark against other available AI text detection methods. Our model demonstrates 99.85% accuracy with 0.19% false positive rate across thousands of examples across ten different categories of writing and eight commonly used large language models. Other methods fail on more capable LLMs such as GPT-4 (<=75% accuracy) while Pangram Labs sustains 99-100% accuracy across all language models tested.
 Comparaison de la précision globale
Comparaison de la précision globale
Introduction aux textes générés par l'IA
Les grands modèles linguistiques (LLM), tels que ChatGPT, ont connu un essor fulgurant en 2023, alors que les capacités de l'IA atteignaient un tournant décisif. Les LLM qui alimentent les assistants IA pouvaient répondre à des questions, proposer des idées et rédiger du contenu, tout en donnant l'impression d'être des êtres humains. Cela a eu des retombées positives : l'information est plus accessible que jamais et les assistants nous font gagner du temps en se chargeant des tâches subalternes. Cependant, n'importe qui est capable de produire un texte d'un réalisme convaincant sans pratiquement aucun effort, ce qui comporte son lot d'inconvénients. Les spammeurs peuvent rédiger des e-mails plus difficiles à filtrer. Les vendeurs sur les places de marché en ligne peuvent générer des milliers d'avis d'apparence authentique en quelques minutes. Des acteurs malveillants peuvent se tourner vers les réseaux sociaux et influencer l'opinion publique à l'aide de milliers de bots alimentés par des LLM.
Malheureusement, ces risques sociétaux ne peuvent être atténués au niveau des modèles linguistiques (LLM) : ceux-ci ne sont pas en mesure de déterminer si une requête est légitime ou si elle fait partie des milliers générées par un spammeur. C'est pourquoi nous avons besoin de filtres de contenu au niveau de la couche applicative, afin de préserver le caractère humain des espaces communautaires.
Pourquoi Pangram Labs accorde une importance particulière à la précision
Nous avons entendu beaucoup de scepticisme à propos de ce domaine. On nous dit que le problème est insoluble, qu’il a été démontré que les détecteurs d’IA « ne fonctionnent pas », ou qu’il suffit de contourner le problème en modifiant la formulation. Ou encore que, même si c’est possible aujourd’hui, ce sera plus difficile l’année prochaine, voire impossible d’ici à ce que l’IA générale voie le jour.
Notre point de vue est un peu différent. Nous sommes fermement convaincus qu’il est non seulement possible, mais aussi nécessaire de résoudre ce problème. Peu importe la difficulté, peu importe le nombre d’heures qu’il faudra y consacrer pour créer un outil que les utilisateurs pourront utiliser en toute confiance. Sans notre travail, ce n’est qu’une question de temps avant que l’Internet ne soit envahi par des spammeurs alimentés par l’IA. Les voix humaines seront alors noyées dans le bruit.
Pour nous, garantir la résolution du problème implique de continuer à augmenter la difficulté de nos ensembles d'évaluation. Au début, il était facile d'atteindre une précision de 100 % lors des évaluations, mais il est rapidement apparu que cela ne reflétait pas la précision réelle. En créant des évaluations plus difficiles, nous sommes en mesure de mesurer nos progrès de manière objective. Nous pensons déjà que notre benchmark actuel est légèrement plus difficile que ce que produisent les spammeurs dans le monde réel, et ce benchmark est proche de son maximum. Lorsque nous reviendrons avec de nouveaux chiffres, il pourrait sembler que les autres méthodes se soient encore détériorées, mais en réalité, nous reviendrons avec un ensemble d'évaluation plus difficile, où les IA les plus performantes seront poussées à leurs limites pour créer du texte qui semble authentique, et notre objectif est de toujours être en mesure de le détecter avec une précision de 99 %.
Le problème ne sera jamais entièrement résolu, mais nous devons progresser régulièrement pour ne pas prendre de retard alors que les grands modèles de langage (LLM) ne cessent de gagner en puissance. C'est la mission que nous nous sommes fixée, et nous continuerons à la mener à bien jusqu'au bout.
Comparaison des outils de détection basés sur l'IA
Dans notre rapport technique, nous avons comparé Pangram Labs aux deux principaux outils de détection de l'IA, ainsi qu'à une méthode académique de pointe de 2023 en matière de détection de l'IA.
Nous comparons :
- Pangram Labs
- GPTZero
- Originality.ai
- DetectGPT
Notre base de référence comprend 1 976 documents, dont la moitié a été rédigée par des humains et l'autre moitié générée par huit des modèles de langage génératif (LLM) les plus populaires, notamment ChatGPT et GPT-4.
Comparaison de la précision globale
Voici une brève explication de la signification de ces chiffres :
- Précision: quel pourcentage de l'ensemble des documents l'outil a-t-il classé correctement ?
- Taux de faux positifs: sur l'ensemble des documents rédigés par des humains, combien ont été classés à tort comme provenant de l'IA ?
- Taux de faux négatifs: parmi tous les documents traités par l'IA, combien ont été classés à tort comme ayant été rédigés par un humain ?
Pour illustrer concrètement le taux de faux positifs : un taux de 9 % signifie qu'un document rédigé par un humain sur onze sera signalé comme ayant été généré par une IA. Un taux de 2 % signifie qu'un document rédigé par un humain sur cinquante sera signalé comme ayant été généré par une IA. Et un taux de 0,67 % signifie qu'un document rédigé par un humain sur cent cinquante sera signalé comme ayant été généré par une IA.
De même, un taux de faux négatifs de 10 % signifie qu'un document généré par l'IA sur dix passe inaperçu, tandis qu'un taux de 1,4 % signifie qu'un document généré par l'IA sur soixante-dix passe inaperçu.
Réfléchissons aux implications de ces résultats. On ne peut pas se fier à un modèle de détection présentant un taux de faux positifs de 9 % ; sinon, les fausses accusations se multiplieraient. Quant à un modèle de détection présentant un taux de faux négatifs de 10 %, il laisserait passer tellement de spam généré par l'IA que, quelle que soit l'attaque, les utilisateurs seraient tout de même submergés.
Analyser les résultats en détail
Notre référence s'articule autour de deux axes distincts : le domaine textuel et le modèle de langage de base (LLM) d'origine. Le « domaine textuel », ou simplement « domaine », désigne une catégorie spécifique d'écrits. Par exemple, une dissertation de collège se lit très différemment d'un article scientifique, qui lui-même se lit très différemment d'un e-mail. En classant les résultats par domaine, nous pouvons mieux cerner les domaines dans lesquels nous excellons et ceux sur lesquels nous devons concentrer nos efforts pour nous améliorer.
 Précision par domaine textuel
Précision par domaine textuel
Les résultats montrent que Pangram Labs surpasse GPTZero et Originality dans les dix domaines évalués.
L'un des domaines, celui des e-mails, affiche des résultats particulièrement bons, car Pangram Labs n'inclut aucun e-mail dans ses données d'entraînement. Nos performances dans ce domaine reposent entièrement sur l'entraînement d'un modèle robuste capable de s'adapter à la plupart des types de textes qu'un LLM peut produire.
 Documents classés correctement par l'IA, selon le modèle de langage (LLM) d'origine
Documents classés correctement par l'IA, selon le modèle de langage (LLM) d'origine
Une analyse par modèle de langage (LLM) d'origine révèle une autre réalité : les modèles concurrents de détection de l'IA obtiennent de meilleurs résultats sur les modèles open source moins performants, mais obtiennent des résultats moins bons sur ChatGPT (gpt-3.5-turbo) et peinent considérablement sur GPT-4, le modèle de langage le plus performant d'OpenAI. Nous avons évalué plusieurs versions des modèles GPT 3.5 Turbo et GPT-4, car ce sont ceux qui sont le plus couramment utilisés dans la pratique.
Nous constatons que notre modèle est le seul capable de détecter de manière fiable les textes générés par GPT-4, et qu'il surpasse également tous les autres modèles que nous avons testés.
Il est intéressant de noter que notre concurrent obtient de bien meilleurs résultats sur les modèles open source que sur les modèles GPT et Gemini, qui sont propriétaires. Nous émettons l'hypothèse que cela est dû à une dépendance excessive aux caractéristiques de perplexité et de burstiness – bien que ces caractéristiques soient précieuses, on ne peut calculer avec précision la perplexité et la burstiness que sur un modèle open source : sur les modèles closed-source, on ne peut qu'effectuer une estimation approximative. Cela démontre la valeur de notre approche basée sur l'apprentissage profond – elle ne repose pas sur des caractéristiques fragiles comme la perplexité et peut apprendre des schémas sous-jacents plus subtils.
Robustesse
Une question qui nous est souvent posée est la suivante : que se passe-t-il lorsqu’un nouveau modèle linguistique est lancé ? Faut-il entraîner le modèle sur chaque nouvelle version pour détecter ses résultats ? En bref, non. OpenAI a publié deux nouvelles versions de ses modèles linguistiques de grande envergure (LLM) au cours des dernières semaines. Sans avoir du tout entraîné notre modèle sur ces nouveaux LLM, nous l’avons évalué et avons constaté qu’il fonctionnait toujours très bien !
- GPT-3.5-Turbo-0125 : précision de 99,66 %
- GPT-4-0125-Aperçu : précision de 99,18 %
Ces nouvelles versions sont similaires aux versions précédentes publiées par OpenAI. La question qui se pose alors est la suivante : quels sont nos résultats avec des familles de modèles totalement différentes ? Pour y répondre, nous avons évalué notre modèle sur un ensemble de modèles open source que notre classificateur n'avait jamais rencontrés auparavant.
 Performances d'un grand modèle de langage (LLM) open source, non observées par Pangram Labs pendant la phase d'entraînement.
Performances d'un grand modèle de langage (LLM) open source, non observées par Pangram Labs pendant la phase d'entraînement.
C'est vraiment génial ! Cela s'explique en grande partie par le fait que de nombreux modèles open source s'inspirent de la famille Llama ou utilisent des ensembles de données d'entraînement open source similaires, mais cela nous permet d'avoir confiance en notre capacité à généraliser sans avoir à entraîner chaque modèle open source individuellement.
Cela dit, notre pipeline de données est conçu de manière à nous permettre de générer un nouvel ensemble d'apprentissage dans les heures qui suivent la publication d'une API de modèle de langage (LLM) – la seule contrainte étant la limite de débit de l'API. Nous sommes pleinement conscients que les modèles de langage continuent de s'améliorer, et à mesure que nous nous rapprochons de l'IA générale (AGI), il sera de plus en plus important de rester à la page et de veiller à pouvoir suivre le rythme même des agents d'IA les plus avancés.
L'anglais comme deuxième langue
Des études antérieures ont montré que les détecteurs de modèles de langage à grande échelle (LLM) disponibles dans le commerce font systématiquement preuve de partialité à l'égard des locuteurs non natifs (ESL, ou anglais langue seconde). Pour vérifier cette hypothèse, les chercheurs ont utilisé un ensemble de référence composé de 91 dissertations issues du TOEFL (Test of English as a Foreign Language) afin de tester plusieurs détecteurs.
Nous avons sélectionné les 91 dissertations du TOEFL issues de notre ensemble d'entraînement et avons évalué Pangram Labs sur ce benchmark. Grâce à nos efforts visant à réduire les taux de faux positifs pour les locuteurs non natifs, nous enregistrons un taux de faux positifs de 0 % sur le benchmark TOEFL, ce qui signifie qu'aucune des dissertations rédigées par des humains dans ce benchmark n'a été classée à tort comme provenant d'une IA.
 Comparaison avec les critères de référence du TOEFL
Comparaison avec les critères de référence du TOEFL
L'approche de Pangram Labs en matière de détection de l'IA
Détecter les contenus générés par l'IA n'est pas une mince affaire. Nous entraînons un modèle d'apprentissage profond doté d'une architecture de type « transformers », en recourant à deux méthodes clés pour améliorer considérablement la précision de notre modèle.
Miroirs synthétiques
Chaque document de notre ensemble d'apprentissage est étiqueté soit « Humain », soit « IA ». En apprentissage automatique, on appelle ces documents des « exemples ».
Nous disposons de millions d'exemples humains issus de bases de données publiques pour l'entraînement, mais nous n'avons pas d'équivalent en matière de données d'IA. Nous résolvons ce problème en associant chaque exemple humain à un « miroir synthétique » – un terme que nous utilisons pour décrire un document généré par l'IA et basé sur un document humain. Nous interrogeons un LLM en lui demandant un document sur le même sujet et de même longueur. Pour une partie des exemples, nous demandons au LLM de partir de la première phrase du document humain, afin de rendre les documents générés par l'IA plus variés.
Exploitation minière « hard negative »
Très tôt, nous avons atteint une limite dans l'entraînement de notre modèle. Nous avons essayé d'ajouter davantage d'exemples, mais nous avons fini par constater que le modèle était « saturé » : l'ajout d'exemples d'entraînement supplémentaires n'améliorait plus ses performances.
 Expérience sur les lois d'échelle
Expérience sur les lois d'échelle
Les performances de ce premier modèle n'étaient pas satisfaisantes : il affichait encore un taux de faux positifs supérieur à 1 % dans de nombreux domaines. Nous avons constaté que nous n'avions pas seulement besoin de plus d'exemples, mais aussi d'exemples plus complexes.
Nous avons identifié des exemples plus complexes en partant de notre modèle initial et en analysant des dizaines de millions d'exemples humains issus de jeux de données ouverts, à la recherche des documents les plus difficiles que notre modèle avait mal classés. Nous avons ensuite généré des versions synthétiques de ces documents et les avons ajoutées à notre ensemble d'apprentissage. Enfin, nous avons réentraîné le modèle et répété le processus.
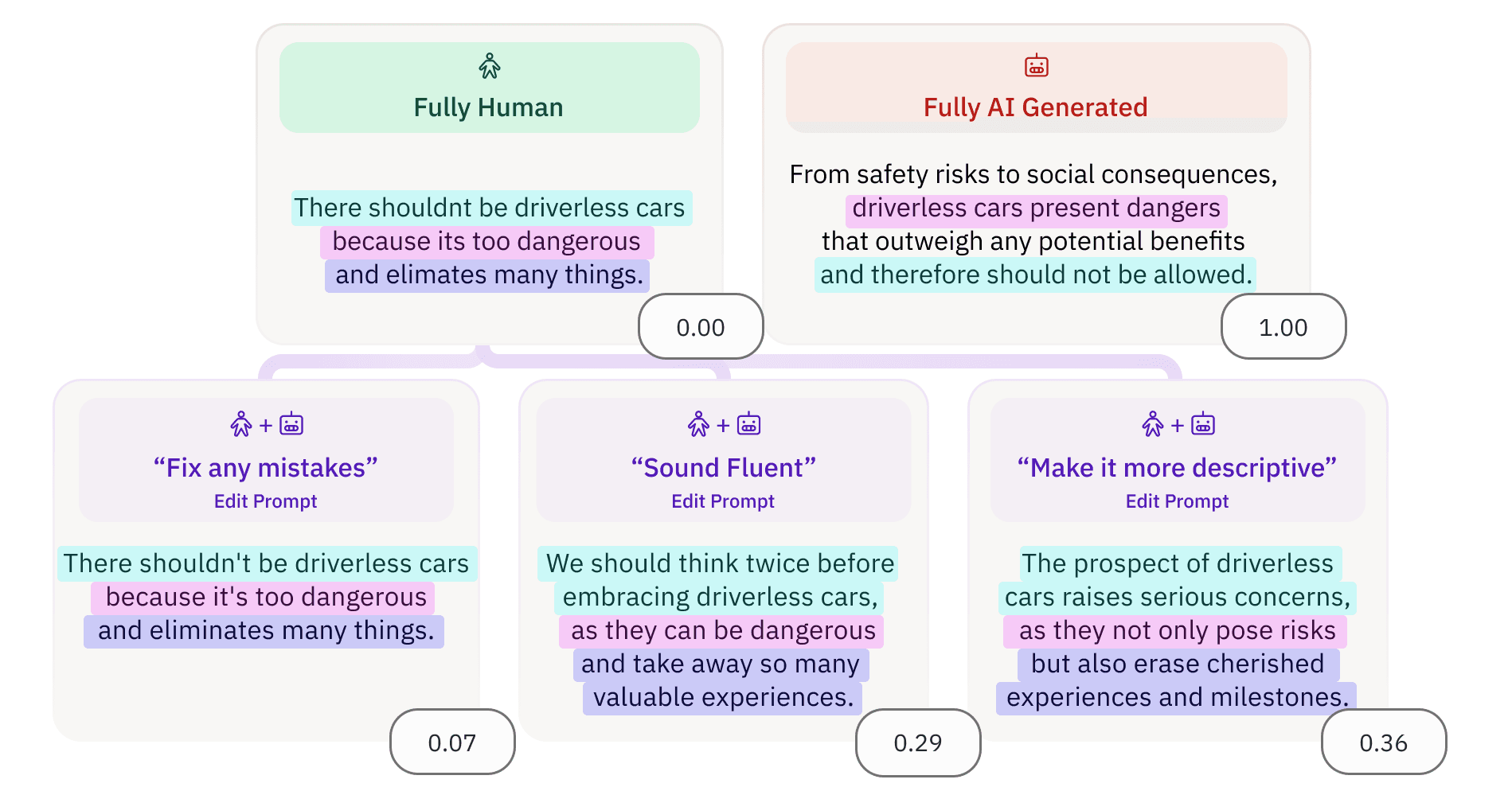
Processus d'entraînement du classificateur de textes générés par IA de Pangram Labs
Grâce à cette méthode d'entraînement, nous avons réussi à réduire notre taux de faux positifs d'un facteur 100 et à mettre en production un modèle dont nous sommes fiers.
 Tableau des taux de faux positifs par domaine
Tableau des taux de faux positifs par domaine
Nous appelons cette méthode « l'exploration des négatifs durs à l'aide de miroirs synthétiques » et nous en détaillons le processus dans notre rapport technique.
Quelle est la prochaine étape pour Pangram Labs ?
Bien sûr, notre parcours ne s'arrête pas là. Nous avons toute une série de nouvelles idées pour faire passer nos performances au niveau supérieur. Nous allons continuer à améliorer nos ensembles d'évaluation afin de pouvoir suivre de plus près le taux de faux positifs, jusqu'au centième de pour cent près. Nous prévoyons d'étendre notre modèle à d'autres langues que l'anglais et nous nous efforçons de comprendre et d'identifier nos cas d'échec. Restez à l'affût de nos prochaines initiatives !
Vous avez des questions ou des remarques ? Écrivez-nous à l'adresse info@pangram.com!

Bradley est chercheur en intelligence artificielle et spécialiste du développement de produits basés sur l'apprentissage profond dans le secteur industriel. Il a récemment dirigé le groupe de recherche sur l'apprentissage profond chez Absci, une entreprise spécialisée dans la découverte de médicaments par l'IA générative, et faisait auparavant partie de l'équipe principale chargée de la vision par ordinateur chez Tesla Autopilot.
Pendant ses études supérieures, Bradley a rédigé plusieurs articles de recherche sur l'apprentissage profond au sein du Stanford Vision Lab. Il est titulaire d'une licence en physique et d'un master en intelligence artificielle de l'université de Stanford. Outre l'IA, il s'intéresse également à l'éducation et à la philosophie, et est un passionné de golf.

Max est un ingénieur chevronné en apprentissage automatique. Il a récemment travaillé sur les véhicules autonomes chez Nuro, où il a dirigé les efforts en matière d'apprentissage actif. Il possède une longue expérience dans le déploiement de produits d'apprentissage automatique couronnés de succès chez Google, Two Sigma et Yelp.
Max est titulaire d'une licence en informatique théorique et d'un master en intelligence artificielle de l'université de Stanford. Outre sa passion pour la construction, il est également un membre actif de la communauté des cubes de Magic: The Gathering.
Lectures complémentaires

Une étude indépendante démontre que Pangram est le détecteur d'IA le plus performant

Le pangram fonctionne-t-il dans Claude Fable 5 ?

Pangram détecte-t-il Llama 4 de Meta ?

Présentation des balises et des groupes

Pangram est désormais capable de détecter les outils d'humanisation basés sur l'IA
Pangram 3.0 : Quantifier l'ampleur de la révision par l'IA dans les textes
