O Pangram é o único detetor de IA que supera os especialistas humanos na identificação de conteúdos gerados por IA
Estamos entusiasmados com a nova investigação de Jenna Russell, Marzena Karpinksa e Mohit Iyyer, colaboradores da Universidade de Maryland e da Microsoft, que demonstra que o Pangram é o detetor de IA com melhor desempenho numa comparação e o único sistema capaz de superar especialistas humanos experientes na deteção de conteúdos gerados por IA. Leia o artigo completo aqui.

Para além de estudarem a eficácia dos detetores automáticos de IA, os investigadores também analisam a forma como os especialistas humanos experientes identificam sinais que os ajudam a determinar os indícios reveladores de conteúdos gerados por IA. Acreditamos que esta investigação representa um enorme passo em frente no que diz respeito à explicabilidade e à interpretabilidade na deteção de IA e estamos entusiasmados por explorar mais a fundo esta linha de investigação.
Nesta publicação do blogue, iremos explicar os pontos-chave da investigação e o que isso significa para a deteção de LLM no futuro.
Formar pessoas para se tornarem detetores de IA
Já escrevemos anteriormente sobre como detectar textos gerados por IA e sobre o teste de referência humano, bem como sobre a forma como o utilizamos para obter uma intuição valiosa sobre textos gerados por IA, o que nos ajuda a desenvolver modelos melhores.
Normalmente, quando começamos a tentar treinar-nos para identificar críticas, ensaios, publicações em blogs ou notícias geradas por IA, no início não somos muito bons nisso. Leva algum tempo até começarmos a perceber os sinais reveladores de que um texto foi gerado pelo ChatGPT ou por outro modelo de linguagem. Por exemplo, quando começámos a estudar críticas, aprendemos com o tempo, ao analisar muitos dados, que o ChatGPT adora começar uma crítica com a frase «Recentemente, tive o prazer de», ou quando começámos a ler histórias de ficção científica geradas por IA, estas começam frequentemente com a frase «No ano de». No entanto, com o tempo, começamos a interiorizar estes padrões e passamos a reconhecê-los.
Os investigadores também se questionaram se os especialistas poderiam ser formados para detetar artigos gerados por IA da mesma forma. Formaram cinco anotadores na Upwork para detetar conteúdos gerados por IA e compararam a sua capacidade de identificar a IA à primeira vista com a de pessoas sem conhecimentos especializados.
Embora fosse de esperar uma diferença na capacidade destes dois grupos para identificar o texto escrito por IA, o que os investigadores descobriram foi uma diferença substancial. Os leigos têm um desempenho semelhante ao do acaso na deteção de texto gerado por IA, enquanto os especialistas demonstram uma elevada precisão (uma taxa de verdadeiros positivos superior a 90 %, em média).

Uma secção que achámos particularmente interessante foi a intitulada «O que é que os anotadores especializados vêem que os leigos não vêem?». Os investigadores pediram aos participantes que explicassem por que razão achavam que um texto tinha sido gerado por IA ou não, e depois analisaram os comentários dos participantes.
Eis algumas análises retiradas diretamente do artigo:
«Os leigos tendem frequentemente a fixar-se erroneamente em certas propriedades linguísticas, ao contrário dos especialistas. Um exemplo é a escolha do vocabulário, em que os leigos interpretam a inclusão de qualquer palavra «sofisticada» ou de baixa frequência como um indício de texto gerado por IA; em contrapartida, os especialistas estão muito mais familiarizados com palavras e expressões específicas que a IA utiliza em excesso (por exemplo, «testamento», «crucial»). Os leigos também acreditam que os autores humanos são mais propensos a formar frases gramaticalmente corretas e, por isso, atribuem frases encadeadas à IA, mas o oposto é verdadeiro: os humanos são mais propensos do que a IA a usar frases incorretas ou encadeadas. Por fim, os leigos atribuem qualquer texto escrito num tom neutro à IA, o que resulta em muitos falsos positivos, uma vez que a escrita humana formal também é frequentemente neutra no tom.» (Russell, Karpinska e Iyyer, 2025).
No apêndice, os autores apresentam uma lista do «vocabulário de IA» mais utilizado pelo ChatGPT – uma funcionalidade que lançámos recentemente no painel do Pangram e que destaca as expressões de IA mais comuns!

Pela nossa experiência, constatámos que, apesar de muitas pessoas pensarem que a IA utiliza um vocabulário sofisticado e «sofisticado», na prática verificamos que a IA tende, pelo contrário, a utilizar um vocabulário mais clichê e metafórico que, muitas vezes, não faz qualquer sentido. De forma informal, diríamos que os LLMs são mais como pessoas que tentam parecer inteligentes, mas que, na verdade, estão apenas a usar frases que acham que as farão parecer inteligentes.
Robustez dos detectores de IA face aos modelos de última geração
Uma das perguntas que nos fazem frequentemente na Pangram é: como é que se mantêm a par dos modelos de ponta? Quando os modelos linguísticos melhoram, isso significa que a Pangram deixará de funcionar? Será um jogo do gato e do rato em que os laboratórios de vanguarda, como a OpenAI, acabarão por nos vencer?
Os investigadores também se questionaram sobre isso e analisaram o desempenho de vários métodos de deteção de IA face ao o1-pro da OpenAI, o modelo mais avançado lançado até à data.
Os investigadores descobriram que o Pangram tem uma precisão de 100% na deteção de resultados do o1-pro, e ainda assim atingimos uma precisão de 96,7% na deteção de resultados «humanizados» do o1-pro (assunto que abordaremos daqui a pouco)! Em comparação, nenhum outro detetor automatizado chega sequer aos 76,7% nos resultados básicos do o1-pro.
Como é que o Pangram consegue generalizar desta forma? Afinal, na altura do estudo, nem sequer tínhamos dados do o1-pro no nosso conjunto de treino.
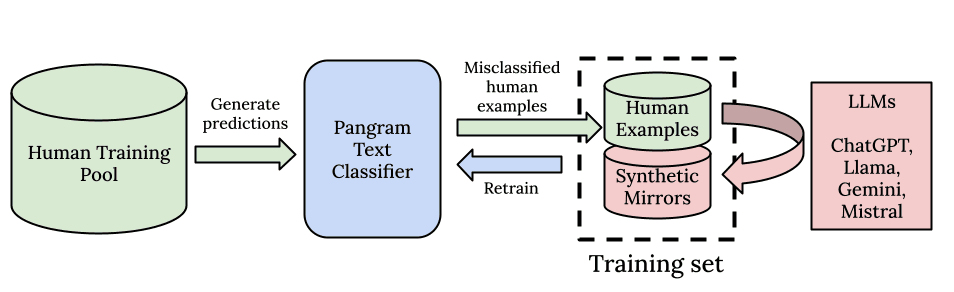
Tal como todos os modelos de aprendizagem profunda, acreditamos no poder da escala e da capacidade computacional. Em primeiro lugar, partimos de um modelo base poderoso, pré-treinado num enorme corpus de treino, tal como os próprios LLMs. Em segundo lugar, criámos um pipeline de dados concebido para a escala. O Pangram é capaz de reconhecer padrões subtis a partir do seu corpus de treino de 100 milhões de documentos escritos por humanos.
Não nos limitamos a construir um conjunto de dados para ensaios, notícias ou críticas: tentamos obter a rede mais ampla possível de todos os dados escritos por humanos que existem, para que o modelo possa aprender a partir da distribuição de dados da mais alta qualidade e mais diversificada e aprender sobre todos os tipos de escrita humana. Constatamos que esta abordagem geral à deteção de IA funciona muito melhor do que a abordagem especializada de construir um modelo por domínio de texto.
A complementar o nosso conjunto de dados humanos extremamente vasto e de alta qualidade está o nosso pipeline de dados sintéticos e o nosso algoritmo de pesquisa baseado na aprendizagem ativa. Para obter os dados de IA necessários ao nosso algoritmo, utilizamos uma biblioteca exaustiva de prompts e todos os principais modelos de IA de código aberto e fechado para gerar dados sintéticos. Utilizamos prompts espelho sintéticos, sobre os quais escrevemos no nosso relatório técnico, e a mineração de falsos negativos, que procura os exemplos no nosso conjunto de dados com o maior erro e cria exemplos de IA muito semelhantes aos humanos, retreinando o modelo até não observarmos mais erros. Isso permite-nos reduzir as taxas de falsos positivos e falsos negativos do nosso modelo para zero de forma muito eficiente.
Em resumo, a nossa generalização deve-se à dimensão dos nossos dados de pré-treino, à diversidade de prompts e de modelos de linguagem de grande escala (LLMs) utilizados na geração de dados sintéticos, bem como à eficiência dos dados resultante da nossa abordagem de aprendizagem ativa e de mineração de exemplos negativos.
Além disso, não nos limitamos a procurar um excelente desempenho fora da distribuição, mas também queremos garantir que o maior número possível de LLMs comuns se encontre, na medida do possível, dentro da distribuição. Por isso, criámos um fluxo de trabalho automatizado e robusto para recolher dados dos modelos mais recentes, de modo a podermos iniciar o treino com novos LLMs assim que forem lançados e manter-nos atualizados. Constatamos que não se trata de um compromisso entre equilibrar o desempenho em diferentes modelos: verificamos que, sempre que introduzimos um novo LLM no conjunto de treino, a generalização do modelo melhora.
Com o nosso sistema atual, não estamos a constatar que, à medida que os modelos melhoram, se tornem mais difíceis de detetar. Em muitos casos, o modelo da próxima geração é, na verdade, mais fácil de detetar. Por exemplo, verificámos que fomos mais precisos na deteção do Claude 3 quando este foi lançado do que no caso do Claude 2.
Ataques do Paraphraser e do Humanizer
Na nossa recente série de publicações no blogue, descrevemos o que é um «humanizador de IA» e lançámos também um modelo com um desempenho significativamente melhorado na humanização de textos gerados por IA. É com satisfação que constatamos que uma entidade externa já validou as nossas afirmações com um conjunto de dados de artigos humanizados da o1-pro.
No texto humanizado o1-pro, alcançamos uma precisão de 96,7%, enquanto o segundo melhor modelo automatizado consegue detetar apenas 46,7% do texto humanizado.
Também apresentamos 100% de precisão no texto do GPT-4o que foi parafraseado frase a frase.
Conclusão
Estamos entusiasmados com o excelente desempenho do Pangram num estudo independente sobre as capacidades de deteção da IA. Temos sempre todo o prazer em apoiar a investigação académica e disponibilizamos acesso livre a todos os académicos que desejem estudar o nosso detetor.
Para além de avaliarmos o desempenho dos detetores automatizados, estamos entusiasmados por ver investigações que começam também a abordar a explicabilidade e a interpretabilidade da deteção por IA: não se trata apenas de saber se algo foi escrito por IA, mas sim porquê. Estamos ansiosos por escrever mais sobre como estes resultados podem ajudar professores e educadores a identificar, à primeira vista, textos gerados por IA, e sobre como pretendemos incorporar esta investigação em ferramentas de deteção automatizada mais explicáveis.
Para mais informações, visite o nosso site pangram.com ou contacte-nos através do endereço info@pangram.com.

Bradley é investigador na área da IA e especialista no desenvolvimento de produtos de aprendizagem profunda no setor industrial. Recentemente, liderou o grupo de investigação em aprendizagem profunda da Absci, uma empresa de descoberta de medicamentos que utiliza IA generativa, e, anteriormente, integrou a equipa principal de visão computacional do Tesla Autopilot.
Enquanto estudante de pós-graduação, Bradley foi autor de várias publicações na área da investigação sobre aprendizagem profunda no Stanford Vision Lab. É licenciado em Física e mestre em Inteligência Artificial pela Universidade de Stanford. Para além da IA, interessa-se também por educação e filosofia, e é um ávido jogador de golfe.
Leitura relacionada

Novos níveis de produtos Pangram

Qual é a capacidade do Pangram para detetar modelos de raciocínio?

Apresentamos a nova página de resultados

Os detectores de IA funcionam contra o GPT-5?
Relatório técnico sobre a deteção de texto gerado por IA com elevada precisão

Como detectar IA em Python
para receber as nossas atualizações
