Pangram ist der einzige KI-Detektor, der bei der Erkennung von KI-Inhalten besser abschneidet als menschliche Experten
Wir freuen uns über die neuen Forschungsergebnisse von Jenna Russell, Marzena Karpinska und Mohit Iyyer, Forscher der University of Maryland und von Microsoft, die zeigen, dass „Pangram“ in einem Vergleichstest als der leistungsstärkste KI-Detektor hervorgeht und das einzige System ist, das bei der Erkennung von KI-generierten Inhalten sogar geschulte menschliche Experten übertrifft. Lesen Sie hier den vollständigen Artikel.

Neben der Untersuchung der Wirksamkeit automatisierter KI-Detektoren befassen sich die Forscher auch damit, wie geschulte Experten Anhaltspunkte erkennen, anhand derer sie die typischen Merkmale von KI-generierten Inhalten bestimmen können. Wir sind der Ansicht, dass diese Forschung einen großen Fortschritt für die Erklärbarkeit und Interpretierbarkeit bei der KI-Erkennung darstellt, und freuen uns darauf, diesen Forschungsansatz weiter zu vertiefen.
In diesem Blogbeitrag erläutern wir die wichtigsten Ergebnisse der Studie und was sie für die künftige Erkennung von LLM-Inhalten bedeutet.
Menschen darin schulen, KI-Detektoren zu werden
Wir haben bereits darüber berichtet, wie man KI-Texte erkennt und wie der „Human Baseline Test“ funktioniert, sowie darüber, wie wir diese Erkenntnisse nutzen, um wertvolle Einblicke in KI-generierte Texte zu gewinnen, die uns dabei helfen, bessere Modelle zu entwickeln.
Wenn wir uns darin üben wollen, von KI generierte Rezensionen, Essays, Blogbeiträge oder Nachrichten zu erkennen, sind wir anfangs meist noch nicht besonders gut darin. Es dauert eine Weile, bis wir die verräterischen Anzeichen dafür erkennen, dass ein Text von ChatGPT oder einem anderen Sprachmodell generiert wurde. Als wir beispielsweise begannen, Rezensionen zu untersuchen, lernten wir im Laufe der Zeit anhand zahlreicher Daten, dass ChatGPT Rezensionen gerne mit dem Satz „Ich hatte kürzlich das Vergnügen, ...“ beginnt, oder als wir anfingen, KI-generierte Science-Fiction-Geschichten zu lesen, stellten wir fest, dass diese häufig mit dem Satz „Im Jahr ...“ beginnen. Mit der Zeit verinnerlichen wir diese Muster jedoch und können sie erkennen.
Die Forscher fragten sich zudem, ob Experten auf dieselbe Weise darin geschult werden können, von KI generierte Artikel zu erkennen. Sie schulten fünf Korrektoren auf Upwork darin, von KI generierte Inhalte zu erkennen, und verglichen deren Fähigkeit, KI auf den ersten Blick zu erkennen, mit der von Laien.
Zwar war zu erwarten, dass sich diese beiden Gruppen in ihrer Fähigkeit, von KI verfasste Texte zu erkennen, unterscheiden würden, doch stellten die Forscher eine erhebliche Diskrepanz fest. Laien schneiden beim Erkennen von KI-generierten Texten ähnlich wie bei einem Zufallstest ab, während Experten eine hohe Trefferquote aufweisen (im Durchschnitt über 90 % bei der True-Positive-Rate).

Ein Abschnitt, den wir besonders interessant fanden, war der Abschnitt „Was sehen erfahrene Korrektoren, was Laien nicht sehen?“. Die Forscher baten die Teilnehmer, zu erklären, warum sie glaubten, dass ein Text von einer KI generiert worden sei oder nicht, und analysierten anschließend die Kommentare der Teilnehmer.
Hier sind einige Auszüge aus der Studie:
„Laien legen im Vergleich zu Experten oft fälschlicherweise zu viel Wert auf bestimmte sprachliche Merkmale. Ein Beispiel ist die Wortwahl: Laien werten das Vorkommen von „ausgefallenen“ oder anderweitig seltenen Wörtern als Anzeichen für KI-generierten Text; Experten hingegen sind viel besser mit den genauen Wörtern und Phrasen vertraut, die von KI übermäßig häufig verwendet werden (z. B. „testament“, „crucial“). Laien glauben zudem, dass menschliche Autoren eher grammatikalisch korrekte Sätze bilden, und schreiben daher Bandwurmsätze der KI zu, doch das Gegenteil ist der Fall: Menschen verwenden eher ungrammatische oder Bandwurmsätze als KI. Schließlich schreiben Laien jeden Text, der in einem neutralen Ton verfasst ist, der KI zu, was zu vielen Fehlalarmen führt, da auch formelle menschliche Texte oft einen neutralen Ton haben.“ (Russell, Karpinska & Iyyer, 2025).
Im Anhang stellen die Autoren eine Liste mit „KI-Begriffen“ bereit, die von ChatGPT häufig verwendet werden – eine Funktion, die wir kürzlich im Pangram-Dashboard eingeführt haben und die häufig verwendete KI-Ausdrücke hervorhebt!

Unserer Erfahrung nach haben wir festgestellt, dass viele Menschen zwar glauben, KI verwende ein ausgefeiltes, „anspruchsvolles“ Vokabular, wir in der Praxis jedoch feststellen, dass KI stattdessen eher klischeehafte, metaphorische Ausdrücke verwendet, die oft keinen Sinn ergeben. Umgangssprachlich würden wir sagen, dass große Sprachmodelle eher wie Menschen sind, die versuchen, klug zu klingen, aber in Wirklichkeit nur Formulierungen verwenden, von denen sie glauben, dass sie sie klug klingen lassen.
Robustheit von KI-Detektoren gegenüber modernsten Modellen
Eine Frage, die uns bei Pangram häufig gestellt wird, lautet: Wie haltet ihr mit den neuesten Modellen Schritt? Wenn die Sprachmodelle immer besser werden, bedeutet das dann, dass Pangram nicht mehr funktionieren wird? Ist es ein Katz-und-Maus-Spiel, bei dem uns Vorreiter wie OpenAI schlagen werden?
Auch die Forscher stellten sich diese Frage und untersuchten die Leistungsfähigkeit verschiedener KI-Erkennungsmethoden im Vergleich zu „o1-pro“ von OpenAI, dem bislang fortschrittlichsten Modell.
Die Forscher stellten fest, dass Pangram bei der Erkennung von o1-pro-Ausgaben eine Genauigkeit von 100 % aufweist, und selbst bei der Erkennung von „humanisierten“ o1-pro-Ausgaben (auf die wir gleich noch eingehen werden) liegt unsere Genauigkeit noch bei 96,7 %! Im Vergleich dazu erreicht kein anderer automatisierter Detektor bei einfachen o1-pro-Ausgaben auch nur 76,7 %.
Wie kann Pangram solche Verallgemeinerungen vornehmen? Schließlich hatten wir zum Zeitpunkt der Studie noch nicht einmal o1-pro-Daten in unserem Trainingssatz.
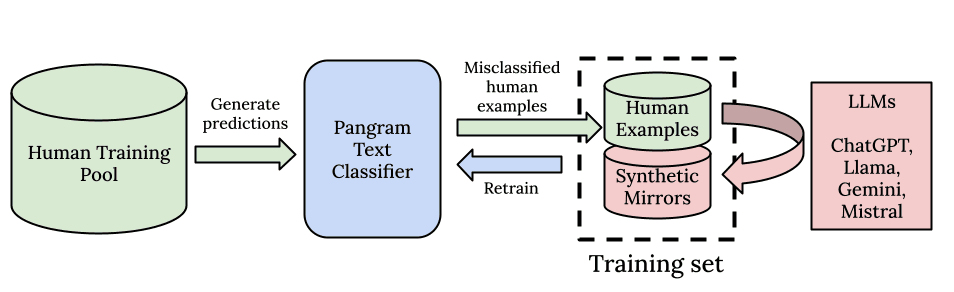
Wie bei allen Deep-Learning-Modellen setzen wir auf die Kraft von Skalierbarkeit und Rechenleistung. Zunächst beginnen wir mit einem leistungsstarken Basismodell, das – genau wie die LLMs selbst – anhand eines riesigen Trainingskorpus vortrainiert wurde. Zweitens haben wir eine Datenpipeline entwickelt, die auf Skalierbarkeit ausgelegt ist. Pangram ist in der Lage, anhand seines Trainingskorpus aus 100 Millionen von Menschen verfassten Dokumenten subtile Muster zu erkennen .
Wir erstellen nicht nur einen Datensatz für Essays, Nachrichten oder Rezensionen: Wir versuchen, ein möglichst breites Spektrum aller existierenden, von Menschen verfassten Daten zu sammeln, damit das Modell von der hochwertigsten und vielfältigsten Datenverteilung lernen und alle Arten menschlichen Schreibens erfassen kann. Wir stellen fest, dass dieser allgemeine Ansatz zur KI-Erkennung viel besser funktioniert als der spezialisierte Ansatz, ein Modell pro Textdomäne zu erstellen.
Ergänzend zu unserem extrem umfangreichen, qualitativ hochwertigen Datensatz mit menschlichen Daten setzen wir unsere Pipeline für synthetische Daten und einen auf aktivem Lernen basierenden Suchalgorithmus ein. Um die KI-Daten für unseren Algorithmus zu beschaffen, nutzen wir eine umfassende Bibliothek von Eingabeaufforderungen sowie alle wichtigen Open-Source- und Closed-Source-KI-Modelle zur Generierung synthetischer Daten. Wir verwenden synthetische Spiegel-Prompts, über die wir in unserem technischen Bericht berichtet haben, sowie Hard-Negative-Mining, bei dem wir in unserem Datenpool nach den Beispielen mit den höchsten Fehlern suchen und KI-Beispiele erstellen, die den menschlichen sehr ähnlich sehen, und das Modell so lange neu trainieren, bis wir keine Fehler mehr feststellen. Auf diese Weise können wir die Falsch-Positiv- und Falsch-Negativ-Raten unseres Modells sehr effizient auf null senken.
Kurz gesagt beruht unsere Verallgemeinerungsfähigkeit auf dem Umfang unserer Vortrainingsdaten, der Vielfalt der Prompts und der für die Generierung synthetischer Daten verwendeten großen Sprachmodelle sowie der Dateneffizienz, die wir durch unseren Ansatz des aktiven Lernens und des Hard-Negative-Mining erzielen.
Darüber hinaus streben wir nicht nur eine hervorragende Leistung bei Daten außerhalb der Trainingsdaten an, sondern möchten auch sicherstellen, dass möglichst viele der gängigen LLMs so gut wie möglich mit den Trainingsdaten übereinstimmen. Aus diesem Grund haben wir eine robuste automatisierte Pipeline entwickelt, um Daten aus den neuesten Modellen zu beziehen, sodass wir mit dem Training auf neuen LLMs beginnen können, sobald diese veröffentlicht werden, und stets auf dem neuesten Stand bleiben. Wir stellen fest, dass es sich nicht um einen Kompromiss zwischen der Leistungsbalance verschiedener Modelle handelt: Wir stellen fest, dass sich die Generalisierungsfähigkeit des Modells jedes Mal verbessert, wenn wir ein neues LLM in den Trainingssatz aufnehmen.
Bei unserem derzeitigen System stellen wir nicht fest, dass die Modelle mit zunehmender Verbesserung auch schwerer zu erkennen sind. In vielen Fällen ist das Modell der nächsten Generation sogar leichter zu erkennen. So haben wir beispielsweise festgestellt, dass wir Claude 3 bei seiner Veröffentlichung genauer erkennen konnten als Claude 2.
Angriffe auf Paraphrasierer und Humanizer
In unserer jüngsten Blog-Reihe haben wir erläutert, was ein „AI Humanizer“ ist, und zudem ein Modell veröffentlicht, das bei der Humanisierung von KI-Text eine deutlich verbesserte Leistung zeigt. Wir freuen uns, dass bereits ein Dritter unsere Aussagen anhand eines Datensatzes mit humanisierten o1-pro-Artikeln bestätigt hat.
Bei humanisiertem O1-Pro-Text erreichen wir eine Genauigkeit von 96,7 %, während das nächstbeste automatisierte Modell nur 46,7 % des humanisierten Textes erkennen kann.
Wir erzielen zudem eine 100-prozentige Genauigkeit bei GPT-4o-Texten, die Satz für Satz umformuliert wurden.
Fazit
Wir freuen uns sehr über die hervorragenden Ergebnisse, die Pangram in einer unabhängigen Studie zu KI-Erkennungsfähigkeiten erzielt hat. Wir unterstützen wissenschaftliche Forschung stets gerne und gewähren allen Wissenschaftlern, die unseren Detektor untersuchen möchten, freien Zugang.
Neben dem Leistungsvergleich automatisierter Erkennungssysteme freuen wir uns besonders über Forschungsarbeiten, die sich nun auch mit der Erklärbarkeit und Interpretierbarkeit der KI-Erkennung befassen: Es geht nicht nur darum, ob ein Text von einer KI verfasst wurde, sondern auch darum, warum. Wir freuen uns darauf, in Zukunft darüber zu berichten, wie diese Ergebnisse Lehrern und Pädagogen helfen können, KI-generierte Texte auf den ersten Blick zu erkennen, und wie wir diese Forschungsergebnisse in noch besser nachvollziehbare automatisierte Erkennungswerkzeuge einfließen lassen wollen.
Weitere Informationen finden Sie auf unserer Website pangram.com oder kontaktieren Sie uns unter info@pangram.com.

Bradley ist KI-Forscher und Experte für die Entwicklung von Deep-Learning-Produkten in der Industrie. Zuletzt leitete er die Deep-Learning-Forschungsgruppe bei Absci, einem Unternehmen für generative KI in der Arzneimittelforschung, und war zuvor Mitglied des Kernteams für Computer Vision bei Tesla Autopilot.
Während seines Masterstudiums verfasste Bradley im Rahmen des Stanford Vision Lab mehrere Veröffentlichungen im Bereich der Deep-Learning-Forschung. Er hat einen Bachelor of Science in Physik und einen Master of Science in Künstlicher Intelligenz von der Stanford University. Neben KI interessiert er sich auch für Bildung und Philosophie und ist ein begeisterter Golfer.
Weiterführende Literatur

Neue Pangram-Produktstufen

Wie gut kann Pangram Schlussfolgerungsmodelle erkennen?

Wir stellen die neue Ergebnisseite vor

Sind KI-Detektoren gegen GPT-5 wirksam?
Technischer Bericht zur hochpräzisen Erkennung von KI-generierten Texten

So erkennt man KI in Python
