
Ver no Espaço Pangram
Exploração das representações internas do Pangram 3.3.2
Por Elyas Masrour, Katherine Thai e Bradley Emi
Junho de 2026
Introdução
Desde o lançamento do ChatGPT em 2022, a escrita assistida por IA tem-se expandido a um ritmo impressionante. Como o texto gerado por IA está agora presente em grande parte do que lemos, tornou-se evidente que certas formas de escrita perdem o seu valor quando produzidas por uma máquina. No meio académico, os ensaios destinam-se a cultivar o raciocínio dos estudantes. No mercado, as avaliações de produtos são valiosas porque refletem as experiências de outras pessoas.
A Pangram é uma empresa de investigação que desenvolve modelos de deteção de IA de última geração para resolver este problema. O nosso produto principal é um modelo de deteção de texto por IA com taxas de falsos positivos entre as mais baixas do setor, capacidades multilingues e capacidade de distinguir entre conteúdo gerado por IA e conteúdo assistido por IA.
Desde o lançamento do nosso primeiro whitepaper em 2024, temos tido uma perspetiva única para acompanhar onda após onda de avanços na IA. Os nossos investigadores têm-se deparado com filtros de conteúdo excessivamente rigorosos e testemunhado o colapso de modos, e esquivou-se de ondas de travessões e da palavra «delve».
O nosso modelo principal é um LLM que foi ajustado especificamente para esta tarefa de classificação de sequências. Não utilizamos métricas personalizadas, como a perplexidade ou a variabilidade. Não fazemos qualquer extração manual de características. Temos, no entanto, um produto destinado aos clientes chamado «AI Phrases», através do qual fornecemos aos nossos utilizadores informações sobre frases que aparecem com maior frequência em textos gerados por IA. Mas estas não são utilizadas diretamente como características para o modelo. Passado algum tempo, a curiosidade surge: o que é que o modelo vê?
Para nós, enquanto investigadores, esta questão é importante. Temos um forte incentivo para evitar atalhos, corrigir comportamentos indesejados do modelo e compreender este problema em profundidade. Neste artigo, iremos apresentar os nossos esforços iniciais em matéria de interpretabilidade, recorrendo à análise ao nível do documento.
Dados
Criámos um conjunto de dados de interpretabilidade a partir de amostras retidas dentro do domínio, extraídas do nosso conjunto de treino de produção. O explorador interativo nesta página utiliza um subconjunto equilibrado de 5 000 documentos, repartidos de forma equitativa entre humanos e IA, ao longo de 20 camadas pares. As amostras de IA abrangem as variantes de modelo abaixo, nas seis famílias de modelos utilizadas para o teste do classificador.
Modelos
- Claude 3.7 Soneto
- Claude Soneto 4
- Claude Sonnet 4.5
- Claude Obra 4
- Claude Opus 4.1
- Claude Opus 4.5
- GPT-3.5 Turbo (novembro de 2023)
- GPT-3.5 Turbo (janeiro de 2024)
- GPT-4 (março de 2023)
- GPT-4 (junho de 2023)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- Qwen 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
Domínios de origem
- Notícias
- Resumos científicos
- Avaliações de produtos
- Avaliações de empresas
- Escrita Criativa no Reddit
- Reddit ELI5
- Livros (autoeditados)
- Livros (Projeto Gutenberg)
- Wikipedia (inglês)
- Wikipédia (Multilíngue)
- Lang-8 (ESL)
Visão geral do Pangram 3.3.2
O Pangram 3.3.2 é um modelo de deteção de IA lançado pela Pangram Labs em 2026. Utiliza o mesmo modelo subjacente que o Pangram 3.3, com correções de erros posteriores que melhoram o desempenho. O Pangram 3.3 sucedeu ao Pangram 3.2 e melhorou a taxa de recuperação em resultados de LLM mais recentes, texto humanizado e conteúdos longos gerados por IA, ao mesmo tempo que reduziu os falsos positivos em textos escritos por falantes não nativos de inglês.
Ficha do modeloLeia a ficha do modelo Pangram 3.3Consulte os detalhes do lançamento da versão Pangram 3.3.2.Ler artigoO trabalho sobre interpretabilidade está em curso. Ao longo deste artigo, também aplicamos os nossos métodos retroativamente ao Pangram 3.2 e ao Pangram 3.1.
Métodos
Ativações
A arquitetura EditLens é um sistema de classificação baseado em «buckets» que se resume a um único ai_assistance_score. Neste projeto, desconsideramos o resultado final do modelo e, em vez disso, concentramo-nos nas representações internas que o modelo aprende. Para as analisar, recolhemos as ativações realizando uma passagem direta do modelo com um determinado documento de entrada e guardando a representação oculta do modelo em várias camadas internas. Neste projeto, extraímos as ativações para cada documento, em todas as camadas pares ao longo da rede.
Redução da dimensionalidade
Cada vetor de ativação extraído tinha 5 120 dimensões. Para compreender melhor as representações, recorremos a várias técnicas de redução de dimensionalidade.
PCA
A Análise de Componentes Principais (PCA) é a projeção linear mais simples: identifica as direções de máxima variância no espaço de ativação. Neste projeto, constatamos que, na parte final da rede, a maior parte da variância está contida nas componentes principais 1 e 2 e, por isso, representamos graficamente estas duas componentes uma em relação à outra.
UMAP
O UMAP apresenta uma visualização não linear concebida para preservar a estrutura de vizinhança. Se dois documentos estiverem próximos um do outro no espaço interno do modelo, o UMAP tenta mantê-los próximos no espaço 2D. No entanto, os eixos e as distâncias exatas entre os agrupamentos não devem ser sobreinterpretados.
t-SNE
O t-SNE é outro método de projeção não linear que se destaca na identificação de agrupamentos locais. Para os fins deste projeto, utilizamos o t-SNE para verificar se os grupos semanticamente relevantes, tais como famílias de modelos ou rótulos «humano/IA», se agrupam de forma visível à medida que a rede se torna mais profunda.
Sondas lineares
Utilizamos sondas lineares para quantificar os resultados qualitativos que observamos a partir dos nossos métodos de redução de dimensionalidade. Para cada camada, verificamos se um classificador simples consegue recuperar um rótulo-alvo a partir dos vetores de ativação dessa camada. Uma elevada precisão da sonda significa que a distinção relevante já está codificada numa direção linearmente acessível do espaço de representação.
A tarefa de deteção por IA
Precisão binária
Para compreender como se consegue a separação final das classes ao longo da rede, treinamos sondas lineares em cada camada. O treino é realizado com 500 amostras, distribuídas uniformemente entre humanos e IA, com uma divisão de 80:20 entre treino e teste. Constatamos que, mesmo nas primeiras camadas da rede, o desempenho já é sólido: alcançamos uma precisão de 0,83 logo após a camada 2. Isto corresponde à nossa intuição, uma vez que os modelos «bag-of-words» são frequentemente linhas de base úteis para a tarefa de deteção de IA. Ao longo da rede, a precisão vai aumentando até atingir o valor máximo de 1,0 na camada 24.
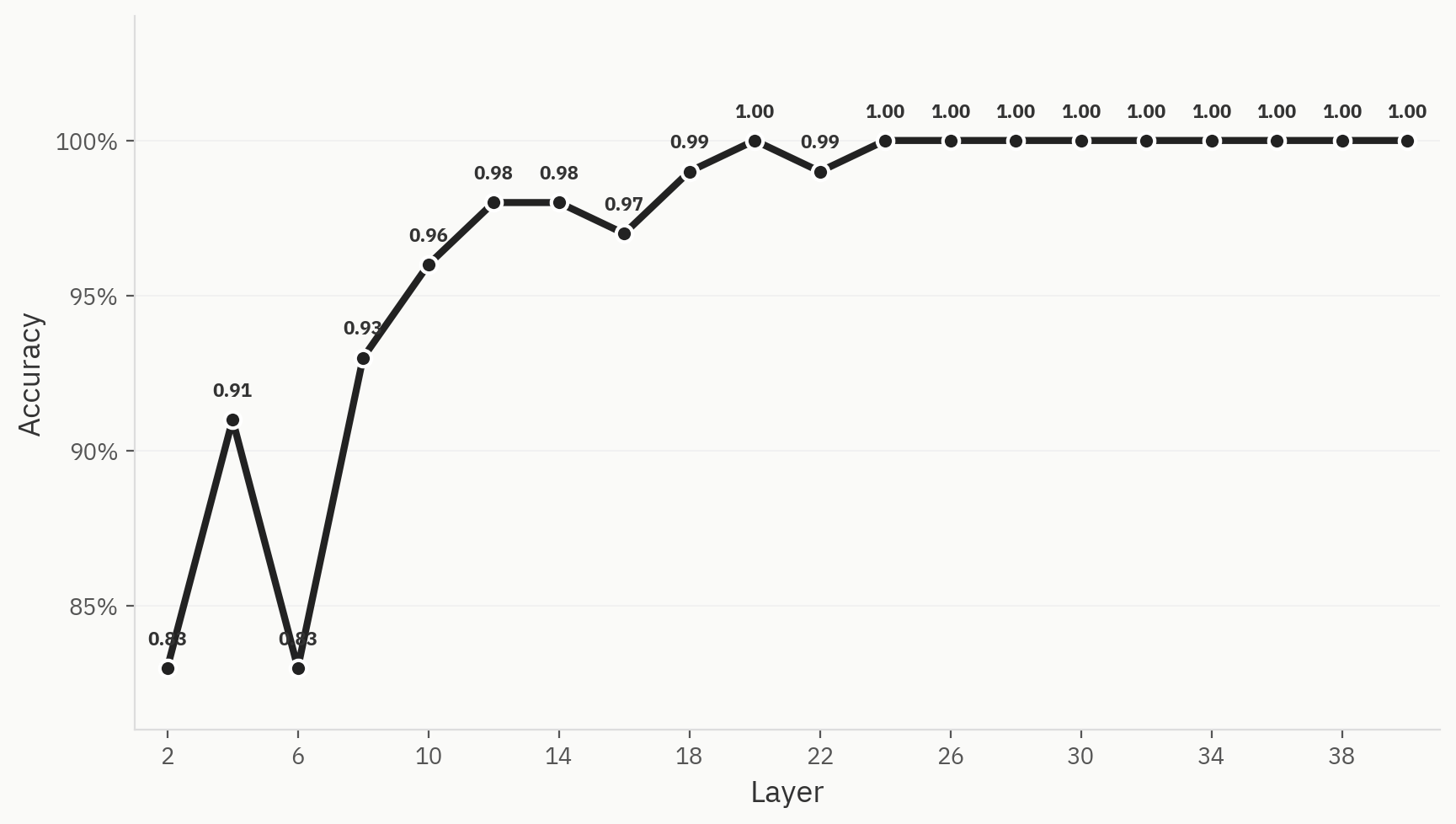
Fig. 3 Esta separação é claramente visível nos três métodos de redução de dimensões.
Classificação LLM
Nos gráficos do t-SNE e do UMAP, reparámos que os documentos pareciam agrupar-se de acordo com o modelo que os gerou. Isto foi uma surpresa para nós. As versões anteriores do Pangram tinham um módulo de classificação de LLM separado, mas essa tarefa específica já tinha sido abandonada há muito tempo. No seu processo de treino, o Pangram 3.3.2 não recebe quaisquer rótulos correspondentes ao modelo de origem de um documento de IA.
Apesar disso, formaram-se agrupamentos em torno da família de modelos de origem. E o que é ainda mais interessante é que esses agrupamentos parecem surgir em todas as camadas da rede.
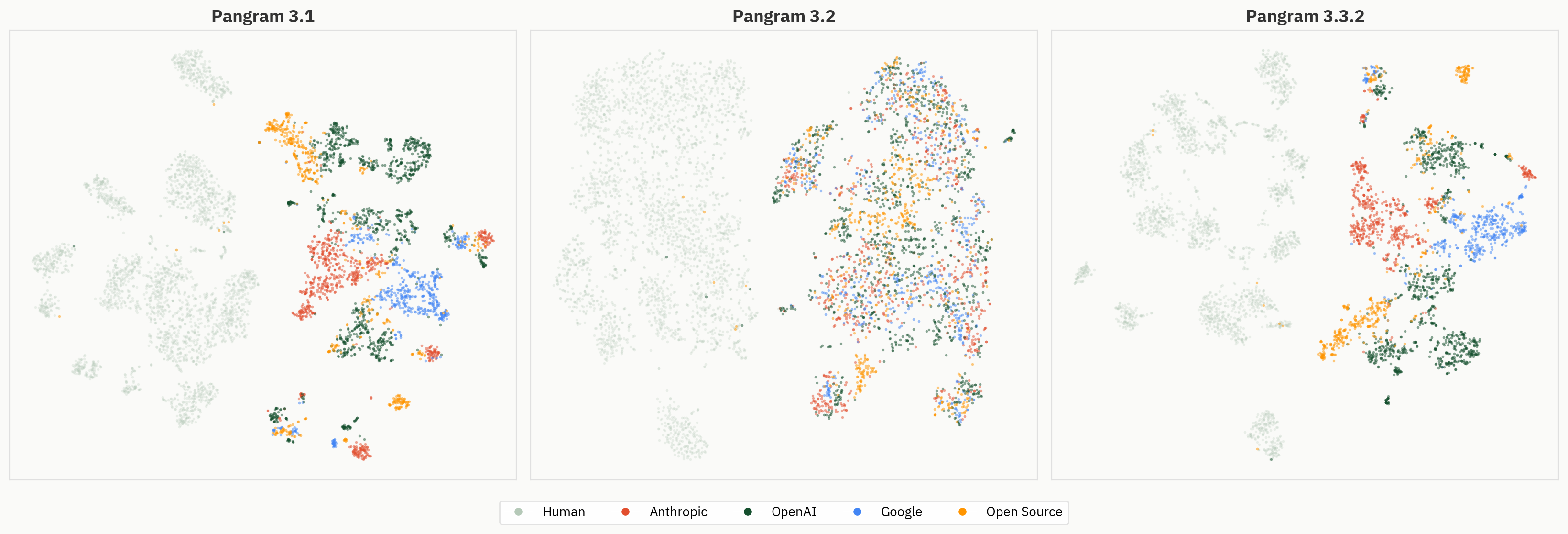
Surgimento de agrupamentos de modelos
Pinte as mesmas representações por família de modelos para ver a geometria ao nível do fornecedor a surgir em todas as camadas.
Fig. 4: Incorporações das camadas 2 a 40, coloridas por família de modelos. Os agrupamentos ao nível do prestador tornam-se mais visíveis nas camadas posteriores.
Sonda
Para quantificar este fenómeno, treinámos um classificador em seis famílias de modelos (Anthropic, OpenAI, Google, Qwen, Llama, DeepSeek) com 500 amostras por família de modelos e 3 000 amostras no total, numa divisão de 80:20 entre dados de treino e de teste. Constatamos que é, de facto, possível treinar um modelo capaz de classificar a família de modelos de origem de um determinado documento utilizando apenas ativações de pangramas, com uma precisão máxima top-1 de 91%.
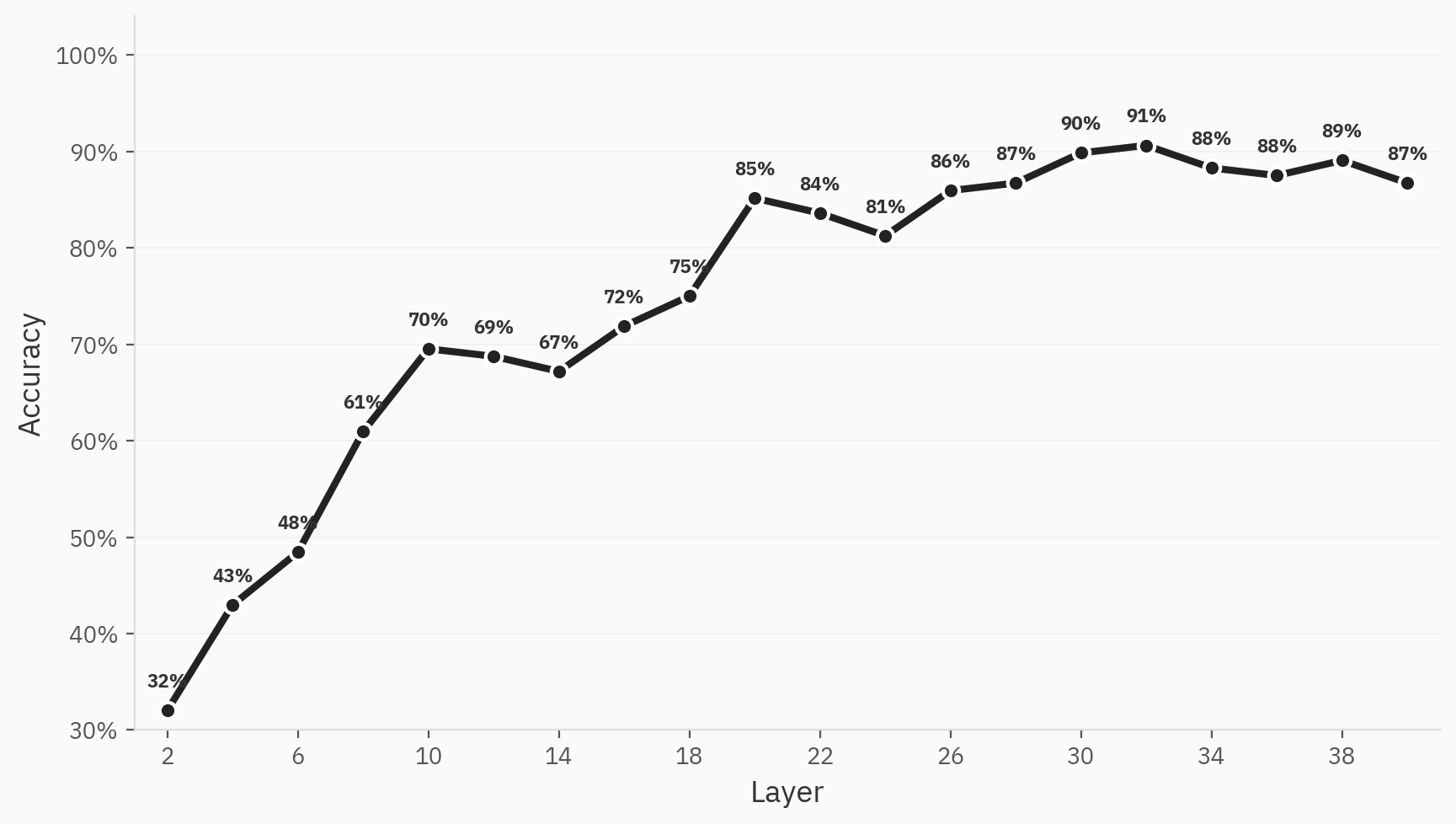
A emergência não é garantida
As nossas experiências iniciais sobre interpretabilidade incluíram testes com vários modelos. Para nossa surpresa, o surgimento de uma capacidade de «classificação por LLM» foi uma das únicas conclusões deste projeto que diferiu significativamente entre os modelos.
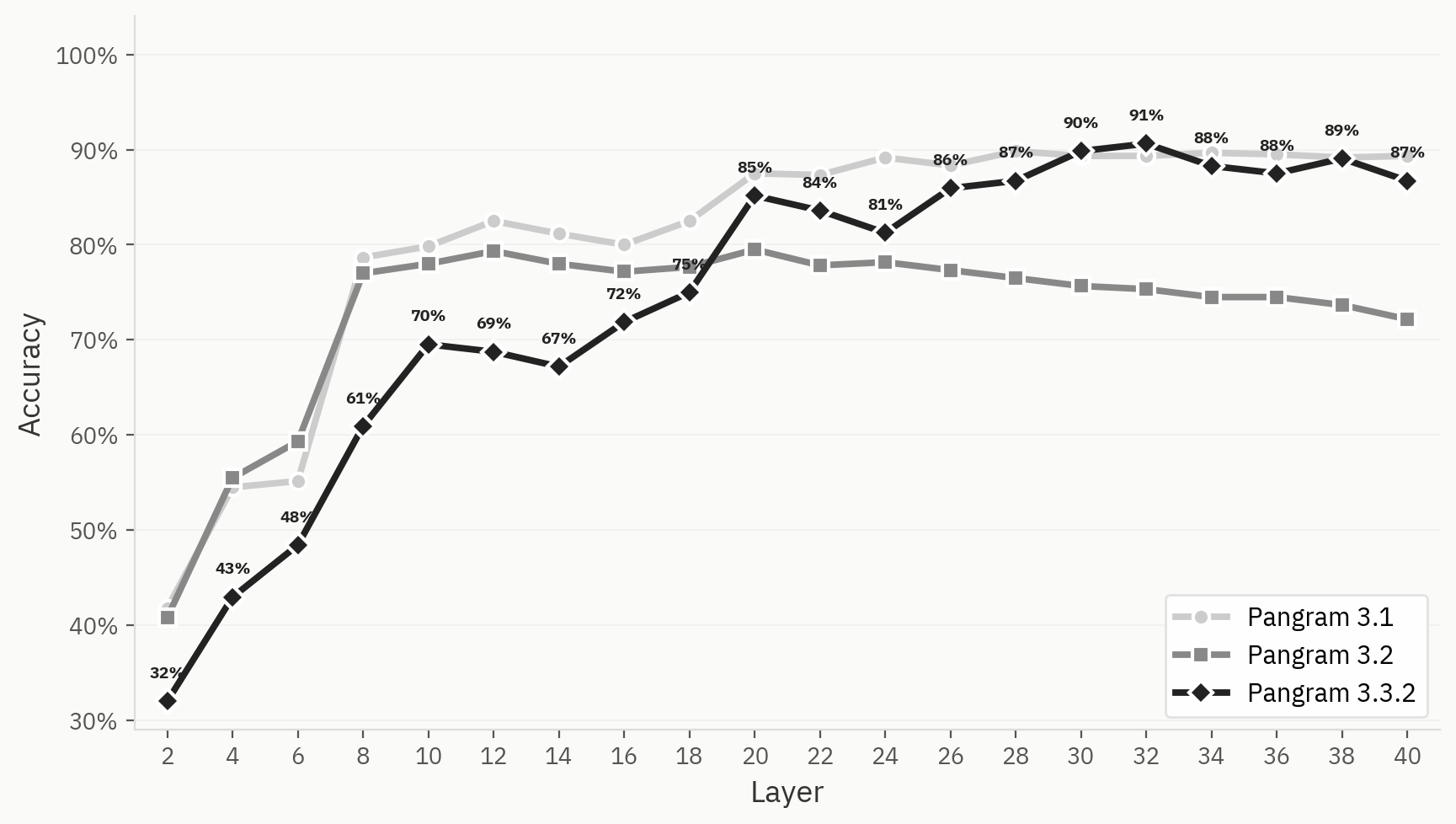
A figura abaixo compara o comportamento de agrupamento do Pangram 3.1, 3.2 e 3.3.2. Apesar de o modelo ter apresentado um desempenho superior ao do 3.1 na tarefa binária «humano-IA» nas nossas avaliações internas de validação, os agrupamentos do modelo são, em geral, menos definidos no Pangram 3.2 do que no Pangram 3.1 ou no 3.3.2.
Para ilustrar melhor esta diferença, comparamos o desempenho do classificador LLM nos Pangram 3.1, 3.2 e 3.3.2. Todos os três apresentam uma melhoria na precisão top-1 nas primeiras camadas, mas o desempenho do Pangram 3.2 começa a diminuir após a camada 12, enquanto o do Pangram 3.1 e do 3.3.2 se mantém elevado.
Humanizadores
Os «humanizadores» são uma classe de ferramentas adversárias concebidas para modificar texto gerado por IA de forma a contornar os detetores de IA. Para verificar a posição do texto humanizado em relação ao texto humano e ao texto gerado por IA no espaço de ativação, criámos um conjunto de dados separado de humanizadores, que consiste em cerca de 1 900 amostras, distribuídas de forma relativamente equilibrada por três modelos generativos (Claude Sonnet 4.5, Gemini 2.5 Pro e GPT-5), dez serviços de humanização diferentes e os mesmos domínios de origem que o conjunto de dados de interpretabilidade original. Devido aos riscos adversariais, não revelamos quais os serviços que utilizamos.
Como o modelo identifica os «humanizadores»
Algumas amostras do nosso conjunto de dados «humanizer» são, de facto, difíceis de detetar pelo nosso modelo. Neste caso, utilizamos a mesma sonda linear para a tarefa «humano/IA», mas com o texto humanizado rotulado como «IA», tal como fazemos na configuração de treino original. Verificamos que, mesmo a partir da primeira camada, o texto humanizado é consistentemente interpretado como mais humano do que a sua contraparte direta da IA.
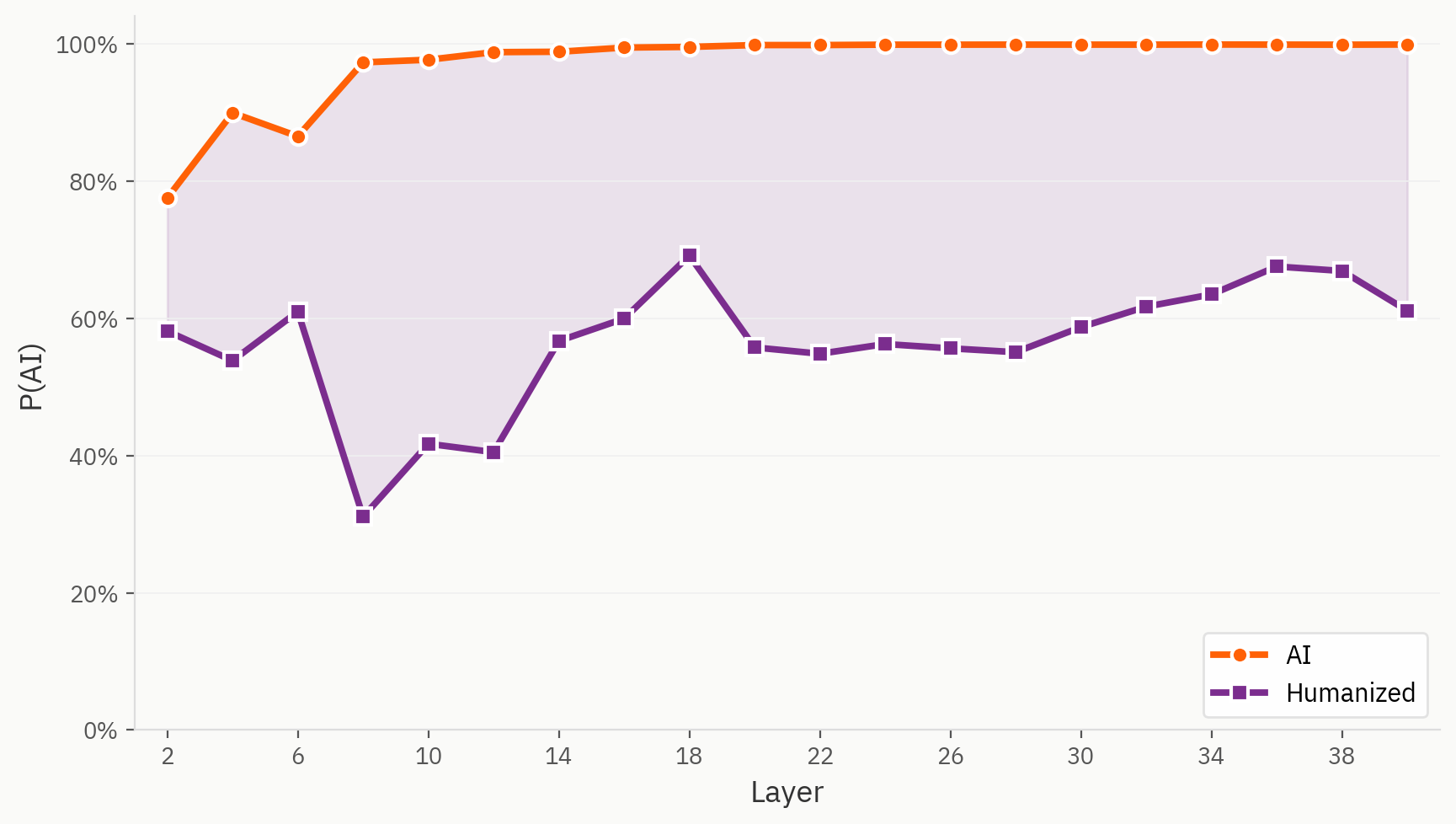
Onde se encontram os «humanizadores» no espaço de incorporação
No entanto, quando analisamos para além do resultado final, deparamo-nos com uma representação muito mais rica do texto humanizado. A seguir, aplicamos os nossos métodos de redução de dimensionalidade aos textos humanos, de IA e humanizados. Do ponto de vista qualitativo, podemos observar que os humanizadores tendem a ocupar partes distintas do espaço de ativação e a formar agrupamentos fora das regiões dos textos humanos e de IA.
A nossa hipótese é que, apesar de não dispor de rótulos para o texto humanizado, o modelo é capaz de distinguir entre texto humanizado, texto escrito por humanos e texto gerado por IA. No entanto, na avaliação final, o modelo é obrigado a ignorar esse sinal e fá-lo de forma inconsistente.
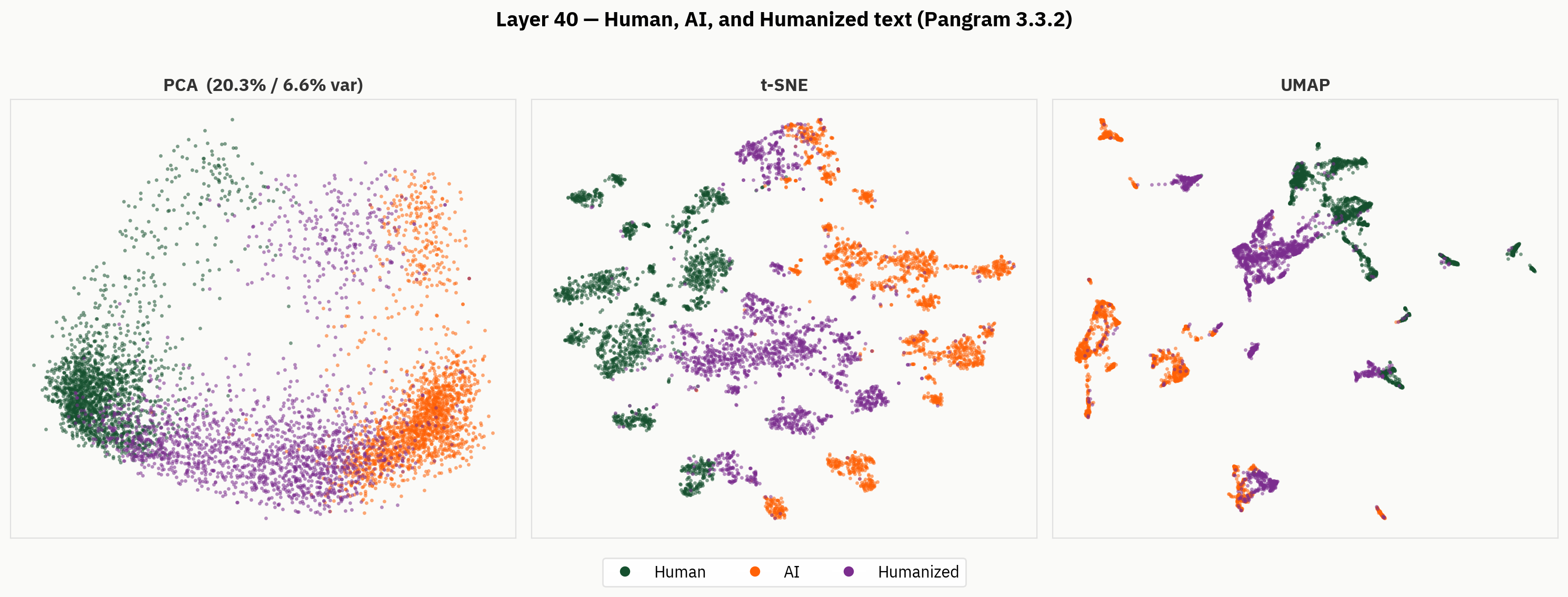
Sonda
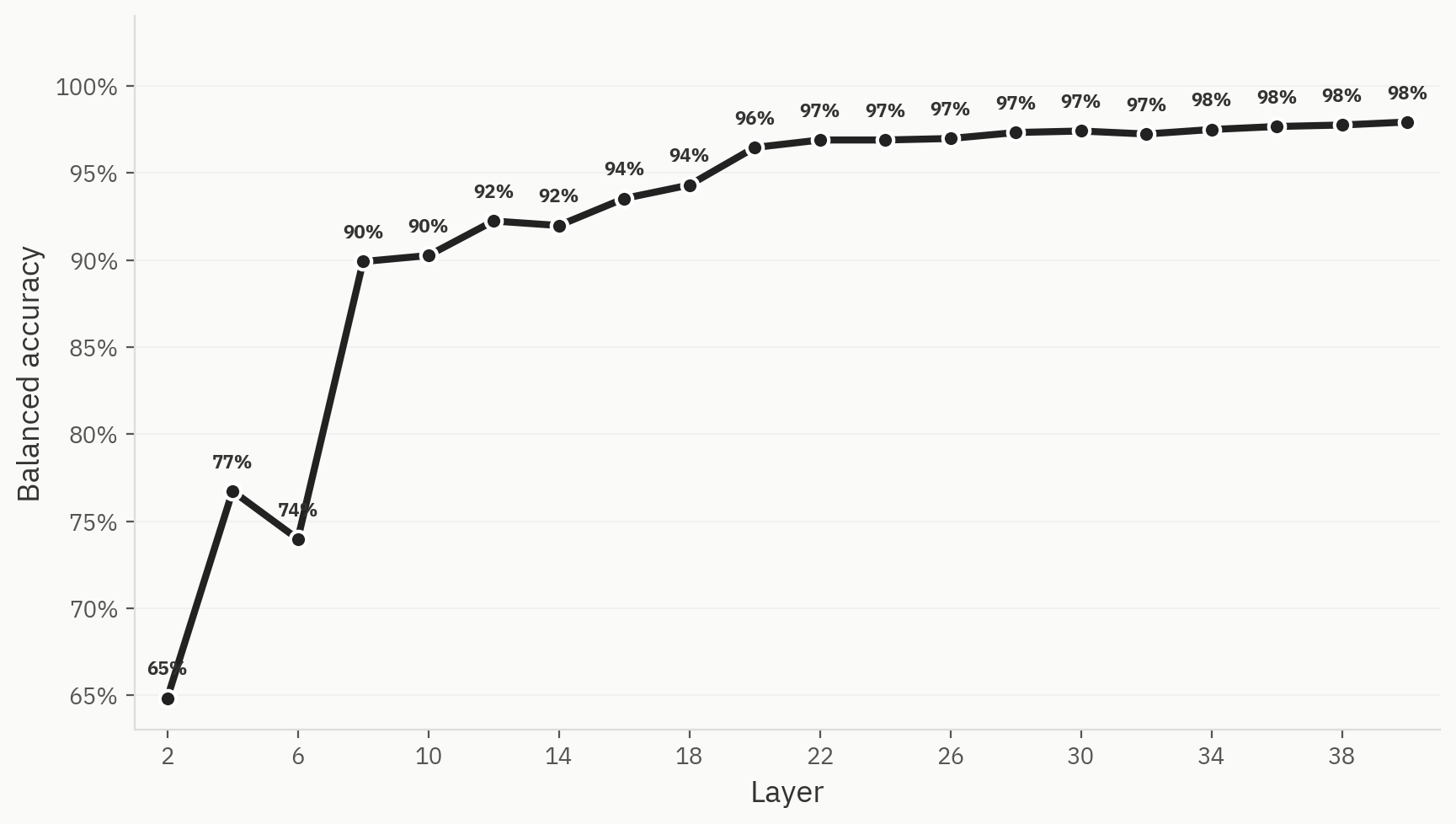
Para validar esta hipótese, treinámos um «probe» linear de três classes com rótulos para texto gerado por IA, texto humano e texto humanizado. O «probe» atinge uma elevada precisão top-1 logo nas primeiras camadas da rede e acaba por estabilizar nos 98%.
Conclusão
O nosso trabalho sugere que as representações internas do Pangram contêm mais estrutura do que aquela que a leitura binária final, por si só, revela. Ao longo das camadas, observamos que os documentos humanos e os da IA se separam, que surge informação sobre a família de modelos e que o texto humanizado ocupa a sua própria região no espaço de ativação. Estas conclusões são preliminares, mas proporcionam-nos um mapa útil para compreender o que o modelo aprende antes de sintetizar tudo numa única pontuação de deteção.
Esta publicação apresenta apenas os primeiros passos dos nossos esforços em matéria de interpretabilidade, mas, internamente, estamos entusiasmados e interessados nesta linha de investigação.
A nossa visão em relação à interpretabilidade e explicabilidade dos modelos Pangram é que estes possam:
- Proporcionar uma melhor compreensão interna do comportamento do modelo.
- Apresente provas de apoio e explicações mais claras para os resultados individuais do Pangram.
Se for um investigador interessado em interpretabilidade, na investigação sobre deteção de IA ou em qualquer outro aspeto deste trabalho, entre em contacto com elyas@pangram.com.
