Detecção por IA para equipas de ML e de dados
Detetor de IA para engenheiros de ML e cientistas de dados
Otimize o treino de LLM e a seleção de dados. Evite o colapso do modelo filtrando texto sintético dos seus conjuntos de dados de pré-treino ou de afinação, com uma precisão de 99,98% e um desempenho de API de alto rendimento.
Desenvolvido por investigadores da Google, da Tesla e da Universidade de Stanford. Validado pela ICLR e pela Universidade de Maryland.
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")
















Casos de utilização
Não treine os seus modelos
com dados de má qualidade.
O texto sintético está a contaminar os conjuntos de dados públicos. Filtre o conteúdo gerado por IA dos seus fluxos de treino com o motor de deteção de IA mais preciso para manter a pureza do corpus.
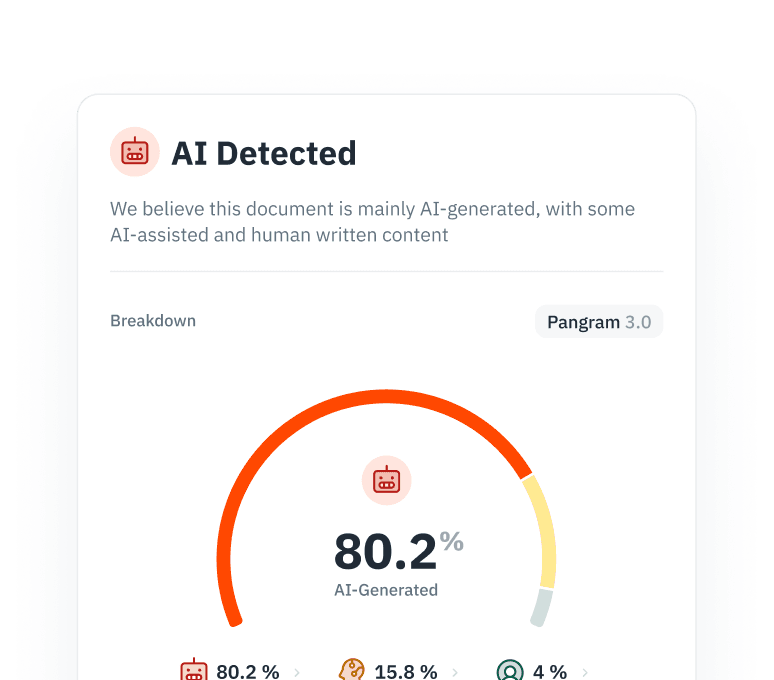
Evitar o colapso do modelo
O treino recursivo com conteúdo gerado por IA prejudica o desempenho e a diversidade do modelo. Identifique e filtre o conteúdo escrito por IA dos seus fluxos de extração de dados para garantir a pureza do corpus.
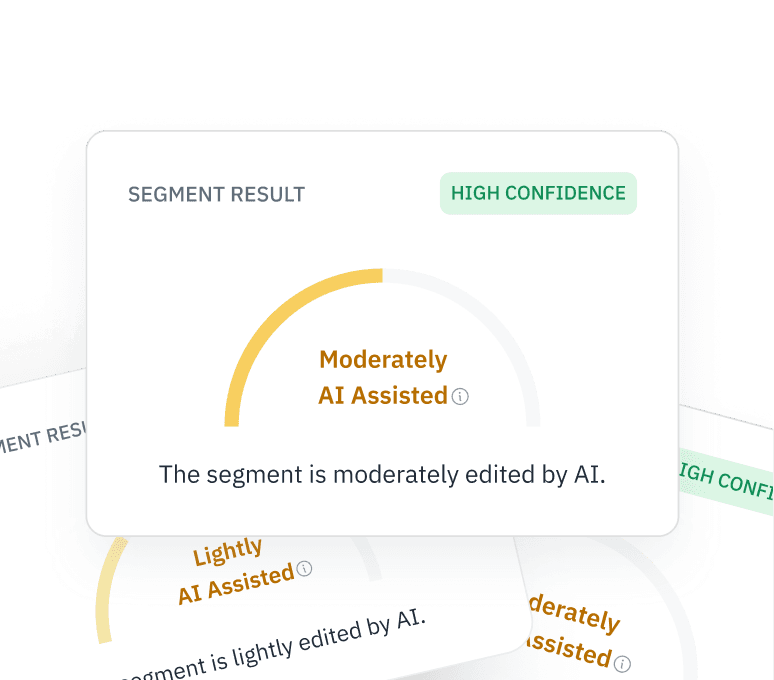
Verificar entradas do RLHF
Certifique-se de que os seus dados de feedback humano (RLHF) são realmente de origem humana. Verifique se os colaboradores da plataforma de crowdsourcing estão a utilizar o ChatGPT para gerar respostas nas suas tarefas de afinação.
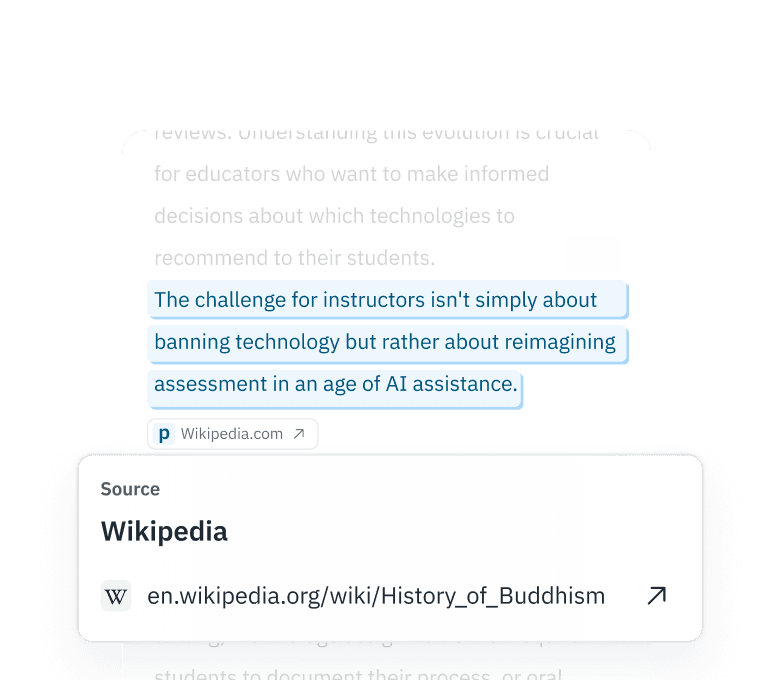
Interpretabilidade granular
Não se contente com uma classificação binária. A nossa API Premium apresenta probabilidades ao nível do token, permitindo-lhe manter os segmentos editados manualmente e descartar o «material de baixa qualidade» totalmente sintético.
Abordagem técnica
Um modelo em que pode confiar
Concebido para engenheiros que precisam de ter confiança na filtragem dos seus dados. O nosso modelo aborda os falsos positivos, a robustez face a ataques adversários e os resultados em constante evolução da IA.

Mineração de Negativos Rígidos
Treinar com «exemplos negativos definitivos» — textos escritos por humanos com um estilo formal ou repetitivo — para minimizar os falsos positivos e garantir que não descarta dados humanos valiosos.
Robustez adversária
A Pangram lida com conteúdos gerados por IA que foram parafraseados ou modificados. Os nossos modelos são treinados para lidar com «humanizadores» e ataques adversários, de modo a detetar texto sintético ofuscado.
Preparação para o futuro
Deteta texto proveniente dos modelos mais recentes, incluindo o GPT-5, o Claude 3.5 e o Llama 3, garantindo que os seus filtros se mantêm à frente do estado da arte atual.
Integração
Concebido para o seu pipeline de dados do

01
SDK do Python
Instale o pangram-sdk e integre a detecção nos seus pipelines do Airflow ou do Databricks com apenas algumas linhas de código. Otimizado para gestão de pools de ligações e tratamento de erros.
Ver documentos →
02
API de alta produtividade do
Processe conjuntos de dados de grande volume com baixa latência. A nossa infraestrutura suporta o processamento em lote e garante o rendimento, tratando milhões de pedidos para operações de scraping empresarial.
Obter chave API →
03
Segurança e conformidade com a norma
Totalmente certificados pela norma SOC 2 Tipo 2. Oferecemos terminais privados e políticas rigorosas de retenção de dados — nunca treinamos o nosso sistema com os seus dados proprietários.
Saiba mais →
Perguntas frequentes
Perguntas frequentes sobre a deteção por IA
Perguntas frequentes sobre a deteção de IA para engenheiros de ML
e cientistas de dados.
Sim. Pode instalar o pangram-sdk para integrar a deteção em pipelines do Airflow ou do Databricks com apenas algumas linhas de código. A nossa API está otimizada para operações de scraping empresariais de alto rendimento, suportando milhões de pedidos com baixa latência.
Descubra mais
Detecção de IA para
todas as organizações
Para programadores
Detecção de código gerado por IA para programadores e equipas de engenharia. Detete código gerado por IA a partir do ChatGPT, Copilot e Claude em Python, Java, C++ e outras linguagens.
Saiba mais →Para moderação de conteúdos
Moderação de conteúdos por IA para equipas de confiança e segurança. Detete avaliações geradas por IA, comentários falsos e conteúdos sintéticos em grande escala através da API.
Saiba mais →Para universidades
Detecção de IA para universidades e instituições de ensino superior. Verifique os trabalhos dos alunos, analise os trabalhos de investigação apresentados e proteja a reputação da instituição.
Saiba mais →Limpe os seus dados de treino hoje mesmo
Evite o colapso do modelo, verifique as entradas RLHF e filtre o conteúdo sintético dos seus conjuntos de dados com uma precisão de 99,98%.
para receber as nossas atualizações
