NOT: Adımızı Pangram Labs olarak değiştirdik! Daha fazla bilgi için blog yazımızı okuyun.
Checkfor.ai olarak, interneti düşük kaliteli, yapay zeka tarafından üretilen içerik kirliliğinden korumak misyonumuzu gerçekleştirmek için sektörün en iyi yapay zeka metin tespit aracı olmaya çalışıyoruz. Savunmamız gereken en önemli alanlardan biri de kullanıcı yorum platformlarıdır.
Sahte çevrimiçi yorumlar sonuçta hem işletmelere hem de tüketicilere zarar veriyor ve ChatGPT, yorum sahtekarlığının büyük ölçekte işlenmesini daha da kolaylaştırdı.
 Yelp'te ChatGPT tarafından oluşturulan yorum
Yelp'te ChatGPT tarafından oluşturulan yorum
Çevrimiçi yorumlara duyulan kullanıcı güvenini korumak, Checkfor.ai olarak çevrimiçi ortamda kullanıcılar tarafından oluşturulan içeriğin özgünlüğünü korumaya yönelik misyonumuzun önemli bir parçasıdır.
Hakkımda
Adım Bradley Emi ve Checkfor.ai’nin CTO’suyum. Stanford’da yapay zeka araştırmacısı olarak çalıştım, Tesla Autopilot ekibinde makine öğrenimi bilimcisi olarak üretim modelleri hayata geçirdim ve Absci’de büyük sinir ağları kullanarak ilaç tasarlamak için bir platform geliştiren araştırma ekibine liderlik ettim. Otonom araçlar ve ilaç keşfi alanlarında %99 doğruluk oranı kesinlikle yeterli değildir. %99 doğruluk oranı, her 100 yayadan 1'inin otonom bir araç tarafından ezilebileceği veya her 100 hastadan 1'inin kötü tasarlanmış bir ilacın hayatı tehdit eden yan etkilerine maruz kalabileceği anlamına gelebilir.
AI tarafından üretilen metinleri tespit etmek her ne kadar hayati bir mesele olmasa da, Checkfor.ai olarak aynı kalite standartlarına sahip modeller ve yazılım sistemleri tasarlamak istiyoruz. Algılayıcımız, yeniden ifade etme, gelişmiş komut satırı mühendisliği gibi saldırgan saldırılara ve undetectable.ai gibi algılama kaçırma araçlarına karşı dayanıklı olmalıdır. Bu sorunu çözme konusunda ciddiyiz (örneğin, sadece %99'a ulaşmakla yetinmiyoruz) ve bu nedenle mühendislik ekibimizin en önemli önceliklerinden biri, son derece sağlam bir değerlendirme platformu geliştirmektir.
Değerlendirme Felsefesi: Test Setleri Birim Testleridir
Bir Yazılım 1.0 siber güvenlik şirketi, birim testleri yapılmadan asla bir ürünü piyasaya sürmez. Bir Yazılım 2.0 şirketi olarak, birim testlerinin eşdeğerine ihtiyacımız var; ancak bu testlerin, milyonlarca hatta milyarlarca parametreye sahip, stokastik davranışlar sergileyebilen ve uç durumların geniş bir dağılımını kapsarken doğru şekilde çalışması gereken büyük modelleri test etmesi gerekiyor. "Test setinde %99 doğruluk" elde edip işi bitiremeyiz: gerçek dünyada karşılaşacağımız örnek türlerini özel olarak test eden değerlendirmelere ihtiyacımız var.
İyi bir test seti, belirli soruları yanıtlar ve karıştırıcı değişkenlerin sayısını en aza indirir.
Hedef odaklı test soruları ve bunlara karşılık gelen test setlerine örnekler şunlardır:
- Modelimiz Yelp yorumlarında ne kadar başarılı? Bin adet gerçek Yelp yorumu ve bin adet yapay zeka tarafından üretilmiş Yelp yorumundan oluşan test kümesi.
- Modelimiz, yeniden ifade edilmiş metinlerde ne kadar başarılı? Yüzlerce gerçek öğrenci kompozisyonu, yüzlerce yapay zeka kompozisyonu ve QuillBot ya da Undetectable.AI aracılığıyla yeniden ifade edilmiş tam olarak aynı kompozisyonlardan oluşan test kümesi.
Test kümenizde bulunan her şeyi öylece bir araya getirip tek bir rakam olarak sunamamanızın birkaç nedeni vardır.
- Karıştırıcı değişkenler çok fazla — testin başarılı olup olmadığını veri dağılımından mı yoksa modelden mi kaynaklandığını bilmiyoruz.
- Herkes, test kümesini kolay örneklerle doldurarak doğruluk oranını yapay olarak şişirebilir.
- Test kümesinin tarafsız bir şekilde nasıl oluşturulduğuna dair açık ve tekrarlanabilir bir açıklama olmadan, birisinin modelinin başarılı olduğu ve temel modelin başarısız olduğu örnekleri özenle seçip seçmediğini bilemeyiz.
İşte bu yüzden bu tür karşılaştırmalı çalışmalar tamamen isabetten uzak kalıyor. Odaklanmamışlar ve modelin sergilemesini istediğimiz belirli davranışları test etmiyorlar. Önyargılı test kümeleri, modelin gerçek dünyadaki örneklerle karşılaştığı anlarda değil, en iyi performansını sergilediği anlarda onu öne çıkarıyor.
Tarafsız bir Yelp karşılaştırması
Yapay zeka ile metin tespitinin gerçek hayattaki bir uygulama örneği, Yelp'te yapay zeka tarafından üretilen yorumları tespit etmektir. Yelp, yorum platformunu sıkı bir şekilde denetlemeye büyük önem vermektedir. 2022 tarihli Güven ve Güvenlik Raporu'na göz attığınızda, Yelp'in sahte, ücretli, teşvik edilmiş veya başka şekillerde dürüst olmayan yorumlarla mücadeleye ne kadar önem verdiğinin açıkça görüldüğü anlaşılmaktadır.
Neyse ki Yelp de mükemmel bir açık kaynak veri seti yayınladı. Bu veri setinden rastgele 1000 yorum seçtik ve en yaygın kullanılan büyük dil modeli (LLM) olan ChatGPT'den 1000 yapay yorum ürettik.
ChatGPT yorumlarının, Kaggle veri setindeki gerçek Yelp işletmelerine ait olduğunu belirtmek önemlidir: bu sayede model, işletmelerin dağılımındaki farklılıklar gibi ayrıntılara aşırı uyum sağlayarak hile yapamaz. Değerlendirme sırasında, modelin gerçek ile sahteyi ayırt etmek için metindeki doğru özellikleri kullanmayı gerçekten öğrenip öğrenmediğini test ediyoruz.
Bu veri setini, hangi yapay zeka algılama modellerinin ChatGPT tarafından oluşturulan yorumları gerçek yorumlardan gerçekten ayırt edebildiğini belirlemek için kullanıyoruz!
Model doğrulukları
En basit ölçütümüz doğruluktur: Her model kaç örneği doğru bir şekilde sınıflandırdı?
- Checkfor.ai: %99,85 (1997/2000)
- Originality.AI: %96,2 (1738/1806) (not: Originality.AI, 50 kelimeden kısa belgeleri sınıflandırmamaktadır).
- GPTZero: %90,8 (1815/2000)
%99,85 ile %96 arasındaki fark ilk bakışta çok büyük görünmeyebilir, ancak hata oranını göz önünde bulundurduğumuzda bu rakamları daha net bir şekilde değerlendirebiliriz.
Checkfor.ai'nin her 666 sorguda bir, Originality.AI'nin ise her 26 sorguda bir hata vermesi beklenirken, GPTZero her 11 sorguda bir hata veriyor. Bu, hata oranımızın Originality.AI'den 25 kat, GPTZero'dan ise 60 kat daha iyi olduğu anlamına geliyor.
Yanlış pozitifler ve yanlış negatifler
Yanlış pozitif ve yanlış negatif sonuçları incelemek için (makine öğrenimi terminolojisinde buna çok benzer olan “hassasiyet” ve “geri çağırma” istatistiklerini ele alırız), karışıklık matrisine bakabiliriz – doğru pozitif, yanlış pozitif, doğru negatif ve yanlış negatif sonuçların göreceli oranları nedir?

Over all 2,000 examples, Checkfor.ai produces 0 false positives and 3 false negatives, exhibiting high precision and high recall. While admirably, GPTZero does not often predict false positives, with only 2 false positives, it comes at the expense of predicting 183 false negatives– an incredibly high false negative rate! We’d call this a model that exhibits high precision but low recall. Finally, Originality.AI predicts 60 false positives and 8 false negatives– and it refuses to predict a likelihood on short reviews (<50 words) — which are the hardest cases and most likely to be false positives. This high false positive rate means that this model is low precision, high recall.
AI metin algılamasında düşük bir yanlış pozitif oranı daha önemli olsa da (gerçek insanların ChatGPT'den intihal yaptığını yanlışlıkla suçlamak istemeyiz), düşük bir yanlış negatif oranı da gereklidir – AI tarafından üretilen içeriğin %10–20'sinden fazlasının gözden kaçmasına izin veremeyiz.
Model Güveni
Sonuç olarak, metnin insan tarafından yazıldığı ya da ChatGPT tarafından yazıldığı açıkça belli olduğunda, modelimizin yüksek bir güven derecesi göstermesini istiyoruz.
Mitchell ve arkadaşlarının hazırladığı mükemmel akademik makale DetectGPT’de izlenen görselleştirme stratejisine benzer bir yaklaşım izleyerek, üç modelin her biri için hem yapay zeka tarafından üretilen yorumların hem de gerçek yorumların model tahminlerine ait histogramları çiziyoruz. Üç modelin de doğruluk oranı %90’un üzerinde olduğundan, her bir modelin güven aralığının özelliklerini görselleştirmek için y ekseninde logaritmik ölçek kullanmak en yararlı yöntemdir.

Bu grafikte x ekseni, modelin girdi olarak verilen yorumu yapay zeka tarafından üretilmiş olarak tahmin etme olasılığını temsil etmektedir. Y ekseni ise modelin bu olasılığı gerçek metinler (mavi çubuklar) veya yapay zeka metinleri (kırmızı çubuklar) için ne sıklıkla tahmin ettiğini göstermektedir. Bu "yumuşak" tahminlere baktığımızda, Checkfor.ai'nin sadece evet veya hayır demek yerine, GPTZero veya Originality.AI'dan çok daha iyi bir şekilde net bir karar sınırı çizdiğini ve daha güvenilir tahminlerde bulunduğunu görüyoruz.
GPTZero, olasılık aralığı 0,4–0,6 arasında çok fazla örnek tahmin etme eğilimindedir ve en sık görülen değer tam olarak 0,5 civarındadır. Öte yandan, Originality.AI’nın yanlış pozitif sorunu, düşük olasılıklı tahminler incelendiğinde daha da belirgin hale gelmektedir. Birçok gerçek yorum, 0,5 eşiğini geçmese bile, AI tarafından üretilmiş olarak tahmin edilmeye çok yakındır. Bu durum, kullanıcının modelin AI tarafından üretilmiş metni güvenilir bir şekilde tahmin edebileceğine güvenmesini zorlaştırır; çünkü yorumdaki küçük değişiklikler, bir saldırganın yorumu tespit eşiğinin altına düşene kadar tekrar tekrar düzenleyerek dedektörü atlatmasına olanak tanıyabilir.
Buna karşılık, modelimiz genellikle oldukça kararlıdır. Genellikle kendinden emin kararlar verebiliyoruz. Derin öğrenme veya bilgi teorisi konusunda bilgi sahibi okuyucularımız için belirtmek gerekirse, gerçek dağılım ile tahmin edilen dağılım arasında en düşük çapraz entropi/KL-diverjans değerine sahibiz.
Gerçek metinleri yüksek bir güven derecesiyle gerçek olarak tahmin etmenin bariz bir değeri vardır ( Twitter'dan alınan bu esprili şekle bakınız). Bu eğitimci, yapay zeka olasılığını açıkça yapay zeka tarafından yazılmış metin miktarı olarak yanlış yorumlamış olsa da, algılayıcılar gerçek metinlerin gerçekten gerçek olup olmadığı konusunda emin olmadıklarında, bu durum yanlış yorumlara yol açabilir.
 https://twitter.com/rustykitty_/status/1709316764868153537
https://twitter.com/rustykitty_/status/1709316764868153537
Checkfor.ai tarafından tespit edilen 3 hatadan ne yazık ki ikisi oldukça yüksek güvenilirlik derecesine sahip. Algılayıcımız kusursuz değil ve bu tür yüksek güvenilirlikli yanlış tahminleri önlemek için modeli kalibre etmeye aktif olarak çalışıyoruz.
Sonuç
Gerçek ve sahte Yelp yorumlarının değerlendirilmesinde kullanılan veri kümelerini açık kaynak olarak paylaşıyoruz; böylece gelecekteki modeller, algılayıcılarının doğruluğunu test etmek için bu önemli karşılaştırma ölçütünü kullanabilecekler.
Önemli noktalarımız şunlardır:
Checkfor.ai, hem düşük yanlış pozitif hem de düşük yanlış negatif oranına sahiptir. Checkfor.ai, gerçek yorumlarla yapay zeka tarafından üretilen yorumları sadece yüksek doğrulukla değil, aynı zamanda yüksek bir güven derecesiyle de ayırt edebilmektedir. Gelecekte bu tarzda daha fazla blog yazısı yayınlayacağız ve daha fazla bilgi edindikçe modelimizle ilgili dürüst değerlendirmelerimizi kamuoyuyla paylaşacağız. Bizi takip etmeye devam edin ve görüşlerinizi bizimle paylaşın!

Bradley, bir yapay zeka araştırmacısı ve endüstride derin öğrenme ürünleri geliştirme konusunda uzman bir isimdir. Son olarak, üretken yapay zeka ile ilaç keşfi yapan Absci şirketinde derin öğrenme araştırma grubuna liderlik etmiş ve daha önce Tesla Autopilot’un temel bilgisayar görme ekibinin bir üyesi olarak görev yapmıştır.
Bradley, yüksek lisans öğrencisiyken Stanford Vision Lab bünyesinde derin öğrenme alanında birçok makale kaleme almıştır. Stanford Üniversitesi’nden fizik lisans ve yapay zeka yüksek lisans derecelerine sahiptir. Yapay zekanın yanı sıra eğitim ve felsefe konularına da ilgi duymakta olup, aynı zamanda tutkulu bir golfçüdür.
İlgili makaleler

Pangram, GPTZero ile karşılaştırıldığında nasıl bir performans sergiliyor?
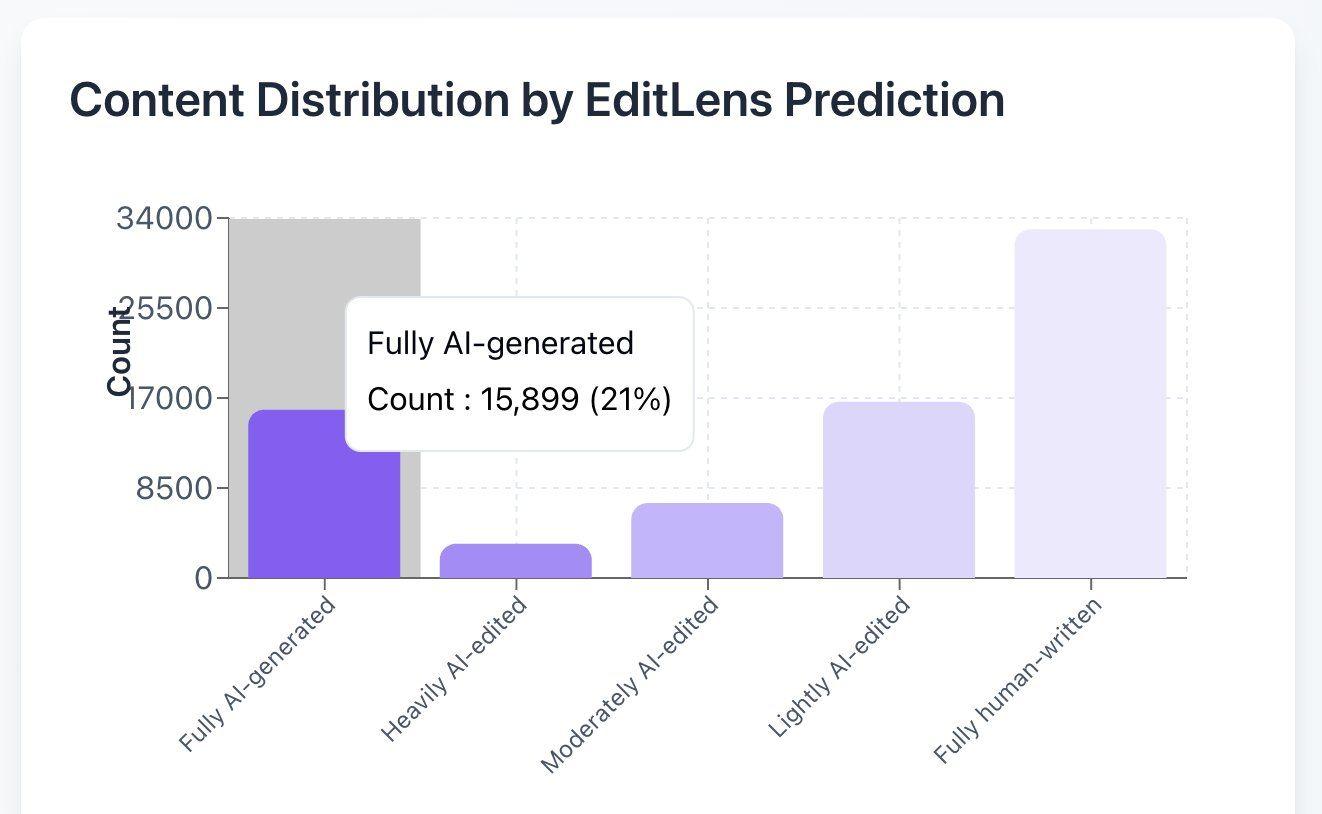
Pangram, ICLR makalelerinin %21’inin yapay zeka tarafından yazıldığını öngörüyor

Yapay zeka tarafından yazılmış yorumları nasıl ayırt edersiniz?

Üçüncü Taraf Pangram Değerlendirmeleri

İşletmenizi LLM ve GenAI'ye Uygun Hale Getirmek

Yapay zeka, ödüllü kurgu eserleri yazıyor
adresinden güncellemelerimize abone olun
