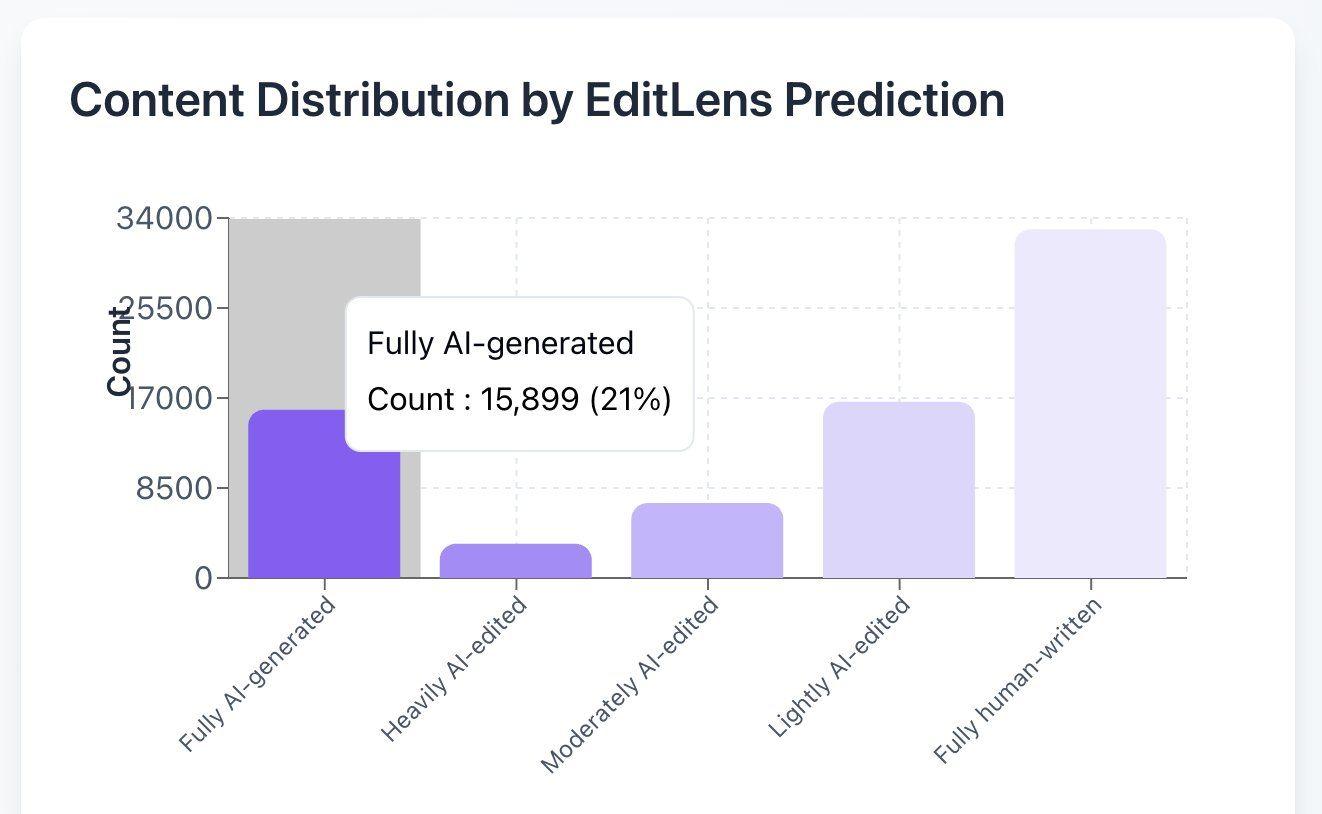
一张图表展示了按年份统计的提交至ICLR的人工智能生成的摘要所占比例,显示自2023年以来呈上升趋势。
一张图表展示了按年份统计的提交至ICLR的人工智能生成的摘要所占比例,显示自2023年以来呈上升趋势。
2024年2月,《细胞与发育生物学前沿》上发表的一篇文章中出现了明显由人工智能生成的图表。这篇文章之所以成为头条新闻,是因为其中一张图片展示了一只睾丸异常巨大的老鼠,配文更是毫无意义的乱码。
这是一篇发表在《细胞与发育生物学前沿》上的真实论文。图中的插图显然是由人工智能生成的。其中一幅插图描绘了一只睾丸异常巨大的大鼠。插图中的文字完全是胡言乱语。pic.twitter.com/4Acn2YZYwM
— 克里夫·斯旺 (@cliff_swan) 2024年2月15日
虽然同行评审(理论上)应该足以发现此类显而易见的案例,但如果论文的实际内容是由人工智能生成的呢?即便是专家,也很难区分人工智能生成的研究与人类撰写的研究。
《自然》杂志最近的一篇新闻报道突显了人们对学术论文中人工智能生成内容的日益担忧。该文章讨论了一项研究:计算机科学家利用最新的大语言模型(LLM)之一——Claude 3.5——来生成研究思路并撰写论文,随后将这些论文提交给科学评审员。评审员们随后根据“新颖性、吸引力、可行性和预期有效性”对这些论文进行了评分。结果发现,评审员给人工智能生成的论文打的分数平均高于人类撰写的论文! 这引发了一个问题:AI 产生的研究思路真的比人类更好吗?虽然人们很容易相信情况确实如此,但在研究人员研究的 4,000 篇 AI 生成的论文中,只有 200 篇(5%)真正包含任何原创想法:大多数论文只是在重复大语言模型训练集中已有的想法。
归根结底,人工智能生成的研究会在同行评审过程中增加噪音、削弱有效信息,从而损害学术界,更不用说浪费了那些致力于维护研究标准的评审人员的时间和精力。 更糟糕的是,AI生成的研究往往看似令人信服,但实际上,语言模型生成的文本虽然读起来流畅,却可能充斥着错误、幻觉和逻辑矛盾。令人担忧的是,即便是专家评审员,也常常无法分辨自己所读的内容是否属于大语言模型(LLM)的幻觉。
各大机器学习会议的组织者与我们的观点一致:在科学写作中,不应出现由大型语言模型生成的文本。ICML(国际机器学习会议)的官方政策如下:
关于大型语言模型政策的说明
我们(程序委员会主席)已在2023年ICML的征文通知中加入了以下声明:
禁止在论文中使用由大型语言模型(LLM)(如ChatGPT)生成的文本,除非该文本作为论文实验分析的一部分呈现。
这一声明引发了潜在作者的诸多疑问,并促使部分作者主动与我们联系。我们感谢大家的反馈和意见,并希望进一步阐明该声明的初衷,以及我们计划如何在ICML 2023中落实这一政策。
简而言之;
ICML 2023 的大型语言模型(LLM)政策禁止完全由大型语言模型生成的文本(即“生成”的文本)。但这并不禁止作者使用大型语言模型对自行撰写的文本进行编辑或润色。 该政策主要基于审慎原则,旨在防范使用大型语言模型可能引发的问题,包括剽窃。
尽管有此警告,我们发现机器学习领域中违反该政策、在论文中使用人工智能生成文本的作者数量依然相当可观,且呈上升趋势。
评估问题的严重程度
在 Pangram,我们希望衡量这一问题在我们所在领域——人工智能——中的影响范围。我们着手回答这样一个问题:人工智能研究人员是否在使用 ChatGPT 来撰写自己的研究论文?
为了研究这一问题,我们利用 OpenReview API 提取了 2018 年至 2024 年间两大顶级人工智能会议——ICLR和NeurIPS——的会议投稿数据。
随后,我们对提交至这些会议的所有摘要运行了Pangram的AI检测器。以下是我们的发现:
ICLR
一张图表展示了按年份统计的提交至ICLR的人工智能生成的摘要所占比例,显示自2023年以来呈上升趋势。
NeurIPS
 一张图表展示了按年份提交至Neurips的人工智能生成的摘要所占比例,显示自2023年以来呈上升趋势。
一张图表展示了按年份提交至Neurips的人工智能生成的摘要所占比例,显示自2023年以来呈上升趋势。
结果
我们可以将2022年之前的所有数据视为验证集,用于验证我们模型的假阳性率,因为当时还未出现大型语言模型。 如图所示,我们的模型将2022年及之前的每一篇会议摘要都判定为人类撰写。这应能增强我们对模型准确性的信心:在科学摘要方面,我们的假阳性率表现优异,因此对于2023年和2024年做出的每一条阳性预测,我们都可以确信其为真阳性。
此后我们所见的情况令人深感担忧。自2022年11月ChatGPT发布以来,已经历了三个会议周期。
第一轮提交恰逢ChatGPT发布之际(ICLR 2023)。 虽然投稿截止日期实际上早于ChatGPT的发布,但作者在会议召开前仍有机会进行修改,而会议是在ChatGPT发布数月后才举行的。我们的发现符合预期:仅有极少数摘要由AI撰写(在本轮中,我们在数千份摘要中仅发现2份由AI撰写),且这些摘要很可能是在截止日期之后经过修改的。
第二轮会议大约在6个月后举行,即NeuRIPS 2023,该会议的投稿截止日期为2023年夏季,会议定于12月举行。在此次会议上,我们报告称,提交的摘要中约有1.3%是由人工智能生成的:这一比例虽小,但具有统计学意义。
最后,在最近一届的ICLR 2024会议上(该会议仅在数月前举行),我们注意到这一比例已升至4.9%:与NeuRIPS 2023相比,AI生成的评论数量增长了近4倍!
这些结果揭示了一个令人担忧的趋势:不仅提交至主要人工智能会议的人工智能生成论文数量在增加,而且增长速度也在加快:换言之,人工智能生成论文的提交速度正在加快。
由人工智能生成的摘要是什么样子的?
请看以下这些摘要,亲自判断它们是否像您在技术科学文献中习惯阅读的那种文风:
-
在错综复杂的网络化数据环境中,理解干预措施的因果效应是一项关键挑战,其影响遍及多个领域。图神经网络(GNNs)已成为捕捉复杂依赖关系的有力工具,但几何深度学习在基于 GNN 的网络因果推断中的潜力尚未得到充分探索。本研究为弥合这一差距做出了三项关键贡献。 首先,我们建立了图曲率与因果推断之间的理论联系,揭示了负曲率会给识别因果效应带来挑战。其次,基于这一理论洞见,我们利用里奇曲率预测因果效应估计的可靠性,并通过实证结果表明,正曲率区域能产生更准确的估计。 最后,我们提出一种利用里奇流的方法来改进网络数据上的处理效应估计,通过拉平网络中的边来降低误差,从而展现出优异的性能。我们的研究成果为在因果效应估计中运用几何学开辟了新途径,并提供了能够提升图神经网络在因果推断任务中性能的见解与工具。
-
在语言模型领域,数据编码至关重要,它直接影响模型训练的效率和效果。字节对编码(BPE)是一种成熟的子词分词技术,通过合并高频字节或字符对,在计算效率与语言表达能力之间实现了平衡。 鉴于语言模型训练需要大量的计算资源,我们提出了一种名为“融合令牌”(Fusion Token)的方法,该方法在语言模型的数据编码方面,对传统的字节对编码(BPE)方法进行了显著增强。 与BPE相比,Fusion Token采用了更激进的计算策略,将分词单元从二元组扩展至十元组。值得注意的是,在词汇表中仅增加1024个词汇的情况下,其压缩率便显著超越了词汇表规模为一百万的常规BPE分词器。 总体而言,由于每计算单元处理的数据范围扩大,Fusion Token方法带来了显著的性能提升。此外,更高的压缩率意味着每条给定字符串的令牌数量减少,从而缩短了推理时间。通过在令牌化器构建过程中投入更多计算资源,Fusion Token最大限度地发挥了语言模型作为高效数据压缩引擎的潜力,从而构建出更高效的语言建模系统。
-
在快速发展的动作生成领域,增强文本语义已被公认为一种极具前景的策略,可用于生成更准确、更逼真的动作。 然而,现有技术往往依赖于大型语言模型来优化文本描述,却无法保证文本与动作数据之间的精确对齐。这种错位常导致动作生成效果欠佳,从而限制了这些方法的潜力。为解决这一问题,我们提出了一个名为SemanticBoost的创新框架,旨在弥合文本与动作数据之间的鸿沟。 我们的创新方案整合了源自运动数据本身的补充语义信息,并结合专用的去噪网络,从而确保语义连贯性并提升运动生成的整体质量。通过广泛的实验与评估,我们证明SemanticBoost在运动质量、对齐精度和逼真度方面显著优于现有方法。此外,我们的研究成果突显了利用运动数据中语义线索的潜力,为更直观、多样化的运动生成开辟了新途径。
发现什么规律了吗?首先,我们可以看到它们都以非常相似的短语开头:“在……这一复杂的领域中”、“在……这一领域中”、“在……这一快速发展的领域中”。我们称这种表达为“刻意华丽的语言”。 我们此前曾探讨过,大型语言模型(LLMs)经常使用大量词汇却产出极少实质内容。虽然这对试图达到作业最低字数要求的学生来说或许是件好事,但对于试图阅读研究论文的技术读者而言,这种过于冗长的语言不仅让论文更难读、更费时,反而使论文的实际信息变得更加模糊不清。
人工智能领域的论文真的能被会议录用吗?
我们想知道,由人工智能生成的论文是否真的能被同行评审过程有效筛除,还是其中有些会漏网。
为解答这一问题,我们分析了ICLR 2024会议中AI生成的摘要与论文录用结果之间的关联。(口头报告、亮点报告和海报展示均属于“录用”论文;其中口头报告和亮点报告是特别表彰类别。)我们的研究结果如下:
| 类别 | AI生成百分比 |
|---|---|
| ICLR 2024 口头报告 | 2.33% |
| ICLR 2024 海报 | 2.71% |
| ICLR 2024 焦点 | 1.36% |
| 被拒绝 | 5.42% |
尽管被录用的AI生成论文所占比例低于提交比例,但仍有相当数量的论文通过了同行评审。这表明,虽然评审员可能发现了一些AI生成的内容,但并未全部发现。
我们注意到,甚至有些口头报告和重点论文的摘要也是由人工智能生成的!如果善意地解读这一现象,我们可能会发现,这些研究实际上质量很高,而作者只是借助ChatGPT走了一条捷径,以便更好地展示或修改他们的研究成果。
值得注意的是,鉴于研究界中许多人的母语并非英语,大型语言模型(LLMs)将越来越多地被用于将其他语言撰写的论文翻译成英语。
结论
尽管人工智能界已明确要求作者不要使用ChatGPT,但许多作者仍无视这一规定,继续利用大型语言模型(LLM)协助撰写论文。更令人担忧的是,就连那些本应作为同行评审员、负责防范大型语言模型生成论文的AI专家,也未能察觉其中端倪!
ChatGPT正在学术流程中引发更广泛的连锁反应。一项最新的ICML案例研究发现,6%至16%的同行评审报告本身是由人工智能生成的,而且人工智能生成的同行评审报告与评审提交时间距离截止日期有多近之间存在正相关关系!
我们呼吁人工智能界更好地落实这些政策,并呼吁作者承担起责任,确保其论文由人类撰写。
人工智能在正式写作领域的渗透不仅限于研究领域——它还屡获小说奖项。

布拉德利是一位人工智能研究员,也是工业领域深度学习产品开发的专家。他最近曾领导生成式人工智能药物发现公司Absci的深度学习研究团队,此前曾是特斯拉Autopilot核心计算机视觉团队的成员。
在攻读研究生期间,布拉德利曾与斯坦福视觉实验室合作,在深度学习研究领域发表了多篇论文。他拥有斯坦福大学物理学学士学位和人工智能硕士学位。除了人工智能,他还对教育和哲学充满热情,并且是一名狂热的高尔夫球手。