一款真正管用的AI检测工具。
以99.98%的准确率检测AI生成的内容。深受全球大学、学校及企业的信赖。

经包括马里兰大学和芝加哥大学在内的第三方研究人员验证,该AI检测工具是市场上最可靠、最准确的。
等全球知名品牌信赖


















AI生成的文本包含结构、风格和语义上的特定模式,这些模式都能被训练有素的眼睛或功能足够强大的检测软件识别出来。AI检测并非魔法,它确实是行之有效的。
Pangram 的人工智能检测器利用自然语言处理技术,并结合庞大的人类与人工智能写作数据集,对 ChatGPT、Gemini、Grok、Llama 和 Claude 等流行模型生成的文本中的模式进行分析。
Pangram 的检测准确率处于行业领先地位,并已获得芝加哥大学和马里兰大学研究人员的验证。
在人工智能生成内容在学术界、媒体和商业领域日益普及的时代,区分人类和机器撰写的文本的能力至关重要。在教育领域,这有助于建立师生之间的信任;在新闻业中,这同样至关重要,因为新闻诚信是该行业的核心。人工智能生成的文本本身并非坏事。然而,如果社会能够区分人工智能生成的文本和人类撰写的文本,将从中受益。
我们的产品
检测AI生成的内容
及剽窃
Pangram 融合了尖端的人工智能技术与全面的抄袭检测功能,助您全面掌握文本真实性,一站式获取所需信息。
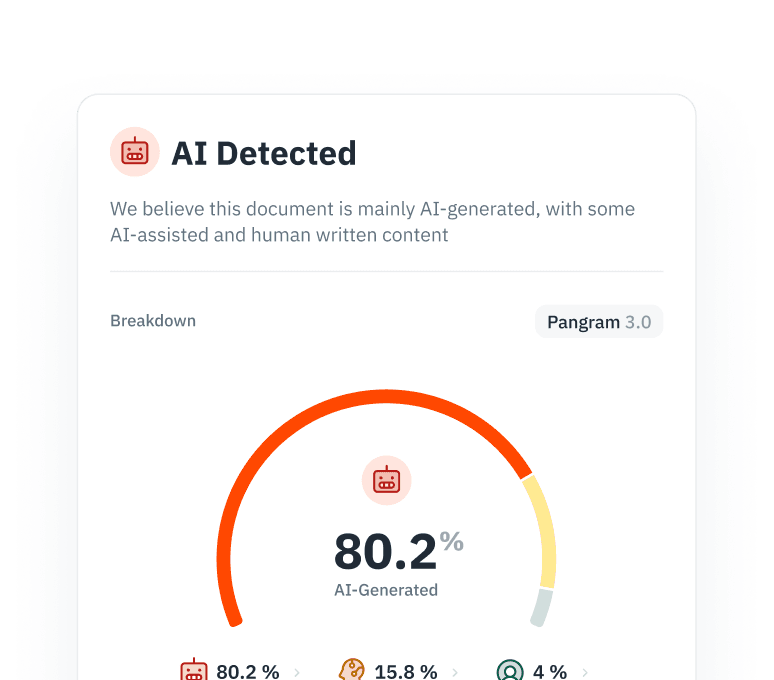
AI细分市场分析
Pangram 不仅会告诉你它有多确信该文档是由 AI 生成的,还会告诉你其中有多少比例是由 AI 生成的。
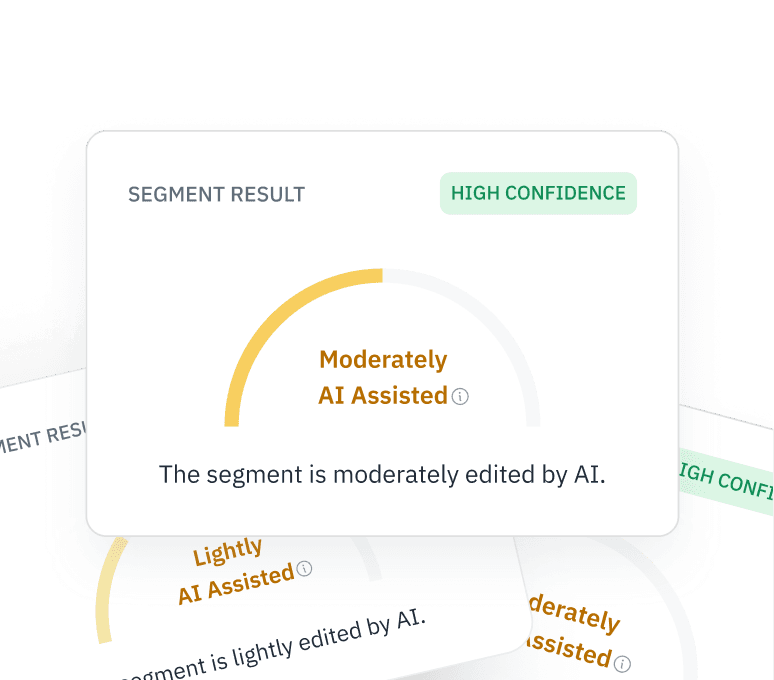
AI 辅助
Pangram 将特别标注那些由人工智能编辑而非完全由人工智能生成的内容。
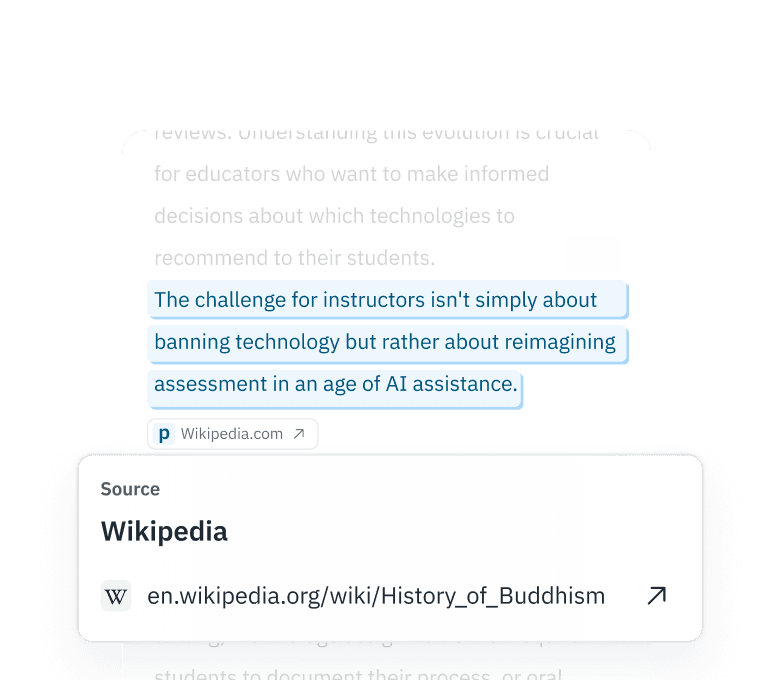
抄袭检测工具
一键检测剽窃和AI生成内容。只需点击一下,即可进行AI剽窃检测。

功能
的“全字母句”有何不同?
市面上有许多AI检测工具,但Pangram与众不同。它确实有效。我们还提供基于同行评审研究的高级功能,帮助用户了解文章的来源。

多年的研究
采用经过多年研发的专有技术,而非开源模型或贴牌的商用大型语言模型。
在多种数据集上进行过训练
Pangram 依托多样化的数据集、硬负样本挖掘和主动学习,实现了业界领先的假阳性率(FPR),而非依赖在实际应用中往往难以奏效的困惑度和突发性指标。
检测所有大型语言模型
Pangram 能够检测包括 ChatGPT、Claude、Gemini、Llama 等在内的所有主流语言模型生成的内容,因此成为一套全面的人工智能检测解决方案。
支持20多种语言
我们的AI检测功能支持20多种语言,是面向全球机构和企业的真正全球化、多语言解决方案。
表现优于受过训练的人类
独立研究表明,Pangram的人工智能检测在识别人工智能生成的内容方面,表现优于经过培训的人类读者。
检测自然语言文本
即使经过“人性化”处理,或经过试图规避AI检测的工具处理,Pangram仍能检测出AI生成的文本,从而确保检测的可靠性。
关于我们
关于
Pangram Labs
在 Pangram,我们的使命是在生成式人工智能内容日益增多的背景下重建信任。公司由来自特斯拉和谷歌的人工智能研究人员于 2024 年在纽约布鲁克林创立,我们持续为研究界做出贡献,以提升透明度。如果您感兴趣,欢迎进一步了解我们的研究成果与合作项目。

工作原理
Pangram 的 AI 检测器如何工作
将文本复制并粘贴到输入框中,或上传文件。Pangram 支持 PDF、DOCX 和 RTF 格式文件,每次最多可上传 100 个文件。
Pangram 利用先进的 AI 检测算法分析您的文本,以高精度识别由 AI 生成的内容。

查看详细结果,其中包含AI检测分数、标注段落以及对您文本的全面分析。
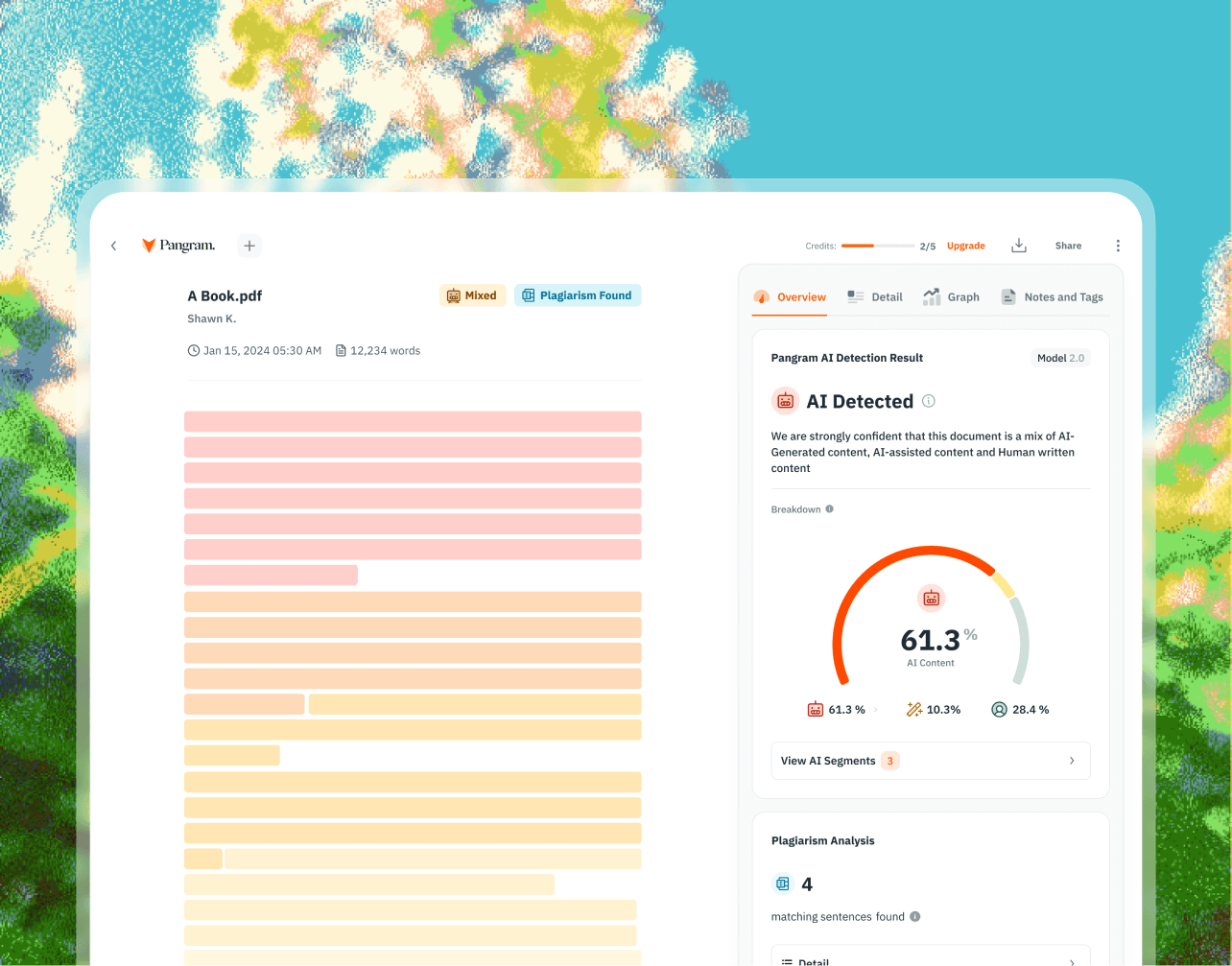
您可以在一个地方查看完整的扫描历史记录、下载报告并管理以往的检测记录。
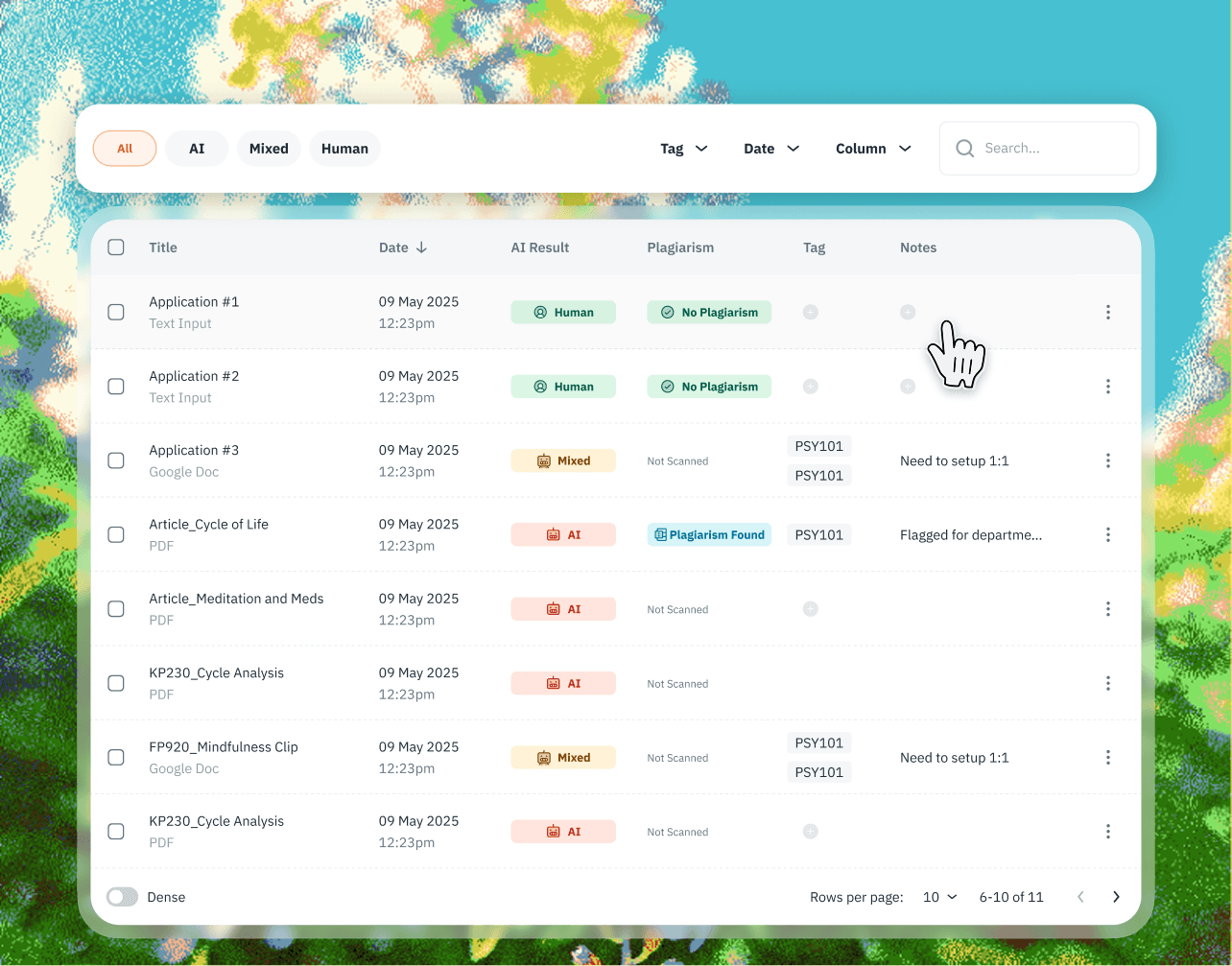

Pangram 还已集成到 Chrome 浏览器、Google 文档以及 Google Classroom 和 Canvas 等众多学习管理系统中。
将文本复制并粘贴到输入框中,或上传文件。Pangram 支持 PDF、DOCX 和 RTF 格式文件,每次最多可上传 100 个文件。
Pangram 利用先进的 AI 检测算法分析您的文本,以高精度识别由 AI 生成的内容。
查看详细结果,其中包含AI检测分数、标注段落以及对您文本的全面分析。
您可以在一个地方查看完整的扫描历史记录、下载报告并管理以往的检测记录。
Pangram 还已集成到 Chrome 浏览器、Google 文档以及 Google Classroom 和 Canvas 等众多学习管理系统中。


功能
面向企业和学校的 AI 检测解决方案




看看我们的用户怎么说
用户喜爱Pangram

亚历克斯·伊马斯,教授
Pangram 确实非常出色。比其他 AI 检测工具强得多(简直是天壤之别)。我亲自使用并进行了全面测试,发现误报和漏报的情况极少。
芝加哥大学布斯商学院
对我来说,Pangram Labs 已成为我为课程找到的最以学生为中心的选择。学生们可以在我们的 Canvas 平台中直接看到与我相同的报告,而且 Pangram 记录在案的误报率(1/10,000)让我能够放心地将系统标记视为一次沟通的契机,而非预设学生有错。
——苏珊·雷,特拉华县社区学院英语副教授
人工智能领域充斥着大量被过度炒作、千篇一律的产品,但这款检测工具的表现简直好得超乎寻常。我至今尚未遇到过任何误报或漏报的情况。
云架构师
——瑞安·尼科拉西,云架构师

珍娜·拉塞尔,博士
我们将人类专家与五款人工智能检测工具(包括Pangram和GPTZero)进行了对比。在自动检测工具中,Pangram的表现明显优于其他工具。

图欣·查克拉巴蒂 教授
Pangram 确实是我们拥有的最佳 AI 检测工具之一,大家应该用用看。

根据我们在秋季学期的经验,我们对Pangram作为维基百科条目中AI内容的检测工具充满信心。
——莉安娜·戴维斯,维基教育项目总监兼副主任
Pangram 的表现明显优于我尝试过的其他大型语言模型(LLM)内容检测服务。它大大减轻了我们的审核工作量,其带来的效益远超其成本。如果您运营的是用户生成内容的平台,那么您应该考虑使用它。
——罗伯特·穆什卡特布拉特,LessWrong首席技术官

Qwoted首席执行官丹·西蒙
新闻业的未来取决于信任。正因如此,我们非常高兴能与 Pangram 合作——该公司在人工智能检测与归因领域树立了黄金标准。

.svg)
我们的分类器采用传统的语言模型架构。它接收输入文本并将其分词。随后,模型将每个词汇转换为嵌入向量,即一个代表该词汇含义的数字向量。输入数据经过神经网络处理后,生成一个输出向量。分类器头部将该输出向量转换为“人类”、“AI”或“AI辅助”的预测结果。 我们使用一个规模虽小但多样化的数据集对初始模型进行训练,该数据集包含约100万份由人类撰写且采用公开许可协议的文档。该数据集还包含由GPT-5及其他前沿语言模型生成的AI文本。训练结果是一个能够可靠预测文本由人类还是AI创作的神经网络。
.svg)
在初始训练完成后,我们的模型会通过迭代优化实现持续改进。我们收集实际应用中的反馈,并整合新的数据模式,以提升检测准确率。这一迭代过程确保我们的AI检测技术始终处于行业前沿,能够适应不断涌现的新语言模型和写作风格。
.svg)
为了保持最高的准确率,我们持续使用包含最新AI生成内容的更新数据集对AI检测模型进行重新训练。这一定期的重新训练流程确保我们的检测能力能够跟上不断发展的AI技术,并能可靠地识别出由最新语言模型生成的内容。
我们的分类器采用传统的语言模型架构。它接收输入文本并将其分词。随后,模型将每个词汇转换为嵌入向量,即一个代表该词汇含义的数字向量。输入数据经过神经网络处理后,生成一个输出向量。分类器头部将该输出向量转换为“人类”、“AI”或“AI辅助”的预测结果。 我们使用一个规模虽小但多样化的数据集对初始模型进行训练,该数据集包含约100万份由人类撰写且采用公开许可协议的文档。该数据集还包含由GPT-5及其他前沿语言模型生成的AI文本。训练结果是一个能够可靠预测文本由人类还是AI创作的神经网络。
全字母句
0.5%
GPTZero
2.4%
Originality.ai
1.7%
RoBERTa
30.6%
误报率 — 产品评测
全字母句
0%
GPTZero
0.5%
Originality.ai
0%
RoBERTa
64.9%
误报率 — 博客文章
全字母句
0.1%
GPTZero
1%
Originality.ai
0.3%
RoBERTa
77.8%
假阳性率 — 新闻报道
全字母句
0%
GPTZero
0.5%
Originality.ai
0.3%
RoBERTa
53.2%
假阳性率 — 小说节选
全字母句
0.8%
GPTZero
1%
Originality.ai
2.2%
RoBERTa
51.7%
误报率 — 餐厅点评
全字母句
0%
GPTZero
0%
Originality.ai
0.1%
RoBERTa
69.1%
假阳性率 — 摘要
全字母句
0.5%
GPTZero
2.4%
Originality.ai
1.7%
RoBERTa
30.6%
误报率 — 产品评测










以获取我们的最新动态
