 ChatGPT 只需几秒钟就能写出2000字的垃圾内容
ChatGPT 只需几秒钟就能写出2000字的垃圾内容
ChatGPT 及其他大型语言模型(LLMs)——通常统称为“AI”——已成为越来越受欢迎的工具。它们最常见的应用场景是作为助手,用户可以与语言模型直接对话。然而,大型语言模型正越来越多地被用于生成“垃圾内容”,这个术语指的是不受欢迎或草率生成的 AI 内容。 AI垃圾内容的典型例子包括:由ChatGPT全权撰写并发布在互联网上的博客文章,其目的仅在于吸引搜索流量;还有企业利用AI撰写多篇冗长且溢美之词的评论,以此提升自身评分。
Pangram Labs 开发了一个高精度的机器学习模型,用于识别由人工智能生成的文本。在训练结束时,该模型已处理了数亿条由人类撰写和人工智能生成的文本示例。本文将帮助您培养识别人工智能生成的文本的直觉,最好是在较少示例的情况下也能做到这一点。
我曾与教育工作者、招生顾问和出版商交流过,由于人工智能应用的激增,过去一年里他们都不得不学习这项技能。本文综合了从他们那里获得的信息,以及我们Pangram公司内部用于帮助新员工快速上手的技巧。毕竟,如果不熟悉任务本身,就无法训练出优秀的机器学习模型。
简而言之
- 查找常见的人工智能术语。
- 请让 ChatGPT 生成多种你试图检测的文档类型,并寻找其中的相似之处。
- 试着让AI生成的内容难以辨别,并找出其中突兀之处。
- 使用抄袭检测工具来磨练你的直觉。
写作的组成部分
主题
通常情况下,AI无法自行选择主题——它会根据提示撰写关于特定内容的文章。即便如此,AI在选择其自行确定的子主题时仍会表现出偏见。 例如,如果我提示ChatGPT为我写一篇关于《白鲸》中象征主义的论文,它很可能会选择同一套最显而易见的主题。然而,任何学生都可以提示ChatGPT专门写关于书中某种特定象征形式的内容,而ChatGPT也能写出来。正因如此,在判断文本是否由AI生成时,我不会过多考虑主题本身。
结构
当被要求撰写完整的文档时,AI通常会采用某种默认的结构。 若让它撰写博客文章,它通常会以引言开头,接着是3-4个段落,再列出几个要点,最后以总结全文的结论收尾。同样地,如果我让AI写一篇餐厅点评,它往往会以“最近我有幸在____用餐”开头,随后谈论食物、氛围和服务,最后以热情洋溢的“强烈推荐”作结。 虽然可以通过提示语打破这种默认结构(例如“写一篇20段的博客文章”、“保持评论简短,不要提及餐厅名称”),但这需要付出许多提示者不愿付出的努力。当文章的结构与其他AI生成的内容相似时,这往往是一个强烈的初步信号,表明需要进一步深入探究。
样式
在扑克游戏中,“破绽”(tell)一词指的是玩家在虚张声势时无意间透露出的线索。例如,当有人感到紧张时,可能会不停摆弄眼镜,从而泄露了关于自己下注意图的信息。同样,在Pangram中,我们将某些词汇或短语称为“AI破绽”——这些是ChatGPT或其他语言模型使用频率异常高的词汇或短语,一旦你开始注意到它们,它们就是AI生成内容的强烈信号。
“Delve”是一个典型的AI特征词,因为ChatGPT使用该词的频率远高于普通美式英语中的使用频率。
有人给我发了一封冷邮件,提议开展一个新项目。随后我注意到邮件中用了“delve”这个词。
— 保罗·格雷厄姆 (@paulg) 2024年4月7日
我还注意到,“最近我有幸……”是餐厅评论中常见的表达,而如果你让ChatGPT撰写求职信,它总会设法插入“热衷”这个词。即使给予大量提示,大型语言模型(LLMs)的行为仍深受其内在风格倾向的驱动。正因如此,风格是我非常重视的一个重要信号。
以下是一些常用的人工智能短语,供您参考。(来源:reddit、aiphrasefinder.com)
- “需要特别指出的是”
- “深入探索”
- 《挂毯》
- “充满活力”
- “热闹”
- “总而言之”或“最后”
- “请记住……”
- “深入探索”
- “驾驭”,即“驾驭局势”、“驾驭……的复杂性”
- “景观”,即“……的景观”,尤其是“不断演变的景观”
- “Testament”,即“……的见证”
- “在……的世界里”
- “领域”
- “启航”
- 《交响曲》
- “拥抱”
- “无论你是X还是Y”
- “说到”
提升直觉的技巧
短语是一个不错的参考基准,但人工智能生成的文本往往虽然明显是AI写的,却并未使用这些短语。为了提升这项技能,我们需要花些时间实际研究AI的写作方式。
学习人工智能写作
对有些人来说这可能令人反感,对另一些人来说却充满乐趣,但如果你想识别AI生成的内容,就必须了解AI写作的特点。如果你有特定类型的文本需要识别,这会更有帮助。 假设我想练就识别AI邮件的绝活。首先要做的是让ChatGPT写一封陌生人搭讪邮件、一封感谢邮件和一封营销邮件。重复几次,每次调整提示词,并记录每次生成的文本之间的共同点。接下来,再用Claude和Gemini尝试,继续寻找规律。
主题:探讨与OpenAI的合作机会
尊敬的 [创始人姓名],
希望您一切安好。我是[您的姓名],现任[您的公司/机构]的[您的职位],我们专注于[简要描述您的领域或专长]。我一直关注着OpenAI在人工智能领域取得的突破性进展,贵公司对伦理人工智能开发的承诺以及项目带来的变革性影响,令我深感钦佩。
我联系您,是希望探讨我们双方机构之间潜在的合作机会。我相信,将 OpenAI 的 AI 能力与我们在 [贵方具体领域或技术] 方面的专业知识相结合,有望催生出创新解决方案,从而推动该领域的发展并创造巨大价值。
希望能有机会进一步探讨此事,并共同探索如何携手实现我们的共同目标。方便的话,能否安排一次简短的电话沟通或面谈?我的时间比较灵活,很乐意配合您的日程安排。
感谢您对此次机会的关注。我期待能有机会与您共事,并为 OpenAI 的激动人心的发展贡献自己的力量。
此致,
[您的全名]
[您的职位]
[贵公司/贵机构]
[联系方式]
[领英个人资料或网站](可选)
玩对抗性游戏
在创立Pangram Labs之初,我们进行了大量被称为“人类基准测试”的实验。规则很简单:先选定一个主题。我们的首次人类基准测试选定的是大学申请文书。A 方收集五篇由人类撰写的大学申请文书,然后使用 ChatGPT 或其他大型语言模型(LLM)生成五篇由 AI 撰写的文书。将这十篇文书打乱顺序,作为测试材料交给 B 方,请其判断哪些是 AI 生成的。 参与者B可以进行测试并说明其判断依据。这为评估这些文章的可识别性建立了基准,并有助于制定识别准则。
更进一步,B 可以利用这些发现来设定一个更具挑战性的“人类基准”,例如向大语言模型提供更多输入,或者要求它避免使用那些会暴露其身份的短语。这种反复试错的过程不仅能进一步提升你的直觉,还能帮助你识别哪些 AI 特征会反复出现。
关于人类基准的示例,请参考以下两篇评论。一篇来自Yelp,另一篇来自GPT-4。
| 示例 1 | 示例 2 |
|---|---|
| 教科书咖啡馆是令人愉悦的瑰宝!这家温馨小店氛围宜人,堪称享受宁静午后的绝佳去处。这里的三明治堪称一绝,新鲜食材与创意搭配既满足传统口味,也迎合冒险家般的味蕾。服务热情周到,每次光临都能收获愉悦体验。无论是匆匆来份快餐,还是捧着好书悠然小憩,教科书咖啡馆都是放松身心、品味美馔的理想之选。 | 我们分食了梅尔盖兹早餐三明治、鱼肉三明治和薯条。早餐三明治相当扎实,不过我觉得如果把梅尔盖兹肉饼捣碎成小块,再和鸡蛋一起炒散,让肉味更均匀地分布,味道会更好。有些口里全是香肠没有其他配料,我觉得混合起来会更美味。鱼肉三明治相当不错,和许多同类三明治相比,份量特别大。 面包量是否过多?但比起份量不足的三明治,这反而是个更令人欣慰的烦恼。薯条裹着突尼斯风味调料,却未能打动我——香气诱人,口感却略带苦涩,且调料附着不均,有些薯条被厚厚覆盖,有些则毫无沾染。 |
如果还不明显的话,第一个例子是AI生成的,第二个则是人类写的。我既指定了主题(布鲁克林的“教科书咖啡馆”),也指定了结构(一段),但ChatGPT的风格太过鲜明,所以还是能明显分辨出来。不妨自己试着写一个,然后分享给朋友看看!
使用专为AI检测设计的工具
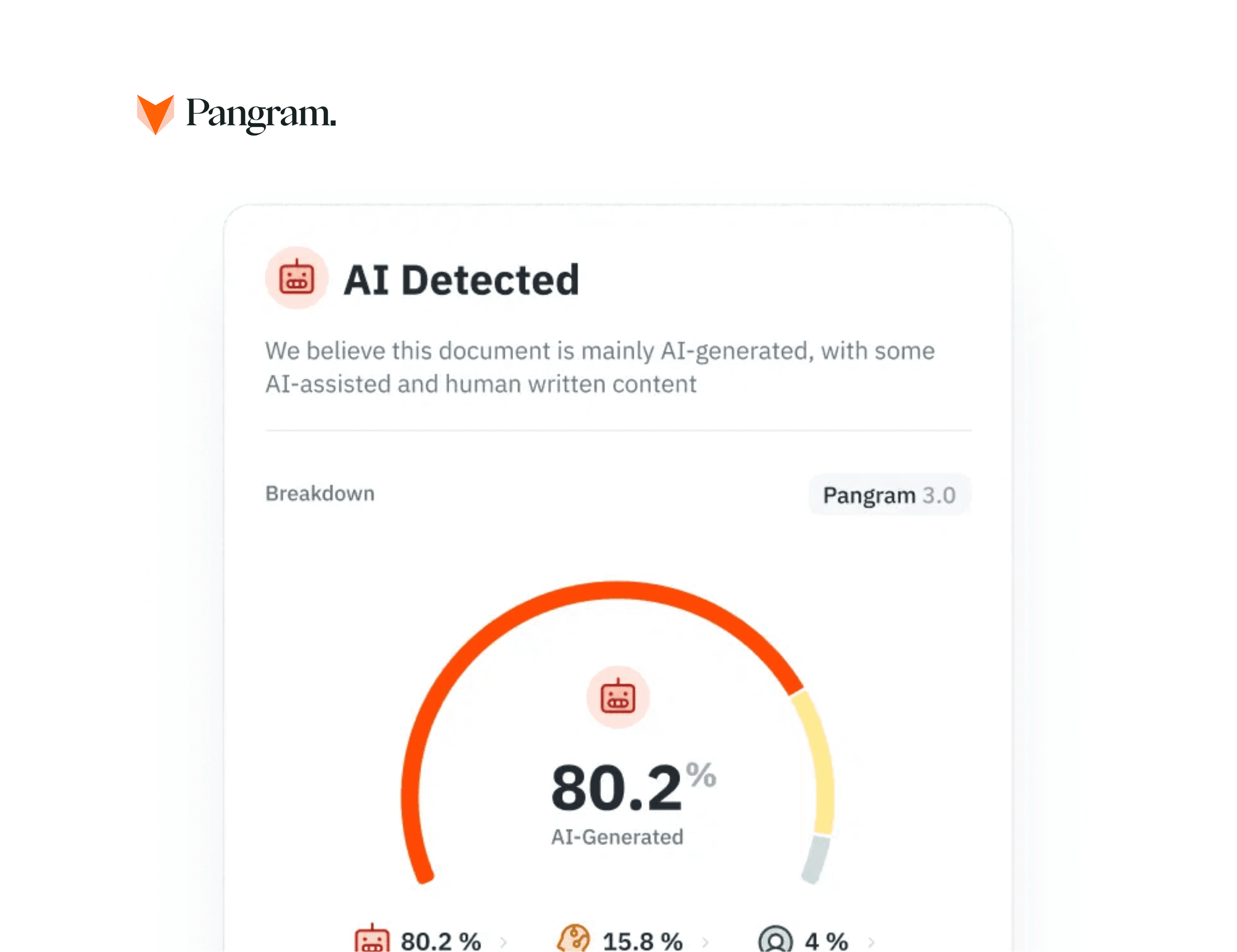
Pangram Labs 投入了无数时间来训练机器学习模型,这些模型通过分析数亿份文档,已能精准区分由人工智能和人类撰写的内容。既然如此,我不如稍微自卖自夸一下。 我们的仪表盘支持粘贴文本或上传文档,因此如果您心存疑虑,希望获得比直觉更确凿的依据,它将为您提供分类结果及置信度评分。仪表盘还包含深度分析功能,可显示哪些词汇或短语在分类过程中提供了最显著的特征信号。每当我在互联网上看到令人心生疑虑的内容时,我都会随时使用这个工具,希望它对您同样有所帮助。
有问题?有意见?发现了一些令人瞠目的AI垃圾内容并想分享吗?请在Twitter/X上联系我:@max_spero_。
想检验一下你的直觉吗?试试 Pangram的人工智能检测工具,它能扫描任何文本,检测其中是否包含人工智能生成的内容。

马克斯是一位经验丰富的机器学习工程师。他最近在Nuro从事自动驾驶汽车相关工作,负责领导该公司的主动学习项目。此前,他在谷歌、Two Sigma和Yelp拥有丰富的成功部署机器学习产品的经验。
马克斯拥有斯坦福大学理论计算机科学学士学位和人工智能硕士学位。除了对游戏开发的热情外,他还是《万智牌》Cube社区的活跃成员。




以获取我们的最新动态
