بانجرام هو الكاشف الوحيد للذكاء الاصطناعي الذي يتفوق على الخبراء البشريين في تحديد المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي
يسعدنا الاطلاع على الدراسة البحثية الجديدة التي أجرتها جينا راسل ومارزينا كاربينسكا وموهيت إيير، وهم باحثون من جامعة ماريلاند وشركة مايكروسوفت، والتي تبيّن أن «بانغرام» هو أفضل كاشف للذكاء الاصطناعي من حيث الأداء في مقارنة أجريت، كما أنه النظام الوحيد القادر على التفوق على الخبراء البشريين المدربين في الكشف عن المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي. اقرأ الورقة البحثية كاملة هنا.

بالإضافة إلى دراسة فعالية أدوات الكشف الآلية التي تعتمد على الذكاء الاصطناعي، يبحث الباحثون أيضًا في الكيفية التي يلتقط بها الخبراء البشريون المدربون الإشارات التي تساعدهم على تحديد العلامات الدالة على المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي. ونحن نعتقد أن هذا البحث يمثل خطوة كبيرة إلى الأمام في مجال قابلية التفسير والتوضيح في مجال الكشف عن الذكاء الاصطناعي، ونحن متحمسون لمواصلة استكشاف هذا الاتجاه البحثي.
في هذه المدونة، سنشرح أبرز نتائج البحث وما يعنيه ذلك بالنسبة لاكتشاف نماذج اللغة الكبيرة (LLM) في المستقبل.
تدريب البشر ليصبحوا قادرين على كشف الذكاء الاصطناعي
لقد كتبنا في الماضي عن كيفية الكشف عن النصوص التي كتبها الذكاء الاصطناعي واختبار المعيار البشري، وكيف نستخدم ذلك لاكتساب فهم عميق للنصوص التي يولدها الذكاء الاصطناعي، مما يساعدنا على تطوير نماذج أفضل.
عادةً، عندما نبدأ في تدريب أنفسنا على اكتشاف التعليقات أو المقالات أو منشورات المدونات أو الأخبار التي أنشأتها الذكاء الاصطناعي، لا نكون بارعين في ذلك في البداية. يستغرق الأمر بعض الوقت قبل أن نبدأ في ملاحظة العلامات الدالة على أن النص قد تم إنشاؤه بواسطة ChatGPT أو نموذج لغوي آخر. على سبيل المثال، عندما بدأنا دراسة المراجعات، تعلمنا بمرور الوقت من خلال الاطلاع على الكثير من البيانات أن ChatGPT يحب أن يبدأ المراجعة بعبارة "لقد كان من دواعي سروري مؤخرًا"، أو عندما بدأنا قراءة قصص الخيال العلمي التي تم إنشاؤها بواسطة الذكاء الاصطناعي، غالبًا ما تبدأ بعبارة "في عام". ومع ذلك، بمرور الوقت، نبدأ في استيعاب هذه الأنماط ويمكننا البدء في التعرف عليها.
كما تساءل الباحثون عما إذا كان من الممكن تدريب الخبراء على اكتشاف المقالات التي تم إنشاؤها بواسطة الذكاء الاصطناعي بالطريقة نفسها. وقاموا بتدريب خمسة مُصنِّفين على منصة Upwork على اكتشاف المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي، وقارنوا قدرتهم على اكتشافه بالعين المجردة بقدرة غير الخبراء.
ورغم أنه من المتوقع أن نلاحظ اختلافًا في قدرة هاتين المجموعتين على تمييز النصوص التي كتبها الذكاء الاصطناعي، إلا أن ما توصل إليه الباحثون كان فارقًا كبيرًا. فأداء غير المتخصصين في اكتشاف النصوص التي أنتجها الذكاء الاصطناعي لا يختلف كثيرًا عن الصدفة العشوائية، في حين أن أداء الخبراء يتسم بدقة عالية (بمعدل إيجابي صحيح يزيد عن 90٪ في المتوسط).

كان أحد الأقسام التي وجدناها مثيرة للاهتمام بشكل خاص هو القسم المعنون "ما الذي يراه المُعلِّقون الخبراء ولا يراه غير الخبراء؟". طلب الباحثون من المشاركين شرح الأسباب التي دفعتهم إلى الاعتقاد بأن نصًا ما قد تم إنشاؤه بواسطة الذكاء الاصطناعي أو العكس، ثم قاموا بتحليل تعليقات المشاركين.
فيما يلي بعض التحليلات المقتبسة مباشرة من الورقة البحثية:
"غالبًا ما يركز غير الخبراء بشكل خاطئ على خصائص لغوية معينة مقارنة بالخبراء. ومن الأمثلة على ذلك اختيار المفردات، حيث يعتبر غير الخبراء أن استخدام أي كلمات "رنانة" أو كلمات نادرة الاستخدام دليلًا على أن النص من إنتاج الذكاء الاصطناعي؛ في المقابل، فإن الخبراء أكثر درايةً بالكلمات والعبارات المحددة التي يفرط الذكاء الاصطناعي في استخدامها (مثل: testament، crucial). يعتقد غير الخبراء أيضًا أن المؤلفين البشريين أكثر عرضة لتكوين جمل صحيحة نحويًا، وبالتالي ينسبون الجمل المتداخلة إلى الذكاء الاصطناعي، ولكن العكس هو الصحيح: البشر أكثر عرضة من الذكاء الاصطناعي لاستخدام جمل غير نحوية أو متداخلة. أخيرًا، ينسب غير الخبراء أي نص مكتوب بنبرة محايدة إلى الذكاء الاصطناعي، مما يؤدي إلى العديد من النتائج الإيجابية الخاطئة لأن الكتابة البشرية الرسمية غالبًا ما تكون محايدة في نبرتها أيضًا." (Russell, Karpinska, & Iyyer, 2025).
في الملحق، يقدم المؤلفون قائمة بـ«مفردات الذكاء الاصطناعي» التي يستخدمها ChatGPT بشكل شائع – وهي ميزة أطلقناها مؤخرًا في لوحة تحكم Pangram لتسليط الضوء على العبارات الشائعة في مجال الذكاء الاصطناعي!

من واقع خبرتنا، وجدنا أنه على الرغم من اعتقاد الكثيرين بأن الذكاء الاصطناعي يستخدم مفردات معقدة و"متكلفة"، فإننا نلاحظ في الواقع أن الذكاء الاصطناعي يميل بدلاً من ذلك إلى استخدام مفردات مبتذلة ومجازية لا تكون منطقية في أغلب الأحيان. وبصورة غير رسمية، يمكننا القول إن نماذج اللغة الكبيرة (LLMs) تشبه إلى حد كبير الأشخاص الذين يحاولون الظهور بمظهر الأذكياء، لكنهم في الحقيقة لا يستخدمون سوى العبارات التي يعتقدون أنها ستجعلهم يبدون أذكياء.
قدرة أجهزة الكشف القائمة على الذكاء الاصطناعي على الصمود أمام أحدث النماذج
أحد الأسئلة التي نتلقاها كثيرًا في Pangram هو: كيف تواكبون أحدث النماذج اللغوية؟ وعندما تتطور النماذج اللغوية، هل يعني ذلك أن Pangram لن تعمل بعد الآن؟ هل هي لعبة القط والفأر التي ستتفوق علينا فيها المختبرات الرائدة مثل OpenAI؟
وقد تساءل الباحثون عن ذلك أيضًا، وقاموا بدراسة أداء عدة طرق للكشف باستخدام الذكاء الاصطناعي في مواجهة نموذج o1-pro التابع لـ OpenAI، وهو النموذج الأكثر تقدمًا الذي تم إصداره حتى الآن.
وقد توصل الباحثون إلى أن "بانجرام" يتمتع بدقة تبلغ 100% في الكشف عن مخرجات o1-pro، كما أننا لا نزال نحقق دقة تبلغ 96.7% في الكشف عن مخرجات o1-pro "المُصممة بطريقة تشبه البشر" (والتي سنتطرق إليها بعد قليل)! وبالمقارنة، لم يتمكن أي كاشف آلي آخر من تجاوز نسبة 76.7% حتى في الكشف عن مخرجات o1-pro الأساسية.
كيف تمكنت Pangram من التعميم بهذه الطريقة؟ ففي نهاية المطاف، لم تكن لدينا في وقت إجراء الدراسة أي بيانات من نوع o1-pro ضمن مجموعة التدريب الخاصة بنا.
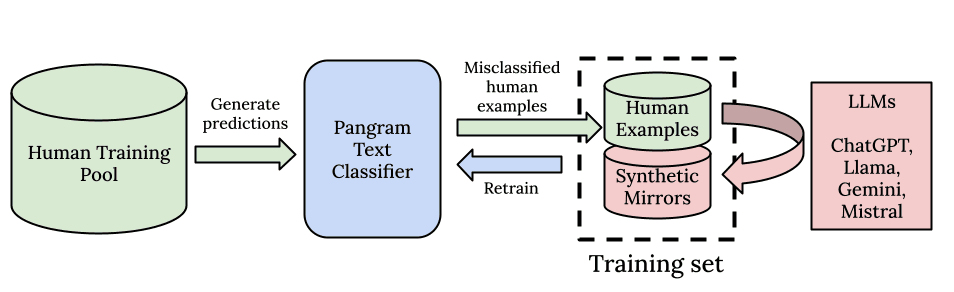
مثل جميع نماذج التعلم العميق، نؤمن بقوة التوسع والقدرة الحاسوبية. أولاً، نبدأ بنموذج أساسي قوي تم تدريبه مسبقاً على مجموعة بيانات تدريب ضخمة، تماماً مثل نماذج اللغة الكبيرة (LLMs) نفسها. ثانياً، قمنا ببناء مسار بيانات مصمم للتوسع. يستطيع Pangram التعرف على الأنماط الدقيقة من مجموعة بيانات التدريب الخاصة به التي تضم 100 مليون وثيقة كتبها البشر.
نحن لا نكتفي ببناء مجموعة بيانات للمقالات أو الأخبار أو المراجعات: بل نحاول الحصول على أوسع شبكة ممكنة من جميع البيانات المكتوبة بواسطة البشر الموجودة، حتى يتمكن النموذج من التعلم من توزيع البيانات الأعلى جودة والأكثر تنوعًا والتعرف على جميع أنواع الكتابة البشرية. نجد أن هذا النهج العام للكشف عن الذكاء الاصطناعي يعمل بشكل أفضل بكثير من النهج المتخصص المتمثل في بناء نموذج واحد لكل مجال نصي.
ويكمل قاعدة بياناتنا البشرية الضخمة للغاية وعالية الجودة كل من مسار البيانات الاصطناعية وخوارزمية البحث القائمة على التعلم النشط. ومن أجل توفير بيانات الذكاء الاصطناعي اللازمة لخوارزميتنا، نستخدم مكتبة شاملة من المطالبات وجميع نماذج الذكاء الاصطناعي الرئيسية مفتوحة المصدر ومغلقة المصدر لتوليد البيانات الاصطناعية. نستخدم المطالبات المرآة الاصطناعية، التي كتبنا عنها في تقريرنا الفني، والتعدين السلبي الصارم، الذي يبحث عن الأمثلة في مجموعة البيانات لدينا التي تحتوي على أعلى نسبة خطأ، ويخلق أمثلة للذكاء الاصطناعي تشبه إلى حد كبير تلك البشرية، ويعيد تدريب النموذج حتى لا نرى أي أخطاء أخرى. يتيح لنا ذلك خفض معدلات الإيجابيات الكاذبة والسلبيات الكاذبة لنموذجنا إلى الصفر بكفاءة عالية.
باختصار، يعود الفضل في تعميمنا إلى حجم بيانات التدريب المسبق لدينا، وتنوع المطالبات ونماذج اللغة الكبيرة المستخدمة في توليد البيانات الاصطناعية، وكفاءة البيانات الناتجة عن نهجنا القائم على التعلم النشط واستخراج الحالات السلبية الصعبة.
علاوة على ذلك، لا نسعى فقط إلى تحقيق أداء ممتاز في البيانات خارج نطاق التوزيع، بل نريد أيضًا التأكد من أن أكبر عدد ممكن من نماذج اللغات الكبيرة الشائعة تكون ضمن نطاق التوزيع قدر الإمكان. ولذلك، قمنا ببناء مسار عمل آلي قوي لاستخراج البيانات من أحدث النماذج، حتى نتمكن من بدء التدريب على نماذج اللغات الكبيرة الجديدة فور إصدارها والبقاء على اطلاع دائم. نجد أنه لا يوجد تناقض بين تحقيق التوازن في الأداء على النماذج المختلفة: نجد أنه في كل مرة نقدم فيها نموذج لغة كبير (LLM) جديد إلى مجموعة التدريب، يتحسن تعميم النموذج.
في ظل نظامنا الحالي، لا نلاحظ أن النماذج تصبح أصعب في الكشف عنها مع تحسنها. ففي كثير من الحالات، يكون النموذج من الجيل التالي أسهل في الكشف عنه بالفعل. على سبيل المثال، وجدنا أننا كنا أكثر دقة في الكشف عن «كلود 3» عند إطلاقه مقارنةً بـ«كلود 2».
هجمات برامج إعادة الصياغة وإضفاء الطابع الإنساني
في سلسلة منشورات المدونة الأخيرة، وصفنا ماهية أداة "إضفاء الطابع البشري على الذكاء الاصطناعي" ، كما أطلقنا نموذجًا يتميز بأداء محسّن بشكل كبير في مجال النصوص التي تم إضفاء الطابع البشري عليها باستخدام الذكاء الاصطناعي. ويسعدنا أن نرى بالفعل أن جهة خارجية قد أثبتت صحة ادعاءاتنا من خلال مجموعة بيانات تضم مقالات o1-pro التي تم إضفاء الطابع البشري عليها.
فيما يتعلق بالنصوص المُصاغة بأسلوب بشري في مجموعة o1-pro، حققنا دقة بلغت 96.7٪، في حين أن أفضل نموذج آلي آخر لم يتمكن سوى من اكتشاف 46.7٪ من النصوص المُصاغة بأسلوب بشري.
كما أننا نحقق دقة بنسبة 100٪ في النصوص المكتوبة بواسطة GPT-4o التي تمت إعادة صياغتها جملةً جملةً.
الخلاصة
يسعدنا أن نرى الأداء القوي الذي حققته Pangram في دراسة مستقلة حول قدرات الكشف باستخدام الذكاء الاصطناعي. ويسعدنا دائمًا دعم الأبحاث الأكاديمية، ونوفر إمكانية الوصول المفتوح لأي باحث أكاديمي يرغب في دراسة أداة الكشف الخاصة بنا.
بالإضافة إلى تقييم أداء أدوات الكشف الآلي، نحن متحمسون لرؤية الأبحاث التي بدأت تتناول مسألة قابلية تفسير وتوضيح عمليات الكشف التي تقوم بها الذكاء الاصطناعي: ليس فقط ما إذا كان النص قد كُتب بواسطة الذكاء الاصطناعي، بل لماذا. ونحن نتطلع إلى كتابة المزيد حول كيفية مساعدة هذه النتائج للمعلمين والمربين على التعرف على النصوص التي أنشأها الذكاء الاصطناعي بمجرد النظر إليها، وكيف نخطط لدمج هذه الأبحاث بشكل أكبر في أدوات كشف آلية أكثر قابلية للتفسير.
لمزيد من المعلومات، يرجى زيارة موقعنا الإلكتروني pangram.com أو الاتصال بنا على العنوان info@pangram.com.

برادلي باحث في مجال الذكاء الاصطناعي وخبير في تطوير منتجات التعلم العميق في القطاع الصناعي. وقد تولى مؤخرًا قيادة مجموعة أبحاث التعلم العميق في شركة «أبسكي» (Absci)، وهي شركة متخصصة في اكتشاف الأدوية باستخدام الذكاء الاصطناعي التوليدي، وكان قبل ذلك عضوًا في الفريق الأساسي للرؤية الحاسوبية في نظام «تيسلا أوتوبيلوت» (Tesla Autopilot).
أثناء دراسته للدراسات العليا، ألف برادلي العديد من المنشورات البحثية في مجال التعلم العميق بالتعاون مع مختبر ستانفورد للرؤية. وهو حاصل على بكالوريوس في الفيزياء وماجستير في الذكاء الاصطناعي من جامعة ستانفورد. وبالإضافة إلى الذكاء الاصطناعي، يهتم برادلي أيضًا بمجالي التعليم والفلسفة، كما أنه لاعب غولف شغوف.
مقالات ذات صلة

مستويات منتجات بانغرام الجديدة

ما مدى كفاءة برنامج Pangram في اكتشاف نماذج الاستدلال؟

تقديم صفحة النتائج الجديدة

هل تعمل أدوات الكشف عن الذكاء الاصطناعي ضد GPT-5؟
تقرير تقني حول الكشف عالي الدقة عن النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي

كيفية التعرف على الذكاء الاصطناعي في لغة بايثون
لتلقي آخر أخبارنا
