
الرؤية في فضاء البانغرام
استكشاف التمثيلات الداخلية لـ «بانغرام 3.3.2»
بقلم إلياس مسرور، وكاثرين تاي، وبرادلي إيمي
يونيو 2026
مقدمة
منذ ظهور ChatGPT لأول مرة في عام 2022، انتشرت الكتابة المدعومة بالذكاء الاصطناعي بوتيرة مذهلة. ونظرًا لأن النصوص التي يُنتجها الذكاء الاصطناعي أصبحت تظهر الآن في جزء كبير مما نقرأه، فقد أصبح من الواضح أن بعض أشكال الكتابة تفقد قيمتها عندما تنتجها آلة. ففي الأوساط الأكاديمية، تهدف المقالات إلى تنمية قدرات الطلاب على التفكير المنطقي. أما في السوق، فتُعد مراجعات المنتجات ذات قيمة لأنها تعكس تجارب الآخرين.
بانغرام هي شركة أبحاث تعمل على تطوير نماذج كشف متطورة تعتمد على الذكاء الاصطناعي لمعالجة هذه المشكلة. منتجنا الرئيسي هو نموذج للكشف عن النصوص المكتوبة بواسطة الذكاء الاصطناعي، يتميز بمعدلات إيجابية كاذبة منخفضة هي الأفضل في القطاع، وقدرات متعددة اللغات، والقدرة على التمييز بين النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي وتلك التي تم إنشاؤها بمساعدة الذكاء الاصطناعي.
منذ إصدار أول ورقة بحثية لنا في عام 2024، حظينا بفرصة فريدة لمراقبة موجة تلو الأخرى من التطورات في مجال الذكاء الاصطناعي. وقد واجه باحثونا صعوبات جمة في التعامل مع مرشحات المحتوى شديدة الصرامة، وشهدوا نصيبنا العادل من حالات انهيار النمط، وتفادى موجات من الشرطات الطويلة وكلمة «delve».
نموذجنا الرئيسي هو نموذج لغة كبير (LLM) تم ضبطه بدقة لمهمة تصنيف التسلسلات هذه. لا نستخدم مقاييس مخصصة مثل «الارتباك» أو «التقلب». كما أننا لا نقوم بأي استخراج يدوي للسمات. لدينا منتج موجه للعملاء يُسمى «AI Phrases»، حيث نقدم لمستخدمينا معلومات حول العبارات التي تظهر بشكل متكرر في نصوص الذكاء الاصطناعي. لكن هذه العبارات لا تُستخدم مباشرةً كسمات للنموذج. وبعد فترة، ينتاب المرء الفضول. ما الذي يراه النموذج؟
بالنسبة لنا كباحثين، فإن هذا السؤال مهم. لدينا دوافع قوية لمنع اتخاذ الطرق المختصرة، وتصحيح السلوك غير المقصود للنموذج، وفهم هذه المشكلة بعمق. في هذا المنشور، سنلخص جهودنا الأولية في مجال قابلية التفسير باستخدام التحليل على مستوى الوثيقة.
البيانات
قمنا بإنشاء مجموعة بيانات قابلة للتفسير من عينات تم استبعادها من نطاق المجال، مأخوذة من مجموعة التدريب الإنتاجية الخاصة بنا. يستخدم المستكشف التفاعلي الموجود في هذه الصفحة مجموعة فرعية متوازنة مكونة من 5,000 وثيقة، مقسمة بالتساوي بين البشر والذكاء الاصطناعي، عبر 20 طبقة زوجية. وتغطي عينات الذكاء الاصطناعي متغيرات النماذج الواردة أدناه عبر مجموعات النماذج الست المستخدمة في اختبار المصنف.
النماذج
- كلود 3.7 سونيت
- كلود سونيت 4
- كلود سونيت 4.5
- كلود أوبوس 4
- كلود أوبوس 4.1
- كلود أوبوس 4.5
- GPT-3.5 Turbo (نوفمبر 2023)
- GPT-3.5 Turbo (يناير 2024)
- GPT-4 (مارس 2023)
- GPT-4 (يونيو 2023)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- جيميني 2.0 فلاش
- جيميني 2.5 فلاش
- جيميني 2.5 برو
- جيميني 3 برو
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- كوين 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
مجالات المصدر
- الأخبار
- ملخصات علمية
- تقييمات المنتجات
- تقييمات الشركات
- الكتابة الإبداعية على Reddit
- Reddit ELI5
- الكتب (المنشورة ذاتيًا)
- الكتب (مشروع غوتنبرغ)
- ويكيبيديا (الإنجليزية)
- ويكيبيديا (متعددة اللغات)
- Lang-8 (تعليم اللغة الإنجليزية كلغة ثانية)
نظرة عامة على Pangram 3.3.2
Pangram 3.3.2 هو نموذج للكشف عن الذكاء الاصطناعي أطلقته Pangram Labs في عام 2026. ويستخدم هذا النموذج نفس النموذج الأساسي المستخدم في Pangram 3.3، مع إصلاحات أخطاء لاحقة تعمل على تحسين الأداء. وقد حلّ Pangram 3.3 محل Pangram 3.2، وحسّن معدل الاسترجاع في مخرجات نماذج اللغة الكبيرة (LLM) الأحدث، والنصوص ذات الطابع البشري، والمحتوى الطويل الذي تولده الذكاء الاصطناعي، مع تقليل حالات الإيجابيات الخاطئة في النصوص المكتوبة بلغة إنجليزية غير أم.
بطاقة النموذجاقرأ بطاقة نموذج «بانغرام 3.3»اطلع على تفاصيل الإصدار الخاص بـ Pangram 3.3.2.اقرأ المقاللا تزال الأعمال المتعلقة بقابلية التفسير جارية. وفي جميع أجزاء هذه المقالة، نقوم أيضًا بتطبيق أساليبنا بأثر رجعي على «بانغرام 3.2» و«بانغرام 3.1».
الطرق
عمليات التنشيط
تعد بنية EditLens نظام تصنيف قائم على المجموعات، والذي يمكن تلخيصه في عنصر واحد ai_assistance_score. في هذا المشروع، نتجاهل النتيجة النهائية للنموذج، ونركز بدلاً من ذلك على التمثيلات الداخلية التي يتعلمها النموذج. ولتحليل هذه التمثيلات، نقوم بجمع قيم التنشيط من خلال إجراء تمريرة أمامية للنموذج باستخدام مستند مدخلات معين، وحفظ التمثيل الخفي للنموذج في طبقات داخلية متعددة. وفي هذا المشروع، قمنا باستخراج قيم التنشيط لكل مستند، ولكل طبقة زوجية عبر الشبكة.
تقليل الأبعاد
كان كل متجه تنشيط مستخرج يتألف من 5,120 بُعدًا. ولتحقيق فهم أفضل لهذه التمثيلات، نستخدم عددًا من تقنيات تقليل الأبعاد.
PCA
يُعد تحليل المكونات الرئيسية (PCA) أبسط أشكال الإسقاط الخطي: فهو يحدد اتجاهات التباين الأقصى في فضاء التنشيط. في هذا المشروع، نجد أنه قرب نهاية الشبكة، يتركز معظم التباين ضمن المكونين الرئيسيين 1 و2، ولذلك نقوم برسمهما على محورين متقابلين.
UMAP
يقدم نموذج UMAP عرضًا غير خطي مصممًا للحفاظ على بنية الجوار. فإذا كانت وثيقتان قريبتين من بعضهما في الفضاء الداخلي للنموذج، فإن نموذج UMAP يحاول إبقائهما قريبتين في الفضاء ثنائي الأبعاد. ومع ذلك، لا ينبغي المبالغة في تفسير المحاور والمسافات الدقيقة بين المجموعات.
t-SNE
تُعد t-SNE طريقة إسقاط غير خطية أخرى تُبرع في الكشف عن المجموعات المحلية. ولأغراض هذا المشروع، نستخدم t-SNE لمعرفة ما إذا كانت المجموعات ذات الأهمية الدلالية، مثل عائلات النماذج أو تصنيفات «البشر/الذكاء الاصطناعي»، تتجمع بشكل واضح مع ازدياد عمق الشبكة.
المجسات الخطية
نستخدم «المسبارات الخطية» لتقييم النتائج النوعية التي نلاحظها من طرق تقليل الأبعاد التي نستخدمها. وبالنسبة لكل طبقة، نسأل عما إذا كان بإمكان مصنف بسيط استخلاص التسمية المستهدفة من متجهات التنشيط الخاصة بتلك الطبقة. وتشير الدقة العالية للمسبار إلى أن التمييز ذي الصلة قد تم ترميزه بالفعل في اتجاه يمكن الوصول إليه خطيًّا في فضاء التمثيل.
مهمة الكشف عن الذكاء الاصطناعي
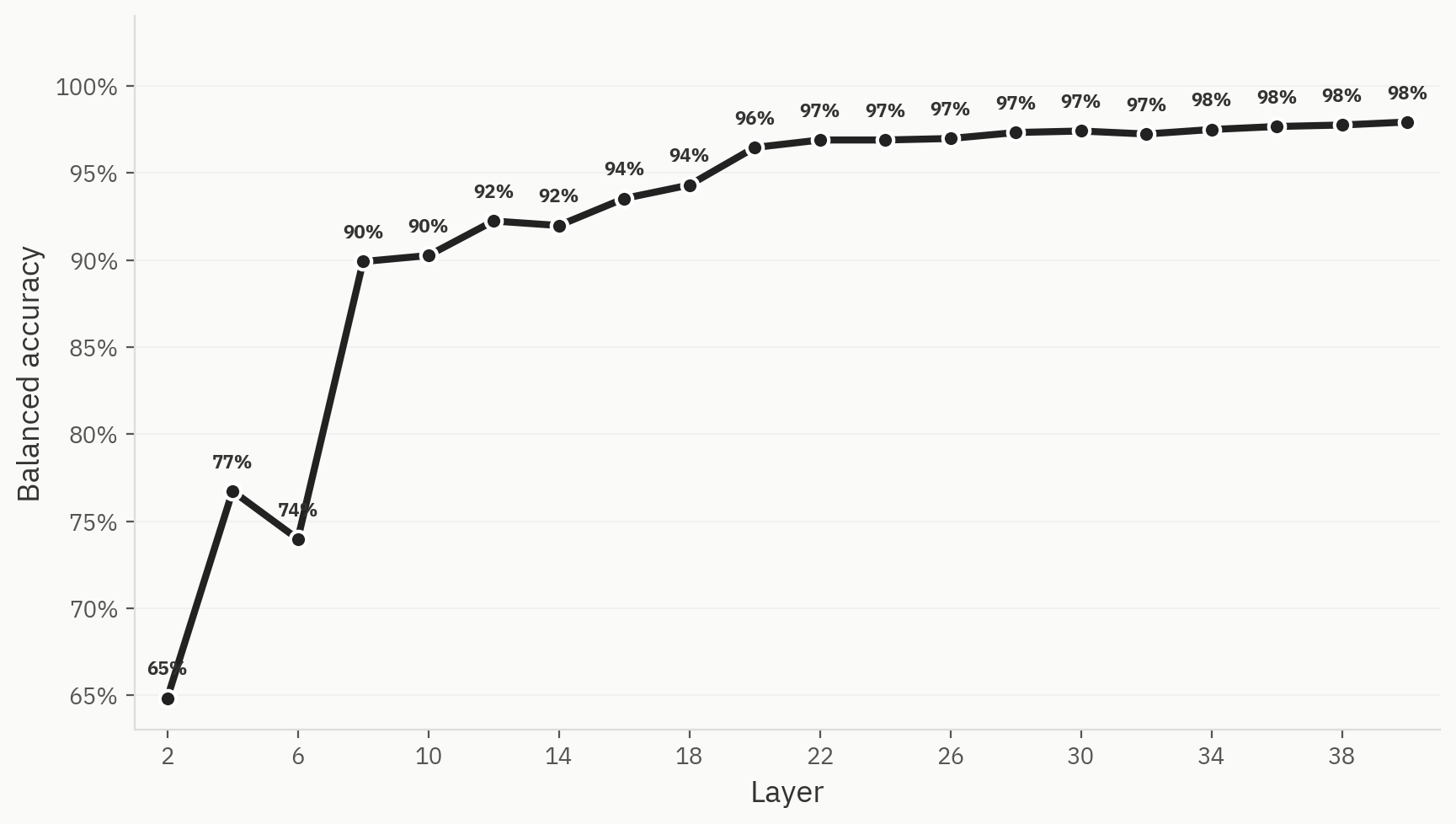
دقة النظام الثنائي
لفهم كيفية تحقيق الفصل النهائي بين الفئات عبر مسار الشبكة، نقوم بتدريب «مسبارات خطية» في كل طبقة. ونقوم بالتدريب على 500 عينة، موزعة بالتساوي بين البشر والذكاء الاصطناعي، مع تقسيم بنسبة 80:20 بين مرحلة التدريب ومرحلة الاختبار. ونجد أن الأداء قوي بالفعل حتى في المراحل المبكرة من الشبكة: فقد حققنا دقة تبلغ 0.83 مباشرة بعد الطبقة الثانية. وهذا يتوافق مع توقعاتنا، حيث إن نماذج «حقيبة الكلمات» غالبًا ما تكون خطوط أساس صالحة لمهمة الكشف عن الذكاء الاصطناعي. وعلى طول الشبكة، تزداد الدقة حتى تصل إلى الحد الأقصى عند 1.0 في الطبقة الـ24.
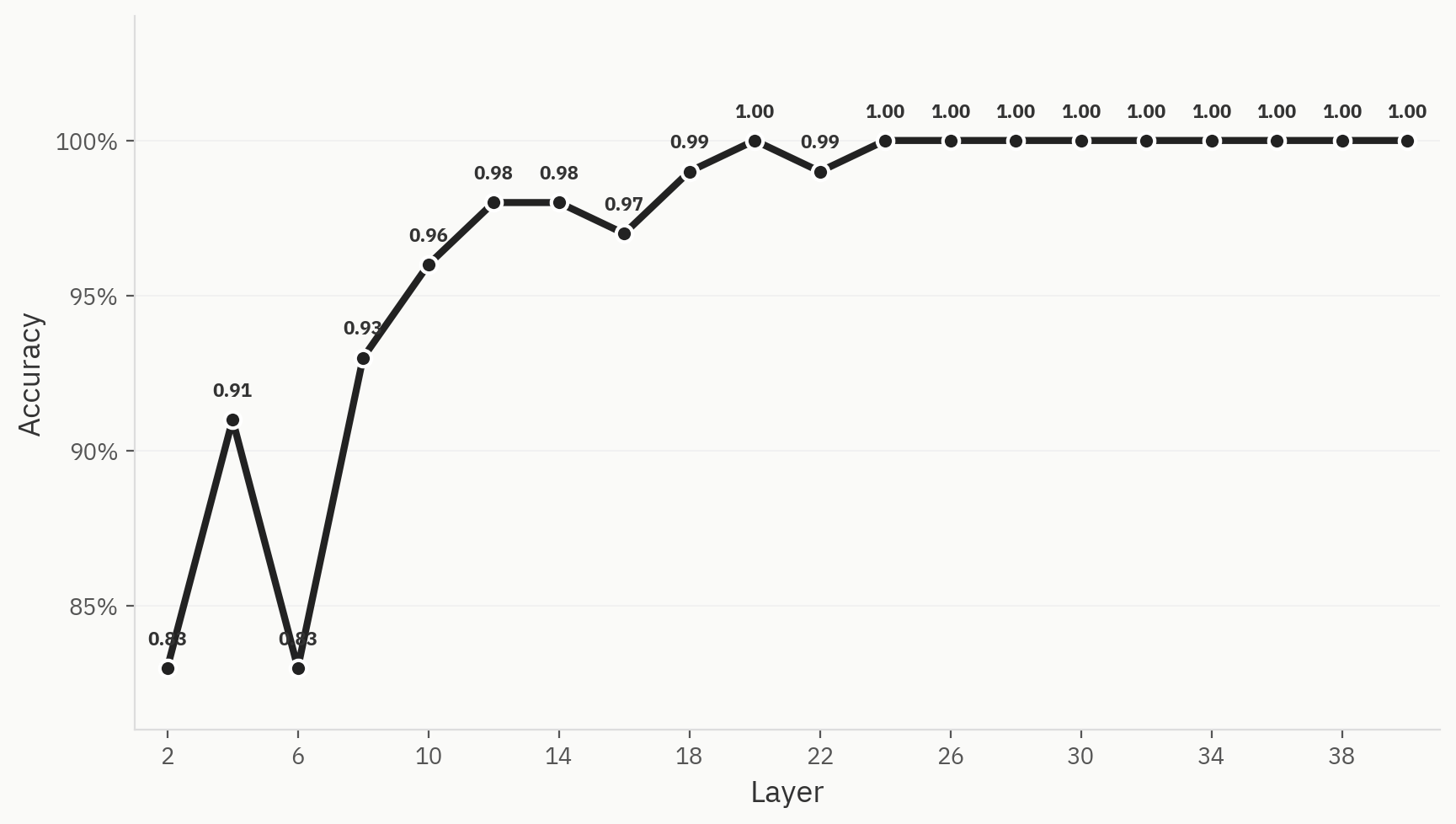
الشكل 3: يظهر هذا الفصل بوضوح في جميع طرق تقليل الأبعاد الثلاث.
تصنيف LLM
في الرسوم البيانية لـ t-SNE و UMAP، لاحظنا أن الوثائق بدت متجمعة حسب النموذج الذي أنتجها. وكان هذا مفاجأة لنا. فقد كانت الإصدارات القديمة من Pangram تحتوي على رأس مصنف منفصل لنماذج اللغة الكبيرة (LLM)، لكن تلك المهمة بالذات تم التخلي عنها منذ فترة طويلة. وفي عملية تدريبه، لا يتم تزويد Pangram 3.3.2 بأي تصنيفات تتوافق مع النموذج الأصلي لأي وثيقة من وثائق الذكاء الاصطناعي.
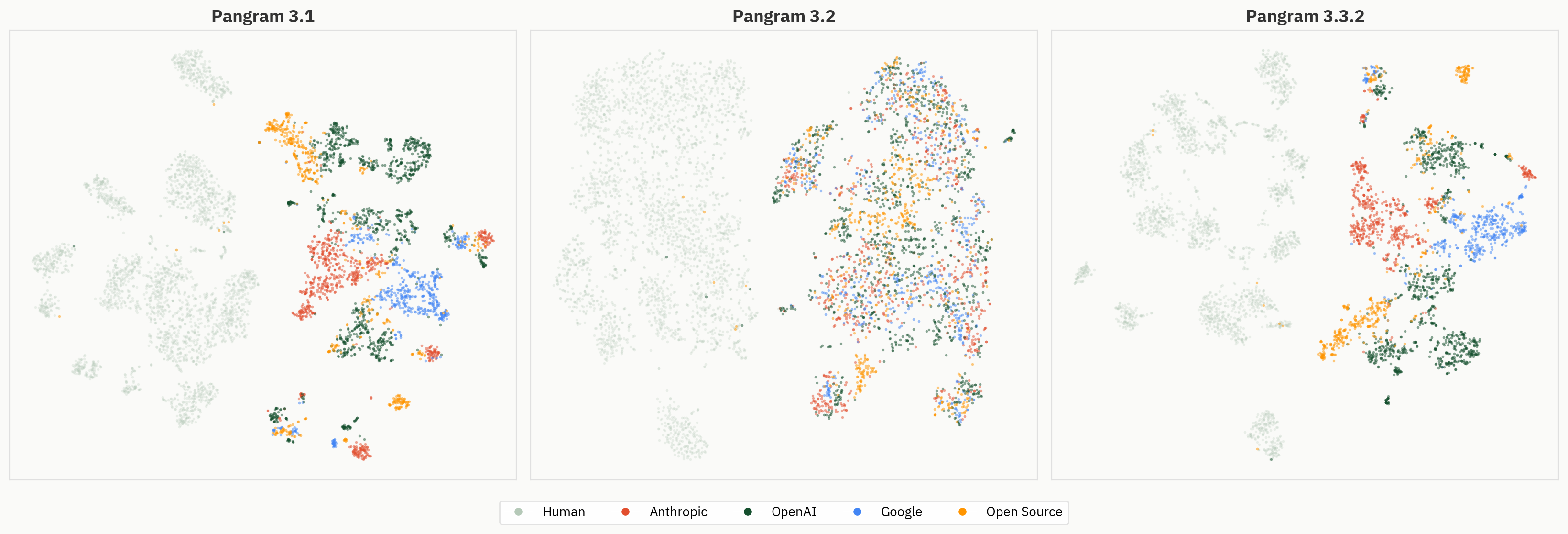
ومع ذلك، تشكلت مجموعات حول عائلة النماذج الأصلية. والأمر الأكثر إثارة للاهتمام هو أن هذه المجموعات تبدو وكأنها تظهر عبر طبقات الشبكة.
ظهور مجموعات النماذج
قم بتلوين التضمينات المتماثلة حسب عائلة النموذج لترى كيف تظهر الهندسة على مستوى المزود عبر الطبقات.
الشكل 4: تم تمييز التضمينات في الطبقات من 2 إلى 40 بالألوان حسب فئة النموذج. وتصبح المجموعات على مستوى المزود أكثر وضوحًا عبر الطبقات اللاحقة.
المسبار
لتحديد حجم هذه الظاهرة، قمنا بتدريب مصنف على ست عائلات من النماذج (Anthropic، OpenAI، Google، Qwen، Llama، DeepSeek) باستخدام 500 عينة لكل عائلة نماذج، و3,000 عينة إجمالاً، مع توزيع 80:20 بين مجموعات التدريب والاختبار. ووجدنا أنه يمكننا بالفعل تدريب أداة فحص قادرة على تصنيف عائلة النماذج الأصلية لوثيقة معينة باستخدام تنشيطات Pangram فقط، مع دقة قصوى في التصنيف الأول (top-1) تبلغ 91%.
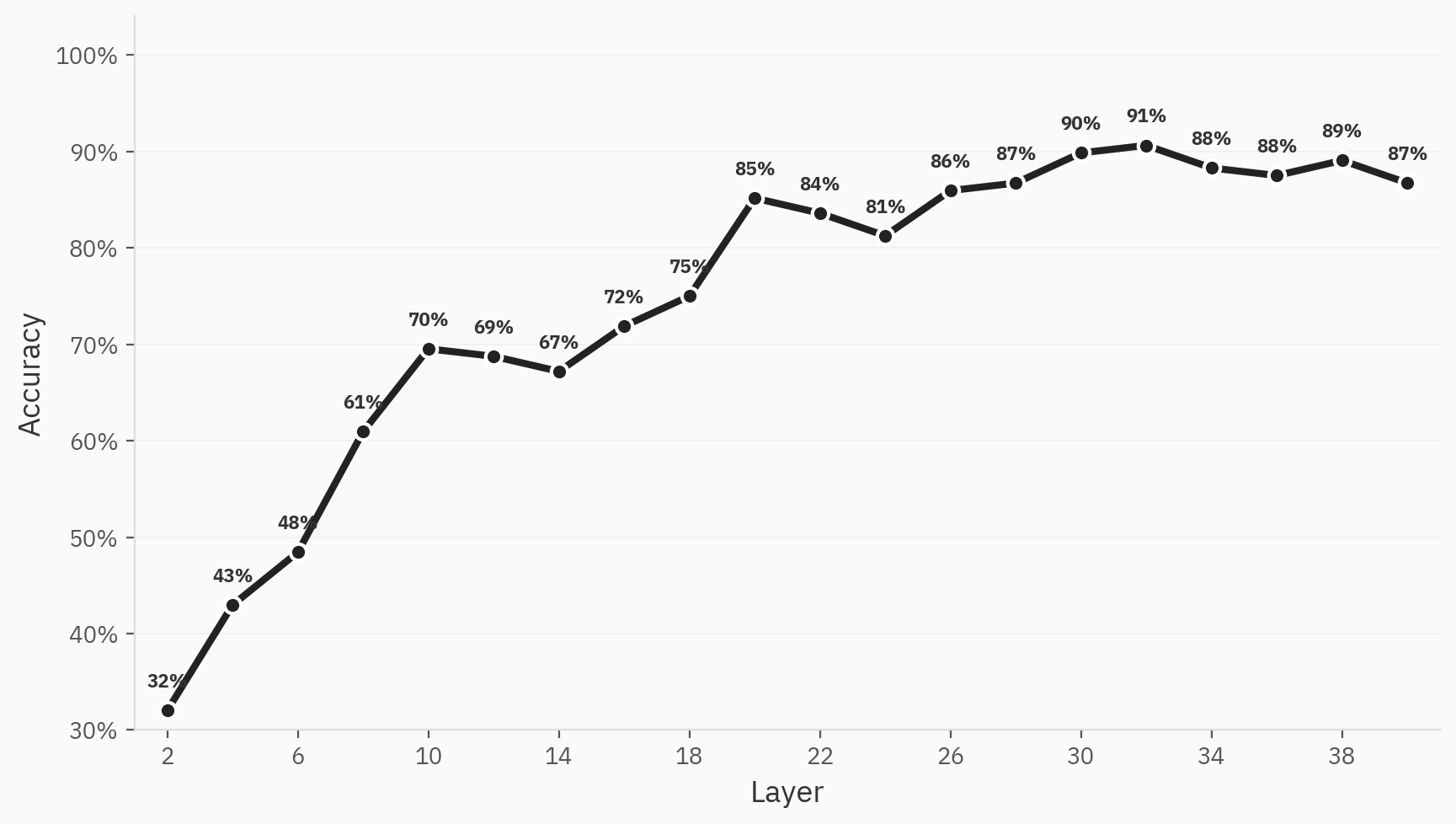
الظهور ليس مضمونًا
تضمنت تجاربنا الأولية المتعلقة بالقابلية للتفسير إجراء اختبارات على عدد من النماذج. ولدهشتنا، كان ظهور قدرة «التصنيف باستخدام النماذج اللغوية الكبيرة» أحد النتائج القليلة في هذا المشروع التي اختلفت اختلافًا جوهريًّا باختلاف النماذج.
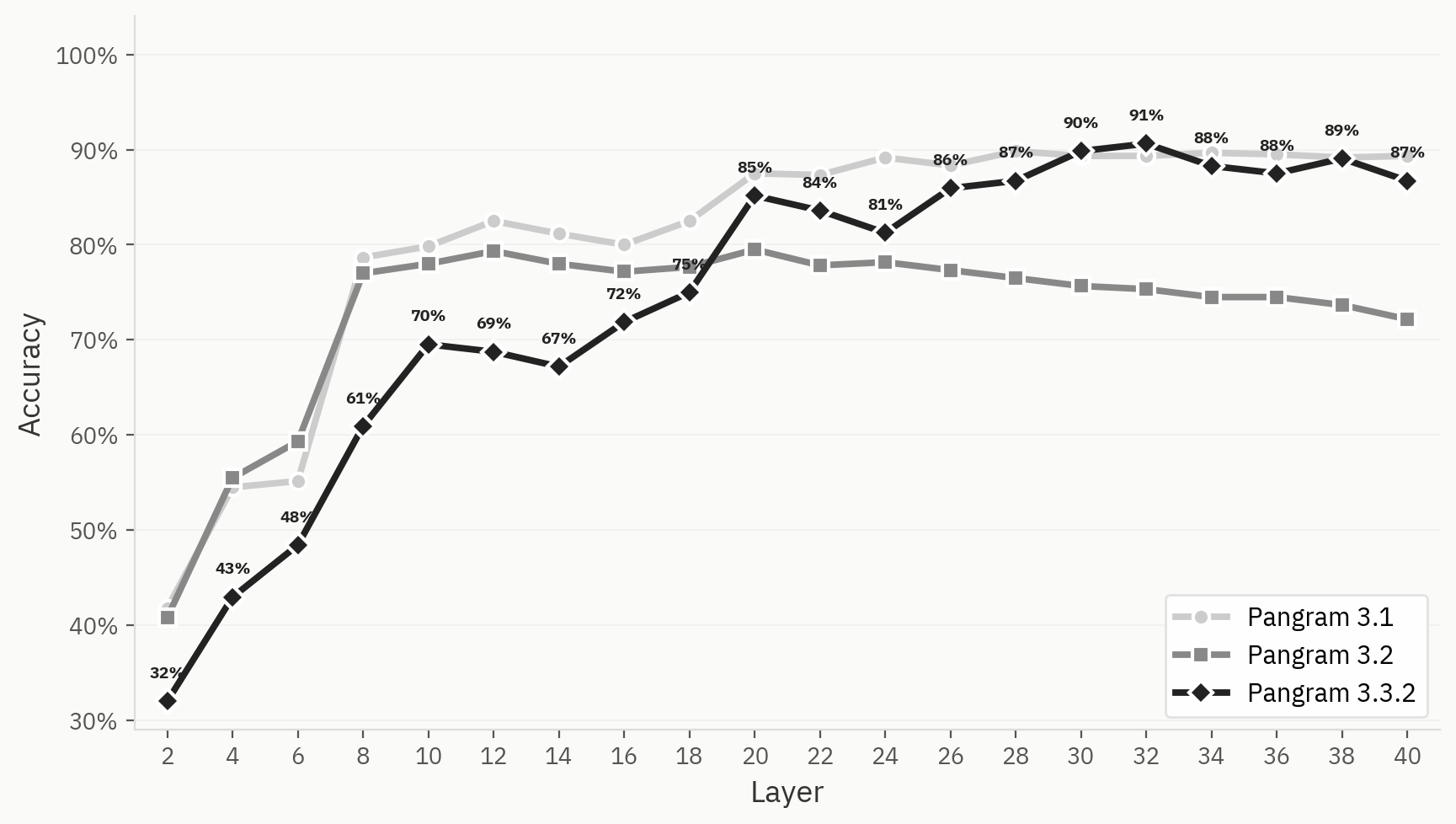
يقارن الشكل أدناه سلوك التجميع في Pangram 3.1 و3.2 و3.3.2. وعلى الرغم من أن أداء النموذج كان أفضل من أداء الإصدار 3.1 في المهمة الثنائية بين الإنسان والذكاء الاصطناعي في تقييماتنا الداخلية النهائية، فإن مجموعات النموذج بشكل عام أقل تحديدًا في Pangram 3.2 مقارنةً بـ Pangram 3.1 أو 3.3.2.
ولتوضيح هذا الاختلاف بشكل أكبر، نقوم بمقارنة أداء اختبار المصنف القائم على نماذج اللغة الكبيرة (LLM) عبر Pangram 3.1 و3.2 و3.3.2. وتحقق النماذج الثلاثة جميعها تحسناً في دقة التصنيف «top-1» في الطبقات المبكرة، لكن أداء اختبار Pangram 3.2 يبدأ في التدهور بعد الطبقة 12، بينما يظل أداء Pangram 3.1 و3.3.2 مرتفعاً.
المُؤنِّشون
تُعد «Humanizers» فئة من الأدوات التنافسية المصممة لتعديل النصوص التي يُنتجها الذكاء الاصطناعي بطريقة تتيح التهرب من أجهزة الكشف عن الذكاء الاصطناعي. لمعرفة موقع النص المُعالج بطريقة تُضفي عليه طابعًا بشريًّا مقارنةً بالنصوص البشرية ونصوص الذكاء الاصطناعي في «فضاء التنشيط»، قمنا بإنشاء مجموعة بيانات منفصلة خاصة بـ«أدوات إضفاء الطابع البشري»، تتألف من حوالي 1,900 عينة، موزعة بشكل متوازن تقريبًا على ثلاثة نماذج توليدية (Claude Sonnet 4.5، وGemini 2.5 Pro، وGPT-5)، وعشر خدمات مختلفة لإضفاء الطابع البشري، ونفس المجالات المصدرية المستخدمة في مجموعة البيانات الأصلية الخاصة بالقابلية للتفسير. ونظرًا للمخاطر التنافسية، فإننا لا نكشف عن الخدمات التي نستخدمها.
كيف يقرأ النموذج «Humanizers»
تشكل بعض العينات من مجموعة بيانات «Humanizer» تحديًا حقيقيًّا لنموذجنا في الكشف عنها. وهنا، نستخدم نفس المسبار الخطي لمهمة التمييز بين النص البشري والنص الذي أنتجته الذكاء الاصطناعي، باستثناء أن النص الذي تم إضفاء الطابع البشري عليه يُصنف على أنه من إنتاج الذكاء الاصطناعي، تمامًا كما نفعل في إعداد التدريب الأصلي. ونلاحظ أنه حتى من الطبقة الأولى، يُقرأ النص الذي تم إضفاء الطابع البشري عليه باستمرار على أنه أكثر إنسانية من نظيره المباشر الذي أنتجته الذكاء الاصطناعي.
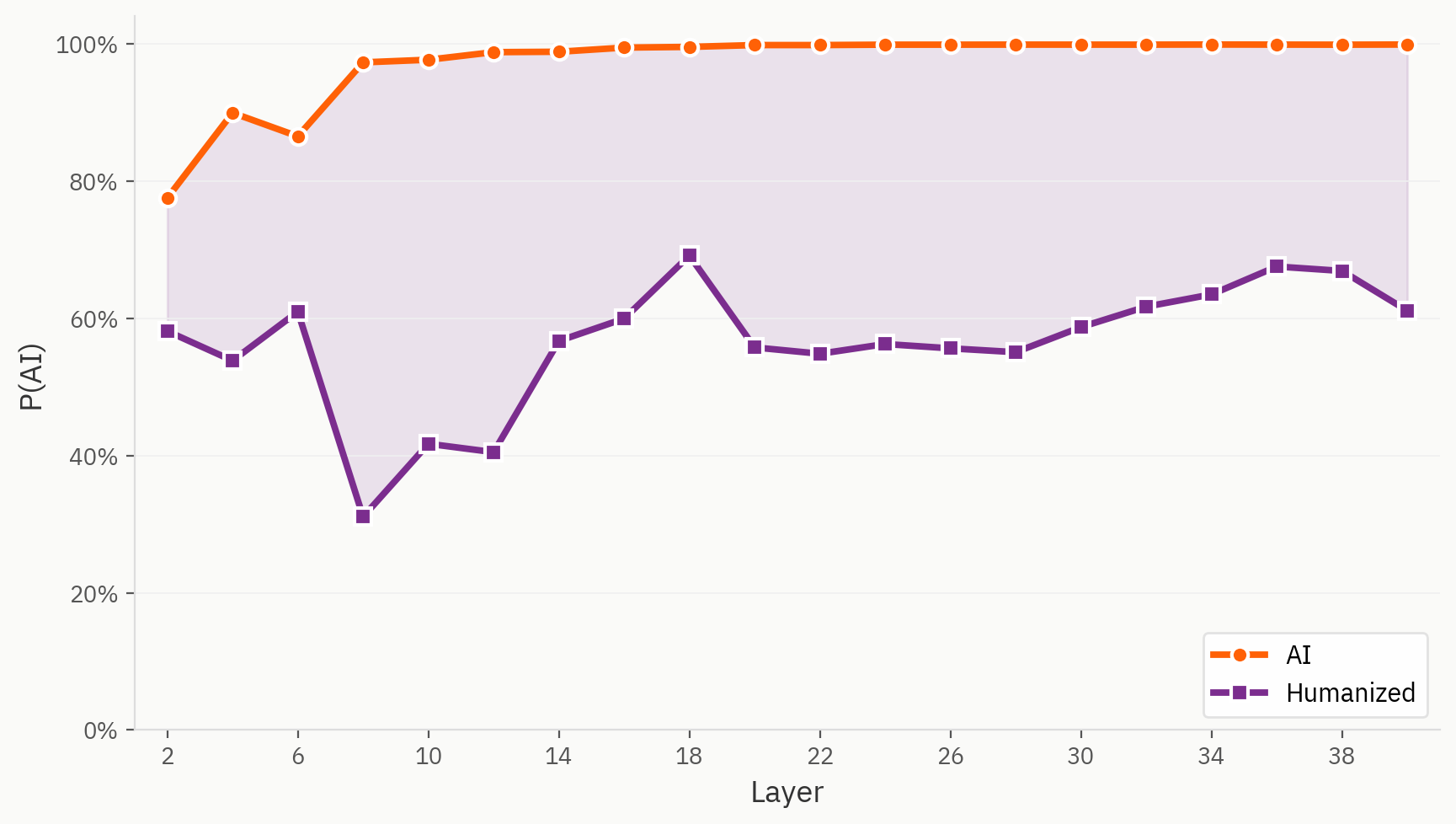
أين توجد «Humanizers» في فضاء التضمين
ومع ذلك، عندما ننظر إلى ما وراء النتائج النهائية، نجد تمثيلاً أكثر ثراءً للنص المُجسَّد. وفيما يلي، نطبق أساليبنا لتقليل الأبعاد على النصوص البشرية ونصوص الذكاء الاصطناعي والنصوص المُجسَّدة. ومن الناحية النوعية، يمكننا ملاحظة أن النصوص المُجسَّدة تميل إلى احتلال أجزاء منفصلة من فضاء التنشيط، وتشكل مجموعات خارج مناطق النصوص البشرية ونصوص الذكاء الاصطناعي.
تتمثل فرضيتنا في أنه على الرغم من عدم وجود تصنيفات للنصوص التي تمت محاكاتها على أسلوب البشر، فإن النموذج قادر على التمييز بين النصوص التي تمت محاكاتها على أسلوب البشر، والنصوص البشرية، والنصوص التي أنتجتها الذكاء الاصطناعي. ومع ذلك، في النتيجة النهائية، يضطر النموذج إلى تجاهل تلك الإشارة، ويقوم بذلك بشكل غير متسق.
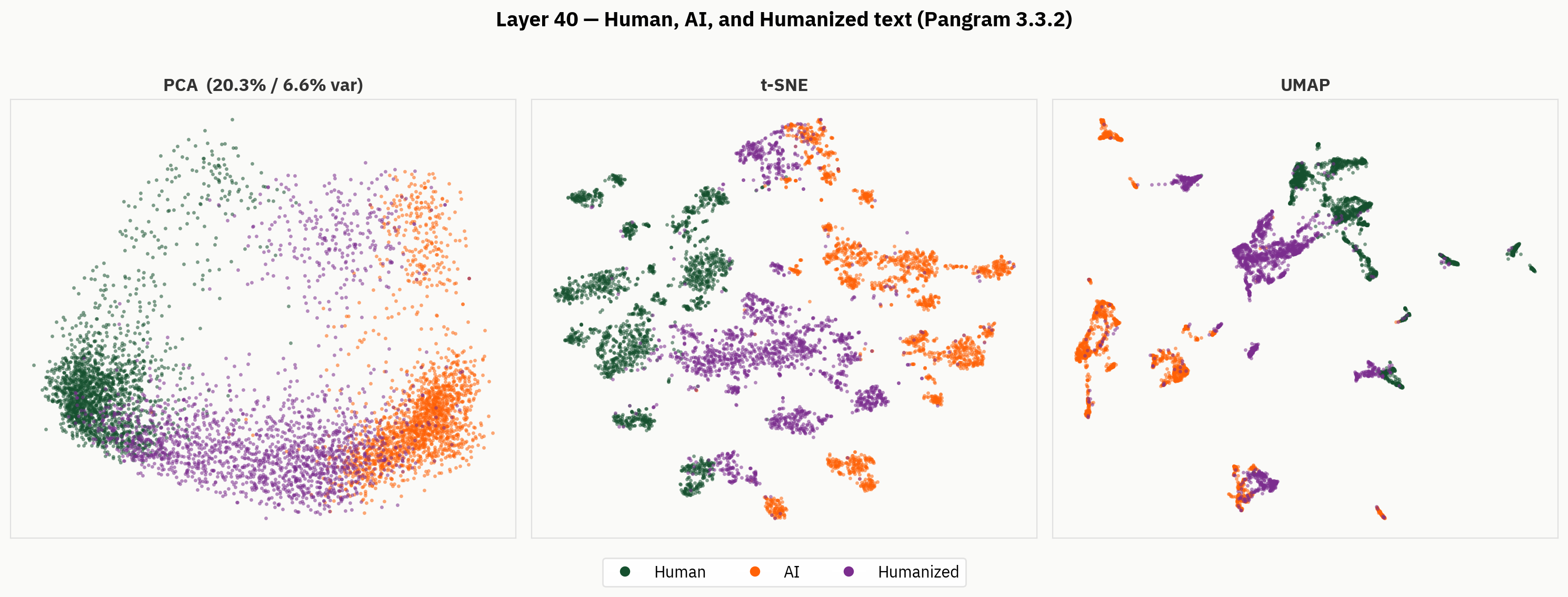
المسبار
لتحقق من صحة هذه الفرضية، قمنا بتدريب «مسبار» خطي ثلاثي الأبعاد مع تصنيفات للنصوص المولدة بالذكاء الاصطناعي، والنصوص البشرية، والنصوص المُشابِهة للنصوص البشرية. ويحقق هذا المسبار دقة «top-1» عالية في المراحل المبكرة من الشبكة، ثم تستقر النتيجة في النهاية عند 98%.
الخلاصة
تشير أبحاثنا هنا إلى أن التمثيلات الداخلية لنموذج «بانغرام» تحتوي على بنية أكثر مما تكشفه القراءة الثنائية النهائية وحدها. وعبر الطبقات المختلفة، نلاحظ انفصال الوثائق البشرية عن تلك التي أنتجها الذكاء الاصطناعي، وظهور معلومات متعلقة بعائلة النماذج، واحتلال النص المُشابِه للبشر منطقة خاصة به في فضاء التنشيط. ورغم أن هذه النتائج لا تزال في مرحلة مبكرة، إلا أنها توفر لنا خريطة مفيدة لفهم ما يتعلمه النموذج قبل أن يدمج كل شيء في درجة كشف واحدة.
يُظهر هذا المنشور الخطوات الأولى فقط في جهودنا الرامية إلى تحقيق قابلية التفسير، لكننا، داخليًّا، متحمسون ومهتمون بهذا الاتجاه البحثي.
تتمثل رؤيتنا فيما يتعلق بقابلية التفسير والتوضيح في نماذج «بانغرام» في أن هذه النماذج قادرة على:
- توفير فهم داخلي أفضل لسلوك النموذج.
- يرجى تقديم أدلة داعمة وتفسيرات أوضح لنتائج كل بانغرام على حدة.
إذا كنت باحثًا مهتمًّا بقابلية التفسير، أو بأبحاث الكشف عن الذكاء الاصطناعي، أو بأي جانب آخر من جوانب هذا العمل، فيُرجى التواصل معنا عبر البريد الإلكتروني elyas@pangram.com.
