الكشف عن الذكاء الاصطناعي لفرق التعلم الآلي والبيانات
أداة الكشف عن الذكاء الاصطناعي لمهندسي التعلم الآلي وعلماء البيانات
تحسين تدريب النماذج اللغوية الكبيرة (LLM) واختيار البيانات. تجنب انهيار النموذج من خلال تصفية النصوص الاصطناعية من مجموعات بيانات التدريب المسبق أو الضبط الدقيق بدقة تصل إلى 99.98٪ وأداء واجهة برمجة التطبيقات (API) عالي الإنتاجية.
صممه باحثون من جوجل وتيسلا وجامعة ستانفورد. تم التحقق من صحته من قبل مؤتمر ICLR وجامعة ماريلاند.
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")
















حالات الاستخدام
لا تقم بتدريب نماذجك
باستخدام بيانات غير صحيحة.
النصوص الاصطناعية تلوث قواعد البيانات العامة. قم بتصفية المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي من مسارات التدريب الخاصة بك باستخدام محرك الكشف الأكثر دقة للحفاظ على نقاء المجموعة النصية.
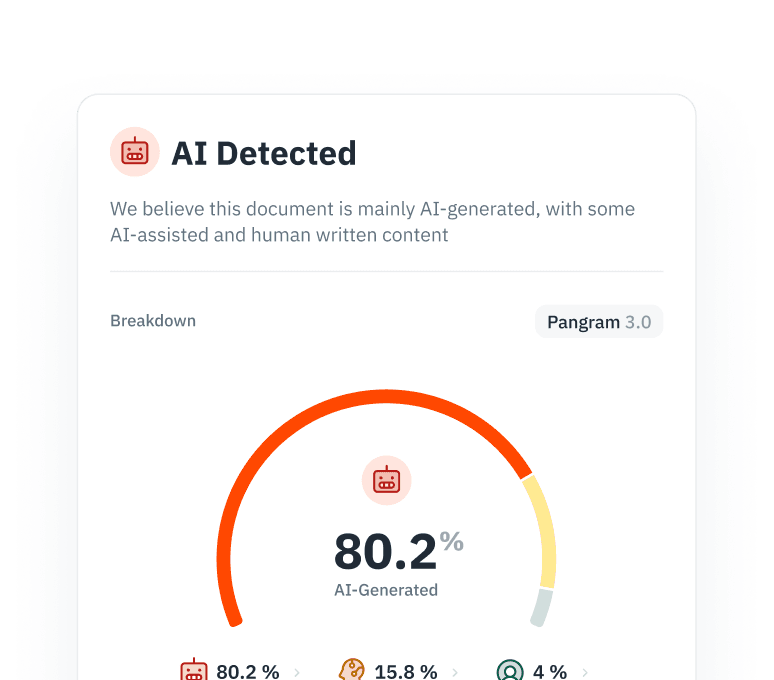
منع انهيار النموذج
يؤدي التدريب التكراري على المحتوى الذي تولده الذكاء الاصطناعي إلى تدهور أداء النموذج وتقليص التنوع. حدد المحتوى الذي كتبته الذكاء الاصطناعي وقم بتصفيته من مسارات استخراج البيانات لديك لضمان نقاء المجموعة النصية.
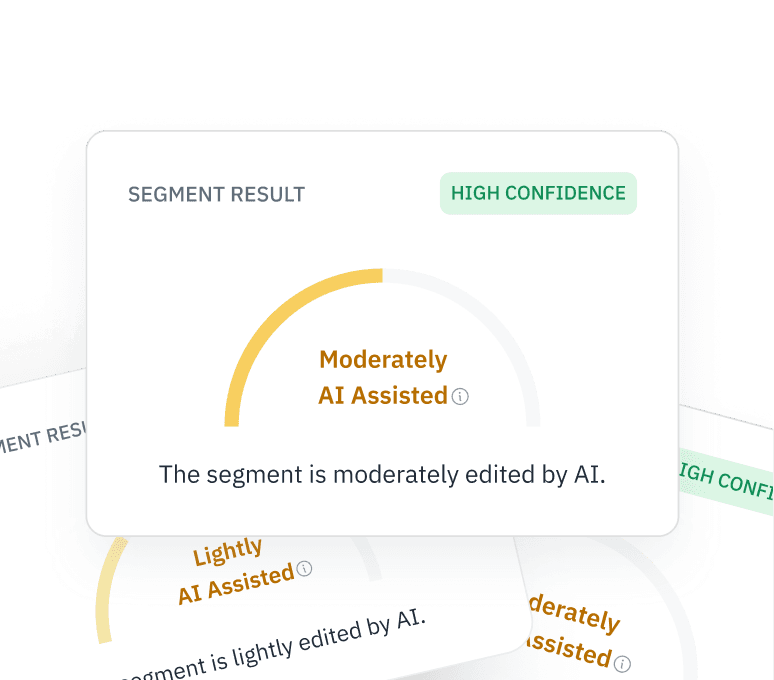
التحقق من مدخلات RLHF
تأكد من أن بيانات "التعليقات البشرية" (RLHF) الخاصة بك تأتي فعلاً من بشر. اكتشف ما إذا كان العاملون في منصات العمل الجماعي يستخدمون ChatGPT لإنشاء ردود لمهام الضبط الدقيق الخاصة بك.
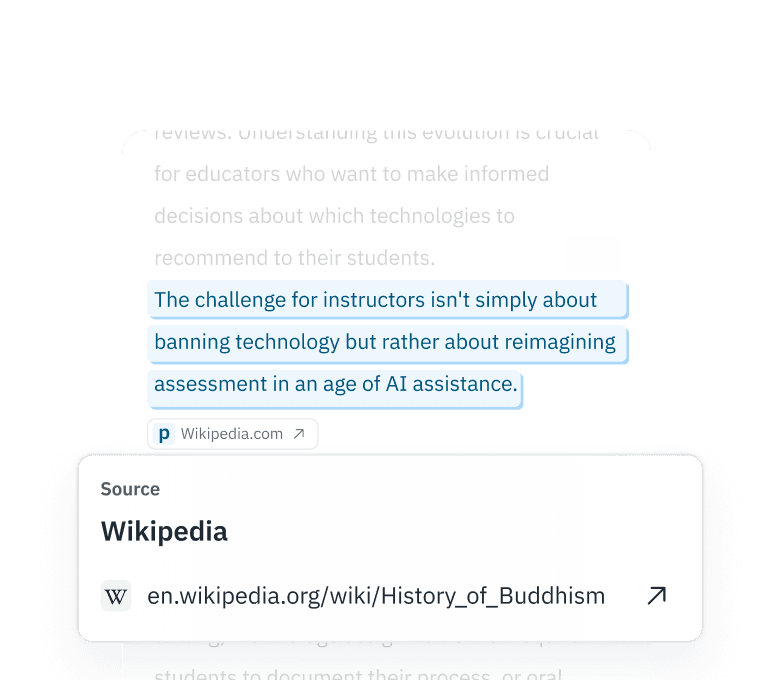
قابلية التفسير على المستوى الجزئي
لا تكتفِ بتصنيف ثنائي. توفر واجهة برمجة التطبيقات (API) المتميزة الخاصة بنا احتمالات على مستوى الرموز، مما يتيح لك الاحتفاظ بالشرائح التي تم تحريرها يدويًّا مع تجاهل "البيانات غير الدقيقة" المصطنعة بالكامل.
النهج الفني
نموذج يمكنك الوثوق به
صُمم هذا النموذج للمهندسين الذين يحتاجون إلى الثقة في عمليات تصفية البيانات التي يقومون بها. ويتناول نموذجنا مشكلات النتائج الإيجابية الخاطئة، ومقاومة الهجمات الخبيثة، ومخرجات الذكاء الاصطناعي المتطورة.

التعدين السلبي الصعب
نقوم بالتدريب على "النتائج السلبية المؤكدة" — أي النصوص البشرية التي تتسم بأسلوب رسمي أو متكرر — لتقليل النتائج الإيجابية الخاطئة إلى أدنى حد وضمان عدم استبعاد البيانات البشرية القيمة.
المقاومة في بيئة تنافسية
تتعامل Pangram مع المحتوى الذي تم إعادة صياغته أو تعديله بواسطة الذكاء الاصطناعي. وقد تم تدريب نماذجنا على التعامل مع "أدوات إضفاء الطابع البشري" والهجمات التنافسية من أجل الكشف عن النصوص الاصطناعية المُشوشة.
التأهب للمستقبل
يكتشف النصوص الصادرة عن أحدث النماذج، بما في ذلك GPT-5 وClaude 3.5 وLlama 3، مما يضمن بقاء مرشحاتك في صدارة أحدث ما توصلت إليه التكنولوجيا (SOTA).
التكامل
مصمم خصيصًا لمسار بيانات "
" الخاص بك

01
حزمة أدوات تطوير البرامج (SDK) لـ Python
قم بتثبيت pangram-sdk ودمج ميزة الكشف في مسارات Airflow أو Databricks الخاصة بك باستخدام بضع أسطر من التعليمات البرمجية فقط. تم تحسينه لتجميع الاتصالات ومعالجة الأخطاء.
عرض المستندات →
02
واجهة برمجة تطبيقات (API) لـ «
» عالية الإنتاجية
معالجة مجموعات البيانات الضخمة بزمن انتقال قصير. تدعم بنيتنا التحتية المعالجة المجمعة وتضمن معدل نقل البيانات، حيث تتعامل مع ملايين الطلبات لعمليات استخراج البيانات على نطاق المؤسسات.
الحصول على مفتاح API →
03
الأمن والامتثال لمعايير "
"
حاصلون على شهادة SOC 2 من النوع 2 بالكامل. نقدم نقاط نهاية خاصة وسياسات صارمة للاحتفاظ بالبيانات — ولا نستخدم أبدًا مدخلاتك الخاصة في التدريب.
مزيد من المعلومات →
الأسئلة الشائعة
الأسئلة الشائعة حول الكشف عن الذكاء الاصطناعي
أسئلة شائعة حول الكشف عن الذكاء الاصطناعي موجهة لمهندسي التعلم الآلي
وعلماء البيانات.
نعم. يمكنك تثبيت pangram-sdk لدمج ميزة الكشف في مسارات Airflow أو Databricks باستخدام بضع أسطر من التعليمات البرمجية فقط. تم تحسين واجهة برمجة التطبيقات (API) الخاصة بنا لتناسب عمليات استخراج البيانات المؤسسية عالية الإنتاجية، حيث تدعم ملايين الطلبات بزمن انتقال منخفض.
اكتشف المزيد
الكشف عن الذكاء الاصطناعي لـ
لكل مؤسسة
للمطورين
كشف الشفرات البرمجية التي تم إنشاؤها بواسطة الذكاء الاصطناعي للمطورين وفرق الهندسة. اكتشف الشفرات البرمجية التي تم إنشاؤها بواسطة الذكاء الاصطناعي من ChatGPT وCopilot وClaude في لغات Python وJava وC++ وغيرها.
اعرف المزيد →لإدارة المحتوى
الإشراف على المحتوى باستخدام الذكاء الاصطناعي لفرق الثقة والأمان. اكتشاف التقييمات التي تم إنشاؤها بواسطة الذكاء الاصطناعي والتعليقات المزيفة والمحتوى المصطنع على نطاق واسع عبر واجهة برمجة التطبيقات (API).
اعرف المزيد →للجامعات
الكشف الآلي عن المحتوى المزيف للجامعات ومؤسسات التعليم العالي. التحقق من واجبات الطلاب، وفحص الأبحاث المقدمة، وحماية سمعة المؤسسة.
اعرف المزيد →نظِّف بيانات التدريب الخاصة بك اليوم
تجنب انهيار النموذج، وتحقق من مدخلات RLHF، وقم بتصفية المحتوى المصطنع من مجموعات البيانات الخاصة بك بدقة تصل إلى 99.98%.
لتلقي آخر أخبارنا
