هل تستخدم كليات الحقوق أجهزة الكشف عن الغش التي تعمل بالذكاء الاصطناعي؟
جدول المحتويات
- هل تستخدم كليات الحقوق برامج الكشف عن الغش باستخدام الذكاء الاصطناعي في مقالات القبول؟
- هل تُستخدم برامج الكشف عن النصوص المكتوبة آليًا في واجبات كليات الحقوق؟
- مشكلة "اللغة القانونية": هل سأحصل على نتيجة إيجابية خاطئة؟
- التعامل مع سياسات الذكاء الاصطناعي في التعليم القانوني
- أفضل الممارسات لحماية سجلك الأكاديمي
الدراسة في كلية الحقوق تتطلب قراءة مكثفة وكتابة كثيرة. ويُعد استخدام أدوات الذكاء الاصطناعي التوليدي مثل ChatGPT أمراً مغرياً للغاية، لا سيما أنها قادرة على صياغة البيانات الشخصية وملخصات القضايا والمذكرات البحثية.
يتناول هذا الدليل كيفية تطور سياسات كليات الحقوق المختلفة، وأسباب ضرورة توخي الحذر الشديد بشأن كيفية دمج الذكاء الاصطناعي في تعليمك القانوني.
هل تستخدم كليات الحقوق برامج الكشف عن الغش باستخدام الذكاء الاصطناعي في مقالات القبول؟
الإجابة على هذا السؤال هي «نعم». تستخدم العديد من مكاتب القبول في كليات الحقوق، والمستشارون المستقلون في مجال التحضير لدراسة القانون، ومكاتب المحاماة، برامج الكشف عن الذكاء الاصطناعي بشكل فعال لضمان أن تكون الرسائل الشخصية ومقالات التنوع التي تشكل جزءًا من طلب الالتحاق من تأليف المتقدم نفسه.
تسعى كليات الحقوق إلى قبول طلاب يتمتعون بوجهات نظر فريدة وأصوات أصيلة، فضلاً عن القوة الفكرية اللازمة للنجاح في برامجها. أما المقالة التي يُنتجها ChatGPT فهي بطبيعتها عامة، وتخالف في نهاية المطاف الغرض من كتابة البيان الشخصي.
تستخدم لجان القبول في كليات الحقوق تقنيات الكشف عن استخدام الذكاء الاصطناعي منذ المراحل الأولى من عملية القبول. وتقوم شركات استشارات القبول الرائدة — مثل Gradpilot على سبيل المثال — بدمج أدوات مثل Pangram مباشرةً في عملية المراجعة التي تقوم بها. وبذلك، يمكنها تحديد ما إذا كان المتقدم يعتمد بشكل مفرط على الذكاء الاصطناعي حتى قبل تقديم المقال فعليًّا إلى LSAC.
هل تُستخدم برامج الكشف عن النصوص المكتوبة آليًا في واجبات كليات الحقوق؟
نعم، تستخدم مكاتب النزاهة الأكاديمية وأساتذة القانون أجهزة كشف تعتمد على الذكاء الاصطناعي من فئة المؤسسات، وهي مدمجة في أنظمة إدارة التعلم الخاصة بهم، لفحص جميع أنواع الواجبات الدراسية في كليات الحقوق. وتشمل بعض الواجبات التي يتم فحصها واجبات الكتابة القانونية، ومذكرات البحث، والامتحانات المنزلية.
في أي نوع من الكتابة القانونية، تُعد الدقة والمصداقية من المتطلبات الأساسية. ويُعد استخدام نماذج اللغة الكبيرة (LLMs) مثل ChatGPT أمراً مشكوكاً فيه، لأنها عرضة لاختلاق السوابق القضائية والمراجع و«الحقائق» القانونية. ولهذا السبب، فإن الاعتماد على الذكاء الاصطناعي في المهام القانونية لا يعرض المرء لخطر تهمة الانتحال فحسب، بل يعرضه أيضاً لعقوبات أكاديمية شديدة بسبب اختلاق سوابق قانونية.
يستخدم الأساتذة نتائج تحليل الذكاء الاصطناعي كأداة تشخيصية. فهم يجمعون بين التشخيص الذي يقدمه برنامج الكشف عن الذكاء الاصطناعي المخصص لكليات الحقوق ومعرفتهم الشخصية بقدرات الطالب السابقة في الكتابة، وذلك للتحقيق في حالات الغش الأكاديمي. وعند تطبيق هذا النهج المتعدد الأبعاد، يصبح من الأسهل الكشف عن استخدام الذكاء الاصطناعي.
مشكلة "اللغة القانونية": هل سأحصل على نتيجة إيجابية خاطئة؟
تشتهر أدوات الكشف عن الذكاء الاصطناعي القياسية والمجانية بوضع علامات خاطئة على النصوص شديدة الرسمية والمنظمة — مثل المذكرات القانونية، على سبيل المثال — باعتبارها من إنتاج الذكاء الاصطناعي. لكن الأمر يختلف مع الأدوات المؤسسية التي تستخدمها الجامعات لفحص الوثائق القانونية بحثًا عن آثار الذكاء الاصطناعي؛ فهذه الأدوات مدربة على تجنب هذا الخلل وتقديم تقييمات دقيقة بشأن الذكاء الاصطناعي.
"الارتباك" هو ما تبحث عنه أدوات الكشف عن الذكاء الاصطناعي القياسية والمجانية. ويُعد الارتباك مقياسًا للمفاجأة الإحصائية، مما يعني أن أدوات الكشف الأساسية عن الذكاء الاصطناعي تبحث عن قابلية التنبؤ ومستوى عالٍ من التنظيم للكشف عن استخدام الذكاء الاصطناعي.
تتميز وثائق مثل «إعلان الاستقلال» بتنظيمها الدقيق وطبيعتها المتوقعة، ولهذا السبب تصنفها العديد من أدوات الكشف الأساسية عن المحتوى المصطنع على أنها من صنع الذكاء الاصطناعي. غير أن الأدوات التي تستخدمها الجامعات تتمتع بدقة أكبر بكثير في تقييماتها.
إذا كنت طالبًا تكتب أعمالك بنفسك ولا تستخدم الذكاء الاصطناعي إلا بالطرق المسموح بها، فلا داعي للقلق. تستخدم الأدوات الجامعية المتميزة، مثل Pangram، تقنية «Hard Negative Mining» للتمييز بين الصياغة اللغوية القانونية الرسمية والنصوص التي يولدها الذكاء الاصطناعي. وينتج عن ذلك معدل إيجابي كاذب يقترب من الصفر، حيث يبلغ 1 من كل 10,000.
التعامل مع سياسات الذكاء الاصطناعي في التعليم القانوني
لكل كلية حقوق سياساتها الخاصة بها فيما يتعلق بالذكاء الاصطناعي. فبعض الأساتذة يتخذون موقفاً صارماً، حيث يُحظر استخدام الذكاء الاصطناعي تماماً. في حين أن أساتذة آخرين أكثر انفتاحاً تجاه هذه التكنولوجيا، ويقومون بدمج الذكاء الاصطناعي في مناهجهم الدراسية لتعليم المحامين المستقبليين كيفية استخدام التكنولوجيا القانونية بشكل مسؤول.
في الوقت الحالي، تعتمد المهنة القانونية الذكاء الاصطناعي التوليدي في المهام الروتينية. وتشمل بعض هذه المهام مراجعة الوثائق وتحليل العقود. ولهذا السبب، يسمح بعض الأساتذة باستخدام الذكاء الاصطناعي في عمليات العصف الذهني أو وضع الخطوط العريضة - ولكن في معظم الحالات، بشرط تقديم بيان يوضح مصدر استخدام الذكاء الاصطناعي.
إذا لم تنص مناهج كلية الحقوق أو أستاذ القانون المعني صراحةً على جواز استخدام نماذج اللغة الكبيرة (LLM) في الواجبات الدراسية، فيجب أن تفترض أن استخدامها ممنوع تمامًا. أما إذا كانت هناك سياسة خاصة بكلية الحقوق بشأن ChatGPT أو مجموعة من الإرشادات المتعلقة باستخدام نماذج اللغة الكبيرة، فيجب عليك الالتزام بهذه السياسة أو الإرشادات.
يُعتبر تقديم أي نوع من النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي دون الإفصاح عن ذلك غشًا أكاديميًا على نطاق واسع. وقد تواجه عواقب وخيمة — من أبرزها الفصل من الجامعة — إذا ثبتت إدانتك بالغش الأكاديمي.
أفضل الممارسات لحماية سجلك الأكاديمي
ينبغي على طلاب القانون والمتقدمين للالتحاق بهذه الكليات اتباع هذه الممارسات الفضلى لحماية سجلهم الأكاديمي: احرصوا دائمًا على كتابة أعمالكم بأنفسكم، وتابعوا سجل التعديلات، واحتفظوا بهذا السجل بعد إرسال الواجب، وتحققوا مسبقًا من مستنداتكم للتأكد من عدم استخدام الذكاء الاصطناعي في إجراء تعديلات نحوية بسيطة أو تبادل الأفكار أو أي غرض آخر.
بالإضافة إلى اتباع تلك الممارسات الفضلى، يجب عليك مراجعة عملك للتأكد من عدم وجود عبارات محددة تشير إلى استخدام الذكاء الاصطناعي. وتعد كلمات مثل «delve» و«tapestry» و«pivotal» من أكثر العبارات شيوعًا التي تدل على استخدام الذكاء الاصطناعي. وقد يؤدي الإفراط في استخدام هذه الكلمات إلى إثارة شكوك القراء وجعلهم يعتقدون أنك استخدمت الذكاء الاصطناعي.
إذا كنت تستخدم أي نوع من أدوات الذكاء الاصطناعي للتدقيق الإملائي، فإن أداة تدقيق متقدمة للكتابة القانونية تعتمد على الذكاء الاصطناعي، مثل Pangram، يمكنها التمييز بين عمليات التدقيق النحوي «المدعومة قليلاً بالذكاء الاصطناعي» والنصوص «المُنتجة بالكامل بواسطة الذكاء الاصطناعي». إن القدرة على التمييز بين هذين النوعين يمكن أن تساعد في إثبات أنك كتبت الحجج الأساسية الواردة في وثيقة معينة.
تراقب كليات الحقوق عن كثب استخدام الذكاء الاصطناعي لحماية نزاهة مهنة المحاماة ومن يعملون فيها.
ورغم أن الذكاء الاصطناعي يُعد أداة قوية للتوليف، إلا أنه لا يمكن أن يحل محل التفكير القانوني الدقيق والتفكير النقدي اللذين يُشترطان للحصول على درجة الدكتوراه في القانون.
تأكد من أن بيانك الشخصي أو مذكرتك القانونية من صياغتك الخاصة تمامًا. تحقق من صحة النص قبل إرساله.

أليكس رويتمان هو رئيس قسم النمو في شركة «بانغرام لابس»، وهي شركة متخصصة في الكشف عن المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي. يركز عمله على الكيفية التي يعيد بها النص الذي يُنتج بواسطة الذكاء الاصطناعي تشكيل ملامح الكتابة والتعليم والثقة في شبكة الإنترنت المفتوحة.
مقالات ذات صلة

ما مدى فعالية "بانغرام" في التعامل مع كود الذكاء الاصطناعي؟
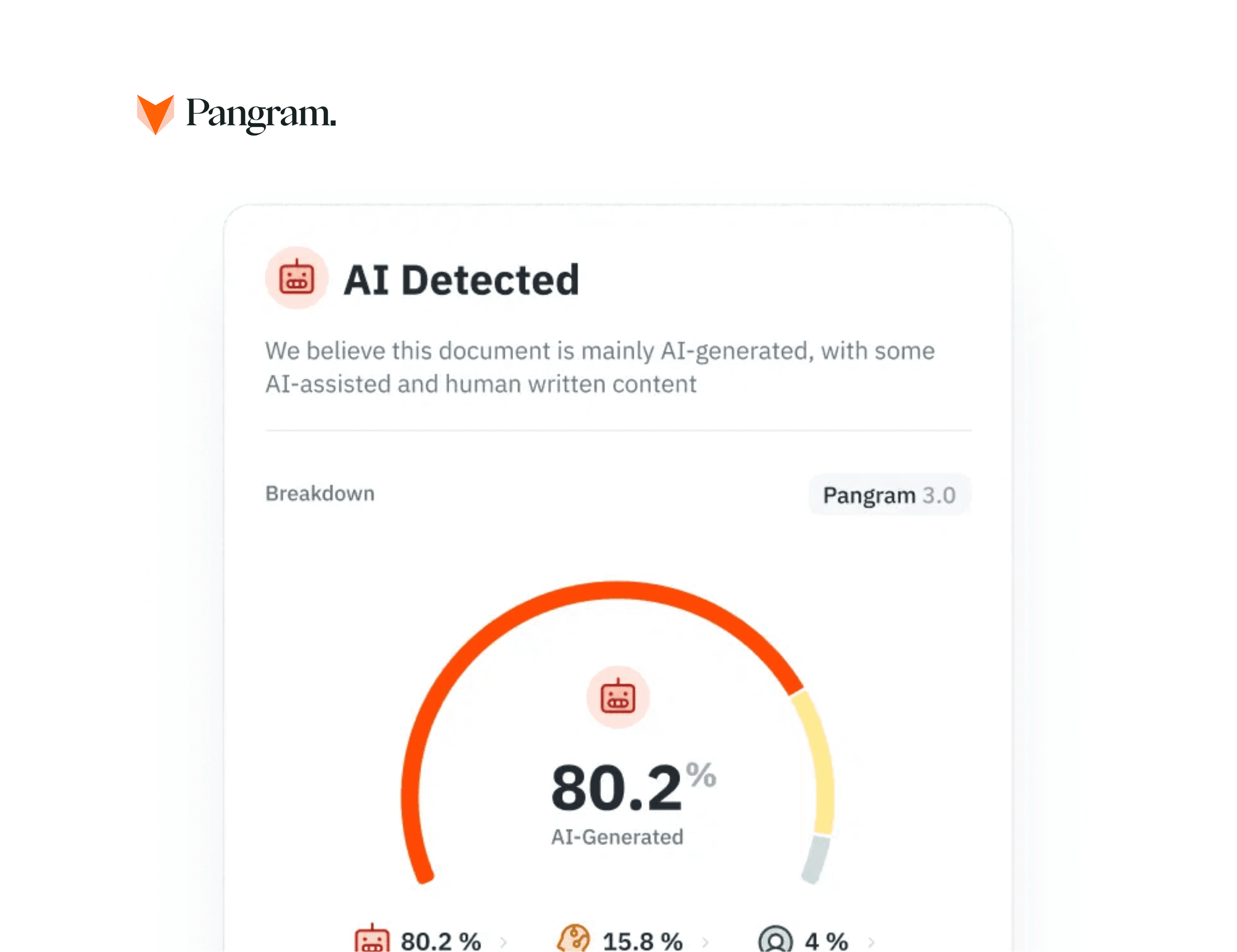
ماذا تعني درجة الكشف عن الذكاء الاصطناعي الخاصة بك؟

كاشف كود الذكاء الاصطناعي: كيفية التحقق مما إذا كان الكود قد كُتب بواسطة ChatGPT أو Copilot أو Claude

هل كتبت الذكاء الاصطناعي هذا النص؟ 4 طرق للتحقق مما إذا كان النص قد تم إنشاؤه آليًا

نهج متعدد الأبعاد للنزاهة الأكاديمية في عصر الذكاء الاصطناعي (بالتعاون مع كريس أوسترو)

تقديم أداة "بانغرام" للكشف عن الانتحال
لتلقي آخر أخبارنا
