Pangram est le seul détecteur d'IA qui surpasse les experts humains dans l'identification des contenus générés par l'IA
Nous sommes ravis de découvrir les nouveaux travaux de recherche de Jenna Russell, Marzena Karpinska et Mohit Iyyer, chercheurs de l'université du Maryland et de Microsoft, qui démontrent que Pangram est le détecteur d'IA le plus performant dans le cadre d'une comparaison, et le seul système capable de surpasser des experts humains formés à la détection de contenus générés par l'IA. Lisez l'article complet ici.

Outre l'étude de l'efficacité des détecteurs automatiques basés sur l'IA, les chercheurs se sont également penchés sur la manière dont des experts humains expérimentés repèrent les indices qui leur permettent d'identifier les signes révélateurs d'un contenu généré par l'IA. Nous estimons que ces travaux constituent une avancée majeure en matière d'explicabilité et d'interprétabilité dans le domaine de la détection de l'IA, et nous sommes impatients d'approfondir cette piste de recherche.
Dans cet article, nous vous présenterons les points forts de cette étude et ce qu'elle implique pour l'avenir de la détection des modèles de langage de grande envergure (LLM).
Former des humains à devenir des détecteurs d'IA
Nous avons déjà abordé la question de la détection des textes générés par l'IA et du test de référence humain, ainsi que la manière dont nous nous en servons pour acquérir une intuition précieuse sur les textes générés par l'IA, ce qui nous aide à développer de meilleurs modèles.
En général, quand on commence à s'entraîner à repérer les avis, les essais, les articles de blog ou les actualités générés par l'IA, on n'est pas très doué au début. Il faut un certain temps avant de commencer à déceler les indices révélateurs qui indiquent qu'un texte a été généré par ChatGPT ou un autre modèle linguistique. Par exemple, lorsque nous avons commencé à étudier les critiques, nous avons appris au fil du temps, en examinant de nombreuses données, que ChatGPT adore commencer une critique par la phrase « J’ai récemment eu le plaisir de », ou lorsque nous avons commencé à lire des récits de science-fiction générés par l’IA, ceux-ci commençaient souvent par la phrase « En l’an ». Cependant, avec le temps, nous commençons à intérioriser ces schémas et pouvons commencer à les reconnaître.
Les chercheurs se sont également demandé si l'on pouvait former des experts à repérer les articles générés par l'IA de la même manière. Ils ont formé cinq annotateurs sur Upwork à la détection de contenus générés par l'IA et ont comparé leur capacité à repérer ces contenus à l'œil nu à celle de non-experts.
Même s'il fallait s'attendre à une différence dans la capacité de ces deux groupes à repérer les textes rédigés par une IA, les chercheurs ont constaté un écart considérable. Les non-spécialistes obtiennent des résultats comparables au hasard lorsqu'il s'agit de détecter des textes générés par une IA, tandis que les experts font preuve d'une grande précision (avec un taux de vrais positifs supérieur à 90 % en moyenne).

L'une des sections qui nous a le plus intéressés était celle intitulée « Que voient les annotateurs experts que les non-experts ne voient pas ? ». Les chercheurs ont demandé aux participants d'expliquer pourquoi ils pensaient qu'un texte avait été généré par l'IA ou non, puis ils ont analysé leurs commentaires.
Voici quelques éléments d'analyse tirés directement de l'article :
« Contrairement aux experts, les non-spécialistes ont souvent tendance à se focaliser à tort sur certaines caractéristiques linguistiques. Prenons l’exemple du choix lexical : les non-spécialistes considèrent la présence de mots « sophistiqués » ou peu courants comme des indices permettant de reconnaître un texte généré par l’IA ; à l’inverse, les experts connaissent bien mieux les mots et expressions précis que l’IA utilise à outrance (par exemple, « testament », « crucial »). Les non-experts pensent également que les auteurs humains sont plus enclins à former des phrases grammaticalement correctes et attribuent donc les phrases à rallonge à l’IA, mais c’est l’inverse qui est vrai : les humains sont plus enclins que l’IA à utiliser des phrases non grammaticales ou à rallonge. Enfin, les non-experts attribuent tout texte rédigé sur un ton neutre à l’IA, ce qui entraîne de nombreux faux positifs, car l’écriture humaine formelle est elle aussi souvent neutre dans son ton. » (Russell, Karpinska et Iyyer, 2025).
En annexe, les auteurs fournissent une liste du « vocabulaire IA » couramment utilisé par ChatGPT – une fonctionnalité que nous avons récemment intégrée au tableau de bord Pangram et qui met en évidence les expressions couramment utilisées en IA !

D'après notre expérience, nous avons constaté que, bien que beaucoup pensent que l'IA utilise un vocabulaire sophistiqué et « sophistiqué », nous observons en réalité qu'elle a plutôt tendance à recourir à un vocabulaire stéréotypé et métaphorique qui n'a souvent aucun sens. Pour le dire de manière informelle, on pourrait dire que les modèles de langage (LLM) ressemblent davantage à des personnes qui essaient de paraître intelligentes, mais qui, en réalité, se contentent d'utiliser des expressions qu'elles pensent les faire passer pour intelligentes.
Résistance des détecteurs d'IA face aux modèles de pointe
Une question qui nous est souvent posée chez Pangram est la suivante : comment faites-vous pour rester à la pointe des modèles les plus récents ? Lorsque les modèles linguistiques s'améliorent, cela signifie-t-il que Pangram ne fonctionnera plus ? S'agit-il d'un jeu du chat et de la souris dans lequel les laboratoires de pointe comme OpenAI finiront par nous devancer ?
Les chercheurs se sont également posé la question et ont étudié les performances de plusieurs méthodes de détection de l'IA face à o1-pro d'OpenAI, le modèle le plus avancé publié à ce jour.
Les chercheurs ont constaté que Pangram détectait avec une précision de 100 % les sorties o1-pro, et que notre système affichait tout de même une précision de 96,7 % pour la détection des sorties o1-pro « humanisées » (nous y reviendrons dans un instant) ! À titre de comparaison, aucun autre détecteur automatisé n'atteint même les 76,7 % pour les sorties o1-pro de base.
Comment Pangram parvient-il à généraliser ainsi ? Après tout, au moment de l'étude, notre ensemble d'apprentissage ne contenait même pas de données o1-pro.
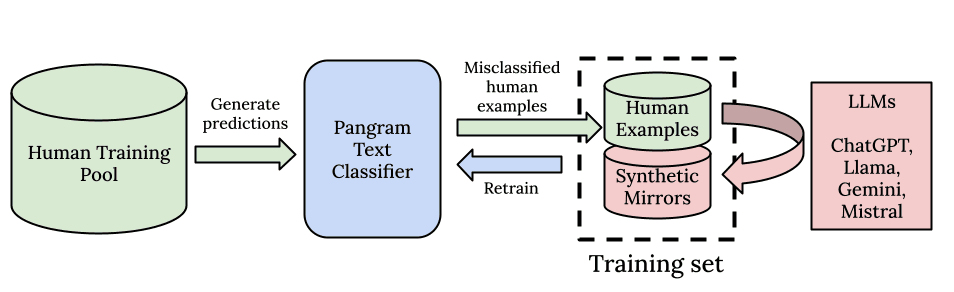
Comme pour tous les modèles d’apprentissage profond, nous croyons en la puissance de l’échelle et de la puissance de calcul. Tout d’abord, nous partons d’un modèle de base puissant, pré-entraîné sur un immense corpus d’entraînement, à l’instar des grands modèles linguistiques (LLM) eux-mêmes. Ensuite, nous avons mis en place un pipeline de données conçu pour l’échelle. Pangram est capable de reconnaître des schémas subtils à partir de son corpus d’entraînement composé de 100 millions de documents rédigés par des humains.
Nous ne nous contentons pas de constituer un ensemble de données pour les essais, les actualités ou les critiques : nous nous efforçons de rassembler le plus large éventail possible de toutes les données écrites par des humains qui existent, afin que le modèle puisse apprendre à partir d'une distribution de données de la plus haute qualité et la plus diversifiée possible, et se familiariser avec toutes sortes d'écrits humains. Nous constatons que cette approche générale de la détection par IA fonctionne bien mieux que l'approche spécialisée consistant à construire un modèle par domaine textuel.
Notre pipeline de données synthétiques et notre algorithme de recherche basé sur l'apprentissage actif viennent compléter notre ensemble de données humaines extrêmement vaste et de grande qualité. Afin d'alimenter notre algorithme en données d'IA, nous utilisons une bibliothèque exhaustive de prompts ainsi que tous les principaux modèles d'IA, qu'ils soient open source ou propriétaires, pour générer des données synthétiques. Nous utilisons des invites miroirs synthétiques, que nous avons décrites dans notre rapport technique, ainsi que l'exploration des cas négatifs (hard negative mining), qui recherche dans notre base de données les exemples présentant le taux d'erreur le plus élevé, puis crée des exemples d'IA très similaires à ceux générés par des humains, avant de réentraîner le modèle jusqu'à ce qu'il ne commette plus aucune erreur. Cette approche nous permet de réduire très efficacement les taux de faux positifs et de faux négatifs de notre modèle à zéro.
En résumé, notre généralisation repose sur l'ampleur de nos données de pré-entraînement, la diversité des invites et des modèles de langage de grande capacité (LLM) utilisés pour la génération de données synthétiques, ainsi que sur l'efficacité de nos données grâce à notre approche d'apprentissage actif et d'extraction de données négatives.
De plus, nous ne nous contentons pas de viser d'excellentes performances hors distribution, mais nous voulons également nous assurer que le plus grand nombre possible de grands modèles de langage (LLM) courants soient aussi proches que possible de la distribution. C'est pourquoi nous avons mis en place un pipeline automatisé robuste permettant d'extraire les données des modèles les plus récents, afin de pouvoir commencer à entraîner de nouveaux LLM dès leur sortie et de rester à jour. Nous constatons qu'il ne s'agit pas d'un compromis entre l'équilibre des performances sur différents modèles : nous observons qu'à chaque fois que nous introduisons un nouveau LLM dans l'ensemble d'entraînement, la généralisation du modèle s'améliore.
Avec notre système actuel, nous ne constatons pas que les modèles deviennent plus difficiles à détecter à mesure qu'ils s'améliorent. Dans de nombreux cas, les modèles de nouvelle génération sont en réalité plus faciles à détecter. Par exemple, nous avons constaté que nous étions plus précis dans la détection de Claude 3 lors de sa sortie que pour Claude 2.
Attaques visant les outils de paraphrase et d'humanisation
Dans notre récente série d'articles de blog, nous avons expliqué ce qu'est un « humaniseur d'IA » et avons également publié un modèle offrant des performances nettement améliorées en matière de humanisation de textes générés par l'IA. Nous sommes ravis de constater qu'un tiers a déjà validé nos affirmations à l'aide d'un ensemble de données composé d'articles o1-pro humanisés.
Sur le corpus de texte humanisé o1-pro, nous atteignons une précision de 96,7 %, alors que le deuxième meilleur modèle automatisé ne parvient à détecter que 46,7 % du texte humanisé.
Nous atteignons également une précision de 100 % sur les textes générés par GPT-4o qui ont été paraphrasés phrase par phrase.
Conclusion
Nous sommes ravis de constater les excellents résultats obtenus par Pangram dans le cadre d'une étude indépendante portant sur les capacités de détection de l'IA. Nous sommes toujours heureux de soutenir la recherche universitaire et offrons un accès libre à tous les chercheurs qui souhaitent étudier notre détecteur.
Outre l'évaluation comparative des performances des détecteurs automatisés, nous nous réjouissons de voir que la recherche commence également à s'intéresser à l'explicabilité et à l'interprétabilité de la détection par IA : il ne s'agit plus seulement de déterminer si un texte a été rédigé par une IA, mais aussi de comprendre pourquoi. Nous avons hâte de vous expliquer plus en détail comment ces résultats peuvent aider les enseignants et les éducateurs à repérer à l'œil nu les textes générés par l'IA, et comment nous comptons intégrer ces recherches dans des outils de détection automatisée plus explicables.
Pour plus d'informations, rendez-vous sur notre site web pangram.com ou contactez-nous à l'adresse info@pangram.com.

Bradley est chercheur en intelligence artificielle et spécialiste du développement de produits basés sur l'apprentissage profond dans le secteur industriel. Il a récemment dirigé le groupe de recherche sur l'apprentissage profond chez Absci, une entreprise spécialisée dans la découverte de médicaments par l'IA générative, et faisait auparavant partie de l'équipe principale chargée de la vision par ordinateur chez Tesla Autopilot.
Pendant ses études supérieures, Bradley a rédigé plusieurs articles de recherche sur l'apprentissage profond au sein du Stanford Vision Lab. Il est titulaire d'une licence en physique et d'un master en intelligence artificielle de l'université de Stanford. Outre l'IA, il s'intéresse également à l'éducation et à la philosophie, et est un passionné de golf.
Lectures complémentaires

Nouveaux niveaux de produits Pangram

Dans quelle mesure Pangram est-il capable de détecter des modèles de raisonnement ?

Présentation de la nouvelle page de résultats

Les détecteurs d'IA sont-ils efficaces contre GPT-5 ?
Rapport technique sur la détection de textes générés par l'IA avec une grande précision

Comment détecter l'IA en Python
