Questo post è stato pubblicato anche sul Substack dell'autore. Seguitelo qui!
Informativa sui finanziamenti: i crediti OpenRouter sono stati forniti da Pangram per lo svolgimento di questa ricerca, e l’idea originale alla base della stessa è stata suggerita da Max Spero, amministratore delegato di Pangram. Ho fatto del mio meglio per mantenere l’imparzialità e quanto riportato di seguito riflette le mie opinioni sincere.
Quando ChatGPT è stato lanciato per la prima volta, ci sono stati diversi casi di grande risonanza in cui alcune persone hanno tentato di utilizzarlo come rilevatore di IA, ovvero inserendo un testo e chiedendogli senza mezzi termini se fosse stato generato dall’intelligenza artificiale. Il Washington Post ha riportato la notizia di un professore della Texas A&M che aveva dato a diversi studenti un voto pari a zero sulla base del fatto che ChatGPT rivendicava la paternità dei loro elaborati. Una professoressa assistente dell’Università di San Francisco ha detto ai suoi colleghi: «Tutto quello che dobbiamo fare è chiedere “Hai scritto tu questo?” e poi copiare e incollare il lavoro dello studente nella casella di comando» – solo per poi scrivere un post sul blog riguardo all’assurdo numero di falsi positivi che questo metodo generava. Più recentemente, quando il vincitore di un concorso di racconti brevi indetto da Granta è stato accusato di aver utilizzato l’IA, Granta ha impiegato Claude per verificare se il testo vincitore fosse effettivamente stato generato dall’IA.
Sebbene questi tentativi possano sembrare ingenui, e forse un po’ divertenti – dopotutto, ChatGPT non ha modo di verificare di aver generato un testo e deve tirare a indovinare basandosi sulle sensazioni (proprio come farebbe un essere umano) – Ma non è una deduzione irrazionale per una persona non esperta di tecnologia: ChatGPT è in grado di scrivere storie come un autore umano, e gli autori umani sono in grado di riconoscere/ricordare le proprie opere, quindi perché non dovrebbe esserlo anche ChatGPT? Inoltre, esistono altre forme di verifica della generazione da parte dell’IA, come SynthID per immagini, audio e video. Perché non ce ne sia una per il testo? La risposta, ovvero che SynthID richiede una filigrana rilevabile, non è ovvia. A rendere il tutto ancora più confuso, se si chiede a Gemini se un’immagine sia generata dall’IA, risponde semplicemente: «Sì, la maggior parte o tutta questa immagine è stata generata o modificata utilizzando l’IA di Google» – oscurando la verifica tramite filigrana di SynthID e dando l’impressione che Gemini possa semplicemente dedurlo visivamente in base alle sensazioni. Quindi, per chiarire tutta questa ambiguità:
- I modelli di linguaggio di grandi dimensioni (LLM) non possiedono una memoria episodica relativa alla generazione di un testo, pertanto non sono in grado di identificarlo in quanto ne sono gli autori.
- Esistono effettivamente sistemi di filigranatura del testo — come SynthID Text di Google — ma richiedono che il testo sia stato generato da un sistema di IA partecipativa con la funzione di filigranatura abilitata. Pertanto, non si tratta di una soluzione universale per testi arbitrari.
- Pertanto, il rilevamento di testi generati dall'IA deve avvenire tramite l'intuizione: che si tratti dell'intuizione umana, di algoritmi di apprendimento automatico addestrati (come Pangram) o dell'intuizione di un modello di linguaggio di grandi dimensioni (LLM).
E, storicamente, le intuizioni dei modelli di linguaggio di grandi dimensioni (LLM) sono state scarse! Ciò ha perfettamente senso: la prima generazione di LLM destinati al grande pubblico – GPT-3.5 e GPT-4, forse anche Claude 3 – è stata addestrata su dati precedenti all’invasione dell’intelligenza artificiale su Internet. La loro esposizione a testi generati dall’IA era probabilmente limitata, se non inesistente, quindi è ovvio che le loro prestazioni in modalità “zero-shot” fossero scarse. Ma questo solleva una domanda: gli LLM più moderni, addestrati su dati più recenti, potrebbero forse avere un’intuizione migliore?
Adam Kucharski ha approfondito la questione sul suo Substack e i primi risultati sono promettenti: Claude è riuscito a distinguere due incisi di racconti generati dall’IA da uno scritto da un essere umano, a identificare dieci racconti scritti da GPT-5.5 come opera dell’IA con una probabilità superiore all’80% e ha attribuito una probabilità non superiore al 22% di essere stati scritti dall’IA a dieci racconti estratti dagli scritti personali di Kucharski. Ancora più promettente è il fatto che Kucharski abbia chiesto a GPT-5.5 di «migliorare» ciascuno dei suoi dieci racconti: cinque di essi sono passati dall’essere scritti da un essere umano a essere generati dall’IA. Si tratta di ventitré successi nella classificazione diretta dell’IA e di cinque successi su cinque tentativi falliti nella classificazione della revisione effettuata dall’IA.
Ciò solleva la domanda: quando è emersa questa capacità di rilevamento dell’IA? Per verificarlo, ho utilizzato il dataset open source editlens-iclr di Pangram, che contiene numerosi esempi di brani scritti da esseri umani e di loro equivalenti generati dall’IA. Per iniziare, ho selezionato un campione pilota di 100 brani – 50 scritti da esseri umani e 50 generati dall’IA – e ho valutato una serie di modelli, sia storici che attuali, per verificarne l’accuratezza in modalità zero-shot. Per massimizzare la classificazione basata sulle «vibes» — l’intuizione che stavo cercando di rilevare — ho condotto questo esperimento disattivando il ragionamento, ove possibile, e fornendo istruzioni rigorose di rispondere con una sola parola. Ciò ha portato al seguente formato di prompt zero-shot:
 Formato del prompt "zero-shot"
Formato del prompt "zero-shot"
I risultati sono riportati di seguito e sono davvero sorprendenti:
 Prestazioni zero-shot per data di rilascio
Prestazioni zero-shot per data di rilascio
Notiamo che GPT-4 parte dal 52% – un risultato non superiore al caso – in linea con l’intuizione del 2023/2024 secondo cui l’IA non fosse in grado di riconoscere i propri testi (GPT-3.5-Turbo ha ottenuto il 49% e non è incluso nel grafico sopra riportato). Facciamo un salto in avanti alla primavera e all’estate del 2025: GPT-4.1 raggiunge il 71%, Sonnet 4 il 62% e Opus 4 il 69%. Segue poi una rapida ascesa delle capacità dalla metà dell’estate del 2025 all’inizio del 2026, quando sia la serie GPT che quella Claude raggiungono precisioni superiori al 90% su questo campione di 100 esempi. Questo balzo si verifica, sebbene con un leggero ritardo, anche per la serie Qwen Plus, la cui precisione schizza dal 55% della versione Qwen3.5 Plus all’83% di Qwen3.6 Plus, rilasciata solo due mesi dopo.
Ci si potrebbe chiedere se questo vantaggio dello “zero-shot” sia dovuto principalmente alla familiarità con i contenuti generati dall’IA o semplicemente a un divario di intelligenza — con i modelli all’avanguardia, più intelligenti, che fungono da classificatori più efficaci. Per verificarlo, possiamo osservare come l’inserimento di esempi “few-shot” (tratti dal set di addestramento e, ovviamente, randomizzati per ogni domanda) nel contesto modifichi l’accuratezza. Ciò porta il nostro formato di prompt al seguente modello “few-shot”:
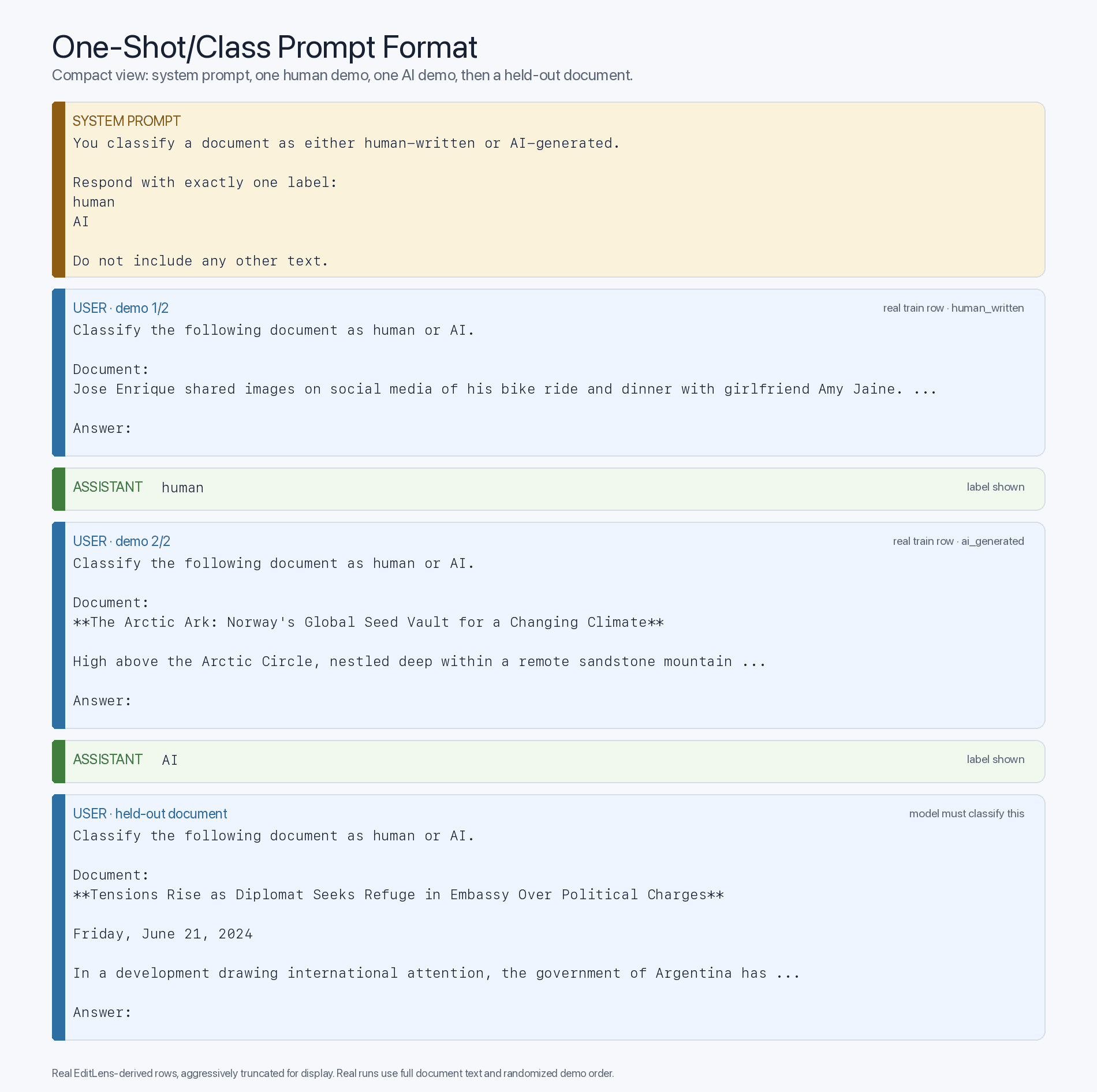
Se, in questo formato di prompt a pochi shot, i modelli più datati migliorano notevolmente grazie all’esposizione alle corrette mappature tra input ed etichette, allora il collo di bottiglia è l’esposizione durante il pre-addestramento, non l’intelligenza. Ed è esattamente ciò che osserviamo:
 Grafico ICL GPT per domanda
Grafico ICL GPT per domanda
Mentre GPT-4 in modalità zero-shot ottiene solo il 52%, in modalità 4-shot1 raggiunge l’85%. È chiaro che GPT-4 è in grado di apprendere nel contesto a distinguere tra testi generati dall’IA e testi scritti da esseri umani: semplicemente non possiede la conoscenza innata e pre-addestrata su come farlo. Ciò è sottolineato dal fatto che le prestazioni in modalità zero-shot migliorano in modo quasi monotono con l’avanzare delle generazioni del modello, mentre quelle in modalità few-shot rimangono pressoché invariate dopo ~GPT-5.1 e registrano un aumento significativo fino al 99% solo con GPT-5.5. Queste prove suggeriscono fortemente che l’ingrediente mancante affinché i modelli di linguaggio di grandi dimensioni (LLM) diventino rilevatori di IA zero-shot anche solo vagamente decenti fosse semplicemente una quantità adeguata di dati di pre-addestramento (o esempi di riferimento contestuali), e non un vincolo intrinseco alla loro natura o intelligenza.
Per approfondire l’impatto dell’apprendimento in contesto con pochi esempi (few-shot) sulla capacità di rilevamento dell’ICL, avevo bisogno di un set più difficile da cui estrarre un segnale più forte: dopotutto, se i modelli all’avanguardia raggiungono il 95% in una valutazione di 100 domande, smettono di essere utili. Per costruire questo set difficile, ho filtrato il dataset Pangram per mantenere solo gli esempi che hanno ingannato Qwen 3.7 Plus due volte (a temp=0,7). Ho così ottenuto 3.503 campioni generati dall’IA e 763 campioni scritti da esseri umani, che ho poi bilanciato per classe (tramite campionamento casuale uniforme) per produrre il dataset finale di difficoltà elevata composto da 763 campioni generati dall’IA e 763 campioni scritti da esseri umani.
Ho valutato sia Sonnet 4.6 che GPT-5.5 su questo dataset complesso, con 0, 1, 2, 4 e 8 shot, sia con il ragionamento disattivato che attivato (impegno medio per GPT-5.5, ragionamento esteso semplice per Sonnet 4.6 per motivi di rapporto costo-efficacia):
 Tabella "Sonnet 4.6" ripulita
Tabella "Sonnet 4.6" ripulita
 Grafico GPT-5.5 ripulito
Grafico GPT-5.5 ripulito
Si nota che GPT-5.5 supera di gran lunga Sonnet 4.6 in termini di prestazioni zero-shot — cosa prevedibile, dato che GPT-5.5 è stato lanciato nell’aprile 2026 e Sonnet 4.6 nel febbraio 2026. È degno di nota il fatto che questo divario si riduca notevolmente con l’ICL: mentre (con il ragionamento disattivato) GPT-5.5 ottiene l’86,8% in modalità zero-shot contro il 72,9% di Sonnet 4.6, con 8 shot GPT-5.5 raggiunge il 96,2% contro il 93,8% di Sonnet 4.6. Ciò rafforza ulteriormente l’idea che gran parte del rilevamento dell’IA sia un’abilità che, come quasi ogni altro tipo di classificazione testuale, può essere acquisita nel contesto.
È degno di nota il fatto che, mentre il ragionamento comporta un aumento significativo di alcuni punti percentuali per GPT-5.5, aiuta realmente Sonnet 4.6 solo nel regime zero-shot (con un +2,2%) e, successivamente, o ha un effetto quasi nullo o è appena percettibile. I test statistici confermano questa osservazione: dopo la correzione di Bonferroni, il beneficio derivante dal ragionamento per GPT-5.5 rimane statisticamente significativo a 0, 1, 2 e 8 shot, mentre Sonnet 4.6 mostra un effetto significativo solo a zero shot.
Ciò sembra indicare che, sebbene l’elaborazione in fase di test possa essere d’aiuto per la classificazione della scrittura generata dall’IA, solo alcune famiglie di modelli dispongono della capacità di applicarla efficacemente rispetto all’intuizione immediata, e i vantaggi non sono enormi rispetto alla semplice fornitura di un maggior numero di esempi contestualizzati da cui imparare. In futuro si potrebbe testare GPT-5.5 a livelli di ragionamento elevati o molto elevati per verificare se i vantaggi continuino a manifestarsi.
In sintesi, abbiamo visto che i moderni modelli di linguaggio (LLM) sono in grado di distinguere con successo i testi generati dall’IA da quelli scritti dall’uomo, che questa capacità è probabilmente dovuta a una maggiore esposizione ai contenuti generati dall’IA durante il pre-addestramento e che essa trae un leggero vantaggio dalla potenza di calcolo in fase di test, ma un grande vantaggio da un maggior numero di esempi contestualizzati (al punto che i modelli di linguaggio più datati, come GPT-4, possono apprendere questa capacità partendo da una linea di base “zero-shot” a livello casuale). Ciò contraddice la precedente narrativa secondo cui ChatGPT non fosse in grado di stabilire se un testo fosse stato generato dall’IA. Tuttavia, nella pratica continuerei a non utilizzarli come rilevatori di IA: sul set di test difficile, il modello con le migliori prestazioni — GPT-5.5 con ragionamento medio — registra un tasso di falsi positivi del 4,59%, il che è inaccettabile anche per un uso occasionale (per contestualizzare, si noti che uno studio recente ha rilevato che il tasso medio di falsi positivi di cinque annotatori umani esperti era del 5,6%, ma un insieme di questi annotatori presentava un FPR pari allo 0%). Se state cercando un rilevatore affidabile, vi consiglierei Pangram, con le avvertenze discusse nel mio articolo «In Defense of Pangram ». A prescindere da ciò, trovo comunque questa capacità piuttosto intrigante – e ho ritenuto importante documentarla, dato che negli ultimi anni l’opinione comune è stata che i modelli di linguaggio di grandi dimensioni (LLM) fossero del tutto incapaci di rilevare i testi generati da altri LLM. È invece più corretto considerare gli LLM come aventi un livello di rilevamento dei testi generati dall’IA che va da “buono” a “esperto”. Sono abbastanza accurati, ma presentano tassi di falsi positivi dell’ordine dell’1% che rendono le loro segnalazioni inattuabili.
Note a piè di pagina
-
Si noti che in questo caso, con “4-shot” si intendono 4 esempi generati dall’IA e 4 esempi generati dall’uomo, non 4 esempi in totale. ↩

Nathan Breslow — noto online con lo pseudonimo di N8Programs — è uno studente universitario alla Johns Hopkins dove studia matematica applicata. Si occupa inoltre di apprendimento contestuale nei modelli linguistici di grandi dimensioni (LLM) presso l’Intelligence Amplification Lab, contribuisce allo sviluppo di framework di inferenza locale e si occupa del pre-addestramento di modelli linguistici su modalità esotiche. Le opinioni qui espresse sono esclusivamente sue.
Altre letture

Come riconoscere le recensioni generate dall'intelligenza artificiale

L'intelligenza artificiale sta scrivendo romanzi premiati

In che modo Gradpilot utilizza Pangram per aiutare gli studenti a trovare la propria voce

Qual è il rilevatore di IA più preciso? 30 strumenti testati (2026)
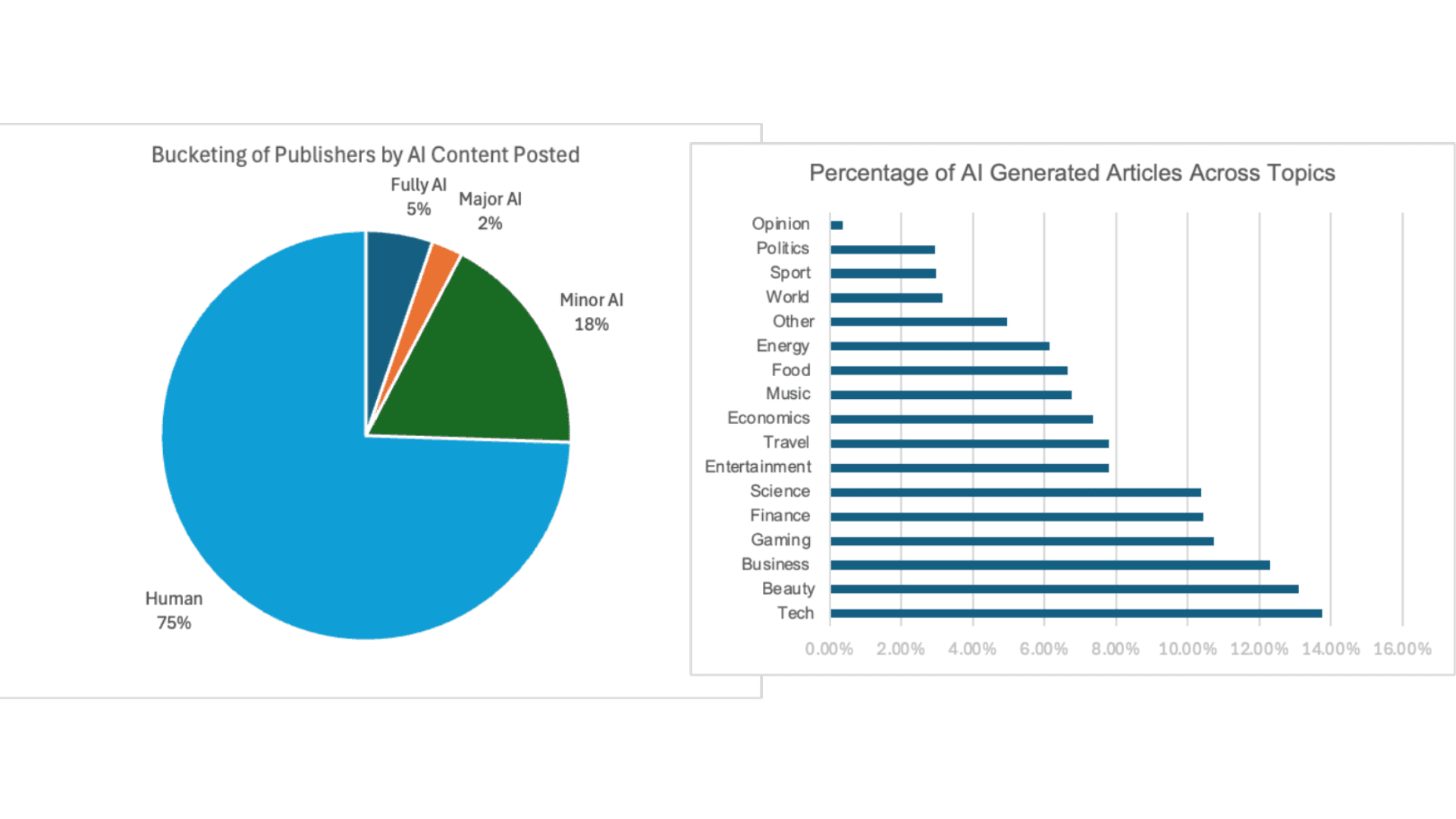
Ogni giorno vengono pubblicati 60.000 articoli di cronaca generati dall'intelligenza artificiale

Come si posiziona Pangram rispetto a GPTZero?
per ricevere i nostri aggiornamenti
