Rilevamento tramite IA per i team di ML e dati
Rilevatore di IA per ingegneri di ML e data scientist
Ottimizza l'addestramento dei modelli LLM e la selezione dei dati. Previeni il collasso del modello filtrando il testo sintetico dai tuoi set di dati di pre-addestramento o di fine-tuning con una precisione del 99,98% e prestazioni API ad alta velocità.
Sviluppato da ricercatori di Google, Tesla e Stanford. Convalidato dall'ICLR e dall'Università del Maryland.
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")marchi internazionali

















Casi d'uso
Non addestrare i tuoi modelli
utilizzando dati di scarsa qualità.
I testi sintetici stanno contaminando i set di dati pubblici. Filtra i contenuti generati dall'IA dalle tue pipeline di addestramento utilizzando il motore di rilevamento IA più accurato per preservare la purezza del corpus.
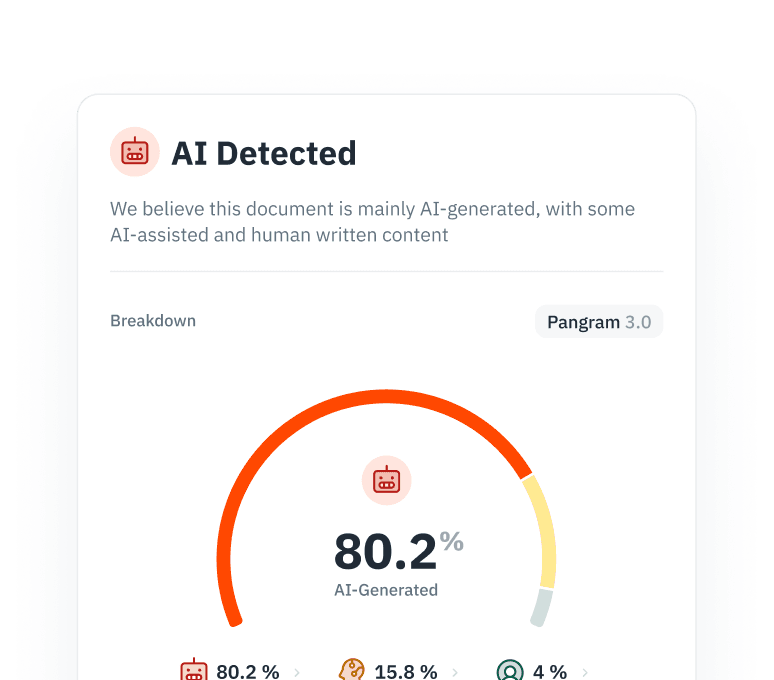
Prevenire il collasso del modello
L'addestramento ricorsivo su contenuti generati dall'IA compromette le prestazioni e la diversità del modello. Identificate e filtrate i contenuti scritti dall'IA dalle vostre pipeline di scraping per garantire la purezza del corpus.
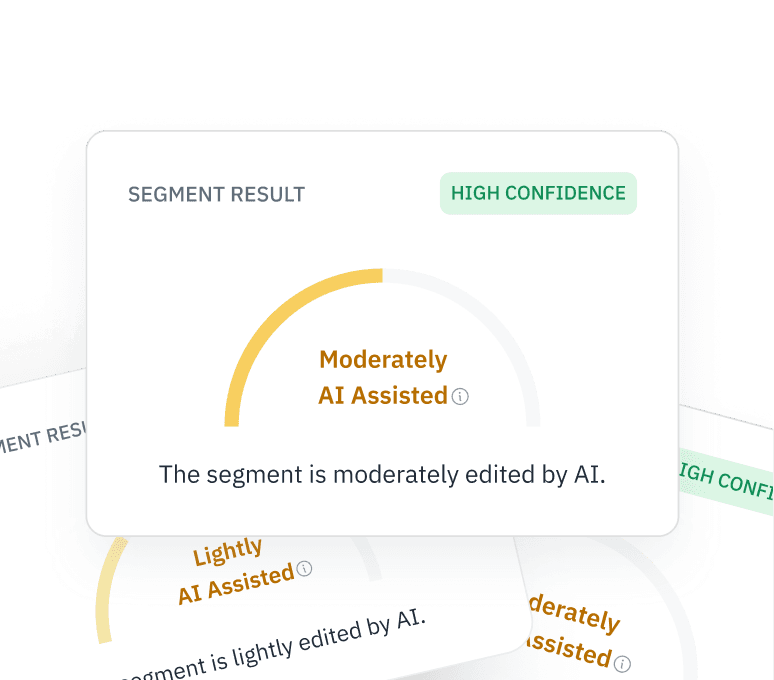
Verifica degli input RLHF
Assicurati che i tuoi dati di feedback umano (RLHF) provengano effettivamente da esseri umani. Verifica se i collaboratori della piattaforma di crowdsourcing utilizzano ChatGPT per generare risposte per le tue attività di messa a punto.
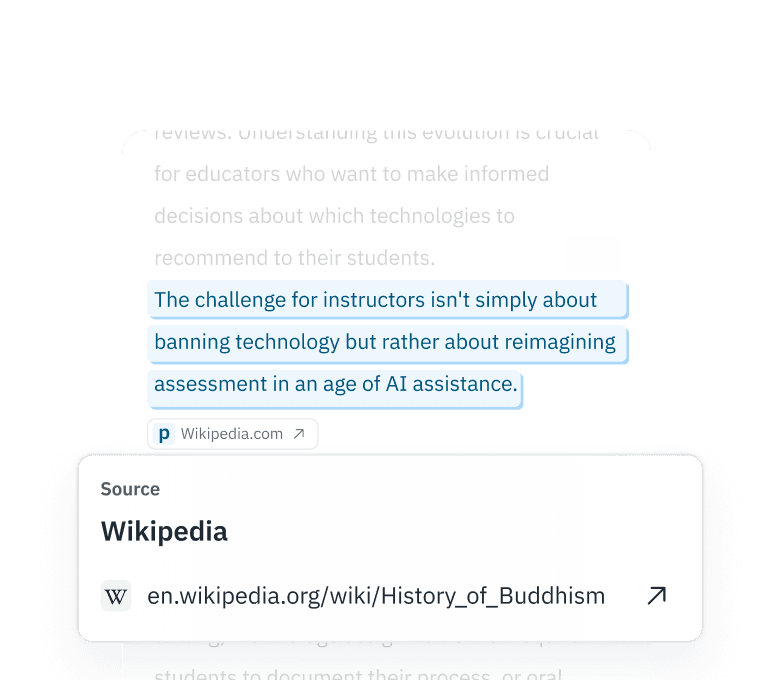
Interpretabilità granulare
Non accontentarti di un'etichetta binaria. La nostra API Premium restituisce probabilità a livello di token, consentendoti di conservare i segmenti revisionati manualmente ed eliminare i contenuti "slop" completamente sintetici.
Approccio tecnico
Un modello di cui ti puoi fidare
Progettato per gli ingegneri che hanno bisogno di poter contare sulla affidabilità del filtraggio dei dati. Il nostro modello affronta i falsi positivi, la robustezza contro gli attacchi avversari e l'evoluzione dei risultati generati dall'intelligenza artificiale.

Estrazione con filtro negativo rigido
Ci alleniamo sui "negativi certi" — testi scritti da esseri umani caratterizzati da uno stile formale o ripetitivo — per ridurre al minimo i falsi positivi e garantire che non vengano scartati dati umani preziosi.
Robustezza agli attacchi avversari
Pangram gestisce contenuti generati dall'intelligenza artificiale che sono stati parafrasati o modificati. I nostri modelli sono addestrati a riconoscere gli "humanizer" e gli attacchi avversari per individuare i testi sintetici occultati.
A prova di futuro
Rileva il testo generato dai modelli più recenti, tra cui GPT-5, Claude 3.5 e Llama 3, garantendo che i tuoi filtri rimangano all'avanguardia rispetto allo stato dell'arte (SOTA).
Integrazione
Progettato per la tua pipeline di dati di

01
SDK Python
Installa pangram-sdk e integra il rilevamento nelle tue pipeline Airflow o Databricks con poche righe di codice. Ottimizzato per il pooling delle connessioni e la gestione degli errori.
Visualizza documenti →
02
API ad alta produttività per l'
Elabora enormi set di dati con bassa latenza. La nostra infrastruttura supporta l'elaborazione in batch e garantisce un'elevata velocità di trasmissione, gestendo milioni di richieste per operazioni di scraping aziendale.
Ottieni la chiave API →
03
Sicurezza e conformità alle norme dell'
Certificazione SOC 2 Tipo 2 completa. Offriamo endpoint privati e rigorose politiche di conservazione dei dati: non utilizziamo mai i vostri dati proprietari per l'addestramento dei modelli.
Scopri di più →
Domande frequenti
Domande frequenti sul rilevamento tramite IA
Domande frequenti sul rilevamento dell'IA per ingegneri di machine learning
e data scientist.
Sì. È possibile installare pangram-sdk per integrare il rilevamento nelle pipeline di Airflow o Databricks con poche righe di codice. La nostra API è ottimizzata per operazioni di scraping aziendali ad alta produttività e supporta milioni di richieste con bassa latenza.
Scopri di più
Rilevamento tramite IA per
ogni organizzazione
Per gli sviluppatori
Rilevamento del codice generato dall'IA per sviluppatori e team di ingegneri. Rileva il codice generato dall'IA tramite ChatGPT, Copilot e Claude in Python, Java, C++ e altri linguaggi.
Scopri di più →Per la moderazione dei contenuti
Moderazione dei contenuti tramite IA per i team dedicati alla fiducia e alla sicurezza. Individua su larga scala recensioni generate dall'IA, commenti falsi e contenuti sintetici tramite API.
Scopri di più →Per le università
Rilevamento tramite IA per università e istituti di istruzione superiore. Verifica dei compiti degli studenti, controllo dei lavori di ricerca presentati e tutela della reputazione dell'istituto.
Scopri di più →Pulisci i tuoi dati di addestramento oggi stesso
Prevenite il collasso del modello, verificate gli input RLHF e filtrate i contenuti sintetici dai vostri set di dati con una precisione del 99,98%.
per ricevere i nostri aggiornamenti
