
Vedere nello spazio dei pangrammi
Analisi delle rappresentazioni interne del Pangram 3.3.2
Di Elyas Masrour, Katherine Thai e Bradley Emi
Giugno 2026
Introduzione
Dal debutto di ChatGPT nel 2022, la scrittura assistita dall’intelligenza artificiale si è diffusa a un ritmo vertiginoso. Poiché i testi generati dall’intelligenza artificiale sono ormai presenti in gran parte di ciò che leggiamo, è diventato evidente che alcune forme di scrittura perdono il loro valore quando sono prodotte da una macchina. In ambito accademico, i saggi hanno lo scopo di coltivare il ragionamento degli studenti. Nel mercato, le recensioni dei prodotti sono preziose perché riflettono le esperienze di altre persone.
Pangram è un'azienda di ricerca che sviluppa modelli di rilevamento basati sull'intelligenza artificiale all'avanguardia per affrontare questo problema. Il nostro prodotto di punta è un modello di rilevamento di testi generati dall'intelligenza artificiale che si distingue per tassi di falsi positivi tra i più bassi del settore, funzionalità multilingue e capacità di distinguere tra contenuti generati dall'intelligenza artificiale e quelli creati con l'ausilio dell'intelligenza artificiale.
Dal lancio del nostro primo white paper nel 2024, abbiamo avuto la possibilità unica di osservare una serie ininterrotta di progressi nel campo dell’intelligenza artificiale. I nostri ricercatori hanno dovuto fare i conti con filtri dei contenuti eccessivamente rigidi e hanno assistito a numerosi casi di “mode collapse”, schivando ondate di trattini lunghi e la parola “delve”.
Il nostro modello di punta è un LLM ottimizzato per questo compito di classificazione delle sequenze. Non utilizziamo metriche personalizzate come la perplessità o la burstiness. Non effettuiamo alcuna estrazione manuale di caratteristiche. Abbiamo un prodotto rivolto ai clienti chiamato AI Phrases, attraverso il quale forniamo ai nostri utenti informazioni sulle frasi che compaiono più frequentemente nei testi generati dall’IA. Tuttavia, queste non vengono utilizzate direttamente come caratteristiche per il modello. Dopo un po’, viene spontaneo chiedersi: cosa vede il modello?
Per noi ricercatori, questa questione è importante. Abbiamo un forte interesse a evitare le scorciatoie, a correggere comportamenti indesiderati dei modelli e a comprendere a fondo questo problema. In questo post illustreremo i nostri primi tentativi di interpretabilità attraverso l’analisi a livello di documento.
Dati
Abbiamo creato un set di dati per l'interpretabilità utilizzando campioni "held-out" all'interno del dominio, estratti dal nostro set di addestramento di produzione. L'esploratore interattivo presente in questa pagina utilizza un sottoinsieme bilanciato di 5.000 documenti, suddiviso equamente tra dati generati dall'uomo e dall'IA, distribuiti su 20 livelli pari. I campioni generati dall'IA coprono le varianti di modello riportate di seguito, appartenenti alle sei famiglie di modelli utilizzate per il test del classificatore.
Modelli
- Claude 3.7 Sonetto
- Claude Sonetto 4
- Claude Sonnet 4.5
- Claude Opus 4
- Claude Opus 4.1
- Claude Opus 4.5
- GPT-3.5 Turbo (novembre 2023)
- GPT-3.5 Turbo (gennaio 2024)
- GPT-4 (marzo 2023)
- GPT-4 (giugno 2023)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- Qwen 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
Domini di origine
- Notizie
- Abstract scientifici
- Recensioni dei prodotti
- Recensioni aziendali
- Reddit - Scrittura creativa
- Reddit ELI5
- Libri (autopubblicati)
- Libri (Progetto Gutenberg)
- Wikipedia (inglese)
- Wikipedia (multilingue)
- Lang-8 (ESL)
Pangram 3.3.2 Panoramica
Pangram 3.3.2 è un modello di rilevamento dell'IA rilasciato da Pangram Labs nel 2026. Utilizza lo stesso modello di base di Pangram 3.3, con successive correzioni di bug che ne migliorano le prestazioni. Pangram 3.3 è succeduto a Pangram 3.2 e ha migliorato il recall sui risultati dei modelli di linguaggio di grandi dimensioni (LLM) più recenti, sui testi umanizzati e sui contenuti di lunga durata generati dall'IA, riducendo al contempo i falsi positivi sui testi scritti in inglese non nativo.
Scheda del modelloLeggi la scheda del modello Pangram 3.3Consulta i dettagli del rilascio di Pangram 3.3.2.Leggi l'articoloIl lavoro sull'interpretabilità è ancora in corso. Nel corso di questo articolo, applichiamo i nostri metodi anche in modo retroattivo a Pangram 3.2 e Pangram 3.1.
Metodi
Attivazioni
L'architettura di EditLens è un sistema di classificazione basato su bucket che si riduce a un unico punteggio_assistenza_ai. Per questo progetto, tralasciamo il risultato finale del modello e ci concentriamo invece sulle rappresentazioni interne che il modello apprende. Per analizzarle, raccogliamo le attivazioni eseguendo un passaggio in avanti del modello con un dato documento di input e salvando la rappresentazione nascosta del modello in diversi livelli interni. Per questo progetto, abbiamo estratto le attivazioni per ogni documento, per ogni livello pari lungo tutta la rete.
Riduzione della dimensionalità
Ciascun vettore di attivazione estratto era a 5.120 dimensioni. Per comprendere meglio tali rappresentazioni, abbiamo utilizzato una serie di tecniche di riduzione della dimensionalità.
PCA
L'analisi delle componenti principali (PCA) è la proiezione lineare più semplice: individua le direzioni di massima varianza nello spazio di attivazione. In questo progetto, abbiamo riscontrato che, verso la fine della rete, la maggior parte della varianza è contenuta nelle componenti principali 1 e 2; pertanto, le rappresentiamo graficamente l'una rispetto all'altra.
UMAP
UMAP offre una rappresentazione non lineare pensata per preservare la struttura di vicinato. Se due documenti sono vicini tra loro nello spazio interno del modello, UMAP cerca di mantenerli vicini anche nello spazio bidimensionale. Tuttavia, non si dovrebbe dare un’interpretazione eccessiva agli assi e alle distanze esatte tra i cluster.
t-SNE
Il t-SNE è un altro metodo di proiezione non lineare particolarmente efficace nell'evidenziare i cluster locali. Ai fini di questo progetto, utilizziamo il t-SNE per verificare se i gruppi semanticamente rilevanti, come le famiglie di modelli o le etichette "umano/IA", tendano a raggrupparsi in modo visibile man mano che la rete diventa più profonda.
Sonde lineari
Utilizziamo sonde lineari per quantificare i risultati qualitativi osservati grazie ai nostri metodi di riduzione della dimensionalità. Per ogni strato, verifichiamo se un semplice classificatore sia in grado di ricavare un’etichetta di riferimento dai vettori di attivazione di quello strato. Un’elevata accuratezza della sonda indica che la distinzione rilevante è già codificata in una direzione linearmente accessibile dello spazio di rappresentazione.
Il compito di rilevamento tramite IA
Precisione binaria
Per comprendere come si ottiene la separazione finale delle classi lungo il percorso della rete, addestriamo delle sonde lineari a ogni livello. L’addestramento viene effettuato su 500 campioni, suddivisi equamente tra esseri umani e IA, con una ripartizione addestramento/test di 80:20. Notiamo che, anche nelle prime fasi della rete, le prestazioni sono già elevate: raggiungiamo un’accuratezza di 0,83 subito dopo il livello 2. Ciò conferma la nostra intuizione, poiché i modelli “bag-of-words” sono spesso linee di base valide per il compito di rilevamento dell’IA. Lungo tutta la rete, l’accuratezza aumenta fino a raggiungere il massimo di 1,0 al livello 24.
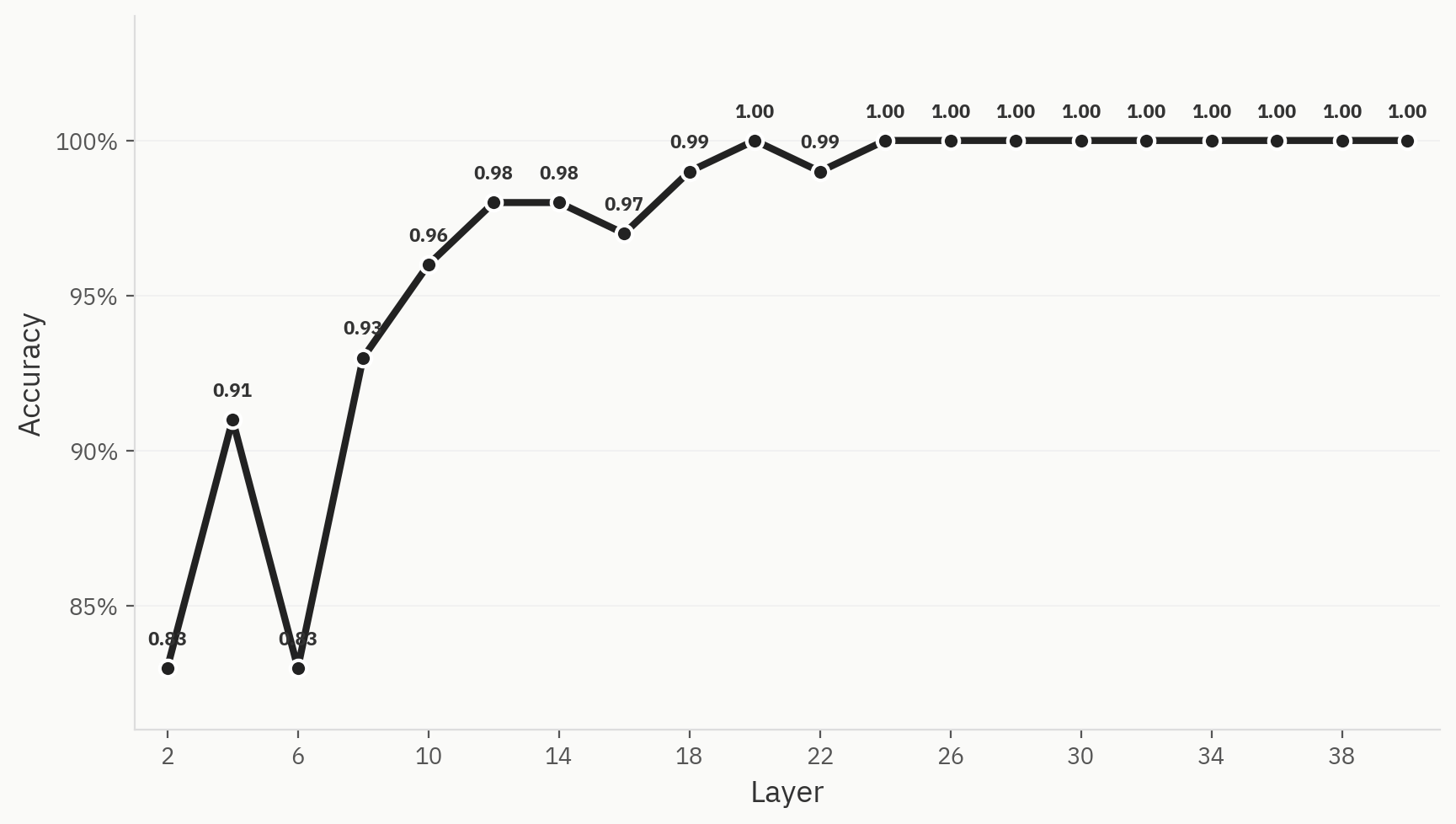
Fig. 3 Questa separazione è chiaramente visibile in tutti e tre i metodi di riduzione della dimensionalità.
Classificazione LLM
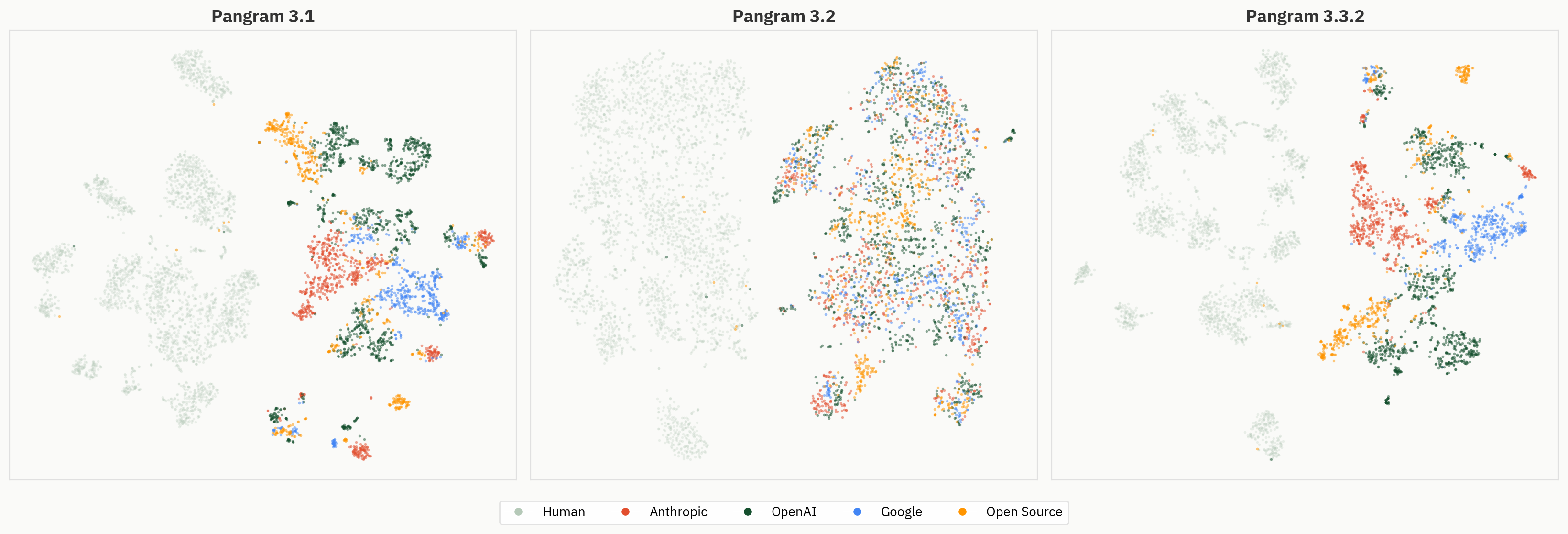
Nei grafici t-SNE e UMAP abbiamo notato che i documenti sembravano raggrupparsi in base al modello che li aveva generati. Questo ci ha sorpreso. Le vecchie iterazioni di Pangram disponevano di un modulo di classificazione LLM separato, ma quel particolare compito era stato abbandonato da tempo. Nel suo processo di addestramento, a Pangram 3.3.2 non vengono fornite etichette corrispondenti al modello di origine di un documento generato dall’IA.
Ciononostante, si sono formati dei cluster attorno alla famiglia di modelli di origine. Ancora più interessante è il fatto che tali cluster sembrano emergere in tutti gli strati della rete.
Emergenza dei cluster di modelli
Colora gli stessi embedding per famiglia di modelli per osservare come la geometria a livello di provider si manifesti in tutti gli strati.
Fig. 4: Embedding dei livelli 2-40 colorati in base alla famiglia di modelli. I cluster a livello di provider diventano più evidenti nei livelli successivi.
Sonda
Per quantificare questo fenomeno, addestriamo un classificatore su sei famiglie di modelli (Anthropic, OpenAI, Google, Qwen, Llama, DeepSeek) utilizzando 500 campioni per ciascuna famiglia di modelli, per un totale di 3.000 campioni, con una suddivisione 80:20 tra set di addestramento e set di test. Abbiamo riscontrato che è effettivamente possibile addestrare un modello in grado di classificare la famiglia di modelli di origine di un determinato documento utilizzando esclusivamente le attivazioni Pangram, con un’accuratezza top-1 massima del 91%.
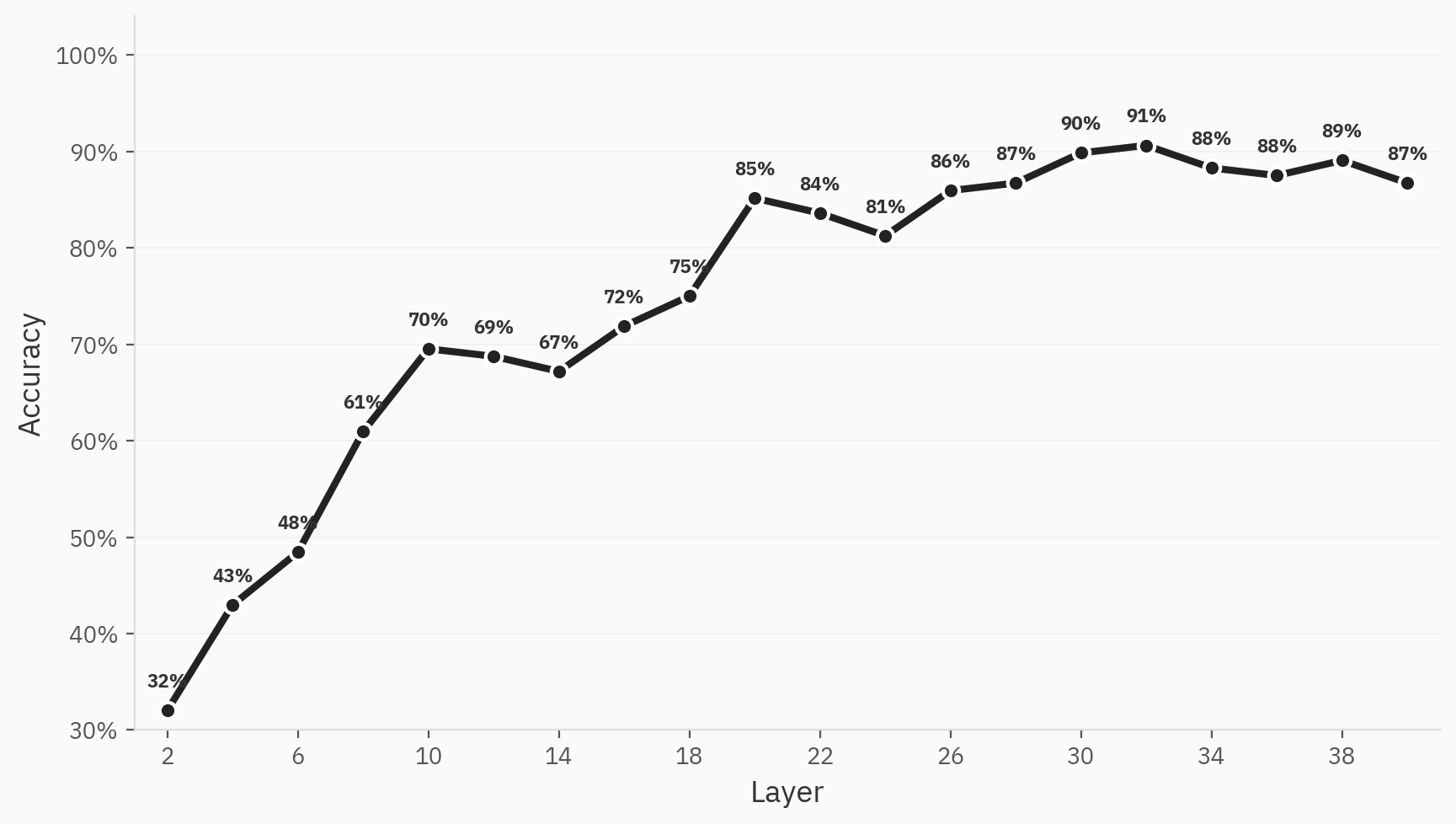
L'emergere non è garantito
I nostri primi esperimenti sull’interpretabilità hanno previsto l’analisi di diversi modelli. Con nostra sorpresa, l’emergere di una capacità di “classificazione LLM” è stato uno dei pochi risultati di questo progetto a presentare differenze significative tra i vari modelli.
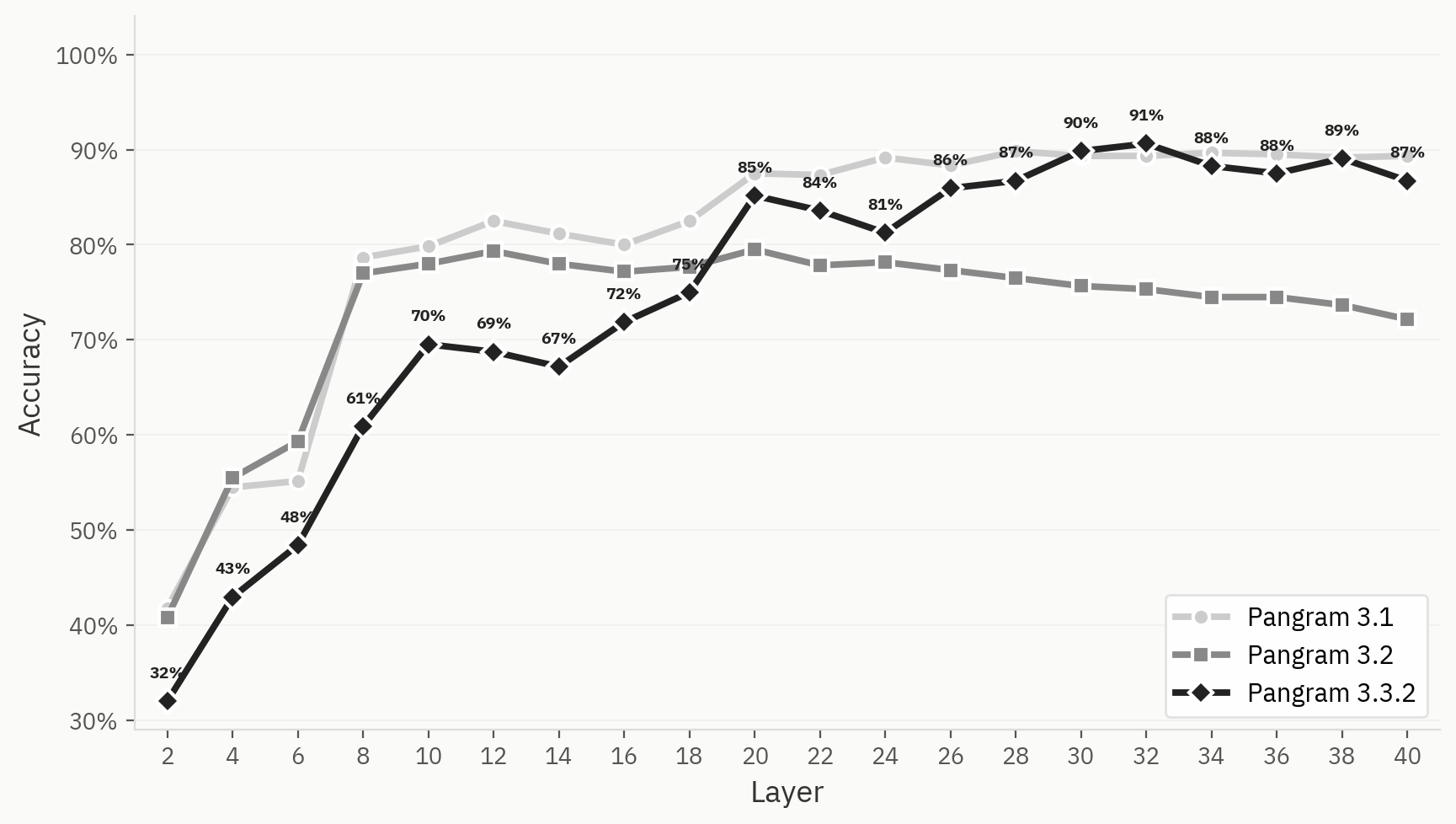
La figura seguente mette a confronto il comportamento di raggruppamento delle versioni 3.1, 3.2 e 3.3.2 di Pangram. Nonostante il modello abbia ottenuto risultati migliori rispetto alla versione 3.1 nel compito binario "uomo-IA" nelle nostre valutazioni interne di verifica finale, i raggruppamenti del modello sono in generale meno definiti nella versione 3.2 di Pangram rispetto alle versioni 3.1 o 3.3.2.
Per illustrare meglio questa differenza, mettiamo a confronto l'andamento del classificatore LLM nei Pangram 3.1, 3.2 e 3.3.2. Tutti e tre registrano un miglioramento dell'accuratezza top-1 nei primi livelli, ma l'andamento del Pangram 3.2 inizia a diminuire dopo il livello 12, mentre quello dei Pangram 3.1 e 3.3.2 rimane elevato.
Humanizers
Gli "humanizer" sono una categoria di strumenti avversari progettati per modificare i testi generati dall'intelligenza artificiale in modo tale da eludere i rilevatori di IA. Per osservare la posizione del testo umanizzato rispetto a quello umano e a quello generato dall’IA nello spazio di attivazione, abbiamo creato un dataset separato dedicato agli umanizzatori, composto da circa 1.900 campioni, distribuiti in modo approssimativamente equilibrato tra tre modelli generativi (Claude Sonnet 4.5, Gemini 2.5 Pro e GPT-5), dieci diversi servizi di umanizzazione e gli stessi domini di origine del dataset originale sull’interpretabilità. A causa dei rischi legati alle tecniche avversarie, non riveliamo quali servizi utilizziamo.
Come il modello identifica gli "humanizer"
Alcuni campioni del nostro dataset “humanizer” rappresentano effettivamente una sfida per il nostro modello in termini di rilevamento. In questo caso, utilizziamo la stessa sonda lineare per il compito “umano/IA”, ma con il testo umanizzato etichettato come “IA”, proprio come nella configurazione di addestramento originale. Osserviamo che, fin dal primo livello, il testo umanizzato viene costantemente interpretato come più “umano” rispetto alla sua controparte diretta generata dall’IA.
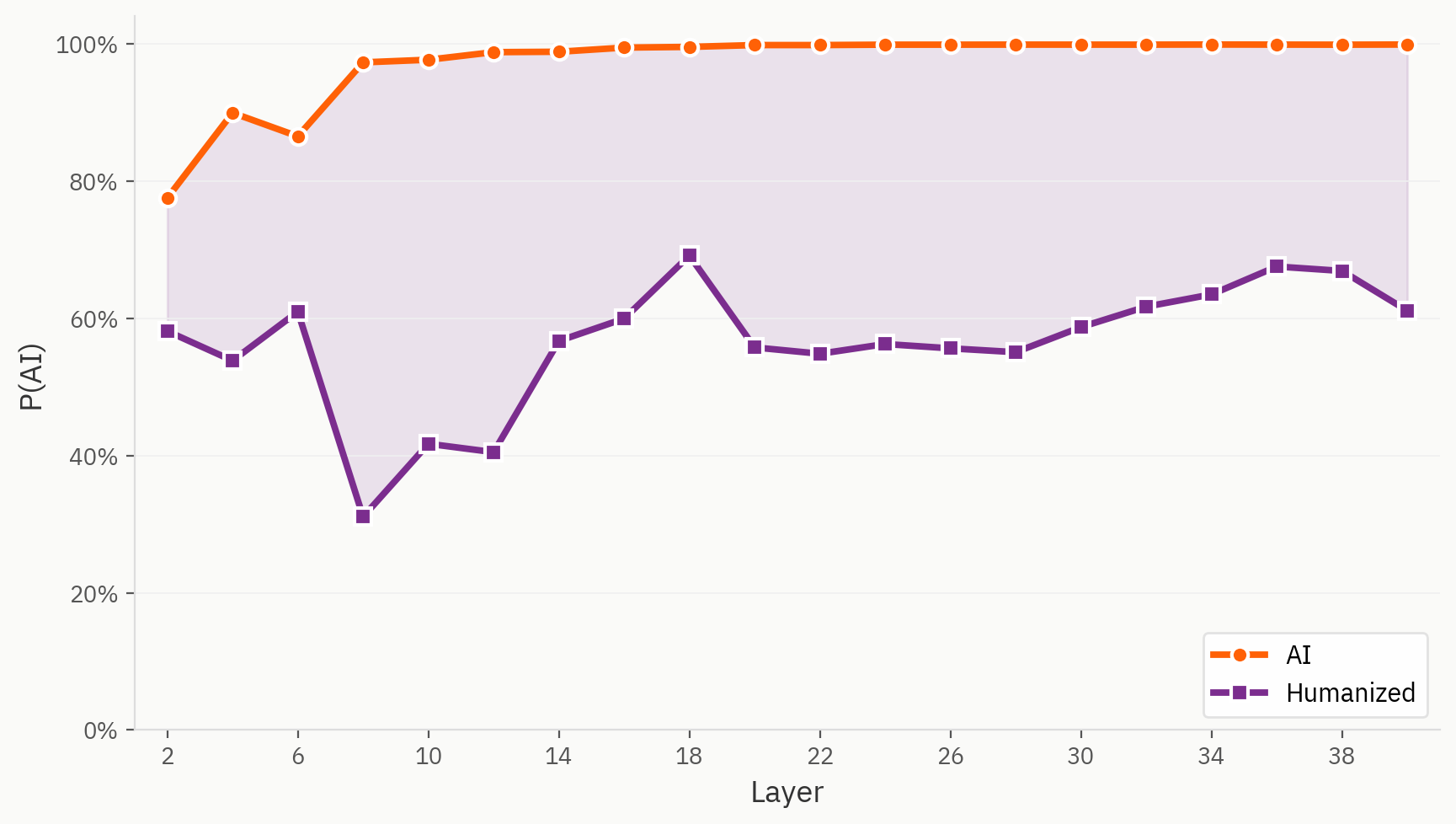
Dove si trovano gli “humanizer” nello spazio di embedding
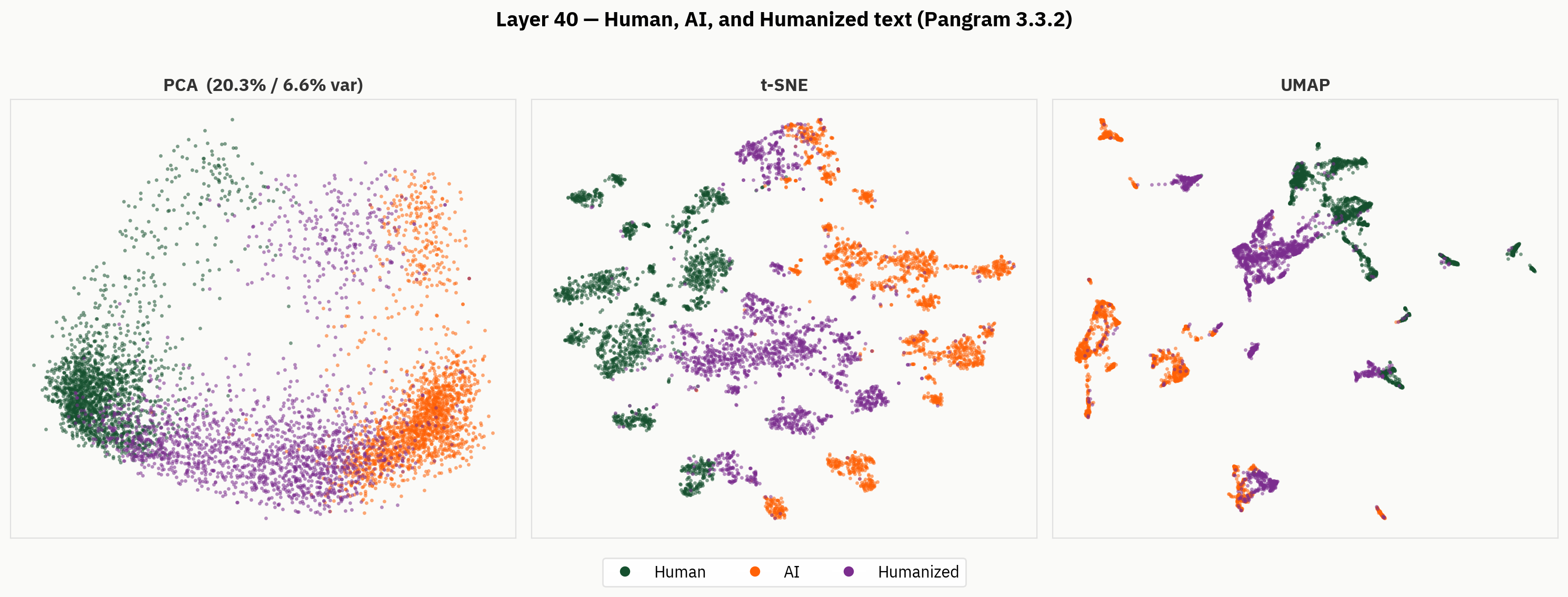
Tuttavia, quando analizziamo più a fondo i risultati finali, troviamo una rappresentazione molto più ricca del testo umanizzato. Di seguito, applichiamo i nostri metodi di riduzione della dimensionalità ai testi umani, a quelli generati dall’IA e a quelli umanizzati. Da un punto di vista qualitativo, possiamo osservare che gli umanizzatori tendono a occupare aree distinte dello spazio di attivazione e a formare cluster al di fuori delle regioni relative ai testi umani e a quelli generati dall’IA.
La nostra ipotesi è che, pur non disponendo di etichette relative ai testi umanizzati, il modello sia in grado di distinguere tra testi umanizzati, testi scritti da esseri umani e testi generati dall'intelligenza artificiale. Tuttavia, nella valutazione finale, il modello è costretto a ignorare tale segnale e lo fa in modo incoerente.
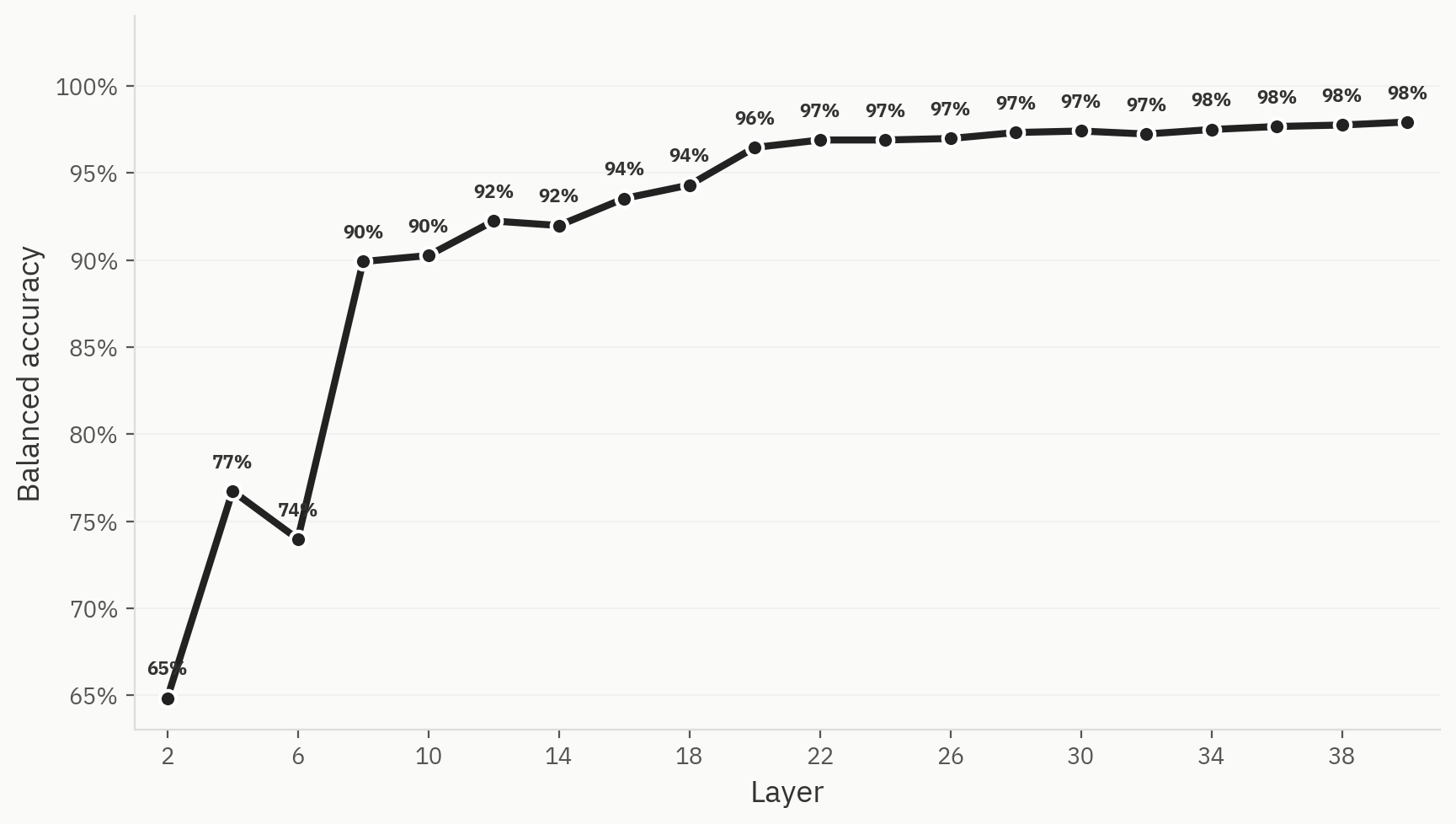
Sonda
Per verificare questa ipotesi, addestriamo una sonda lineare a tre vie con etichette relative a testo generato dall’IA, testo umano e testo umanizzato. La sonda raggiunge un’elevata accuratezza top-1 già nelle prime fasi della rete e alla fine si stabilizza al 98%.
Conclusione
Il nostro lavoro in questo ambito suggerisce che le rappresentazioni interne di Pangram contengano una struttura più complessa di quanto non riveli la sola lettura binaria finale. Attraverso i vari livelli, osserviamo una separazione tra i documenti redatti da esseri umani e quelli generati dall’IA, l’emergere di informazioni relative alla famiglia di modelli e il testo umanizzato che occupa una propria regione dello spazio di attivazione. Si tratta di risultati preliminari, ma ci forniscono una mappa utile per comprendere ciò che il modello apprende prima di sintetizzare il tutto in un unico punteggio di rilevamento.
Questo post illustra solo i primi passi del nostro impegno in materia di interpretabilità, ma internamente siamo entusiasti e interessati a questa direzione di ricerca.
La nostra visione in merito all’interpretabilità e alla spiegabilità dei modelli Pangram è che essi possano:
- Fornire una migliore comprensione interna del comportamento del modello.
- Fornire prove a sostegno e spiegazioni più chiare per i singoli risultati relativi ai pangrammi.
Se sei un ricercatore interessato all'interpretabilità, alla ricerca sul rilevamento dell'intelligenza artificiale o a qualsiasi altro aspetto di questo lavoro, ti invitiamo a contattarci all'indirizzo elyas@pangram.com.
