 ICLRに提出されたAI生成の要旨の割合を年別に示したグラフで、2023年以降、増加傾向にあることがわかる。
ICLRに提出されたAI生成の要旨の割合を年別に示したグラフで、2023年以降、増加傾向にあることがわかる。
2024年2月、『Frontiers in Cell and Developmental Biology』誌に掲載された論文に、明らかにAIによって生成された図が掲載されていた。この論文は、図の一つに、不自然に大きな睾丸を持つラットが描かれており、さらに全く意味をなさない支離滅裂なテキストが添えられていたことから、大きな話題となった。
これは『Frontiers in Cell and Developmental Biology』に掲載された本物の論文です。図は明らかにAIで生成されたものです。そのうちの1つには、とんでもなく大きな睾丸を持つラットが描かれています。図中のテキストは支離滅裂な内容です。pic.twitter.com/4Acn2YZYwM
— クリフ・スワン (@cliff_swan) 2024年2月15日
査読制度は(理論上は)このような明らかな事例を見逃さないはずですが、論文の内容そのものがAIによって生成された場合はどうでしょうか。専門家でさえ、AIが生成した研究と人間が執筆した研究を見分けるのは困難です。
『ネイチャー』誌の最近のニュース記事では、学術論文におけるAI生成コンテンツに対する懸念が高まっていることが取り上げられている。この記事では、コンピュータ科学者たちが最新のLLMの一つである「Claude 3.5」を用いて研究アイデアを生成し、論文を執筆し、それらを科学分野の査読者に提示した研究について論じている。査読者は、これらの論文を「新規性、魅力、実現可能性、および期待される有効性」の観点から評価した。その結果、平均して、査読者は人間が執筆した論文よりもAIが作成した論文の方を高く評価していたことが判明した! これを受けて、「AIは実際に人間よりも優れた研究アイデアを思いつくのか?」という疑問が浮かびます。そう信じたい気持ちはありますが、研究者が調査した4,000本のAI生成論文のうち、実際に独自のアイデアを含んでいたのはわずか200本(5%)に過ぎませんでした。ほとんどの論文は、単にLLMの学習データに含まれる既存のアイデアを丸写ししていたに過ぎなかったのです。
結局のところ、AIによって生成された研究論文は、査読プロセスにおいて「ノイズ」を増やし「有益な情報」を減らすことで、学術コミュニティに悪影響を及ぼす。研究の基準を維持するために細心の注意を払っている査読者の時間と労力を無駄にしていることは言うまでもない。 さらに悪いことに、AIが生成した研究論文は一見説得力があるように見えることが多いが、実際には、言語モデルによって生成されたテキストは単に流暢に聞こえるだけであり、誤りや幻覚、論理的な矛盾が散見される可能性がある。ここで懸念されるのは、専門家の査読者でさえ、自分が読んでいるものがLLMによる幻覚であるかどうかを見分けられない場合が多いという点である。
主要な機械学習カンファレンスの主催者たちも、私たちと同じ見解を持っています。すなわち、科学論文においてLLMが生成したテキストに居場所はないということです。ICML(国際機械学習会議)の公式方針は以下の通りです:
大規模言語モデルに関するポリシーの説明
私たち(プログラム委員長)は、2023年開催のICMLの論文募集要項に以下の声明を盛り込みました:
ChatGPTなどの大規模言語モデル(LLM)によって生成されたテキストを含む論文は、その生成されたテキストが論文の実験的分析の一部として提示されている場合を除き、禁止されます。
この声明に対し、投稿を検討されている方々から多くの質問が寄せられ、中には自ら当方へ連絡をくださった方もいらっしゃいました。皆様からのご意見やご感想に感謝するとともに、本声明の意図およびICML 2023における本方針の実施方法について、さらに詳しく説明させていただきたいと思います。
要約:
ICML 2023の大型言語モデル(LLM)に関するポリシーでは、LLMによって完全に生成された(すなわち「生成された」)テキストの使用を禁止しています。ただし、著者が自ら執筆したテキストの編集や推敲のためにLLMを使用することは禁止されていません。 このLLMポリシーは、盗用を含むLLM使用に伴う潜在的な問題を未然に防ぐため、慎重を期すという原則に基づいています。
こうした警告があるにもかかわらず、機械学習分野の著者のうち、この方針に違反し、論文の作成にAIを用いてテキストを生成している者が、依然として相当数に上り、その数は増え続けていることが判明している。
問題の規模を把握する
パングラムでは、私たちの専門分野である人工知能(AI)において、この問題の規模を把握したいと考えました。そこで、「AI研究者はChatGPTを使って自身の研究論文を書いているのか」という疑問に答えようとしたのです。
この問題を調査するため、OpenReview API を利用して、AI分野で最大規模の2つの会議であるICLRとNeurIPSにおいて、2018年から2024年までの投稿論文を抽出しました。
そこで、これらの学会に提出されたすべての要旨に対して、PangramのAI検出ツールを実行しました。その結果は以下の通りです:
ICLR
ICLRに提出されたAI生成の要旨の割合を年別に示したグラフで、2023年以降、増加傾向にあることがわかる。
NeurIPS
 NeurIPSに提出されたAI生成の要旨の割合を年別に示したグラフで、2023年以降、増加傾向にあることがわかる。
NeurIPSに提出されたAI生成の要旨の割合を年別に示したグラフで、2023年以降、増加傾向にあることがわかる。
結果
2022年以前のデータはすべて、当モデルの偽陽性率を検証するための検証セットと見なすことができます。というのも、当時は大規模言語モデルが存在しなかったからです。 図に示す通り、2022年以前の学会抄録はすべて、当モデルによって「人間が執筆したもの」と予測されます。これは当モデルの精度に対する信頼性を裏付けるものです。科学抄録における偽陽性率は極めて良好であるため、2023年および2024年に下されたすべての陽性予測は、真の陽性であると確信できます。
それ以降に見られる状況は、非常に懸念されるものです。2022年11月にChatGPTがリリースされて以来、3回のカンファレンスサイクルが経過しています。
最初のサイクルは、ChatGPTのリリース(ICLR 2023)とほぼ同時期に発生しました。 投稿締切は実際にはChatGPTのリリース前でしたが、著者は会議本番(ChatGPTのリリースから数ヶ月後)までに修正を行う機会がありました。その結果は予想通りでした。AIによって書かれた要旨はごくわずか(このサイクルでは数千件のうち2件のみがAI作成と判明)であり、それらは締切後に修正された可能性が高いと考えられます。
第2回は、その約6か月後の2023年夏に開催されたNeuRIPS 2023で、2023年12月の会議に向け、夏に投稿締切が設けられていました。この会議において、我々は、提出された抄録の約1.3%がAIによって生成されたものであると報告しました。これはわずかな割合ではありますが、無視できない割合です。
最後に、数ヶ月前に開催された直近の大会であるICLR 2024では、その数値が4.9%まで上昇していることが確認されました。これは、NeuRIPS 2023と比較して、AI生成レビューの精度がほぼ4倍に向上したことを意味します!
これらの結果は、懸念すべき傾向を浮き彫りにしている。主要なAI関連の学会に提出されるAI生成の学会論文の数が増加しているだけでなく、その増加ペースも加速している。つまり、AI生成論文の提出ペースが加速しているということだ。
AIが生成した要約はどのようなものなのでしょうか?
以下の要約をいくつかご覧いただき、これらが、皆さんが科学技術文献で普段目にする文章と似ているかどうか、ご自身で確かめてみてください:
-
ネットワーク化されたデータの複雑な状況において、介入による因果効果を理解することは、様々な分野に影響を及ぼす重要な課題である。グラフニューラルネットワーク(GNN)は、複雑な依存関係を捉えるための強力なツールとして台頭してきたが、GNNに基づくネットワーク因果推論における幾何学的深層学習の可能性は、依然として十分に解明されていない。本研究は、このギャップを埋めるために3つの重要な貢献を行う。 第一に、グラフの曲率と因果推論との間に理論的な関連性を確立し、負の曲率が因果効果の特定において課題となることを明らかにした。第二に、この理論的知見に基づき、リッチ曲率を用いて因果効果推定の信頼性を予測する計算結果を提示し、正の曲率領域においてより正確な推定が得られることを実証的に示した。 最後に、ネットワーク化されたデータにおける治療効果推定を改善するためにリッチフローを用いた手法を提案し、ネットワーク内のエッジを平坦化することで誤差を低減し、優れた性能を示す。我々の知見は、因果効果推定において幾何学を活用する新たな道を開き、因果推論タスクにおけるGNNの性能を向上させる洞察とツールを提供するものである。
-
言語モデルの分野において、データエンコーディングは極めて重要であり、モデル学習の効率と有効性に影響を与えます。バイトペアエンコーディング(BPE)は、頻繁に現れるバイトまたは文字のペアを結合することで、計算効率と言語的表現力のバランスをとる、定評のあるサブワードトークン化手法です。 言語モデルの学習には膨大な計算リソースが必要となるため、我々は、言語モデルのデータエンコーディングにおいて、従来のバイトペアエンコーディング(BPE)アプローチを大幅に強化する手法「Fusion Token」を提案します。 Fusion Tokenは、BPEと比較してより積極的な計算戦略を採用し、トークングループを2グラムから10グラムへと拡張します。注目すべきは、語彙に1024トークンを追加しただけで、その圧縮率が語彙100万の通常のBPEトークナイザーの圧縮率を大幅に上回ることです。 全体として、Fusion Tokenの手法は、計算ユニットあたりのデータ範囲が拡大されることで、顕著な性能向上をもたらします。さらに、圧縮率の向上により、特定の文字列あたりのトークン数が減少するため、推論時間が短縮されます。トークナイザーの構築プロセスにより多くの計算リソースを割くことで、Fusion Tokenは言語モデルが効率的なデータ圧縮エンジンとして持つ可能性を最大限に引き出し、より効果的な言語モデリングシステムを実現します。
-
急速に進歩しているモーション生成の分野において、テキストの意味論を強化することは、より正確で現実的な動きを生成するための極めて有望な戦略であると認識されています。 しかし、現在の手法では、テキスト記述を精緻化するために大規模な言語モデルに依存することが多く、テキストデータとモーションデータ間の正確な整合性が保証されていない。この不整合は、モーション生成の品質を低下させ、これらの手法の可能性を制限する要因となっている。この問題に対処するため、我々はテキストデータとモーションデータの間のギャップを埋めることを目的とした、SemanticBoostという新しいフレームワークを提案する。 我々の革新的なソリューションは、モーションデータ自体から導出された補足的な意味情報を、専用のノイズ除去ネットワークと統合することで、意味的な一貫性を保証し、モーション生成の全体的な品質を向上させます。広範な実験と評価を通じて、SemanticBoostがモーションの品質、整合性、およびリアリズムの点で、既存の手法を大幅に上回ることを実証しました。さらに、我々の知見は、モーションデータからの意味的手がかりを活用する可能性を強調しており、より直感的で多様なモーション生成への新たな道を開くものです。
何かパターンに気づきましたか?まず、どれも「~の複雑な状況において」、「~の分野において」、「急速に進化する~の領域において」といった、非常に似たようなフレーズで始まっていることがわかります。私たちはこれを「不自然に装飾的な表現」と呼んでいます。 LLM(大規模言語モデル)が、実際のコンテンツをほとんど生み出さないにもかかわらず、多くの言葉を使うことがいかに頻繁であるかについては、以前にも触れました。これは、宿題で最低文字数を満たそうとする学生にとっては望ましいことかもしれませんが、研究内容を理解しようとする技術系の読者にとっては、このような過度に冗長な表現は論文の読解を困難にし、時間を浪費させるだけでなく、論文の真のメッセージを曖昧にしてしまうだけです。
AI関連の論文は、実際に学会で採択されるのでしょうか?
AIによって生成された論文は、査読プロセスによって実際に効果的に排除されているのか、それとも一部が審査の網をくぐり抜けてしまっているのか、私たちは疑問に思っていた。
この疑問に答えるため、我々はICLR 2024におけるAI生成要旨と論文採否の相関関係を分析した。(口頭発表、スポットライト、ポスター発表はいずれも「採択」された論文であり、口頭発表とスポットライトは特別な表彰カテゴリーである)。その結果は以下の通りである:
| カテゴリ | AIによる生成率 |
|---|---|
| ICLR 2024 口頭発表 | 2.33% |
| ICLR 2024 ポスター | 2.71% |
| ICLR 2024 注目トピック | 1.36% |
| 却下 | 5.42% |
AIによって生成された論文のうち、採択された割合は投稿された割合よりも低いものの、依然としてかなりの数が査読プロセスを通過している。これは、査読者がある程度のAI生成コンテンツを見抜いているものの、すべてを捕捉できているわけではないことを示唆している。
口頭発表や注目論文の中にも、AIが生成した要旨が使われているものがあることに気づきました!好意的に解釈すれば、今後明らかになるのは、研究そのものは実は質が高く、著者が単にChatGPTを使って手っ取り早く発表の準備や論文の推敲を行っているだけだという可能性もあるでしょう。
特に、研究者の多くは英語を母語としないため、LLMの活用が拡大するにつれ、他言語で書かれた論文を英語に翻訳する用途が増えていくでしょう。
結論
AIコミュニティが著者に対しChatGPTの使用を控えるよう明確に要請しているにもかかわらず、多くの著者はこの方針を無視し、論文執筆の補助としてLLMを利用し続けている。さらに懸念されるのは、LLMによって生成された論文から学会を守るために査読者を務めるAIの専門家たちでさえ、それを発見できていないという点だ!
ChatGPTは、学術プロセス全体にさらに波及効果をもたらしています。最近のICMLのケーススタディによると、査読そのものの6~16%がAIによって生成されていたことが判明しており、AI生成の査読と、その査読が締め切り直前に提出されたかどうかとの間には正の相関関係が見られました!
私たちは、AIコミュニティに対し、これらのポリシーをより適切に実施するよう求めるとともに、著者には、自身の論文が人間によって作成されたものであることを確実にする責任を果たすよう求めます。
AIが学術論文の分野に進出しているのは研究分野だけにとどまらない――AIは小説の賞も受賞している。

ブラッドリーはAI研究者であり、産業界におけるディープラーニング製品の構築の専門家です。最近では、生成AIを活用した創薬企業であるAbsciでディープラーニング研究グループを率いており、それ以前はテスラのオートパイロット部門におけるコアコンピュータビジョンチームのメンバーでした。
大学院生時代、ブラッドリーはスタンフォード・ビジョン・ラボに所属し、ディープラーニング研究に関する複数の論文を発表しました。スタンフォード大学で物理学の学士号と人工知能の修士号を取得しています。AI以外にも、教育や哲学に関心を持ち、熱心なゴルファーでもあります。
関連記事
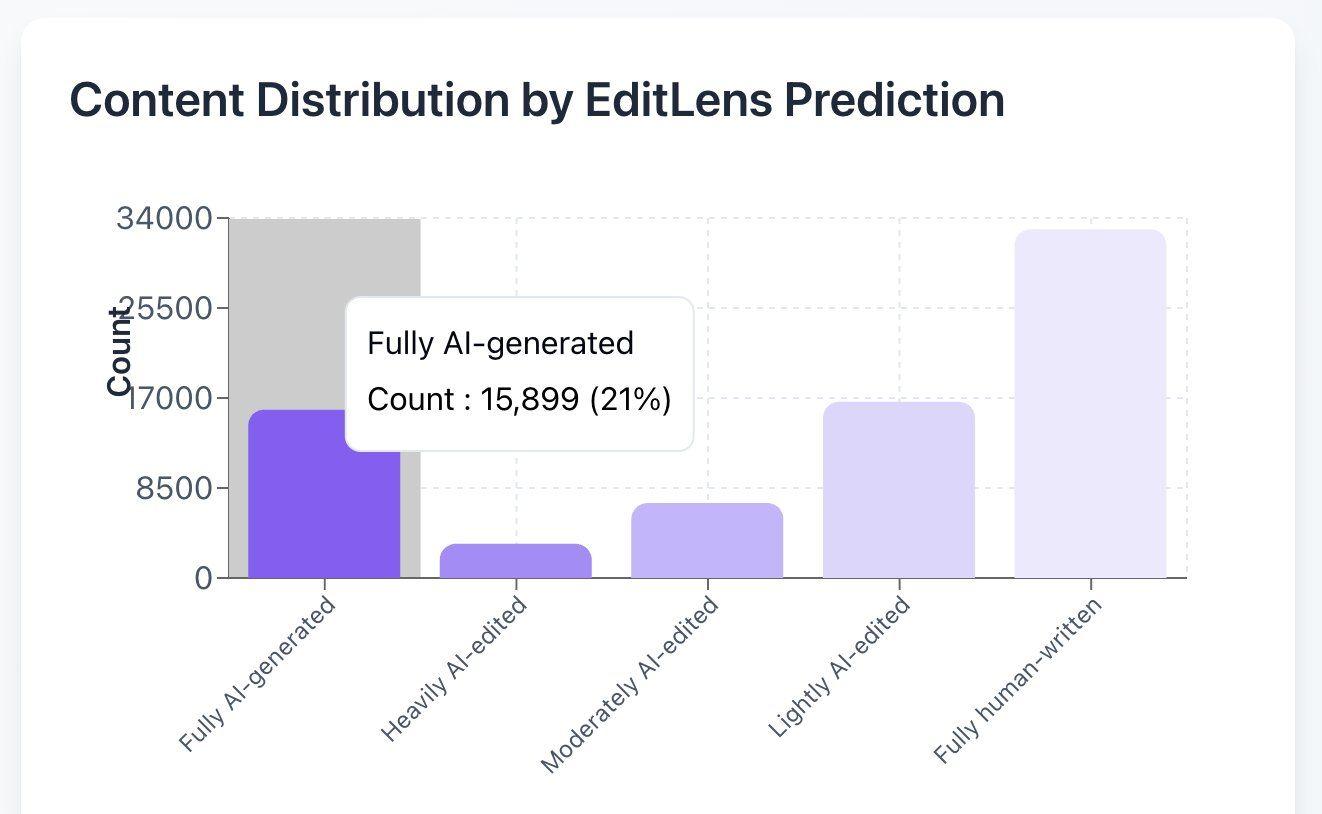
パングラム社、ICLRの査読論文の21%がAIによって生成されたものと予測
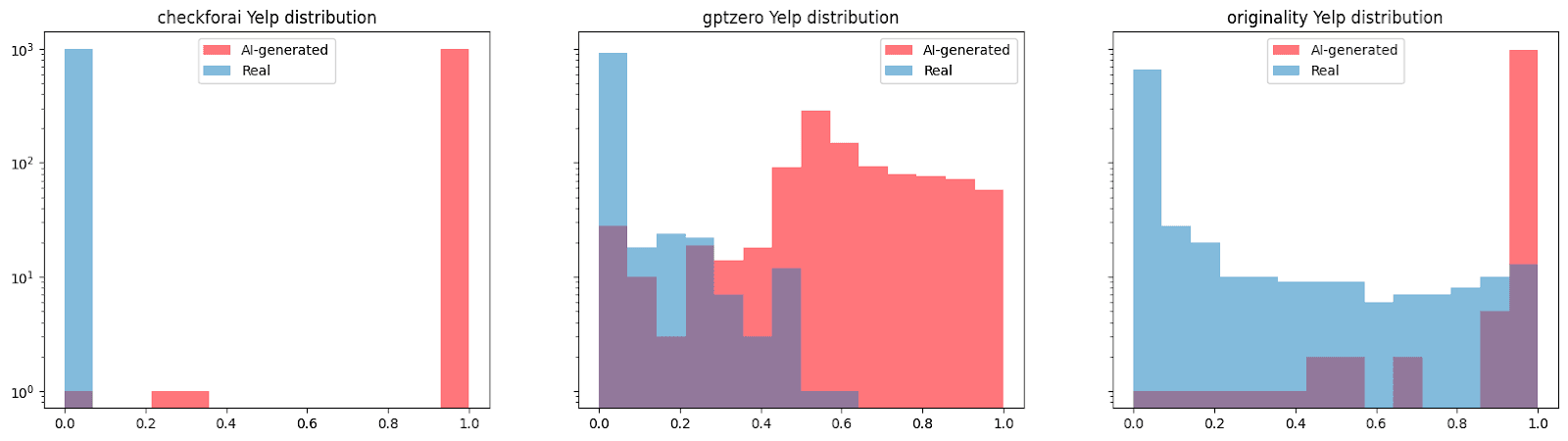
Yelpのレビューを徹底分析

AIはAIを見抜く

現在、Amazonのトップページに掲載されているレビューの3%はAIによって生成されたものである

最も精度の高いAI検出ツールはどれか? 30のツールを検証(2026年)

ビジネスをLLMおよびジェネレーティブAIに対応させる
を購読して、最新情報を受け取りましょう
