Pangram 在人名生成器上的表现如何?(更新于 2025 年 8 月)
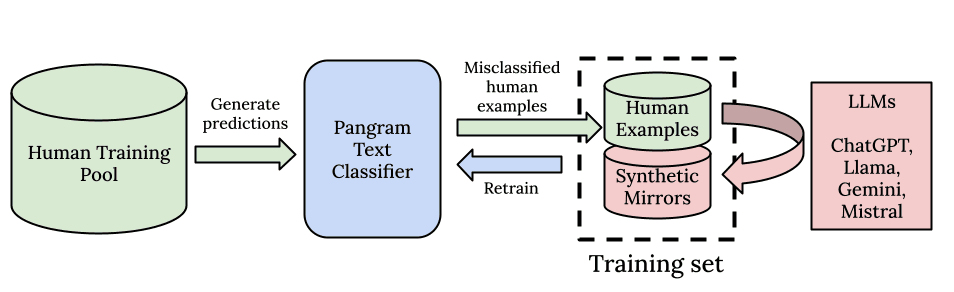
人们常将AI检测描述为大型语言模型、检测器与“人性化工具”之间的一场“军备竞赛”。所谓“人性化工具”,是指一类在线工具,其目的是混淆AI生成的文本,并在其中引入人为错误,从而使生成的文本听起来更具人性化。
在 Pangram,我们始终致力于保持领先地位,并针对新模型和拟人化技术领域的最新进展做出响应。这使我们能够开发出始终可靠的人工智能检测技术。
2025年1月,我们发布了技术报告的更新版本,其中对19款不同的人类化工具和改写工具进行了评估。主要发现如下:
- Pangram 能够有效应对文本自然化工具和改写工具
- 有些人工校对人员会手动添加空格和标点符号的错误,并进行一对一的同义词替换。
- 其他“人性化生成器”本身就是经过微调的大型语言模型,它们经过训练,能够以人类的风格对文本进行改写。
- “人化”文本的可读性或流畅性越高,被Pangram检测到的可能性就越大。
- 换句话说,就流畅度而言,“优质”的人类化处理更容易被察觉,而“劣质”的人类化处理则不太可能被察觉。
然而,人形化技术领域正在迅速发展,因此我们希望发布我们最新人形化基准测试的更新数据。
Pangram 更新后的人类化处理结果
| 人性化处理器 | 准确性 |
|---|---|
| Ahrefs | 100.0% |
| aihumanizer.com | 100.0% |
| 绕过GPT | 99.7% |
| 勺子 | 97.6% |
| 幽灵人工智能 | 100.0% |
| GPTinf | 99.2% |
| Grammarly | 100.0% |
| 人性化人工智能humanizeai.io | 93.8% |
| 人性化人工智能.pro | 100.0% |
| 刚刚完成 | 93.5% |
| Quillbot | 100.0% |
| Scribbr | 99.0% |
| 类人人工智能 | 100.0% |
| 斯莫丁 | 100.0% |
| 隐形GPT | 95.6% |
| 冲浪者SEO | 100.0% |
| surgegraph.io | 100.0% |
| 马克·吐温GPT | 92.7% |
| 隐形人工智能 | 90.3% |
| Writesonic AI | 98.1% |
在我们测试的所有知名人性化处理工具中,Pangram 的表现均超过 90%。
在检测拟人化AI文本方面,Pangram与其他AI检测工具相比表现如何?
在Russell等人发表的研究中,Pangram在拟人化文本上与GPTZero以及几种开源方法进行了性能对比。Pangram的最佳模型在拟人化文本上的准确率达到97%,而GPTZero为46%,FastDetectGPT为23%,Binoculars为7%。
 Pangram在处理自然语言文本方面的表现与其他检测器相比
Pangram在处理自然语言文本方面的表现与其他检测器相比
Jabarian 和 Imas最近的一项研究发现,在 4 款商用检测器中,Pangram 是唯一一款对“人性化”处理具有鲁棒性的检测器:
对于较长的段落,Pangram 能检测出近 100% 的 AI 生成的文本。随着段落变短,FNR 会略有上升,但仍保持在较低水平。其他检测器对“人性化”处理的抗干扰能力较弱。 对于 Originality.AI,长文本的 FNR 值约为 0.05,但短文本的 FNR 值可能高达 0.21,具体取决于文本体裁和 LLM 模型。GPTZero 几乎完全丧失了检测 AI 生成文本的能力,在大多数体裁和 LLM 模型中,其 FNR 值均在 0.50 及以上。RoBERTa 的表现同样不佳,FNR 值始终居高不下。
如何判断一段文本是否经过了“人性化”处理?
有几种方法可以凭肉眼判断一段文本是否经过了“人性化处理”。
被扭曲的短语
识别“人化器”最简单的方法之一,就是寻找那些“生硬的措辞”——这些措辞是刻意替换的同义词,显得格格不入,其目的正是为了掩盖剽窃行为。诸如Grammarly和Quillbot之类的改写工具,早在人工智能出现之前,就已经利用这些同义词替换算法来掩盖剽窃行为。
一些措辞生硬的例子包括用“伪造的意识”代替“人工智能”,或者用“胸怀危机”代替“乳腺癌”。去年我们听说过一个有趣的案例:一名学生在作文中将“马丁·路德·金”写成了“马丁·路德·鲁勒”。
必须谨慎对待将“生硬的短语”作为识别人性化AI文本的唯一依据,因为当非英语母语者误用或误解某些词汇的字面含义或典型用法时,此类生硬的短语在非母语者的英语写作中也十分常见。
不自然的间距错误
“人化”者常通过添加或删除空格来试图欺骗AI检测器的分词器。其中最常见的就是删除句子之间的空格。
常用短语
经过“人性化”处理的AI文本仍会出现与未经处理的AI文本相同的重复短语。如果同一份文档中出现了两次同样生硬的短语,这尤其能说明该文本出自“人性化”处理工具之手,因为这表明该工具正在系统性地应用相同的同义词替换。
非标准字符
“人性化工具”通常还会使用非标准的Unicode字符,以此来迷惑AI检测器的分词器。例如,一款流行的“人性化工具”就使用“U+2009”——即Unicode中的“窄空格”字符——来代替普通空格。 我们推荐访问https://www.soscisurvey.de/tools/view-chars.php这个网站,它能帮助您查看到复制粘贴的字符串中可能隐藏的所有不可打印字符。
 人性化文本中不可打印字符的示例
人性化文本中不可打印字符的示例
写作过程工具
通过使用 Pangram 在 Google 文档中推出的新功能“写作回放”,您还可以检查 Google 文档中的文本是否存在大量内容是通过复制粘贴而非手动输入的。您可以在此处查看有关 Google 文档中 AI 检测功能的更详细说明。
 展示复制和粘贴功能的播放示例
展示复制和粘贴功能的播放示例
为什么Pangram在处理拟人化AI文本时无法达到100%的准确率?
Pangram 之所以无法完美检测人化 AI 文本,原因有以下几点。
-
Pangram 绝不愿在误报率上妥协。我们有几个内部模型虽能以近乎完美的准确率检测出“拟人化工具”生成的内容,但误报率较高。我们不会发布这些模型,因为对我们而言,确保真实的人类写作绝不会被误判为 AI 生成的内容,比捕捉所有拟人化工具的输出结果更为重要。
-
质量极差的“垃圾”文本肉眼即可轻易识别。在大多数Pangram未能检测出“人性化”输出的案例中,文本被严重篡改和混淆,几乎已不似英语。这些情况肉眼很容易发现,但算法却难以捕捉,因为制造无意义乱码的方式有无数种。 与其试图检测无意义文本,我们更倾向于将其排除在检测范围之外,因为试图区分人类产生的无意义文本与“人性化生成器”产生的无意义文本,本身就不是一个明确的定义问题。
Pangram 未来会提升其“humanizer”功能的性能吗?
是的,检测“Humanizer”是Pangram当前的研究重点,我们希望继续深入分析这些“Humanizer”工具的特性,并公开发布我们在检测“Humanizer”生成的文本方面的研究成果。如果Pangram要被视为学术诚信领域的可靠工具,我们就必须能够检测出由这些作弊工具生成的文本,以及直接从大型语言模型中复制粘贴的文本。
试试 Pangram的人工智能检测工具,将您的文档与 Humanizer 生成的内容进行对比检测。

布拉德利是一位人工智能研究员,也是工业领域深度学习产品开发的专家。他最近曾领导生成式人工智能药物发现公司Absci的深度学习研究团队,此前曾是特斯拉Autopilot核心计算机视觉团队的成员。
在攻读研究生期间,布拉德利曾与斯坦福视觉实验室合作,在深度学习研究领域发表了多篇论文。他拥有斯坦福大学物理学学士学位和人工智能硕士学位。除了人工智能,他还对教育和哲学充满热情,并且是一名狂热的高尔夫球手。




以获取我们的最新动态
