
Ver en el espacio Pangram
Análisis de las representaciones internas del Pangram 3.3.2
Por Elyas Masrour, Katherine Thai y Bradley Emi
Junio de 2026
Introducción
Desde el lanzamiento de ChatGPT en 2022, la redacción asistida por IA se ha expandido a un ritmo vertiginoso. Dado que el texto generado por IA está presente en gran parte de lo que leemos, ha quedado claro que algunos tipos de textos pierden su valor cuando los produce una máquina. En el ámbito académico, los ensayos tienen como objetivo fomentar el razonamiento de los estudiantes. En el mercado, las reseñas de productos son valiosas porque reflejan las experiencias de otras personas.
Pangram es una empresa de investigación que desarrolla modelos de detección basados en IA de última generación para abordar este problema. Nuestro producto estrella es un modelo de detección de texto generado por IA que destaca por sus bajas tasas de falsos positivos —líderes en el sector—, sus capacidades multilingües y su capacidad para diferenciar entre contenido generado por IA y contenido creado con la ayuda de la IA.
Desde la publicación de nuestro primer informe técnico en 2024, hemos tenido una perspectiva única para observar una oleada tras otra de avances en IA. Nuestros investigadores se han enfrentado a filtros de contenido excesivamente estrictos y han sido testigos de numerosos casos de colapso de modos, y esquivó oleadas de guiones largos y la palabra «delve».
Nuestro modelo estrella es un LLM que se ha ajustado específicamente para esta tarea de clasificación de secuencias. No utilizamos métricas personalizadas como la perplejidad o la irregularidad. Tampoco realizamos ninguna extracción manual de características. Contamos con un producto dirigido al cliente llamado «AI Phrases», en el que proporcionamos a nuestros usuarios información sobre las frases que aparecen con mayor frecuencia en los textos generados por IA. Sin embargo, estas no se utilizan directamente como características para el modelo. Al cabo de un tiempo, uno siente curiosidad: ¿qué ve el modelo?
Para nosotros, como investigadores, esta cuestión es importante. Tenemos un gran interés en evitar los atajos, corregir comportamientos no deseados del modelo y comprender este problema en profundidad. En esta entrada, describiremos nuestras primeras iniciativas en materia de interpretabilidad mediante el análisis a nivel de documento.
Datos
Hemos creado un conjunto de datos de interpretabilidad a partir de muestras retenidas dentro del dominio, extraídas de nuestro conjunto de entrenamiento de producción. El explorador interactivo de esta página utiliza un subconjunto equilibrado de 5.000 documentos, repartidos a partes iguales entre humanos e IA, a lo largo de 20 capas pares. Las muestras de IA abarcan las variantes de modelo que se indican a continuación, correspondientes a las seis familias de modelos utilizadas para la prueba del clasificador.
Modelos
- Claude 3.7 Soneto
- Claude Soneto 4
- Claude Sonnet 4,5
- Claude Opus 4
- Claude Opus 4.1
- Claude Opus 4.5
- GPT-3.5 Turbo (noviembre de 2023)
- GPT-3.5 Turbo (enero de 2024)
- GPT-4 (marzo de 2023)
- GPT-4 (junio de 2023)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- Gemini 2.5 Flash
- Géminis 2.5 Pro
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- Qwen 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
Dominios de origen
- Noticias
- Resúmenes científicos
- Opiniones sobre productos
- Opiniones sobre empresas
- Reddit: Escritura creativa
- Reddit ELI5
- Libros (autoeditados)
- Libros (Proyecto Gutenberg)
- Wikipedia (inglés)
- Wikipedia (multilingüe)
- Lang-8 (ESL)
Pangram 3.3.2: Descripción general
Pangram 3.3.2 es un modelo de detección de IA lanzado por Pangram Labs en 2026. Utiliza el mismo modelo subyacente que Pangram 3.3, con correcciones de errores posteriores que mejoran su rendimiento. Pangram 3.3 sucedió a Pangram 3.2 y mejoró la recuperación en los resultados de los modelos de lenguaje a gran escala (LLM) más recientes, el texto humanizado y el contenido extenso generado por IA, al tiempo que redujo los falsos positivos en textos escritos en inglés no nativo.
Ficha del modeloLee la ficha del modelo Pangram 3.3Consulta los detalles de la versión de Pangram 3.3.2.Leer el artículoEl trabajo sobre la interpretabilidad sigue en curso. A lo largo de este artículo, también aplicamos nuestros métodos de forma retroactiva a Pangram 3.2 y Pangram 3.1.
Métodos
Activaciones
La arquitectura de EditLens es un sistema de clasificación basado en «buckets» que se reduce a un único puntuación_de_asistencia_de_IA. En este proyecto, descartamos el resultado final del modelo y, en su lugar, nos centramos en las representaciones internas que aprende el modelo. Para analizarlas, recopilamos las activaciones realizando una pasada hacia adelante del modelo con un documento de entrada determinado y guardando la representación oculta del modelo en varias capas internas. En este proyecto, extrajimos las activaciones de cada documento, para cada capa par de toda la red.
Reducción de la dimensionalidad
Cada vector de activación extraído tenía 5.120 dimensiones. Para comprender mejor las representaciones, utilizamos varias técnicas de reducción de dimensionalidad.
PCA
El análisis de componentes principales (PCA) es la proyección lineal más sencilla: identifica las direcciones de máxima varianza en el espacio de activación. En este proyecto, observamos que, hacia el final de la red, la mayor parte de la varianza se concentra en los componentes principales 1 y 2, por lo que los representamos gráficamente uno frente al otro.
UMAP
UMAP ofrece una representación no lineal diseñada para preservar la estructura de vecindad. Si dos documentos están próximos entre sí en el espacio interno del modelo, UMAP intenta mantenerlos próximos en el espacio bidimensional. Sin embargo, no se deben sobreinterpretar los ejes exactos ni las distancias entre los clústeres.
t-SNE
El t-SNE es otro método de proyección no lineal que resulta eficaz para revelar agrupaciones locales. A efectos de este proyecto, utilizamos el t-SNE para comprobar si los grupos que revisten importancia semántica —como las familias de modelos o las etiquetas «humano»/«IA»— se agrupan de forma visible a medida que la red se hace más profunda.
Sondas lineales
Utilizamos sondas lineales para cuantificar los resultados cualitativos que observamos en nuestros métodos de reducción de dimensionalidad. Para cada capa, nos preguntamos si un clasificador sencillo puede recuperar una etiqueta objetivo a partir de los vectores de activación de dicha capa. Una alta precisión de la sonda significa que la distinción relevante ya está codificada en una dirección linealmente accesible del espacio de representación.
La tarea de detección de IA
Precisión binaria
Para comprender cómo se logra la separación final de clases a lo largo de la red, entrenamos sondas lineales en cada capa. El entrenamiento se realiza con 500 muestras, repartidas equitativamente entre humanos e IA, con una división de 80:20 entre entrenamiento y prueba. Observamos que, incluso en las primeras capas de la red, el rendimiento ya es sólido: alcanzamos una precisión de 0,83 justo después de la capa 2. Esto coincide con nuestra intuición, ya que los modelos de «bag-of-words» suelen ser líneas de base válidas para la tarea de detección de IA. A lo largo de la red, la precisión va aumentando hasta alcanzar un máximo de 1,0 en la capa 24.
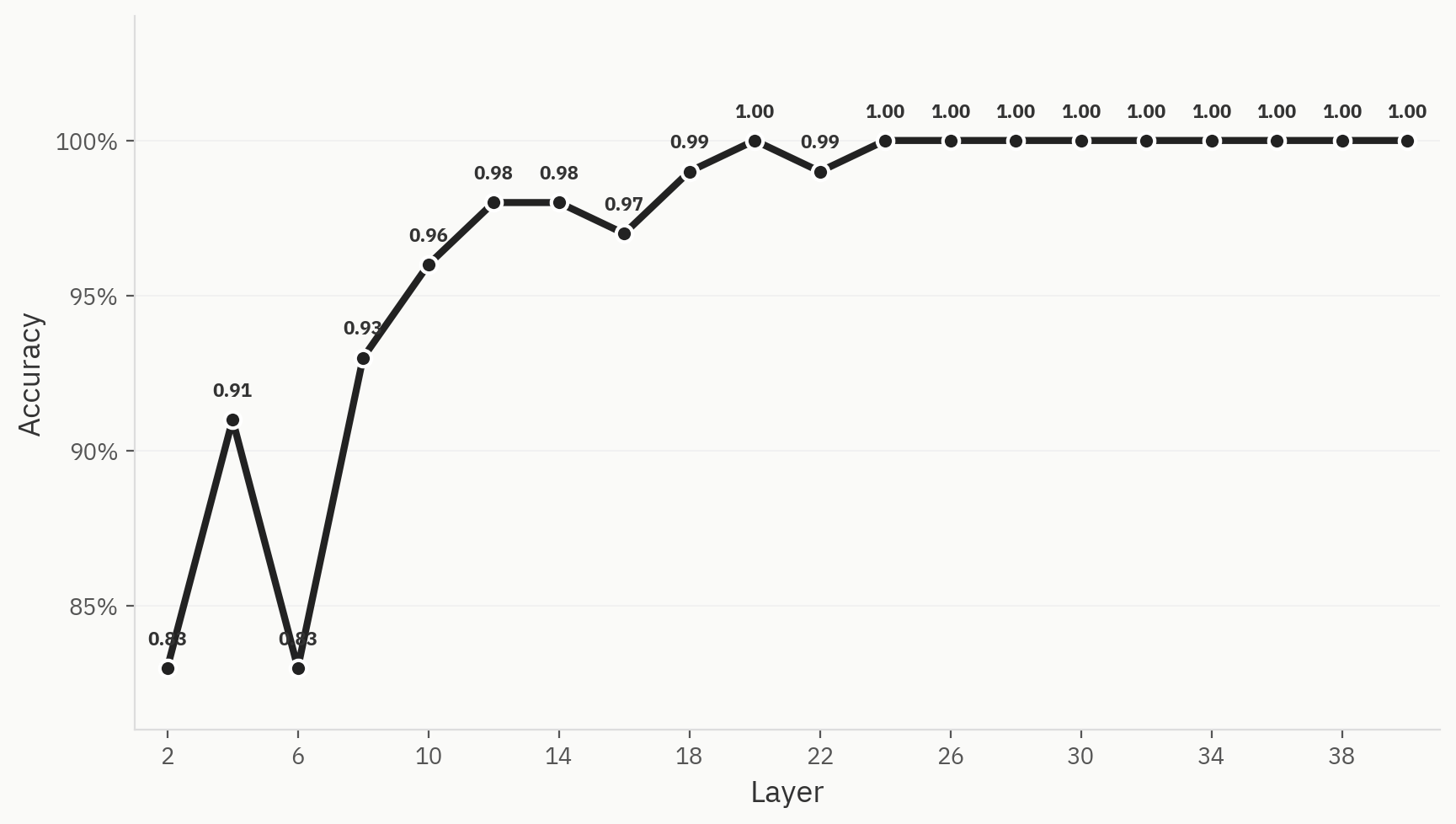
Fig. 3. Esta separación se aprecia claramente en los tres métodos de reducción de dimensiones.
Clasificación LLM
En los gráficos de t-SNE y UMAP, observamos que los documentos parecían agruparse según el modelo que los había generado. Esto nos sorprendió. Las versiones anteriores de Pangram contaban con un módulo de clasificación de modelos de lenguaje grande (LLM) independiente, pero esa tarea concreta se había descartado hacía tiempo. En su proceso de entrenamiento, a Pangram 3.3.2 no se le proporcionan etiquetas que correspondan al modelo de origen de un documento generado por IA.
Aun así, se formaron agrupaciones en torno a la familia de modelos de origen. Y lo que es aún más interesante, las agrupaciones parecen surgir a lo largo de todas las capas de la red.
Aparición de agrupaciones de modelos
Colorea las mismas representaciones según la familia de modelos para ver cómo la geometría a nivel de proveedor se manifiesta en todas las capas.
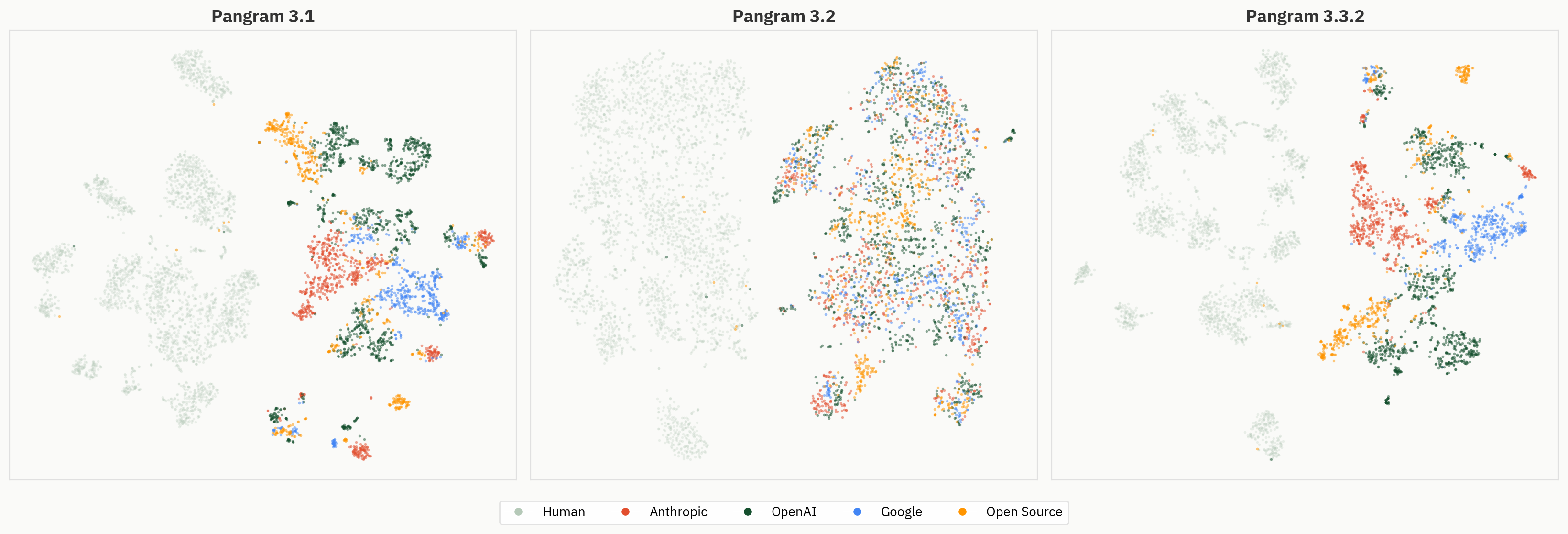
Fig. 4: Representaciones de las capas 2 a 40, clasificadas por familia de modelos. Los grupos a nivel de proveedor se hacen más evidentes en las capas posteriores.
Sonda
Para cuantificar este fenómeno, entrenamos un clasificador con seis familias de modelos (Anthropic, OpenAI, Google, Qwen, Llama y DeepSeek) utilizando 500 muestras por familia de modelos —un total de 3.000 muestras—, con una división entre entrenamiento y prueba de 80:20. Hemos comprobado que, efectivamente, podemos entrenar un modelo capaz de clasificar la familia de modelos de origen de un documento concreto utilizando únicamente activaciones de pangramas, con una precisión máxima top-1 del 91 %.
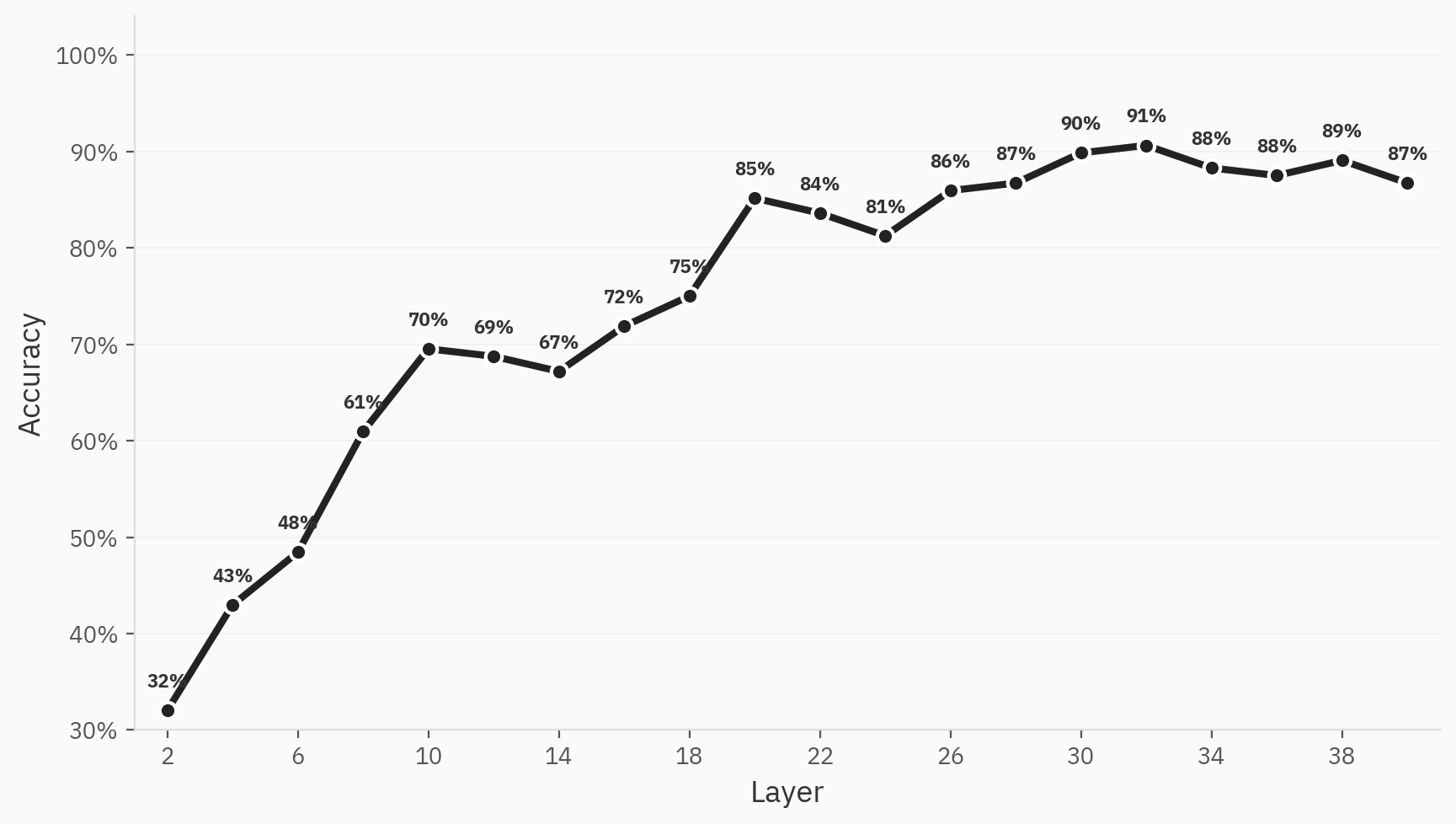
La aparición no está garantizada
Nuestros experimentos iniciales sobre interpretabilidad incluyeron pruebas con varios modelos. Para nuestra sorpresa, la aparición de una capacidad de «clasificación de modelos de lenguaje a gran escala» fue uno de los únicos hallazgos de este proyecto que varió de forma significativa entre los distintos modelos.
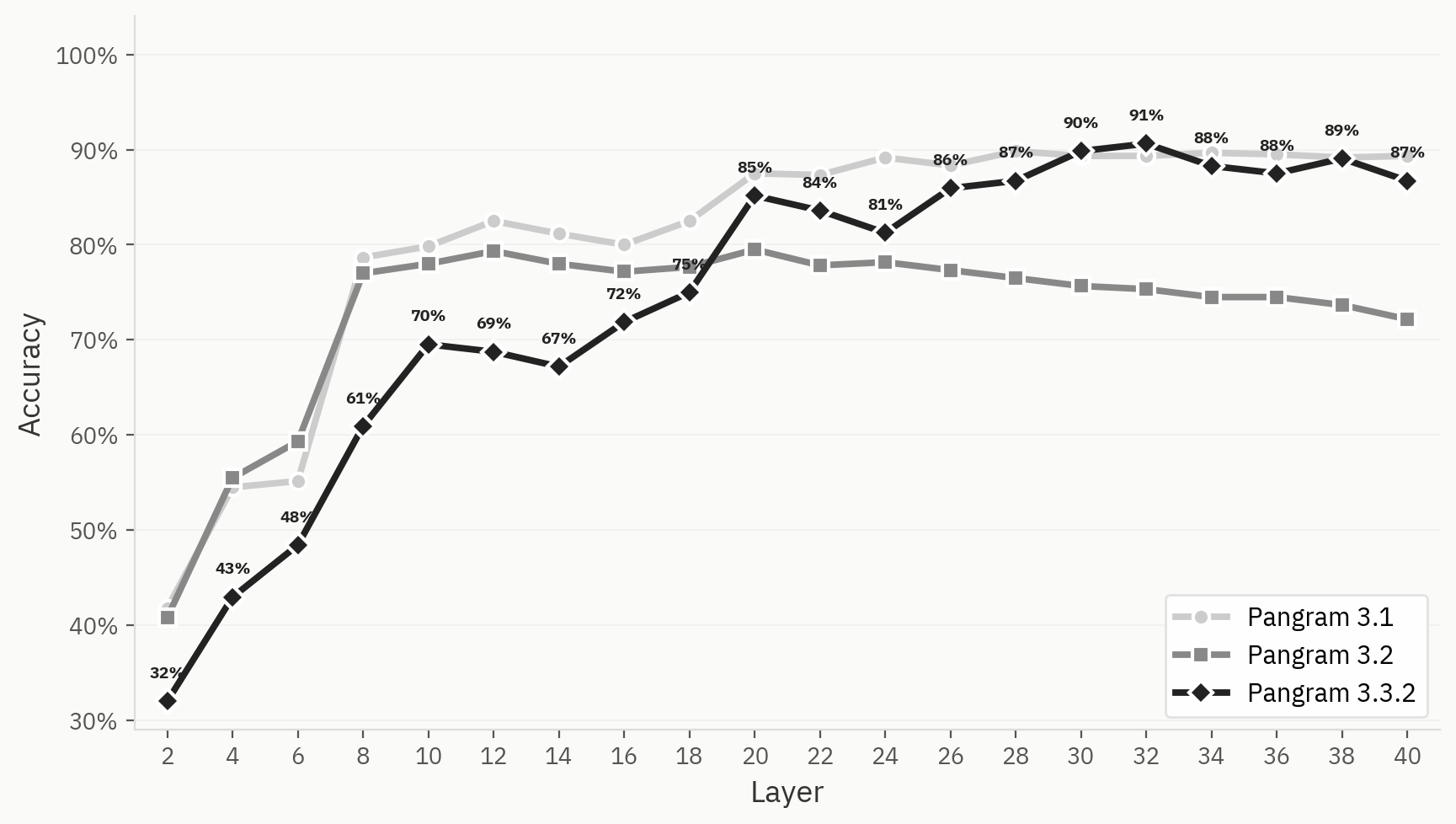
La siguiente figura compara el comportamiento de agrupación de Pangram 3.1, 3.2 y 3.3.2. A pesar de que el modelo obtiene mejores resultados que el 3.1 en la tarea binaria «humano-IA» en nuestras evaluaciones internas de validación, los grupos del modelo son, en general, menos definidos en Pangram 3.2 que en Pangram 3.1 o 3.3.2.
Para ilustrar mejor esta diferencia, comparamos la prueba del clasificador LLM en Pangram 3.1, 3.2 y 3.3.2. Las tres mejoran su precisión top-1 en las primeras capas, pero la prueba de Pangram 3.2 empieza a disminuir a partir de la capa 12, mientras que las de Pangram 3.1 y 3.3.2 se mantienen altas.
Humanizadores
Los «humanizadores» son una clase de herramientas adversarias diseñadas para modificar el texto generado por IA de tal forma que eluda los detectores de IA. Para ver dónde se sitúa el texto humanizado en relación con el texto humano y el generado por IA en el espacio de activación, hemos creado un conjunto de datos independiente de humanizadores, que consta de unas 1.900 muestras, distribuidas de forma más o menos equilibrada entre tres modelos generativos (Claude Sonnet 4.5, Gemini 2.5 Pro y GPT-5), diez servicios de humanización diferentes y los mismos dominios de origen que el conjunto de datos de interpretabilidad original. Debido a los riesgos adversarios, no revelamos qué servicios utilizamos.
Cómo interpreta el modelo los «humanizadores»
Es cierto que algunas muestras de nuestro conjunto de datos «humanizer» resultan difíciles de detectar para nuestro modelo. En este caso, utilizamos la misma prueba lineal para la tarea «humano/IA», salvo que el texto humanizado se etiqueta como «IA», tal y como hacemos en la configuración de entrenamiento original. Observamos que, incluso desde la primera capa, el texto humanizado se interpreta sistemáticamente como más humano que su equivalente directo generado por IA.
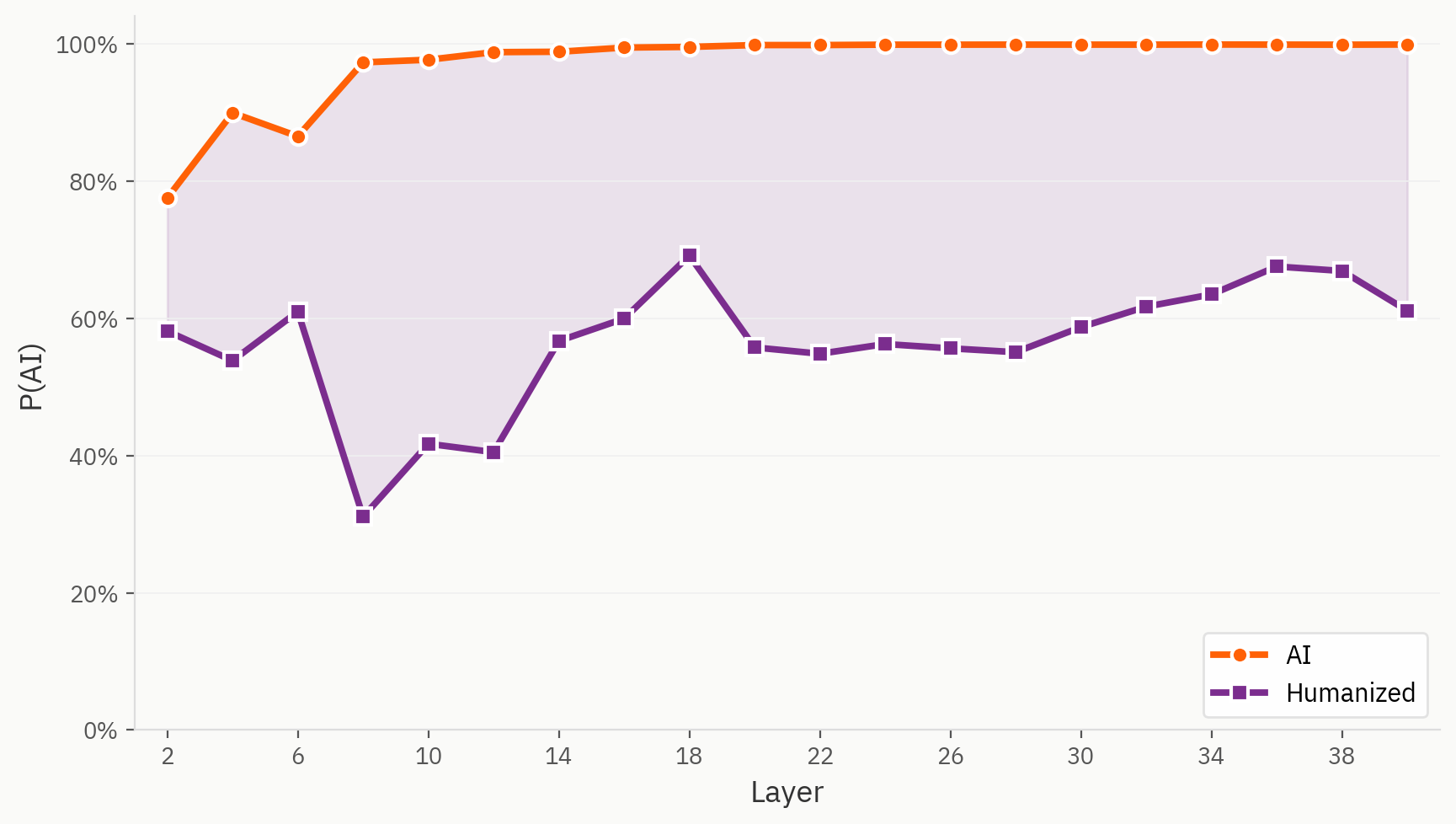
Dónde se encuentran los «humanizadores» en el espacio de incrustación
Sin embargo, cuando analizamos más allá del resultado final, encontramos una representación mucho más rica del texto humanizado. A continuación, aplicamos nuestros métodos de reducción de dimensionalidad a los textos humanos, de IA y humanizados. Desde un punto de vista cualitativo, podemos observar que los humanizadores tienden a ocupar partes separadas del espacio de activación y forman agrupaciones fuera de las regiones de los textos humanos y de IA.
Nuestra hipótesis es que, a pesar de no disponer de etiquetas para el texto humanizado, el modelo es capaz de distinguir entre texto humanizado, texto escrito por humanos y texto generado por IA. Sin embargo, en el resultado final, el modelo se ve obligado a suprimir esa señal y lo hace de forma inconsistente.
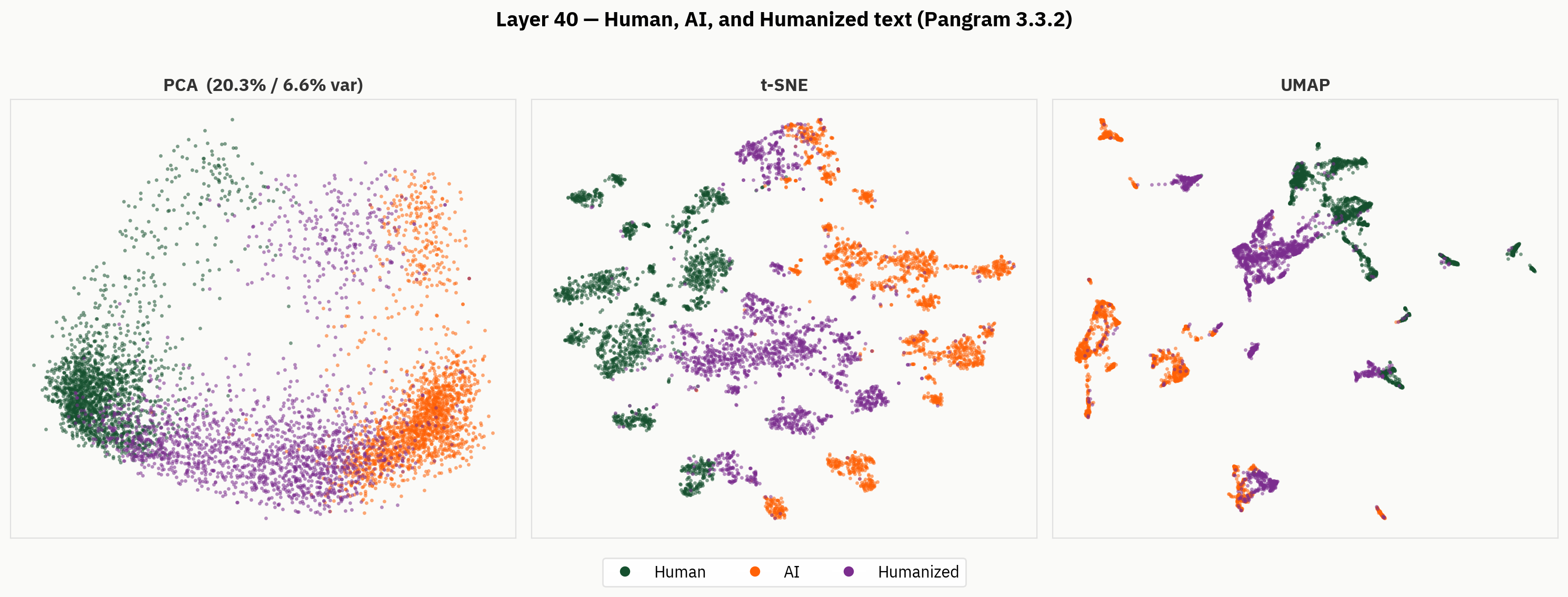
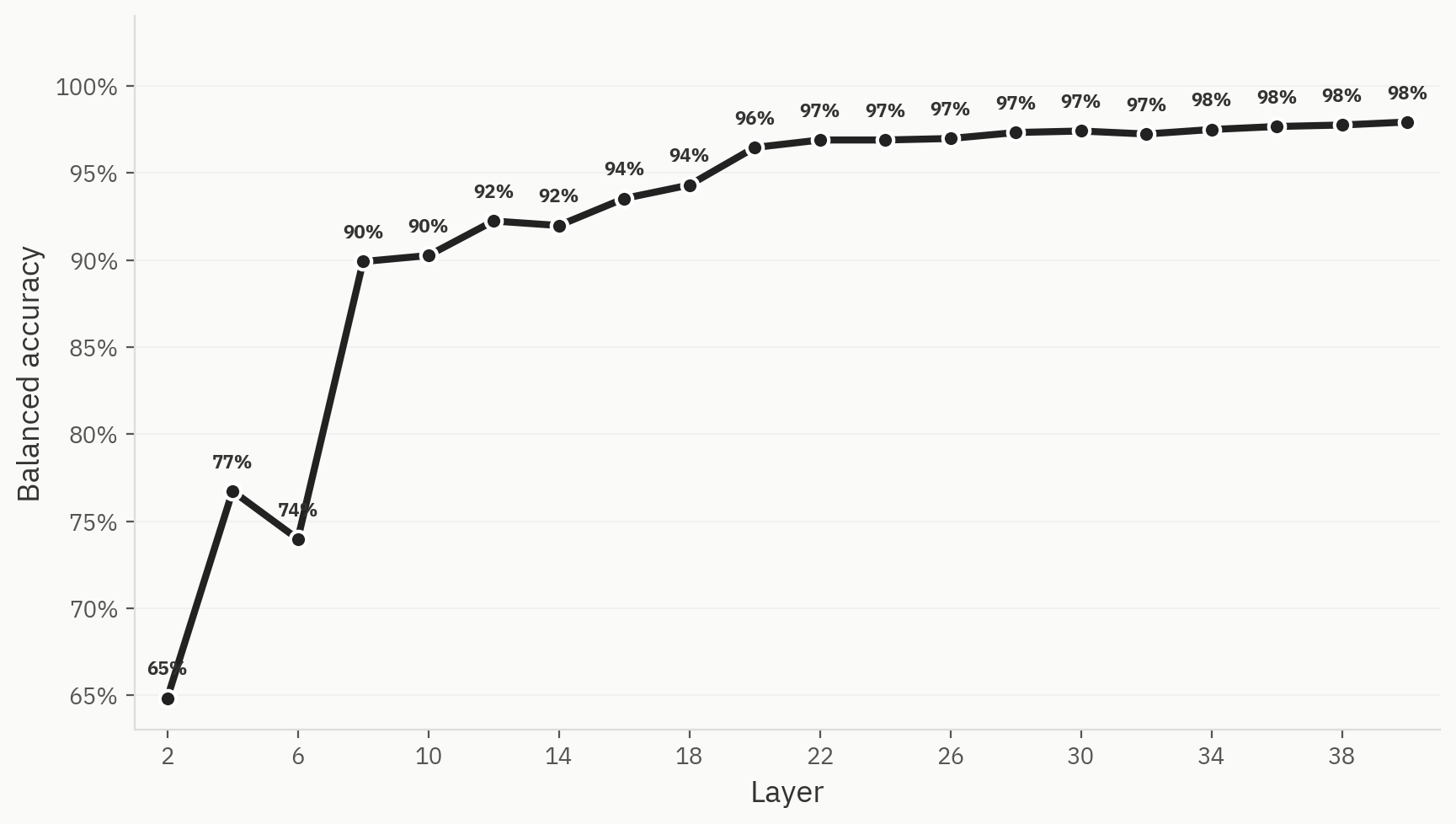
Sonda
Para validar esta hipótesis, entrenamos una sonda lineal de tres vías con etiquetas para texto generado por IA, texto humano y texto humanizado. La sonda alcanza una alta precisión top-1 en las primeras capas de la red y, finalmente, se estabiliza en el 98 %.
Conclusión
Nuestro trabajo sugiere que las representaciones internas de Pangram contienen más estructura de la que revela por sí sola la lectura binaria final. A lo largo de las distintas capas, observamos que los documentos humanos y los generados por IA se separan, que surge información sobre la familia de modelos y que el texto humanizado ocupa su propia región en el espacio de activación. Estos hallazgos son preliminares, pero nos proporcionan un mapa útil para comprender qué aprende el modelo antes de sintetizarlo todo en una única puntuación de detección.
Esta entrada muestra solo los primeros pasos de nuestro trabajo en materia de interpretabilidad, pero, a nivel interno, estamos entusiasmados e interesados en esta línea de investigación.
Nuestra visión sobre la interpretabilidad y la explicabilidad de los modelos Pangram es que estos puedan:
- Facilitar una mejor comprensión interna del comportamiento del modelo.
- Aporta pruebas que respalden los resultados individuales de Pangram y ofrécelas explicaciones más claras.
Si eres investigador y te interesa la interpretabilidad, la investigación sobre la detección de la IA o cualquier otro aspecto de este trabajo, ponte en contacto con nosotros en elyas@pangram.com.
