Detección de IA para equipos de aprendizaje automático y de datos
Detector de IA para ingenieros de aprendizaje automático y científicos de datos
Optimiza el entrenamiento de los modelos de lenguaje grande (LLM) y la selección de datos. Evita el colapso del modelo filtrando el texto sintético de tus conjuntos de datos de preentrenamiento o ajuste fino con una precisión del 99,98 % y un rendimiento de API de alto rendimiento.
Desarrollado por investigadores de Google, Tesla y Stanford. Validado por la ICLR y la Universidad de Maryland.
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")marcas internacionales

















Casos de uso
No entrenes tus modelos
con datos de mala calidad.
El texto sintético está contaminando los conjuntos de datos públicos. Filtra el contenido generado por IA de tus procesos de entrenamiento con el motor de detección de IA más preciso para mantener la pureza del corpus.
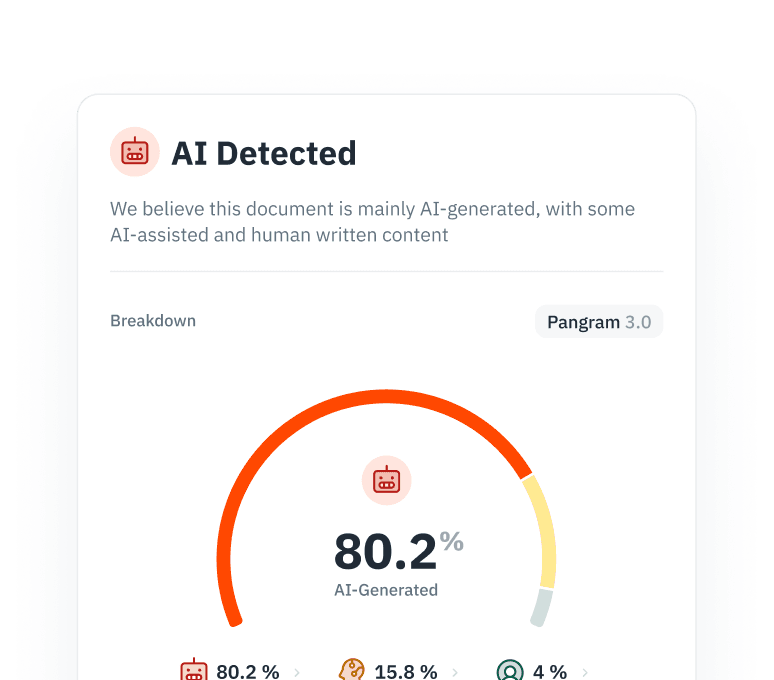
Evitar el colapso del modelo
El entrenamiento recursivo con contenido generado por IA reduce el rendimiento y la diversidad del modelo. Identifica y filtra el contenido escrito por IA de tus procesos de extracción de datos para garantizar la pureza del corpus.
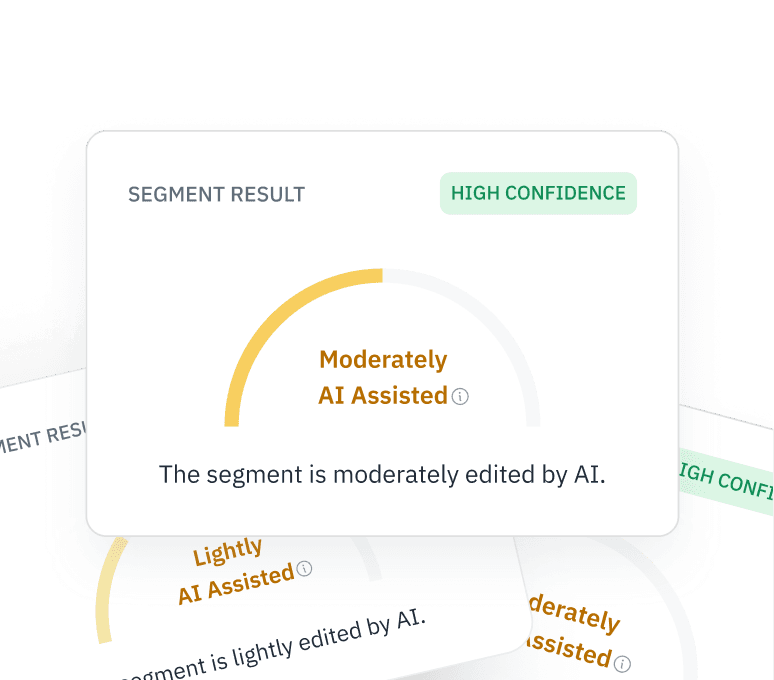
Verificar los datos de entrada de RLHF
Asegúrate de que tus datos de retroalimentación humana (RLHF) procedan realmente de personas. Detecta si los colaboradores de plataformas colaborativas están utilizando ChatGPT para generar respuestas en tus tareas de ajuste fino.
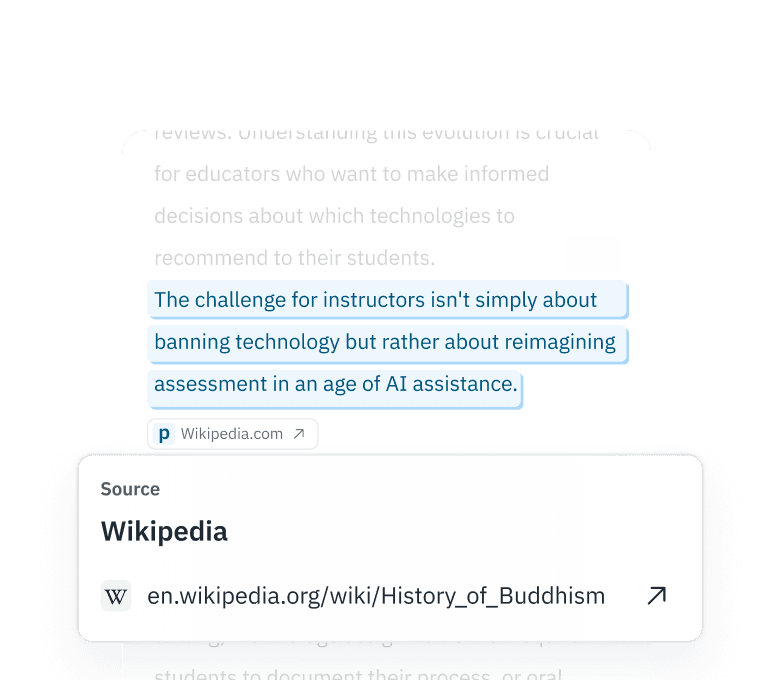
Interpretabilidad granular
No te conformes con una clasificación binaria. Nuestra API Premium ofrece probabilidades a nivel de token, lo que te permite conservar los segmentos revisados por personas y descartar el «material de baja calidad» totalmente sintético.
Enfoque técnico
Una marca en la que puedes confiar
Diseñado para ingenieros que necesitan poder confiar en el filtrado de sus datos. Nuestro modelo aborda los falsos positivos, la robustez ante ataques adversarios y los resultados cambiantes de la IA.

Minería de negativos duros
Entrenamos con «negativos duros» —textos escritos por personas con un estilo formal o repetitivo— para minimizar los falsos positivos y garantizar que no se descarten datos valiosos generados por personas.
Robustez ante ataques adversarios
Pangram gestiona contenidos generados por IA que han sido parafraseados o modificados. Nuestros modelos se entrenan con «humanizadores» y ataques adversarios para detectar textos sintéticos ofuscados.
Preparación para el futuro
Detecta texto generado por los modelos más recientes, como GPT-5, Claude 3.5 y Llama 3, lo que garantiza que tus filtros se mantengan a la vanguardia de los últimos avances tecnológicos.
Integración
Diseñado para tu canalización de datos de «
»

01
SDK de Python
Instala pangram-sdk e integra la detección en tus pipelines de Airflow o Databricks con solo unas pocas líneas de código. Optimizado para la gestión de grupos de conexiones y la gestión de errores.
Ver documentos →
02
API de alto rendimiento de
Procese conjuntos de datos masivos con baja latencia. Nuestra infraestructura admite el procesamiento por lotes y garantiza el rendimiento, gestionando millones de solicitudes para operaciones de scraping empresarial.
Obtener clave API →
03
Seguridad y cumplimiento normativo de la Ley de Protección de Datos de California (
)
Contamos con la certificación SOC 2 Tipo 2. Ofrecemos terminales privadas y políticas estrictas de retención de datos; nunca entrenamos el sistema con sus datos privados.
Más información →
Preguntas frecuentes
Preguntas frecuentes sobre la detección mediante IA
Preguntas frecuentes sobre la detección de IA para ingenieros de aprendizaje automático
y científicos de datos.
Sí. Puedes instalar el pangram-sdk para integrar la detección en los flujos de trabajo de Airflow o Databricks con solo unas pocas líneas de código. Nuestra API está optimizada para operaciones de scraping empresarial de alto rendimiento y admite millones de solicitudes con baja latencia.
Descubre más
Detección mediante IA para
todas las organizaciones
Para desarrolladores
Detección de código generado por IA para desarrolladores y equipos de ingeniería. Detecta código generado por IA a partir de ChatGPT, Copilot y Claude en Python, Java, C++ y otros lenguajes.
Más información →Para la moderación de contenidos
Moderación de contenidos mediante IA para equipos de confianza y seguridad. Detecta reseñas generadas por IA, comentarios falsos y contenido sintético a gran escala a través de la API.
Más información →Para universidades
Detección de IA para universidades y centros de educación superior. Verifica los trabajos de los estudiantes, revisa los trabajos de investigación presentados y protege la reputación de la institución.
Más información →Limpia tus datos de entrenamiento hoy mismo
Evita el colapso del modelo, verifica las entradas de RLHF y filtra el contenido sintético de tus conjuntos de datos con una precisión del 99,98 %.
