Esta publicação no blogue foi republicada a partir do Substack do autor. Siga-o aqui!
Divulgação de financiamento: Os créditos do OpenRouter foram fornecidos pela Pangram para a realização desta investigação, e a ideia original para esta investigação foi sugerida por Max Spero, CEO da Pangram. Esforcei-me ao máximo por manter a imparcialidade e o texto que se segue reflete as minhas opiniões genuínas.
Na altura em que o ChatGPT foi lançado, surgiram várias notícias de grande repercussão em que as pessoas tentaram utilizá-lo como um detetor de IA — ou seja, introduzindo-lhe um texto e perguntando-lhe diretamente se este tinha ou não sido gerado por IA. O Washington Post noticiou o caso de um professor da Texas A&M que tinha atribuído notas zero a vários alunos com base no facto de o ChatGPT ter reivindicado a autoria dos seus trabalhos. Uma professora assistente da Universidade de São Francisco disse aos seus colegas que «Tudo o que temos de fazer é perguntar “Foste tu que escreveste isto?” e, em seguida, copiar e colar o trabalho do aluno na caixa de comando» — apenas para, mais tarde, escrever um post num blogue sobre o número absurdo de falsos positivos que isto gerou. Mais recentemente, quando o vencedor de um concurso de contos publicado pela Granta foi acusado de utilizar IA, a Granta recorreu ao Claude para investigar se o texto vencedor tinha, de facto, sido gerado por IA.
Embora estas tentativas possam parecer ingénuas e talvez um pouco divertidas — afinal, o ChatGPT não tem como verificar se foi ele a gerar um texto e tem de adivinhar com base nas «vibes» (tal como um ser humano faria). Mas não é uma inferência irracional para uma pessoa sem conhecimentos técnicos: o ChatGPT consegue escrever histórias como um autor humano, e os autores humanos conseguem reconhecer/lembrar-se do seu trabalho, então porque não o ChatGPT? Além disso, existem outras formas de verificação da geração por IA, como o SynthID para imagens, áudio e vídeo. Porque não uma para texto? A resposta, de que o SynthID requer uma marca d’água detetável, não é óbvia. Para tornar tudo ainda mais confuso, se perguntarmos ao Gemini se uma imagem foi gerada por IA, ele responde simplesmente: «Sim, a maior parte ou a totalidade desta imagem foi gerada ou editada utilizando a IA do Google.» — ocultando a verificação da marca d’água do SynthID e dando a impressão de que o Gemini consegue simplesmente deduzir isso visualmente com base nas «vibes». Assim, para esclarecer toda esta ambiguidade:
- Os LLMs não têm memória episódica da geração de um texto, pelo que não o conseguem identificar pelo facto de o terem escrito.
- A marca d'água em texto já existe — como o SynthID Text do Google —, mas requer que o texto tenha sido gerado por um sistema de IA participativo com a funcionalidade de marca d'água ativada. Por conseguinte, não se trata de uma solução universal para textos arbitrários.
- Assim, a deteção de texto por IA deve ser feita com base na intuição — seja a intuição humana, algoritmos de aprendizagem automática treinados (como o Pangram) ou a intuição de um LLM.
E, historicamente, as intuições dos LLMs têm sido más! Isto faz todo o sentido — a primeira geração de LLMs destinados ao consumidor — o GPT-3.5 e o GPT-4, talvez o Claude 3 — foram todos treinados com dados anteriores à inundação da Internet por IA. A sua exposição a texto gerado por IA foi provavelmente limitada, se não inexistente, pelo que, naturalmente, o seu desempenho em tarefas «zero-shot» seria fraco. Mas isto levanta a questão: será que os LLMs mais modernos, treinados com dados mais recentes, teriam uma intuição melhor?
Adam Kucharski investigou esta questão no seu Substack, e os resultados iniciais são promissores: o Claude conseguiu distinguir dois inícios de histórias gerados por IA de um escrito por um ser humano, identificou dez histórias escritas pelo GPT-5.5 como sendo da autoria de IA com uma probabilidade >80% e atribuiu uma probabilidade não superior a 22% de terem sido escritas por IA a dez histórias selecionadas dos escritos pessoais de Kucharski. Ainda mais promissor foi o facto de Kucharski ter pedido ao GPT-5.5 para «melhorar» cada uma das suas dez histórias, tendo cinco passado de escritas por humanos para geradas por IA. Isto representa vinte e três acertos na classificação direta de IA e cinco acertos/cinco erros na classificação de edição por IA.
Isto levanta a questão: quando é que esta capacidade de deteção de IA surgiu? Para testar isto, utilizei o conjunto de dados aberto «editlens-iclr» da Pangram, que contém inúmeros exemplos de passagens escritas por humanos e versões geradas por IA dessas mesmas passagens. Para começar, selecionei uma amostra piloto de 100 passagens — 50 escritas por humanos e 50 geradas por IA — e avaliei uma série de modelos — tanto históricos como atuais — quanto à precisão em «zero-shot». Para maximizar a classificação baseada em «vibes» — a intuição que eu estava a tentar detetar —, realizei esta experiência com o raciocínio desativado, sempre que possível, e com instruções rigorosas para responder apenas com uma palavra. Isto resultou no seguinte formato de prompt «zero-shot»:
 Formato de prompt «zero-shot»
Formato de prompt «zero-shot»
Os resultados são apresentados abaixo e são bastante impressionantes:
 Desempenho «zero-shot» por data de lançamento
Desempenho «zero-shot» por data de lançamento
Vemos que o GPT-4 começa com 52% — um resultado não superior ao do acaso —, o que corresponde à intuição de 2023/2024 de que a IA não tem capacidade para detetar a sua própria escrita (o GPT-3.5-Turbo obteve 49% e não está incluído no gráfico acima). Avançando para a primavera e o verão de 2025, o GPT-4.1 atinge 71%, o Sonnet 4 62% e o Opus 4 69%. O que se segue é uma rápida subida da capacidade desde meados do verão de 2025 até ao início de 2026 — altura em que tanto a série GPT como a série Claude atingem precisões superiores a 90% nesta amostra de 100 exemplos. Este salto também ocorre, embora um pouco mais tarde, na série Qwen Plus, que dispara de 55% de precisão na versão Qwen3.5 Plus para 83% na Qwen3.6 Plus — lançada apenas dois meses depois.
Pode-se questionar se esta vantagem do «zero-shot» se deve principalmente à familiaridade com conteúdos gerados por IA ou se é simplesmente uma diferença de inteligência — com modelos de ponta mais inteligentes a funcionarem como melhores classificadores. Para testar isto, podemos verificar como a inserção de exemplos «few-shot» (retirados do conjunto de treino e aleatorizados por pergunta, claro) no contexto altera a precisão. Isto atualiza o nosso formato de prompt para o seguinte modelo «few-shot»:
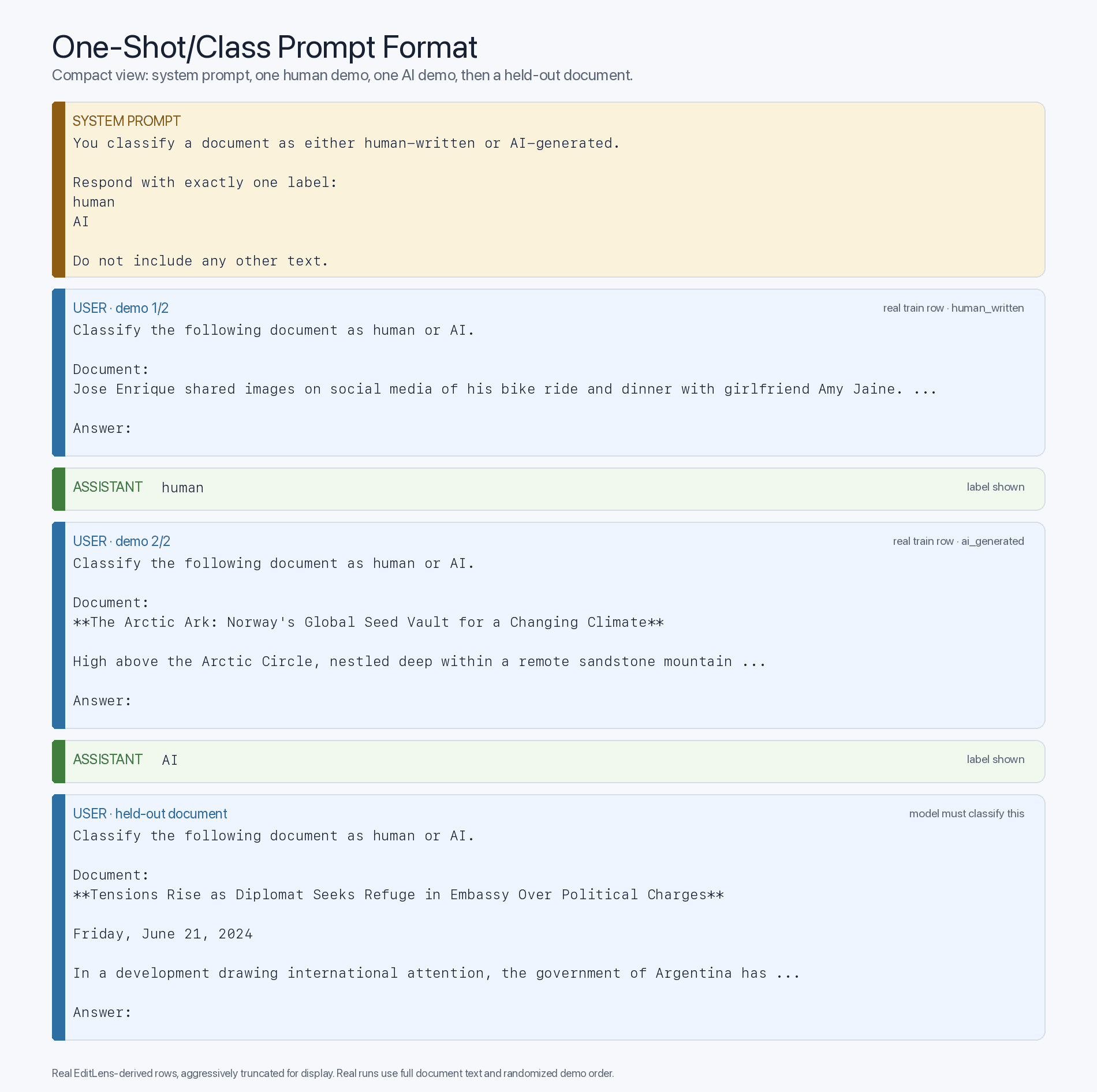
Se, neste formato de prompt com poucos exemplos, os modelos mais antigos melhorarem drasticamente com a exposição aos mapeamentos adequados entre entradas e rótulos, então o gargalo é a exposição ao pré-treino, e não a inteligência. E é exatamente isso que observamos:
 Gráfico ICL do GPT por pergunta
Gráfico ICL do GPT por pergunta
Enquanto o GPT-4 em modo «zero-shot» atinge apenas 52%, no modo «4-shot»1 alcança 85%. É evidente que o GPT-4 consegue aprender, no contexto, a distinguir entre textos gerados por IA e textos escritos por humanos — simplesmente não possui o conhecimento pré-treinado inato de como o fazer. Isto é sublinhado pelo facto de o desempenho «zero-shot» melhorar de forma quase monótona à medida que a geração do modelo avança, mas o desempenho «few-shot» permanecer praticamente estável após o ~GPT-5.1 e só registar um aumento notável para 99% no GPT-5.5. Esta evidência sugere fortemente que o ingrediente que faltava para que os LLMs se tornassem detetores de IA «zero-shot» minimamente decentes era simplesmente dados de pré-treino adequados (ou exemplos de referência no contexto), e não qualquer limitação intrínseca da sua natureza ou inteligência.
Para investigar mais a fundo o impacto da aprendizagem «few-shot» em contexto na capacidade de deteção de ICL, precisei de um conjunto mais difícil para extrair mais sinal — afinal, se os modelos de ponta atuais atingirem 95% numa avaliação de 100 perguntas, isso deixa de ser útil. Para construir este conjunto difícil, filtrei o conjunto de dados Pangram para manter apenas os exemplos que enganaram o Qwen 3.7 Plus duas vezes (com temp=0,7). Isto proporcionou-me 3 503 amostras geradas por IA e 763 amostras escritas por humanos — que depois equilibrei por classe (através de amostragem aleatória uniforme) para produzir o conjunto de dados difícil final, composto por 763 amostras geradas por IA e 763 amostras escritas por humanos.
Avalio tanto o Sonnet 4.6 como o GPT-5.5 neste conjunto de dados complexo, com 0, 1, 2, 4 e 8 tentativas, com o raciocínio desativado e com o raciocínio ativado (esforço médio para o GPT-5.5 e raciocínio alargado simples para o Sonnet 4.6, por uma questão de relação custo-eficácia):
 Gráfico do Soneto 4.6 revisto
Gráfico do Soneto 4.6 revisto
 Gráfico GPT-5.5 revisto
Gráfico GPT-5.5 revisto
Verificamos que o GPT-5.5 supera largamente o Sonnet 4.6 no teste «zero-shot» — o que era de esperar, uma vez que o GPT-5.5 foi lançado em abril de 2026 e o Sonnet 4.6 em fevereiro de 2026. É de salientar que esta diferença diminui consideravelmente com o ICL — enquanto (com o raciocínio desativado) o GPT-5.5 atinge 86,8% no modo «zero-shot» contra os 72,9% do Sonnet 4.6, com 8 exemplos, o GPT-5.5 atinge 96,2% contra os 93,8% do Sonnet 4.6. Isto reforça ainda mais a ideia de que grande parte da deteção de IA é uma capacidade que, tal como quase qualquer outro tipo de classificação de texto, pode ser adquirida no contexto.
É de salientar que, embora o raciocínio resulte num aumento significativo de alguns pontos percentuais para o GPT-5.5, só ajuda realmente o Sonnet 4.6 no regime «zero-shot» (proporcionando +2,2%) e, a partir daí, ou prejudica ligeiramente ou ajuda ligeiramente. Os testes estatísticos confirmam isto — após a correção de Bonferroni, o benefício do raciocínio para o GPT-5.5 continua a ser estatisticamente significativo em 0, 1, 2 e 8 shots, enquanto o Sonnet 4.6 apenas apresenta um efeito significativo em zero shots.
Isto parece sugerir que, embora o processamento em tempo de teste possa ajudar na classificação da escrita gerada por IA, apenas algumas famílias de modelos têm a capacidade de treino necessária para o aplicar de forma eficaz em relação à intuição imediata, e os ganhos não são significativos quando comparados com a simples apresentação de mais exemplos contextuais a partir dos quais aprender. Trabalhos futuros poderiam testar o GPT-5.5 em níveis de raciocínio «high» ou «xhigh» para verificar se os ganhos se mantêm.
Em resumo, verificámos que os LLMs modernos conseguem distinguir com sucesso textos gerados por IA de textos escritos por humanos, que esta capacidade se deve provavelmente a uma maior exposição, durante o pré-treino, a conteúdos gerados por IA, e que beneficia ligeiramente da capacidade de computação na fase de teste, mas significativamente de mais exemplos contextualizados (ao ponto de LLMs mais antigos, como o GPT-4, conseguirem aprender a fazê-lo a partir de uma linha de base de nível aleatório, sem treino prévio). Isto contraria a narrativa anterior de que o ChatGPT era incapaz de indicar se um texto tinha sido gerado por IA. No entanto, na prática, continuaria a não os utilizar como detetores de IA — no conjunto de dados difícil, o modelo com melhor desempenho — o GPT-5.5 com raciocínio médio — apresenta uma taxa de falsos positivos de 4,59%, o que é inaceitável mesmo para uma utilização ocasional (para contextualizar, note-se que um estudo recente revelou que a taxa média de falsos positivos de cinco anotadores humanos especializados foi de 5,6%, mas um conjunto destes anotadores apresentou uma FPR de 0%). Se estiver à procura de um detetor fiável, recomendo o Pangram, com as ressalvas discutidas no meu artigo «In Defense of Pangram ». De qualquer forma, continuo a achar esta capacidade bastante intrigante — e achei importante documentá-la, dado que a sabedoria comum dos últimos anos tem sido a de que os LLMs são totalmente incapazes de detetar textos gerados por LLMs. Em vez disso, é melhor considerar os LLMs como estando, grosso modo, ao nível de «humanos bons a especialistas» na deteção de textos gerados por IA. São bastante precisos, mas apresentam taxas de falsos positivos de uma única percentagem, o que torna as suas acusações impraticáveis.
Notas de rodapé
-
Note-se que, neste contexto, «4-shot» significa 4 exemplos de IA e 4 exemplos humanos — e não 4 exemplos no total. ↩

Nathan Breslow — cujo pseudónimo online é N8Programs — é um estudante de licenciatura em Matemática Aplicada na Universidade Johns Hopkins. Além disso, trabalha na área da aprendizagem contextual em modelos de linguagem de grande escala (LLMs) no Intelligence Amplification Lab, contribui para estruturas de inferência locais e realiza o pré-treino de modelos de linguagem em modalidades exóticas. As opiniões aqui expressas são da sua exclusiva responsabilidade.
Leitura relacionada

Como identificar comentários gerados por IA

A IA está a escrever obras de ficção premiadas

Como o Gradpilot utiliza o Pangram para ajudar os alunos a encontrar a sua voz

Qual é o detetor de IA mais preciso? 30 ferramentas testadas (2026)
Todos os dias são publicados 60 000 artigos noticiosos gerados por IA

Como se compara o Pangram com o GPTZero?
para receber as nossas atualizações
