Pangram, yapay zeka içeriklerini tespit etme konusunda insan uzmanlardan daha iyi performans gösteren tek yapay zeka tespit aracıdır
Maryland Üniversitesi ve Microsoft’tan araştırmacılar Jenna Russell, Marzena Karpinksa ve Mohit Iyyer’in yeni araştırmasını heyecanla karşılıyoruz. Bu araştırma, Pangram’ın karşılaştırmalı değerlendirmede en iyi performans gösteren yapay zeka tespit aracı olduğunu ve yapay zeka tarafından üretilen içeriği tespit etme konusunda eğitimli insan uzmanları geride bırakabilen tek sistem olduğunu ortaya koyuyor. Makalenin tamamını buradan okuyabilirsiniz.

Araştırmacılar, otomatik AI tespit sistemlerinin etkinliğini incelemenin yanı sıra, eğitimli uzmanların AI tarafından üretilen içeriğin belirleyici işaretlerini tespit etmelerine yardımcı olan ipuçlarını nasıl yakaladıklarını da mercek altına alıyorlar. Bu araştırmanın, AI tespitinde açıklanabilirlik ve yorumlanabilirlik açısından atılmış büyük bir adım olduğuna inanıyoruz ve bu araştırma yönünü daha da derinlemesine keşfetmekten büyük heyecan duyuyoruz.
Bu blog yazısında, araştırmanın öne çıkan noktalarını ve bunun gelecekte büyük dil modellerinin (LLM) tespit edilmesi açısından ne anlama geldiğini açıklayacağız.
İnsanları Yapay Zeka Tespitçileri Olarak Eğitmek
Daha önce, yapay zeka tarafından yazılmış metinleri nasıl tespit edebileceğimiz ve insan referans testi hakkında yazmıştık; ayrıca, bu testi daha iyi modeller geliştirmemize yardımcı olacak şekilde, yapay zeka tarafından üretilen metinler hakkında değerli içgörüler elde etmek için nasıl kullandığımızı da anlatmıştık.
Genellikle, yapay zeka tarafından üretilmiş yorumları, makaleleri, blog yazıları veya haberleri tespit etmeyi öğrenmeye başladığımızda, başlangıçta pek başarılı olamayız. Bir metnin ChatGPT veya başka bir dil modeli tarafından üretildiğini gösteren belirgin işaretleri fark etmeye başlamamız biraz zaman alır. Örneğin, yorumları incelemeye başladığımızda, zamanla çok sayıda veriyi inceleyerek ChatGPT'nin yorumlara "Kısa bir süre önce" ifadesiyle başlamayı sevdiğini öğrendik. Ya da AI tarafından üretilen bilim kurgu hikayelerini okumaya başladığımızda, bunların sıklıkla "Şu yılda" ifadesiyle başladığını fark ettik. Ancak zamanla bu kalıpları içselleştirmeye başlar ve bunları tanıyabilir hale geliriz.
Araştırmacılar ayrıca, uzmanların da aynı şekilde yapay zeka tarafından üretilen makaleleri tespit etmek üzere eğitilip edilemeyeceğini merak ettiler. Upwork platformunda beş değerlendiriciyi yapay zeka tarafından üretilen içeriği tespit etmek üzere eğittiler ve bu kişilerin gözle yapay zekayı tespit etme becerilerini uzman olmayanlarla karşılaştırdılar.
Bu iki grubun yapay zeka tarafından yazılmış metni tespit etme becerileri arasında bir fark olması beklense de, araştırmacılar aralarında önemli bir uçurum olduğunu ortaya çıkardı. Uzman olmayanlar, yapay zeka tarafından üretilen metni tespit etmede rastgele tahminle benzer bir performans gösterirken, uzmanlar ise oldukça yüksek bir isabet oranına sahip (ortalama olarak %90'ın üzerinde doğru pozitif oranı).

En ilgi çekici bulduğumuz bölümlerden biri, "Uzman metin değerlendiricileri, uzman olmayanların göremediği neyi görüyor?" başlıklı bölümdü. Araştırmacılar, katılımcılardan bir metnin neden yapay zeka tarafından üretilmiş olduğunu düşündüklerini ya da düşünmediklerini açıklamalarını istedi ve ardından katılımcıların yorumlarını analiz etti.
İşte makaleden doğrudan alıntılanan bazı analizler:
"Uzman olmayanlar, uzmanlara kıyasla genellikle belirli dilbilimsel özelliklere yanlış bir şekilde odaklanırlar. Bunun bir örneği kelime seçimidir; uzman olmayanlar, "süslü" ya da başka bir deyişle nadir kullanılan kelime türlerinin metinde yer almasını yapay zeka tarafından üretilmiş metnin bir işareti olarak görürler; buna karşın uzmanlar, yapay zeka tarafından aşırı sıklıkla kullanılan belirli kelime ve deyimlere (örn. testament, crucial) çok daha aşinadırlar. Uzman olmayanlar ayrıca, insan yazarların gramer açısından doğru cümleler kurma olasılığının daha yüksek olduğuna inanır ve bu nedenle uzun cümleleri yapay zekaya atfederler, ancak gerçekte tam tersi geçerlidir: insanlar, yapay zekaya kıyasla gramer kurallarına uymayan veya uzun cümleler kullanma olasılığı daha yüksektir. Son olarak, uzman olmayanlar nötr bir üslupla yazılmış herhangi bir metni yapay zekaya atfederler; bu da, resmi insan yazıları da genellikle nötr bir üslupta olduğu için birçok yanlış pozitif sonuca yol açar." (Russell, Karpinska ve Iyyer, 2025).
Ek bölümünde yazarlar, ChatGPT tarafından sıklıkla kullanılan bir "AI sözlüğü" listesi sunuyorlar – bu, Pangram kontrol panelinde kısa süre önce kullanıma sunduğumuz ve sık kullanılan AI ifadelerini öne çıkaran bir özellik!

Deneyimlerimize göre, pek çok kişi yapay zekanın sofistike, "süslü" bir kelime dağarcığı kullandığını düşünse de, pratikte yapay zekanın genellikle pek mantıklı olmayan, daha çok klişeleşmiş ve mecazi bir kelime dağarcığı kullanma eğiliminde olduğunu görüyoruz. Basitçe söylemek gerekirse, büyük dil modelleri (LLM'ler) akıllı görünmeye çalışan, ancak aslında sadece kendilerini akıllı göstereceğini düşündükleri ifadeler kullanan insanlara benziyor.
AI dedektörlerinin en gelişmiş modellere karşı dayanıklılığı
Pangram’da sıkça karşılaştığımız sorulardan biri şudur: En son teknoloji ürünü modellerin gerisinde kalmamak için ne yapıyorsunuz? Dil modelleri geliştikçe, bu Pangram’ın artık işe yaramayacağı anlamına mı geliyor? Bu, OpenAI gibi öncü laboratuvarların bizi alt edeceği bir kedi-fare oyunu mu?
Araştırmacılar da bu soruyu kendilerine sordular ve bugüne kadar yayınlanan en gelişmiş model olan OpenAI’nin o1-pro modeline karşı çeşitli yapay zeka tespit yöntemlerinin performansını incelediler.
Araştırmacılar, Pangram'ın o1-pro çıktılarını tespit etmede %100 isabetli olduğunu ortaya koydu; ayrıca, "insanlaştırılmış" o1-pro çıktılarını tespit etmede de hâlâ %96,7 isabet oranına sahibiz (buna birazdan değineceğiz)! Buna karşılık, diğer hiçbir otomatik tespit aracı, temel o1-pro çıktılarında %76,7'yi bile geçemiyor.
Pangram bu şekilde nasıl genelleme yapabiliyor? Ne de olsa, araştırmanın yapıldığı sırada eğitim kümesinde o1-pro verilerimiz bile yoktu.
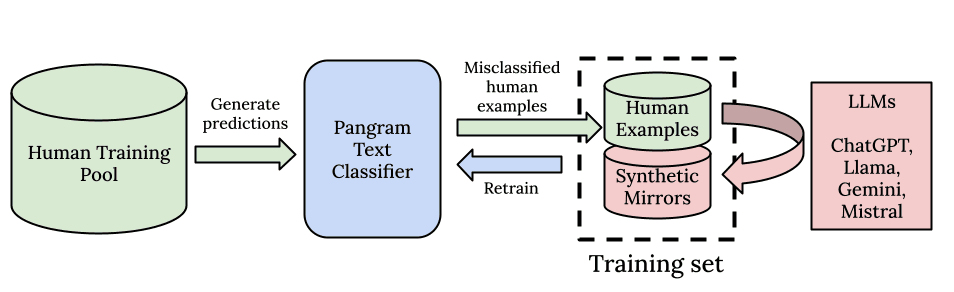
Tüm derin öğrenme modelleri gibi, biz de ölçek ve hesaplama gücüne inanıyoruz. İlk olarak, tıpkı büyük dil modelleri (LLM’ler) gibi, devasa bir eğitim külliyatı üzerinde önceden eğitilmiş güçlü bir temel modelle başlıyoruz. İkinci olarak, ölçeklendirmeyi amaçlayan bir veri işleme hattı oluşturduk. Pangram, 100 milyon insan tarafından yazılmış belgeden oluşan eğitim külliyatından ince kalıp tanımlamaları yapabilmektedir .
Sadece denemeler, haberler veya incelemeler için bir veri kümesi oluşturmuyoruz: modelin en yüksek kalitede ve en çeşitli veri dağılımından öğrenebilmesi ve her türlü insan yazısını öğrenebilmesi için, mevcut tüm insan tarafından yazılmış verilerden mümkün olan en geniş ağı toplamaya çalışıyoruz. AI algılamaya yönelik bu genel yaklaşımın, metin alanı başına bir model oluşturmaya yönelik özel yaklaşımdan çok daha iyi sonuç verdiğini görüyoruz.
Son derece geniş ve yüksek kaliteli insan veri setimizi tamamlayan unsurlar, sentetik veri işleme sürecimiz ve aktif öğrenmeye dayalı arama algoritmamızdır. Algoritmamız için yapay zeka verilerini temin etmek amacıyla, kapsamlı bir komut kütüphanesi ile tüm önemli açık ve kapalı kaynaklı yapay zeka modellerini kullanarak sentetik veriler üretiyoruz. Teknik raporumuzda bahsettiğimiz sentetik ayna komutlarını ve veri havuzumuzda en yüksek hata oranına sahip örnekleri arayan ve insan örneklerine çok benzeyen AI örnekleri oluşturan "hard negative mining" yöntemini kullanıyoruz. Ayrıca, artık hata görmeyene kadar modeli yeniden eğitiyoruz. Bu sayede, modelimizin yanlış pozitif ve yanlış negatif oranlarını çok verimli bir şekilde sıfıra indirgiyoruz.
Kısaca söylemek gerekirse, genellememiz ön eğitim verilerimizin büyüklüğünden, sentetik veri üretimi için kullanılan komutların ve büyük dil modellerinin çeşitliliğinden ve aktif öğrenme ile sert negatif veri madenciliği yaklaşımımızın sağladığı veri verimliliğinden kaynaklanmaktadır.
Ayrıca, sadece dağıtım dışı performansın mükemmel olmasını hedeflemekle kalmıyor, aynı zamanda yaygın olarak kullanılan büyük dil modellerinin (LLM) mümkün olduğunca dağıtım içi olmasını da sağlamak istiyoruz. Bu nedenle, en yeni modellerden veri çekmek için sağlam bir otomatik iş akışı oluşturduk; böylece yeni LLM’ler piyasaya çıkar çıkmaz eğitimlere başlayabilir ve güncel kalabiliriz. Bunun, farklı modellerde performans dengesi arasında bir ödün verme durumu olmadığını görüyoruz: eğitim setine yeni bir LLM eklediğimiz her seferinde, modelin genelleştirme yeteneğinin arttığını gözlemliyoruz.
Mevcut sistemimizde, modellerin gelişmesiyle birlikte bunların tespit edilmesinin zorlaştığını görmüyoruz. Çoğu durumda, yeni nesil modellerin tespit edilmesi aslında daha kolay oluyor. Örneğin, Claude 3 piyasaya çıktığında, onu tespit etmede Claude 2’ye kıyasla daha isabetli olduğumuzu gördük.
Paraphraser ve Humanizer Saldırıları
Son blog yazısı dizimizde, AI insanlaştırıcının ne olduğunu açıkladık ve insanlaştırılmış AI metinlerinde performansı büyük ölçüde artırılmış bir model yayınladık. Üçüncü bir tarafın, insanlaştırılmış o1-pro makalelerinden oluşan bir veri seti ile iddialarımızı doğruladığını görmekten memnuniyet duyuyoruz.
İnsanca yazılmış o1-pro metinlerinde %96,7'lik bir doğruluk oranına ulaşırken, en iyi ikinci otomatik model insanca yazılmış metinlerin yalnızca %46,7'sini tespit edebilmektedir.
Ayrıca, cümle cümle yeniden ifade edilmiş GPT-4o metinlerinde de %100 doğruluk oranına sahibiz.
Sonuç
Pangram'ın yapay zeka algılama yeteneklerine ilişkin bağımsız bir araştırmada gösterdiği güçlü performansı görmekten büyük memnuniyet duyuyoruz. Akademik araştırmaları desteklemekten her zaman mutluluk duyarız ve dedektörümüzü incelemek isteyen tüm akademisyenlere açık erişim imkânı sunuyoruz.
Otomatik algılayıcıların performansını karşılaştırmalı olarak değerlendirmenin yanı sıra, yapay zeka tabanlı algılamanın açıklanabilirliği ve yorumlanabilirliği konusunu da ele almaya başlayan araştırmaları heyecanla takip ediyoruz: sadece bir metnin yapay zeka tarafından yazılmış olup olmadığı değil, bunun neden böyle olduğu da önemli. Bu sonuçların öğretmenlerin ve eğitimcilerin yapay zeka tarafından üretilen metinleri gözle ayırt etmelerine nasıl yardımcı olabileceği ve bu araştırmayı daha açıklanabilir otomatik algılama araçlarına nasıl entegre etmeyi planladığımız konusunda ileride daha fazla yazmayı sabırsızlıkla bekliyoruz.
Daha fazla bilgi için lütfen pangram.com web sitemizi ziyaret edin veya info@pangram.com adresinden bize ulaşın.

Bradley, bir yapay zeka araştırmacısı ve endüstride derin öğrenme ürünleri geliştirme konusunda uzman bir isimdir. Son olarak, üretken yapay zeka ile ilaç keşfi yapan Absci şirketinde derin öğrenme araştırma grubuna liderlik etmiş ve daha önce Tesla Autopilot’un temel bilgisayar görme ekibinin bir üyesi olarak görev yapmıştır.
Bradley, yüksek lisans öğrencisiyken Stanford Vision Lab bünyesinde derin öğrenme alanında birçok makale kaleme almıştır. Stanford Üniversitesi’nden fizik lisans ve yapay zeka yüksek lisans derecelerine sahiptir. Yapay zekanın yanı sıra eğitim ve felsefe konularına da ilgi duymakta olup, aynı zamanda tutkulu bir golfçüdür.
İlgili makaleler

Yeni Pangram Ürün Seviyeleri

Pangram, akıl yürütme modellerini ne kadar iyi tespit edebiliyor?

Yeni Sonuç Sayfasını Tanıtıyoruz

AI Algılayıcıları GPT-5 Karşısında İşe Yarıyor mu?
Yüksek Hassasiyetli Yapay Zeka Tarafından Oluşturulan Metin Algılama Konusunda Teknik Rapor

Python'da yapay zekayı nasıl tespit edebilirim?
adresinden güncellemelerimize abone olun
