我们很高兴看到来自马里兰大学和微软的合作者珍娜·罗素(Jenna Russell)、玛尔泽娜·卡平斯卡(Marzena Karpinska)和莫希特·伊耶(Mohit Iyyer)的最新研究成果。该研究表明,在各项对比测试中,Pangram 是表现最佳的 AI 检测器,也是唯一能在检测 AI 生成内容方面超越受过专业训练的人类专家的系统。点击此处阅读完整论文。

除了研究自动化AI检测器的有效性外,研究人员还深入探讨了经过专业训练的人类专家是如何捕捉那些有助于他们识别AI生成内容特征线索的。我们认为,这项研究是AI检测领域可解释性和可解读性方面的一大进步,并期待进一步探索这一研究方向。
在这篇博客文章中,我们将阐述该研究的主要成果,以及它对未来大语言模型(LLM)检测工作的意义。
训练人类成为人工智能检测员
我们此前曾撰文探讨过如何识别AI生成的文本以及人类基准测试,并介绍了我们如何利用这些方法来获取关于AI生成文本的宝贵直觉,从而帮助我们开发出更优质的模型。
通常,当我们开始训练自己识别由人工智能生成的评论、文章、博客帖子或新闻时,起初往往不太擅长。需要一段时间,我们才能逐渐察觉到某段文本是由ChatGPT或其他语言模型生成的迹象。 例如,当我们开始研究评论时,通过分析大量数据,我们逐渐发现ChatGPT特别喜欢用“我最近有幸……”这一短语开头;而当我们阅读AI生成的科幻故事时,发现它们经常以“在……那一年”开头。不过,随着时间的推移,我们会逐渐将这些模式内化,从而能够识别它们。
研究人员还想知道,是否也能通过同样的方式培训专家来识别AI生成的文章。他们通过Upwork平台培训了五名标注员来识别AI生成的内容,并将他们凭肉眼识别AI内容的能力与非专家进行了对比。
虽然我们本应预期这两组人在识别AI生成的文本方面存在差异,但研究人员发现的差距却相当显著。非专家在识别AI生成的文本时,表现与随机猜测相差无几,而专家的识别准确率则非常高(平均真阳性率超过90%)。

我们认为最有趣的部分是“专业标注员能看到什么,而非专业人士却看不到?”这一章节。研究人员要求参与者解释他们为何认为某篇文字是AI生成的或不是,随后对参与者的评论进行了分析。
以下是直接摘自该论文的分析:
“与专家相比,非专家往往会错误地关注某些语言特征。词汇选择便是其中一例:非专家常将任何‘华丽’或低频词汇的出现视为AI生成文本的标志;而专家则对AI过度使用的特定词汇和短语(如testament、crucial等)更为熟悉。 非专家还认为人类作者更可能写出语法正确的句子,因此将长句归因于AI,但事实恰恰相反:人类比AI更可能使用语法错误或长句。 最后,非专家倾向于将任何语气中性的文本归因于AI,这导致了大量误判,因为正式的人类写作也常常采用中性语气。”(Russell, Karpinska, & Iyyer, 2025)。
在附录中,作者列出了ChatGPT常用的“AI词汇表”——这是我们最近在Pangram仪表盘中推出的一项功能,专门标注常用的AI短语!

根据我们的经验,尽管许多人认为人工智能会使用复杂、"高深"的词汇,但我们在实践中发现,人工智能往往更倾向于使用那些陈词滥调、充满隐喻的词汇,这些词汇通常毫无意义。通俗地说,我们可以认为大型语言模型(LLMs)更像是一群试图显得聪明的人,但实际上他们只是在使用那些自以为能让自己显得聪明的套话。
AI 检测器对最先进模型的鲁棒性
在Pangram,我们经常收到这样一类问题:你们如何跟上最先进的模型?当语言模型不断进步时,是否意味着Pangram将不再适用?这是否是一场猫捉老鼠的游戏,而像OpenAI这样的前沿实验室终将击败我们?
研究人员也对此感到好奇,于是研究了多种人工智能检测方法在面对OpenAI迄今发布的最先进模型o1-pro时的表现。
研究人员发现,Pangram 在检测 o1-pro 输出时准确率高达 100%,而在检测“人性化”的 o1-pro 输出时,我们的准确率仍达 96.7%(这一点我们稍后会详细说明)!相比之下,其他任何自动检测器在检测基础 o1-pro 输出时的准确率甚至都未达到 76.7%。
Pangram 是如何做到这种泛化的?毕竟,在研究进行之时,我们的训练集里甚至还没有任何 o1-pro 数据。
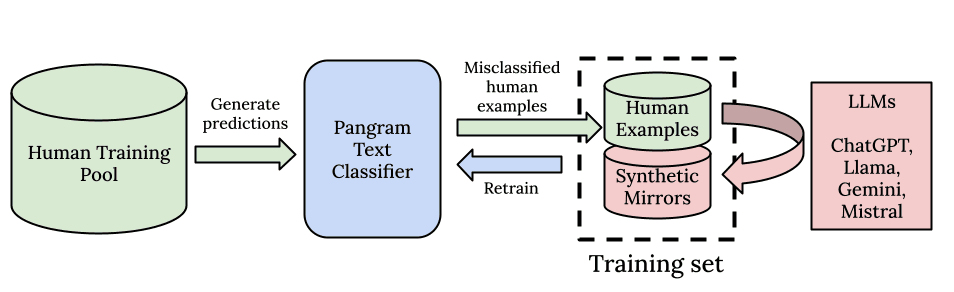
与所有深度学习模型一样,我们坚信规模和计算能力的力量。首先,我们以一个强大的基础模型为起点,该模型是在庞大的训练语料库上预训练的,这与大型语言模型(LLMs)本身如出一辙。其次,我们构建了一条专为大规模处理而设计的数据管道。Pangram 能够从其包含1 亿份人类文档的训练语料库中进行细微的模式识别。
我们不仅构建针对论文、新闻或评论的数据集:我们致力于尽可能广泛地收集所有现存的人类书写数据,以便模型能够从质量最高、分布最广泛的数据中学习,并掌握各类人类写作的特征。我们发现,这种通用的人工智能检测方法,远比针对每个文本领域分别构建模型的专项方法效果更好。
作为我们规模庞大、质量上乘的人类数据集的补充,我们还拥有合成数据管道和基于主动学习的搜索算法。为了为算法获取AI数据,我们利用一个涵盖全面的提示词库以及所有主流的开源和闭源AI模型来生成合成数据。 我们采用合成镜像提示词(相关内容已在技术报告中阐述),并结合“硬负样本挖掘”技术——该技术旨在从数据池中筛选出错误率最高的样本,生成与人类样本高度相似的AI样本,并不断重新训练模型直至消除所有错误。通过这种方式,我们能够非常高效地将模型的假阳性率和假阴性率降至零。
简而言之,我们的泛化能力源于预训练数据的规模、用于生成合成数据的提示词和大型语言模型(LLMs)的多样性,以及我们采用的主动学习和硬负样本挖掘方法所带来的数据利用效率。
此外,我们不仅致力于实现出色的分布外性能,还希望确保尽可能多的常用大型语言模型(LLM)具有良好的分布内表现。因此,我们构建了一条稳健的自动化管道,用于从最新模型中提取数据,以便在新模型发布后立即开始训练,并保持模型的最新状态。 我们发现,这并非在不同模型的性能之间进行权衡取舍:我们发现,每当将新的大型语言模型引入训练集时,模型的泛化能力都会得到提升。
在当前的系统中,我们并未发现随着模型的改进,它们反而变得更难被检测出来。在许多情况下,新一代模型实际上更容易被检测出来。例如,我们发现,在Claude 3发布时,我们对其的检测准确率反而高于Claude 2。
对“Paraphraser”和“Humanizer”的攻击
在我们最近的博客系列文章中,我们介绍了什么是 AI 人性化生成器,并发布了一个在生成人性化 AI 文本方面性能大幅提升的模型。我们很高兴看到,已有第三方通过一组经过人性化处理的 o1-pro 文章数据集验证了我们的说法。
在经过人性化处理的 o1-pro 文本上,我们的准确率达到了 96.7%,而排名第二的自动模型仅能检测出 46.7% 的人性化文本。
对于逐句改写的GPT-4o文本,我们的识别准确率也达到了100%。
结论
我们很高兴看到Pangram在一项关于AI检测能力的独立研究中表现出色。我们一直乐于支持学术研究,并向所有希望研究我们检测器的学者提供开放访问权限。
除了对自动检测工具的性能进行基准测试外,我们还欣喜地看到,相关研究已开始着手解决人工智能检测的“可解释性”问题:不仅要判断某篇文本是否由人工智能生成,更要探究其背后的原因。我们期待后续能进一步探讨这些研究成果如何帮助教师和教育工作者通过肉眼识别人工智能生成的文本,以及我们计划如何将这些研究成果融入到更具可解释性的自动检测工具中。
如需了解更多信息,请访问我们的网站pangram.com或通过info@pangram.com 与我们联系。

布拉德利是一位人工智能研究员,也是工业领域深度学习产品开发的专家。他最近曾领导生成式人工智能药物发现公司Absci的深度学习研究团队,此前曾是特斯拉Autopilot核心计算机视觉团队的成员。
在攻读研究生期间,布拉德利曾与斯坦福视觉实验室合作,在深度学习研究领域发表了多篇论文。他拥有斯坦福大学物理学学士学位和人工智能硕士学位。除了人工智能,他还对教育和哲学充满热情,并且是一名狂热的高尔夫球手。





以获取我们的最新动态
