تم نشر هذه المقالة على المدونة أيضًا على منصة Substack الخاصة بالمؤلف. تابعه هنا!
إفصاح عن التمويل: تم توفير أرصدة OpenRouter من قِبل شركة Pangram لإجراء هذا البحث، وقد اقترح الفكرة الأصلية لهذا البحث ماكس سبيرو، الرئيس التنفيذي لشركة Pangram. وقد بذلت قصارى جهدي للحفاظ على الحياد، وما ورد أدناه يعكس آرائي الحقيقية.
عندما ظهر ChatGPT لأول مرة، انتشرت عدة قصص لاقت اهتمامًا واسعًا حول محاولات بعض الأشخاص استخدامه كأداة للكشف عن المحتوى الذي أنشأته الذكاء الاصطناعي — أي بإدخال نص ما إليه وسؤاله بشكل مباشر عما إذا كان قد تم إنشاؤه بواسطة الذكاء الاصطناعي أم لا. ونشرت صحيفة «واشنطن بوست» تقريرًا عن أستاذ في جامعة تكساس إيه آند إم كان قد أعطى عدة طلاب علامة صفر، استنادًا إلى أن ChatGPT ادعى أنه هو مؤلف أوراقهم البحثية. وقالت أستاذة مساعدة في جامعة سان فرانسيسكو لزملائها: «كل ما علينا فعله هو أن نسأل: "هل كتبت هذا؟" ثم ننسخ عمل الطالب ونلصقه في مربع الإدخال» - لتكتب بعد ذلك منشورًا في مدونتها حول العدد السخيف من النتائج الإيجابية الخاطئة التي نتجت عن ذلك. ومؤخرًا، عندما اتُهم الفائز بمسابقة القصة القصيرة التي نظمتها مجلة «غرانتا» باستخدام الذكاء الاصطناعي، استعانت «غرانتا» ببرنامج «كلود» للتحقق مما إذا كان النص الفائز قد تم إنشاؤه بالفعل بواسطة الذكاء الاصطناعي.
ورغم أن هذه المحاولات قد تبدو ساذجة، وربما مسلية بعض الشيء — ففي النهاية، لا يملك ChatGPT أي وسيلة للتحقق من أنه هو الذي أنتج النص، ولا بد له من التخمين بناءً على الانطباعات (تمامًا كما يفعل الإنسان). لكن هذا الاستنتاج ليس غير منطقي بالنسبة لشخص غير ملم بالتكنولوجيا: يمكن لـ ChatGPT كتابة قصص مثل المؤلف البشري، ويمكن للمؤلفين البشريين التعرف على أعمالهم وتذكرها، فلماذا لا يستطيع ChatGPT ذلك؟ علاوة على ذلك، توجد أشكال أخرى للتحقق من إنشاء المحتوى بواسطة الذكاء الاصطناعي مثل SynthID للصور والصوت والفيديو. فلماذا لا يوجد شيء مماثل للنصوص؟ الإجابة، وهي أن SynthID يتطلب علامة مائية قابلة للكشف، ليست واضحة. وما يزيد الأمر إرباكًا، أنه إذا سألت Gemini عما إذا كانت الصورة من إنتاج الذكاء الاصطناعي، فإنه يرد ببساطة: «نعم، تم إنتاج أو تعديل معظم هذه الصورة أو كلها باستخدام الذكاء الاصطناعي من Google.» — مما يحجب عملية التحقق من العلامة المائية لـ SynthID، ويعطي الانطباع بأن Gemini يمكنه استنتاج ذلك بصريًّا بناءً على الانطباعات. لذا، لتوضيح كل هذا الغموض:
- لا تمتلك نماذج اللغة الكبيرة (LLMs) ذاكرة حادثة تتعلق بإنشاء نص ما، لذا لا يمكنها التعرف عليه بحكم كونها هي التي كتبته.
- توجد بالفعل تقنية وضع العلامات المائية على النصوص — مثل تقنية SynthID Text من Google — لكنها تتطلب أن يكون النص قد تم إنشاؤه بواسطة نظام ذكاء اصطناعي تشاركي مع تفعيل ميزة وضع العلامات المائية. ولذلك، فهي لا تُعد حلاً شاملاً لأي نص عشوائي.
- وبالتالي، يجب أن يتم الكشف عن النصوص باستخدام الذكاء الاصطناعي عن طريق الحدس — سواء كان ذلك الحدس البشري، أو خوارزميات التعلم الآلي المدربة (مثل Pangram)، أو حدس نموذج اللغة الكبير (LLM).
وتاريخياً، كانت الحدس لدى نماذج اللغة الكبيرة (LLMs) سيئاً! وهذا أمر منطقي للغاية — فالجيل الأول من نماذج اللغة الكبيرة الموجهة للمستهلكين — مثل GPT-3.5 وGPT-4، وربما Claude 3 — تم تدريبها جميعاً على بيانات تعود إلى ما قبل «إغراق» الإنترنت بالذكاء الاصطناعي. ومن المرجح أن تعرضها للنصوص التي أنشأها الذكاء الاصطناعي كان محدوداً، إن لم يكن معدوماً، لذا فمن الطبيعي أن يكون أداؤها في «التعلم بدون تدريب مسبق» (zero-shot) ضعيفاً. لكن هذا يطرح السؤال التالي: هل ستتمتع نماذج اللغة الكبيرة (LLMs) الأكثر حداثة، التي تم تدريبها على بيانات أحدث، بحدس أفضل ؟
أجرى آدم كوتشارسكي بحثًا حول هذا الموضوع على منصته «Substack»، وتبدو النتائج الأولية واعدة: فقد تمكن «كلود» من التمييز بين مقدمتين لقصص أنشأتهما الذكاء الاصطناعي ومقدمة واحدة كتبها الإنسان، كما حدد عشر قصص كتبها «GPT-5.5» على أنها من تأليف الذكاء الاصطناعي باحتمال تجاوز 80٪، ولم يمنح أكثر من 22٪ من احتمال أن تكون من تأليف الذكاء الاصطناعي لعشر قصص تم أخذها كعينة من كتابات كوتشارسكي الشخصية. والأمر الأكثر إثارة للتفاؤل هو أن كوتشارسكي طلب من GPT-5.5 «تحسين» كل قصة من قصصه العشر، فتحولت خمس منها من قصص كتبها الإنسان إلى قصص أنشأها الذكاء الاصطناعي. وهذا يمثل ثلاثة وعشرين نجاحًا في التصنيف المباشر للذكاء الاصطناعي، وخمسة نجاحات مقابل خمسة إخفاقات في تصنيف التحرير بواسطة الذكاء الاصطناعي.
وهذا يطرح السؤال التالي: متى ظهرت هذه القدرة على كشف الذكاء الاصطناعي؟ لاختبار ذلك، استخدمتُ مجموعة البيانات المفتوحة «editlens-iclr» من Pangram، والتي تحتوي على أمثلة وفيرة من المقاطع المكتوبة بواسطة البشر ونظائرها التي أنشأها الذكاء الاصطناعي. في البداية، أخذتُ عينة تجريبية من 100 مقطع — 50 منها مكتوبة بواسطة البشر و50 بواسطة الذكاء الاصطناعي — وقمتُ بتقييم مجموعة من النماذج — التاريخية والحالية على حد سواء — من حيث دقة «zero-shot». لتعظيم التصنيف القائم على «الانطباعات» — وهي الحدس الذي كنت أحاول اكتشافه — أجريت هذه التجربة مع تعطيل الاستدلال حيثما أمكن، مع إعطاء تعليمات صارمة بالرد بكلمة واحدة فقط. وأسفر ذلك عن تنسيق المطالبة «بدون تدريب» التالي:
 تنسيق المطالبة بدون تدريب مسبق
تنسيق المطالبة بدون تدريب مسبق
فيما يلي النتائج، وهي مثيرة للانتباه حقًّا:
 الأداء بدون تدريب مسبق حسب تاريخ الإصدار
الأداء بدون تدريب مسبق حسب تاريخ الإصدار
نلاحظ أن نسبة نجاح GPT-4 تبدأ عند 52% — وهي نسبة لا تتجاوز الصدفة — وهو ما يتوافق مع التقدير السائد في عامي 2023/2024 بأن الذكاء الاصطناعي لا يمتلك القدرة على التعرف على كتاباته الخاصة (حيث سجل GPT-3.5-Turbo نسبة 49%، ولم يُدرج في الرسم البياني أعلاه). بالانتقال سريعًا إلى ربيع وصيف عام 2025، يحصل GPT-4.1 على نسبة 71٪، وSonnet 4 على 62٪، وOpus 4 على 69٪. ما يلي ذلك هو ارتفاع سريع في القدرات من منتصف صيف عام 2025 إلى أوائل عام 2026 - حيث تصل كل من سلسلتي GPT وClaude إلى دقة تزيد عن 90% في هذه العينة المكونة من 100 مثال. يحدث هذا القفز أيضًا، وإن كان متأخرًا بعض الشيء، لسلسلة Qwen Plus، التي ترتفع دقتها بشكل كبير من 55٪ في إصدار Qwen3.5 Plus إلى 83٪ في إصدار Qwen3.6 Plus - الذي تم إصداره بعد شهرين فقط.
قد يتساءل المرء عما إذا كانت هذه الميزة في نموذج «الصفر-شوت» تُعزى في الغالب إلى الإلمام بالمحتوى الذي تولده الذكاء الاصطناعي، أم أنها مجرد فجوة في الذكاء — حيث تُعد النماذج الرائدة الأكثر ذكاءً مصنفات أفضل. لاختبار ذلك، يمكننا ملاحظة كيف يؤثر إدراج أمثلة «القليل من الشوت» (المستمدة من مجموعة التدريب والموزعة عشوائيًا لكل سؤال، بالطبع) في السياق على الدقة. وهذا يرفع مستوى تنسيق الموجه الخاص بنا إلى القالب التالي الخاص بـ«القليل من الشوت»:
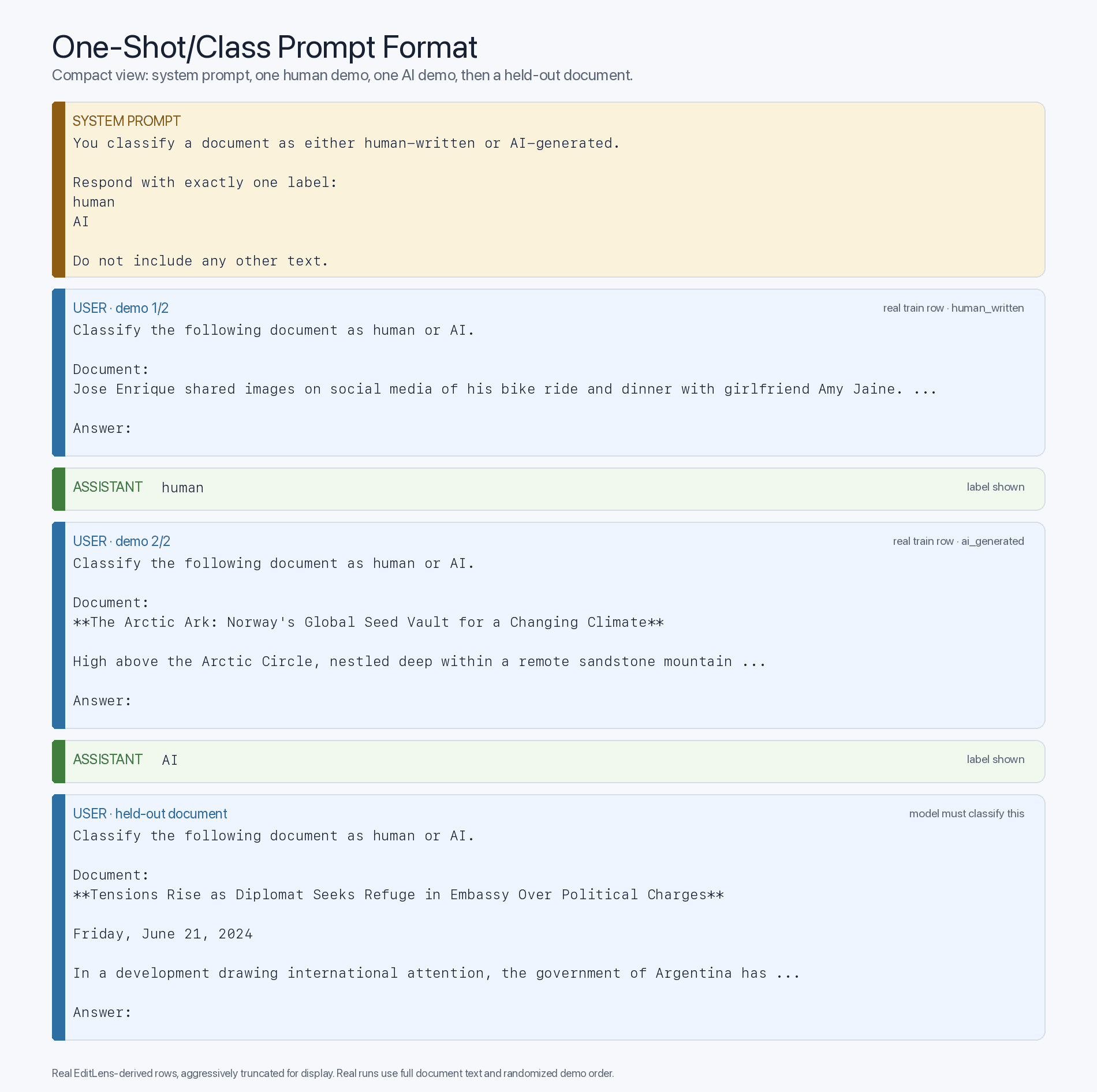
إذا كانت النماذج القديمة، في ظل تنسيق المطالبات ذات «العدد القليل من اللقطات» هذا، تتحسن بشكل كبير عند تعرضها لعمليات التعيين الصحيحة بين المدخلات والتصنيفات، فإن عنق الزجاجة يكمن في التعرض للتدريب المسبق، وليس في الذكاء. وهذا بالضبط ما نلاحظه:
 مخطط ICL لـ GPT لكل سؤال
مخطط ICL لـ GPT لكل سؤال
في حين أن GPT-4 في وضع «zero-shot» يحقق نسبة 52% فقط، فإنه في وضع «4-shot»1 يحقق نسبة 85%. من الواضح أن GPT-4 قادر على التعلم في السياق للتمييز بين النصوص التي أنشأتها الذكاء الاصطناعي وتلك التي كتبها البشر — لكنه يفتقر إلى المعرفة المسبقة الفطرية حول كيفية القيام بذلك. ويؤكد ذلك تحسن أداء "صفر طلقة" بشكل شبه منتظم مع تطور أجيال النماذج، في حين ظل أداء "بضع طلقات" ثابتًا تقريبًا بعد ~GPT-5.1 ولم يرتفع بشكل ملحوظ إلا إلى 99% عند GPT-5.5. تشير هذه الأدلة بقوة إلى أن العنصر المفقود الذي يمنع نماذج اللغة الكبيرة (LLMs) من أن تصبح كاشفات ذكاء اصطناعي «بدون تدريب» ذات كفاءة معقولة هو ببساطة عدم توفر بيانات تدريب مسبق مناسبة (أو أمثلة سياقية مثالية)، وليس أي قيد جوهري في طبيعتها أو ذكائها.
ولإجراء مزيد من التحقيق في تأثير التعلم في السياق باستخدام عدد قليل من الأمثلة (few-shot) على قدرة الكشف عن ICL، كنت بحاجة إلى مجموعة أصعب لاستخراج المزيد من الإشارات — ففي النهاية، إذا حققت النماذج الرائدة الحديثة نسبة 95% في تقييم مكون من 100 سؤال، فإنها تفقد فائدتها. ولإنشاء هذه المجموعة الصعبة، قمت بتصفية مجموعة بيانات Pangram للاحتفاظ فقط بالأمثلة التي خدعت نموذج Qwen 3.7 Plus مرتين (عند temp=0.7). وقد أتاح لي ذلك الحصول على 3,503 عينة تم إنشاؤها بواسطة الذكاء الاصطناعي، و763 عينة كتبها البشر — والتي قمت بعد ذلك بموازنة فئاتها (عبر أخذ عينات عشوائية موحدة) لإنتاج مجموعة البيانات الصعبة النهائية المكونة من 763 عينة تم إنشاؤها بواسطة الذكاء الاصطناعي و763 عينة كتبها البشر.
أقوم بتقييم كل من Sonnet 4.6 و GPT-5.5 على هذه المجموعة الصعبة من البيانات، عند 0 و 1 و 2 و 4 و 8 «شوتات»، مع إيقاف ميزة «الاستدلال» وتشغيلها (مستوى جهد متوسط لـ GPT-5.5، وتفكير موسع بسيط لـ Sonnet 4.6 من أجل تحقيق فعالية التكلفة):
 الرسم البياني المنقح للسوناتة 4.6
الرسم البياني المنقح للسوناتة 4.6
 مخطط GPT-5.5 بعد التنظيف
مخطط GPT-5.5 بعد التنظيف
نلاحظ أن GPT-5.5 يتفوق بفارق كبير على Sonnet 4.6 في اختبار «zero-shot» — وهو أمر متوقع نظرًا إلى أن GPT-5.5 تم إصداره في أبريل 2026، بينما تم إصدار Sonnet 4.6 في فبراير 2026. ومن الجدير بالذكر أن هذه الفجوة تتقلص بشكل كبير مع استخدام ICL - ففي حين يحقق GPT-5.5 (مع إيقاف الاستدلال) نسبة 86.8% في وضع "zero-shot" مقابل 72.9% لـ Sonnet 4.6، فإنه بعد 8 محاولات، يحقق GPT-5.5 نسبة 96.2% مقابل 93.8% لـ Sonnet 4.6. وهذا يؤكد مرة أخرى أن الكثير من عمليات الكشف عن الذكاء الاصطناعي هي قدرة يمكن اكتسابها في السياق، تمامًا مثل أي نوع آخر من تصنيف النصوص تقريبًا.
ومن الجدير بالذكر أنه في حين يؤدي الاستدلال إلى تحسن ملحوظ بنحو بضع نقاط مئوية بالنسبة لـ GPT-5.5، فإنه لا يساعد Sonnet 4.6 فعليًّا إلا في نظام «الصفر-شوت» (حيث يمنحها +2.2%)، أما بعد ذلك، فإما أن يؤثر سلبًا بشكل طفيف أو يساعد بشكل طفيف. وتؤكد الاختبارات الإحصائية ذلك — فبعد تطبيق تصحيح بونفيروني، تظل الفائدة التي يجنيها GPT-5.5 من الاستدلال ذات دلالة إحصائية عند 0 و1 و2 و8 محاولات، في حين لا يكون لـ Sonnet 4.6 تأثير ذو دلالة إحصائية إلا عند عدم وجود محاولات مسبقة.
يبدو أن هذا يشير إلى أنه على الرغم من أن الحوسبة في مرحلة الاختبار يمكن أن تساعد في تصنيف النصوص المكتوبة بواسطة الذكاء الاصطناعي، إلا أن بعض عائلات النماذج فقط تمتلك التدريب أو القدرة على تطبيقها بفعالية مقارنة بالحدس المباشر، كما أن المكاسب ليست كبيرة مقارنةً بمجرد تقديم المزيد من الأمثلة السياقية للتعلم منها. ويمكن أن تختبر الأبحاث المستقبلية نموذج GPT-5.5 عند مستويات الاستدلال العالية أو «xhigh» لمعرفة ما إذا كانت المكاسب ستستمر.
باختصار، لقد رأينا أن نماذج اللغة الكبيرة الحديثة (LLMs) قادرة على التمييز بنجاح بين النصوص التي أنشأتها الذكاء الاصطناعي وتلك التي كتبها البشر، وأن هذه القدرة ترجع على الأرجح إلى التعرض المتزايد خلال مرحلة التدريب المسبق للمحتوى الذي أنشأته الذكاء الاصطناعي، وأنها تستفيد بشكل طفيف من القوة الحاسوبية المتاحة في مرحلة الاختبار، لكنها تستفيد بشكل كبير من وجود المزيد من الأمثلة السياقية (إلى الحد الذي يمكن فيه لنماذج اللغة الكبيرة الأقدم مثل GPT-4 تعلم ذلك انطلاقًا من خط أساس يعتمد على الصدفة دون أي تدريب مسبق). وهذا يتعارض مع الرواية القديمة التي تقول إن ChatGPT كان عاجزًا عن إخبارك ما إذا كان نص ما قد تم إنشاؤه بواسطة الذكاء الاصطناعي أم لا. ومع ذلك، ما زلت لا أستخدمها كأدوات للكشف عن الذكاء الاصطناعي في الممارسة العملية — ففي مجموعة الاختبارات الصعبة، حقق النموذج الأفضل أداءً - GPT-5.5 مع مستوى استدلال متوسط يسجل معدل إيجابي كاذب يبلغ 4.59٪، وهو أمر غير مقبول حتى للاستخدام العادي (للتوضيح، لاحظ أن دراسة حديثة وجدت أن متوسط معدل الإيجابي الكاذب لخمسة خبراء بشريين في التعليق كان 5.6٪، لكن مجموعة من هؤلاء الخبراء سجلت معدل إيجابي كاذب يبلغ 0٪). إذا كنت تبحث عن أداة كشف موثوقة، فإنني أوصي باستخدام Pangram، مع مراعاة التحذيرات التي ناقشتها في مقالتي «دفاعًا عن Pangram ». على أي حال، ما زلت أجد هذه القدرة مثيرة للاهتمام للغاية — ورأيت أنه من المهم توثيقها، نظرًا لأن الرأي السائد على مدى السنوات القليلة الماضية كان أن نماذج اللغة الكبيرة (LLMs) عاجزة تمامًا عن اكتشاف النصوص التي تولدها نماذج اللغة الكبيرة نفسها. بدلاً من ذلك، من الأفضل تصنيف نماذج اللغة الكبيرة على أنها تقع تقريبًا في مستوى «إنسان جيد إلى خبير» في اكتشاف النصوص المكتوبة بواسطة الذكاء الاصطناعي. فهي دقيقة إلى حد ما، لكن معدلات الإيجابية الكاذبة لديها تبلغ نسبة مئوية واحدة، مما يجعل اتهاماتها غير قابلة للتنفيذ.
الحواشي
-
يرجى ملاحظة أن عبارة «4-shot» هنا تعني 4 أمثلة للذكاء الاصطناعي و4 أمثلة بشرية — وليست 4 أمثلة إجمالاً. ↩

ناثان بريسلو — المعروف على الإنترنت باسم N8Programs — هو طالب جامعي في جامعة جونز هوبكنز يدرس الرياضيات التطبيقية. كما يعمل على مجال التعلم في السياق في النماذج اللغوية الكبيرة (LLMs) في مختبر «Intelligence Amplification Lab»، ويساهم في تطوير أطر الاستدلال المحلية، ويقوم بالتدريب المسبق للنماذج اللغوية على أنماط غير تقليدية. الآراء الواردة هنا تعبر عن وجهة نظره الشخصية.
مقالات ذات صلة

كيفية التعرف على التعليقات المزيفة باستخدام الذكاء الاصطناعي

الذكاء الاصطناعي يكتب روايات حائزة على جوائز

كيف يستخدم Gradpilot برنامج Pangram لمساعدة الطلاب على إيجاد أسلوبهم الخاص

ما هو أكثر أدوات الكشف عن الذكاء الاصطناعي دقةً؟ اختبار 30 أداة (2026)
يتم نشر 60 ألف مقال إخباري تم إنشاؤها بواسطة الذكاء الاصطناعي يوميًا

كيف يقارن موقع Pangram بموقع GPTZero؟
لتلقي آخر أخبارنا
