جدول المحتويات
- بطاقة النموذج
- ما الذي يمكن توقعه
- ما الذي تحسّن
- الكشف عن "الهومانيزر" والتوجيه التنافسي
- الكشف عن المنشورات القصيرة على وسائل التواصل الاجتماعي التي تم إنشاؤها بواسطة الذكاء الاصطناعي
- تحسينات إصدار Claude 4.6
- ماذا بعد؟
- الرياضيات والبرمجة والعلوم التي تم إنشاؤها بواسطة الذكاء الاصطناعي
- التكرار المستمر في "Humanizers"
- المستقبل
الإعلان عن إصدار Pangram 3.2
تحديث: أصبح Pangram 3.3 هو الإصدار الأحدث — اطلع على الميزات الجديدة في Pangram 3.3.
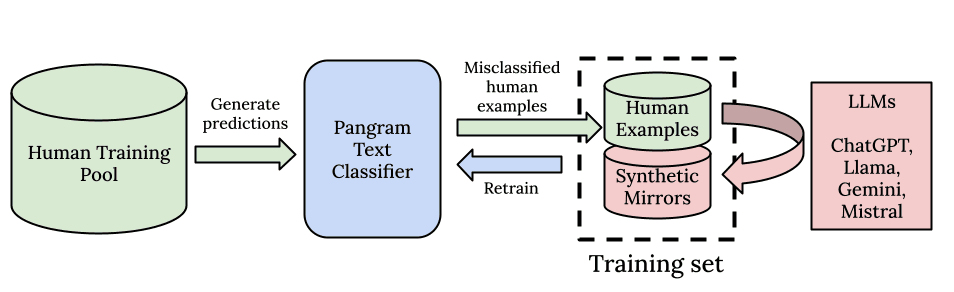
تشعر Pangram بحماس كبير لإطلاق نموذج جديد للكشف عن الذكاء الاصطناعي، وهو Pangram 3.2. وعلى غرار النسختين السابقتين، Pangram 3.1 و Pangram 3.0، فإن هذا النموذج يستند إلى بنية EditLens الموضحة في ورقتنا البحثية المقدمة في مؤتمر ICLR 2026. ما يمكن أن يتوقعه مستخدمونا هو تحسن تدريجي، ولكنه ملحوظ، في عدد النتائج الإيجابية الحقيقية التي يستطيع الكاشف التقاطها (معدل الاسترجاع)، مع الحفاظ على نفس معدل النتائج الإيجابية الخاطئة المنخفض في الصناعة، مما يضمن أن الاتهامات الخاطئة باستخدام الذكاء الاصطناعي لا تزال نادرة للغاية.
بطاقة النموذج
اتباعًا لأفضل الممارسات المتبعة في إصدارات النماذج اللغوية الكبيرة (LLM)، قررنا البدء في إصدار «بطاقات النماذج» جنبًا إلى جنب مع تحديثات أداة الكشف لدينا: وهي بمثابة «ملصقات التغذية» الخاصة بنماذج الذكاء الاصطناعي. تصف بطاقات النماذج لدينا بنية وإطار عمل التدريب، وتفاصيل حول مجموعة بيانات التدريب، ونتائج التقييم ذات الصلة، والتغييرات التي تم إجراؤها والتي قد تؤثر على سلوك أداة الكشف. كما نصف المواصفات الدقيقة لمدخلات ومخرجات النموذج، واللغات المدعومة، وأنواع الظروف التي نتوقع أن يعمل فيها Pangram بشكل جيد، وحيث يكون أكثر محدودية.
ما الذي يمكن توقعه
من المحتمل أن تلاحظ أن Pangram 3.2 أكثر حساسية من Pangram 3.1. بعبارة أخرى، سيتم اكتشاف المزيد من النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي. ويرجع ذلك إلى التحسينات التي طرأت على الكشف عن النصوص المُصطنعة، والكشف عن Claude 4.6، وزيادة الحساسية في اكتشاف النصوص القصيرة التي تم إنشاؤها بواسطة الذكاء الاصطناعي، وإضافة المزيد من البيانات إلى مجموعة بيانات التدريب، واستخدام معلمات فائقة أكثر مثالية في بنية EditLens.
ما الذي تحسّن
الكشف عن "الهومانيزر" والتوجيه التنافسي
أكبر تحسين في Pangram 3.2 هو قدرته على اكتشاف النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي والتي تمت إضفاء الطابع البشري عليها. في مجموعة التقييم الداخلية الخاصة بنا، قمنا بتحسين معدل الكشف عن النصوص المُصاغة بطريقة تشبه أسلوب البشر بمقدار 4 أضعاف مقارنةً بـ Pangram 3.1. كما لاحظنا تحسناً بنحو 3 أضعاف في تقييمنا الداخلي لـ "المطالبات التنافسية"، وهي نصوص تم إنشاؤها بواسطة نموذج لغوي تم توجيهه لإضافة أخطاء عن قصد والكتابة بأسلوب يتجنب الكشف بواسطة الذكاء الاصطناعي.
ويكتسب هذا الأمر أهمية خاصة في مجال التعليم، حيث يتزايد استخدام الطلاب لأدوات "إضفاء الطابع الإنساني" أو محاولتهم توجيه نماذج اللغة بطرق تهدف إلى تجنب أن يبدو النص الناتج "كأنه من إنتاج الذكاء الاصطناعي بشكل مبالغ فيه".
الكشف عن المنشورات القصيرة على وسائل التواصل الاجتماعي التي تم إنشاؤها بواسطة الذكاء الاصطناعي
نظراً للانتشار الواسع الذي حققه روبوتنا على منصة X، والذي استخدمه المستخدمون للتحقق من التغريدات التي تحتوي على نصوص من إنتاج الذكاء الاصطناعي، فقد ركزنا جهودنا مؤخراً على تحسين قدرتنا على الكشف عن المحتوى القصير الذي لا يتجاوز طول التغريدة على الإنترنت. كما قمنا بتخفيض الحد الأدنى لعدد الكلمات من 75 كلمة إلى 50 كلمة، حيث نشعر بأننا أصبحنا أكثر ثقة في قدرتنا على تمييز المنشورات التي تم إنتاجها بواسطة الذكاء الاصطناعي والتي تتراوح كلماتها بين 50 و75 كلمة.
مع الحفاظ على معدل الإيجابيات الخاطئة عند نفس مستوى Pangram 3.1، تمكنا في Pangram 3.2 من تحسين معدل السلبيات الخاطئة في المنشورات القصيرة على وسائل التواصل الاجتماعي بنسبة 17%.
تحسينات إصدار Claude 4.6
أبلغ عدد من المستخدمين عن حالات "سلبية كاذبة" مع نموذج "كلود أوبوس 4.6" على وجه التحديد. وقد عالجنا هذه المشكلة من خلال إعادة إنشاء قاعدة البيانات الخاصة بنا لتشمل بيانات نموذج "كلود أوبوس 4.6". وبعد إجراء التقييم على قواعد البيانات الداخلية الخاصة بالتحديات (وخاصة الأمثلة الصعبة) وإجراء اختبارات "فريق الهجوم"، أصبحنا الآن على ثقة من أن "بانغرام" قادر على اكتشاف نموذج "كلود أوبوس 4.6" وكذلك أي نموذج لغة كبير (LLM) متطور آخر.
ماذا بعد؟
الرياضيات والبرمجة والعلوم التي تم إنشاؤها بواسطة الذكاء الاصطناعي
لا يتم حالياً الكشف عن الأكواد البرمجية والمعادلات الرياضية التي تم إنشاؤها بواسطة الذكاء الاصطناعي بنسبة استرجاع عالية. ونحن نركز حالياً على حالات الاستخدام هذه نظراً لارتفاع الطلب من جانب العملاء. ورغم أن المعادلات الرياضية والأكواد البرمجية تتسم بطابع صيغي أكثر، وبالتالي يصعب الكشف عنها مقارنةً بالكتابة التي تم إنشاؤها بواسطة الذكاء الاصطناعي، فإن بعض تجاربنا الأولية تُظهر نتائج واعدة.
التكرار المستمر في "Humanizers"
يتطور سوق برامج "الهومانيزر" باستمرار، وقد ظهرت مجموعة متنوعة من هذه البرامج في الأسواق خلال الأشهر الأخيرة. ونحن نعمل حالياً على تطوير تقنيات أكثر تطوراً للكشف عن برامج "الهومانيزر"، ونأمل أن نتمكن من مشاركتها مع الجمهور قريباً.
المستقبل
تلتزم Pangram بالبقاء دائمًا في طليعة أحدث ما يمكن تحقيقه في مجال الكشف باستخدام الذكاء الاصطناعي. ونحن نتطور باستمرار مع تزايد قدرات النماذج اللغوية الكبيرة (LLM).
نحن نبحث عن موظفين جدد أيضًا! تفضل بزيارة صفحة الوظائف لدينا لمساعدتنا في تطوير أفضل أدوات الكشف عن الذكاء الاصطناعي في العالم.

كاثرين تاي هي عالمة أبحاث الذكاء الاصطناعي المؤسِّسة في «بانغرام لابس»، وهي شركة ناشئة متخصصة في مجال الكشف باستخدام الذكاء الاصطناعي. وقد حصلت على درجة الدكتوراه في علوم الحاسوب تحت إشراف موهيت إير في جامعة ماساتشوستس أمهرست في ديسمبر 2025، حيث ركزت أبحاثها على تقييم النماذج اللغوية الكبيرة (LLMs) في المهام المتعلقة بالتحليل الأدبي.
مقالات ذات صلة

هل يتعرف برنامج Pangram على نموذج Llama 4 من Meta؟

ما مدى كفاءة Pangram في التعامل مع برامج "humanizers"؟ (تم التحديث في أغسطس 2025)

دليل ترحيل واجهة برمجة التطبيقات (API) لـ Pangram 3.0
تقرير تقني حول الكشف عالي الدقة عن النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي

كيفية اكتشاف الذكاء الاصطناعي في مستندات Google

التزام بانجرام بحماية خصوصية البيانات
لتلقي آخر أخبارنا
