メリーランド大学およびマイクロソフトの共同研究者であるジェナ・ラッセル氏、マルゼナ・カルピンスカ氏、モヒット・アイヤー氏による新たな研究結果が発表されました。この研究では、比較試験において「Pangram」が最も優れた性能を発揮するAI検出器であり、AI生成コンテンツの検出において、訓練を受けた人間の専門家を凌駕できる唯一のシステムであることが示されています。論文の全文はこちらからご覧いただけます。

研究者たちは、自動化されたAI検出ツールの有効性を検証するだけでなく、訓練を受けた専門家が、AI生成コンテンツの特徴的な兆候を見極めるためにどのような手がかりを捉えているかについても詳しく調査しています。私たちは、この研究がAI検出における説明可能性と解釈可能性の分野において大きな前進であると確信しており、この研究の方向性をさらに深めていけることを楽しみにしています。
このブログ記事では、本研究の主なポイントと、今後のLLM検出技術にとってどのような意味を持つのかについて解説します。
人間をAI検出器として育成する
これまで、AIによる文章を判別する方法や人間による基準テストについて、また、それらを活用してAI生成テキストに関する有益な知見を得て、より優れたモデルの開発に役立てていることについて紹介してきました。
通常、AIが生成したレビューやエッセイ、ブログ記事、ニュースを見分ける訓練を始めると、最初はあまりうまくいきません。あるテキストがChatGPTや他の言語モデルによって生成されたものであるという兆候に気づけるようになるまでには、少し時間がかかります。 例えば、レビューの分析を始めた際、大量のデータを分析するうちに、ChatGPTが「最近、私は幸運にも」というフレーズでレビューを始める傾向があることを学びました。また、AIが生成したSF小説を読み始めた際、その冒頭には「ある年のこと」というフレーズが頻繁に登場することが分かりました。しかし、時間が経つにつれて、私たちはこうしたパターンを体得し、それらを認識できるようになっていきます。
研究者たちはまた、専門家も同様の方法でAI生成記事を見分けるよう訓練できるかどうかを検討した。彼らはUpworkで5人のアノテーターをAI生成コンテンツの検出について訓練し、その目視によるAI検出能力を非専門家と比較した。
これら2つのグループがAI生成テキストを見分ける能力に差があることは予想されていたが、研究者たちが発見したのは、その差が極めて大きいということだった。非専門家はAI生成テキストの検出において、ほぼ偶然のレベルに留まるのに対し、専門家は極めて高い精度(平均して90%を超える真陽性率)を示した。

特に興味深かったのは、「専門家と非専門家の見方の違い」というセクションでした。研究者たちは、参加者に「なぜその文章がAI生成だと判断したか、あるいはそうではないと判断したか」を説明するよう求め、そのコメントを分析しました。
以下は、論文から直接引用した分析です:
「専門家に比べて、非専門家は特定の言語的特徴に誤って注目しがちです。その一例が語彙の選択です。非専門家は、いわゆる『凝った』言葉や頻度の低い単語が使われていることを、AIが生成したテキストの証拠だと見なします。対照的に、専門家はAIが過剰に使用する特定の単語やフレーズ(例:testament、crucial)について、はるかに精通しています。 また、非専門家は人間の執筆者が文法的に正しい文章を作る可能性が高いと信じているため、文が長くなりすぎる(run-on sentences)文章をAIの仕業だと見なしがちだが、実際には逆である。人間の方がAIよりも、文法的に正しくない文章や文が長くなりすぎる文章を使う可能性が高いのだ。 最後に、非専門家は中立的な口調で書かれたテキストをすべてAIの仕業だと見なす傾向があり、これは人間の正式な文章もまたしばしば中立的な口調であるため、多くの誤検知(false positives)を引き起こしている。」(Russell, Karpinska, & Iyyer, 2025)。
付録では、著者らがChatGPTで頻繁に使用される「AI用語集」を掲載しています。これは、Pangramダッシュボードで最近リリースされた機能であり、よく使われるAI関連のフレーズをハイライト表示するものです!

これまでの経験から、多くの人はAIが洗練された「凝った」言葉遣いをしていると考えているようですが、実際には、AIはむしろ陳腐で比喩的な言葉を使いがちで、それがしばしば意味をなさないことがわかっています。ざっくり言えば、LLMは「賢く見せようとしている」人のようなもので、実際には単に「賢く聞こえるだろう」と思うフレーズを使っているに過ぎないと言えます。
最先端モデルに対するAI検出器の頑健性
Pangramによく寄せられる質問の一つに、「最先端のモデルにどう対応しているのか」というものがあります。言語モデルが進化すれば、Pangramは機能しなくなるのでしょうか? OpenAIのような最先端の研究機関に、まるで猫とネズミの追いかけっこのように、いつかは追い抜かれてしまうのでしょうか?
研究者たちも同様の疑問を抱き、これまでに公開された中で最も高度なモデルであるOpenAIの「o1-pro」に対して、いくつかのAI検出手法の性能を検証した。
研究者らの調査によると、Pangramはo1-proの出力を100%の精度で検出でき、さらに「ヒューマナイズド」されたo1-proの出力についても96.7%の精度を維持しています(これについては後ほど詳しく説明します)!これに対し、他の自動検出ツールでは、基本的なo1-proの出力であっても76.7%の精度を超えるものは一つもありませんでした。
なぜPangramはこのように一般化できるのでしょうか?何しろ、研究当時、私たちのトレーニングセットにはo1-proデータが一切含まれていなかったのですから。
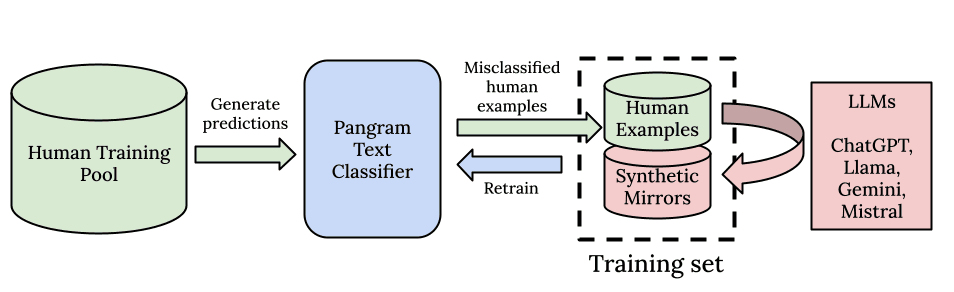
他のすべての深層学習モデルと同様、私たちもスケールと計算能力の力を信じています。まず、LLM(大規模言語モデル)と同様に、膨大なトレーニングコーパスで事前学習された強力なベースモデルから始めます。次に、スケールに対応したデータパイプラインを構築しました。Pangramは、1億件に及ぶ人間が作成した文書からなるトレーニングコーパスから、微妙なパターンの認識を行うことができます。
私たちは、単にエッセイやニュース、レビューのためのデータセットを構築するだけではありません。存在するすべての人間の執筆データから可能な限り広範な網を張り、モデルが最高品質かつ最も多様なデータ分布から学習し、あらゆる種類の人間の文章について理解できるように努めています。このAI検出に対する汎用的なアプローチは、テキストの分野ごとに個別のモデルを構築するという特化型のアプローチよりも、はるかに優れた成果を上げることが分かっています。
当社の極めて大規模かつ高品質な人間によるデータセットを補完するのが、合成データパイプラインとアクティブラーニングに基づく検索アルゴリズムです。アルゴリズム用のAIデータを収集するため、当社は網羅的なプロンプトライブラリと、主要なオープンソースおよびクローズドソースのAIモデルをすべて活用して合成データを生成しています。 当社は、技術レポートでも解説した「合成ミラープロンプト」と、「ハードネガティブマイニング」を活用しています。ハードネガティブマイニングとは、データプール内で最も誤差が大きい例を特定し、それに対して人間が作成した例と非常に類似したAI生成例を作成し、誤差がなくなるまでモデルを再学習させる手法です。これにより、モデルの偽陽性率と偽陰性率を極めて効率的にゼロに抑えることが可能となります。
端的に言えば、我々の一般化能力は、前学習データの規模、合成データ生成に用いられるプロンプトやLLMの多様性、そしてアクティブラーニングとハードネガティブマイニングの手法によるデータ効率の高さに起因しています。
さらに、我々は優れたアウト・オブ・ディストリビューション性能を目指すだけでなく、一般的なLLMの多くが可能な限りイン・オブ・ディストリビューションとなるよう努めています。そのため、最新のモデルからデータを取得するための堅牢な自動化パイプラインを構築し、新しいLLMがリリースされ次第すぐにトレーニングを開始し、常に最新の状態を維持できるようにしています。 異なるモデル間の性能バランスを取ることはトレードオフではないことが分かっています。トレーニングセットに新しいLLMを導入するたびに、モデルの汎化性能が向上することが確認されています。
現在のシステムでは、モデルの性能が向上するにつれて検出が難しくなるという傾向は見られません。多くの場合、次世代モデルの方が実際には検出が容易です。例えば、Claude 3がリリースされた際、Claude 2のときよりも正確に検出できたことが判明しました。
パラフレーザーおよびヒューマナイザーへの攻撃
最近のブログ記事シリーズでは、AIヒューマナイザーとは何かについて解説するとともに、AI生成テキストの人間味を高める性能が大幅に向上したモデルを公開しました。すでに、サードパーティがo1-proの記事データセットを用いて、私たちの主張を実証してくれたことを嬉しく思います。
人間が作成したo1-proテキストに対して、我々は96.7%の精度を達成したのに対し、これに次ぐ自動モデルでも、人間が作成したテキストのわずか46.7%しか検出できていない。
また、文ごとに言い換えられたGPT-4oのテキストについても、100%正確に処理できます。
結論
AI検出機能に関する独立した研究において、Pangramが優れた性能を発揮したことを大変嬉しく思います。当社は常に学術研究を支援することを喜びとしており、当社の検出器を研究したいと考える研究者の方には、誰でも自由にアクセスできる環境を提供しています。
自動検出ツールの性能評価に加え、AI検出の「説明可能性」や「解釈可能性」にも取り組み始めた研究が注目されています。単に「AIによって書かれたかどうか」だけでなく、「なぜそうなのか」という点にも焦点を当てているのです。これらの研究成果が、教師や教育関係者がAI生成テキストを目視で識別する上でどのように役立つか、また、この研究をどのように活用して、より説明可能な自動検出ツールを開発していくかについて、今後さらに詳しくお伝えしていく予定です。
詳細については、弊社ウェブサイトpangram.comをご覧いただくか、info@pangram.com までお問い合わせください。

ブラッドリーはAI研究者であり、産業界におけるディープラーニング製品の構築の専門家です。最近では、生成AIを活用した創薬企業であるAbsciでディープラーニング研究グループを率いており、それ以前はテスラのオートパイロット部門におけるコアコンピュータビジョンチームのメンバーでした。
大学院生時代、ブラッドリーはスタンフォード・ビジョン・ラボに所属し、ディープラーニング研究に関する複数の論文を発表しました。スタンフォード大学で物理学の学士号と人工知能の修士号を取得しています。AI以外にも、教育や哲学に関心を持ち、熱心なゴルファーでもあります。





を購読して、最新情報を受け取りましょう
