
Sehen im Pangram-Raum
Untersuchung der internen Repräsentationen von Pangram 3.3.2
Von Elyas Masrour, Katherine Thai und Bradley Emi
Juni 2026
Einleitung
Seit der Einführung von ChatGPT im Jahr 2022 hat sich das KI-gestützte Schreiben in atemberaubendem Tempo verbreitet. Da KI-generierte Texte mittlerweile in so vielen Bereichen, die wir lesen, vorkommen, ist offensichtlich geworden, dass bestimmte Textformen ihren Wert verlieren, wenn sie von einer Maschine erstellt werden. Im akademischen Bereich sollen Aufsätze das logische Denken der Studierenden fördern. Auf dem Markt sind Produktbewertungen wertvoll, weil sie die Erfahrungen anderer Menschen widerspiegeln.
Pangram ist ein Forschungsunternehmen, das hochmoderne KI-Erkennungsmodelle für dieses Problem entwickelt. Unser Flaggschiffprodukt ist ein KI-Text-Erkennungsmodell mit branchenweit führenden niedrigen Falsch-Positiv-Raten, mehrsprachigen Funktionen und der Fähigkeit, zwischen KI-generierten und KI-unterstützten Texten zu unterscheiden.
Seit der Veröffentlichung unseres ersten Whitepapers im Jahr 2024 hatten wir die einmalige Gelegenheit, eine Welle nach der anderen von Fortschritten im Bereich der KI mitzuerleben. Unsere Forscher haben sich mit übermäßig strengen Inhaltsfiltern auseinandergesetzt und so manchen Modus-Kollaps erlebt, und wich einer Flut von Gedankenstrichen und dem Wort „delve“ aus.
Unser Flaggschiff-Modell ist ein LLM, das speziell auf diese Sequenzklassifizierungsaufgabe abgestimmt ist. Wir verwenden keine benutzerdefinierten Metriken wie Perplexity oder Burstiness. Wir führen keine manuelle Merkmalsextraktion durch. Wir haben zwar ein kundenorientiertes Produkt namens „AI Phrases“, mit dem wir unseren Nutzern Informationen zu Phrasen bereitstellen, die in KI-Texten häufiger vorkommen. Diese werden jedoch nicht direkt als Merkmale für das Modell verwendet. Nach einer Weile wird man neugierig: Was sieht das Modell eigentlich?
Für uns als Forscher ist diese Frage von großer Bedeutung. Wir haben ein starkes Interesse daran, Abkürzungen zu vermeiden, unbeabsichtigtes Modellverhalten zu beheben und dieses Problem gründlich zu verstehen. In diesem Beitrag werden wir unsere ersten Ansätze zur Interpretierbarkeit anhand einer Analyse auf Dokumentebene skizzieren.
Daten
Wir haben einen Datensatz zur Interpretierbarkeit aus In-Domain-Held-Out-Beispielen unseres Produktionstrainingsdatensatzes erstellt. Der interaktive Explorer auf dieser Seite verwendet eine ausgewogene Teilmenge von 5.000 Dokumenten, die gleichmäßig auf menschliche und KI-Beispiele verteilt ist und sich über 20 geradzahlige Schichten erstreckt. Die KI-Beispiele decken die unten aufgeführten Modellvarianten aus den sechs Modellfamilien ab, die für die Klassifikator-Probe verwendet wurden.
Modelle
- Claude 3.7 Sonett
- Claude Sonett 4
- Claude Sonnet 4.5
- Claude Opus 4
- Claude Opus 4.1
- Claude Opus 4.5
- GPT-3.5 Turbo (Nov. ’23)
- GPT-3.5 Turbo (Jan. ’24)
- GPT-4 (März ’23)
- GPT-4 (Juni ’23)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- Qwen 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
Quelldomänen
- Nachrichten
- Wissenschaftliche Abstracts
- Produktbewertungen
- Unternehmensbewertungen
- Reddit – Kreatives Schreiben
- Reddit ELI5
- Bücher (im Eigenverlag erschienen)
- Bücher (Projekt Gutenberg)
- Wikipedia (Englisch)
- Wikipedia (mehrsprachig)
- Lang-8 (ESL)
Pangram 3.3.2 – Überblick
Pangram 3.3.2 ist ein KI-Erkennungsmodell, das 2026 von Pangram Labs veröffentlicht wurde. Es basiert auf demselben Grundmodell wie Pangram 3.3, enthält jedoch spätere Fehlerbehebungen, die die Leistung verbessern. Pangram 3.3 folgte auf Pangram 3.2 und verbesserte die Erkennungsrate bei neueren LLM-Ausgaben, humanisiertem Text und langen, KI-generierten Inhalten, während gleichzeitig die Anzahl der Fehlalarme bei nicht muttersprachlichen englischen Texten reduziert wurde.
ModellkarteLesen Sie die Modellkarte „Pangram 3.3“Hier finden Sie die Details zur Veröffentlichung von Pangram 3.3.2.Artikel lesenDie Arbeiten zur Interpretierbarkeit dauern an. In diesem Artikel wenden wir unsere Methoden zudem rückwirkend auf Pangram 3.2 und Pangram 3.1 an.
Methoden
Aktivierungen
Die EditLens-Architektur ist ein bucket-basiertes Klassifizierungssystem, das sich auf eine einzige ai_assistance_score. Bei diesem Projekt lassen wir das Endergebnis des Modells außer Acht und konzentrieren uns stattdessen auf die internen Repräsentationen, die das Modell lernt. Um diese zu untersuchen, erfassen wir die Aktivierungen, indem wir einen Vorwärtsdurchlauf des Modells mit einem bestimmten Eingabedokument durchführen und die versteckte Repräsentation des Modells auf mehreren internen Schichten speichern. Für dieses Projekt haben wir für jedes Dokument und für jede gerade Schicht im gesamten Netzwerk Aktivierungen extrahiert.
Dimensionsreduktion
Jeder extrahierte Aktivierungsvektor war 5.120-dimensional. Um ein besseres Verständnis der Darstellungen zu erlangen, wenden wir eine Reihe von Verfahren zur Dimensionsreduktion an.
PCA
Die Hauptkomponentenanalyse (PCA) ist die einfachste lineare Projektion: Sie ermittelt die Richtungen mit der größten Varianz im Aktivierungsraum. In diesem Projekt stellen wir fest, dass gegen Ende des Netzwerks der größte Teil der Varianz in den Hauptkomponenten 1 und 2 enthalten ist, weshalb wir diese gegeneinander auftragen.
UMAP
UMAP liefert eine nichtlineare Darstellung, die darauf ausgelegt ist, die Nachbarschaftsstruktur zu bewahren. Befinden sich zwei Dokumente im internen Raum des Modells nahe beieinander, versucht UMAP, sie auch im zweidimensionalen Raum nahe beieinander zu halten. Die genauen Achsen und Abstände zwischen den Clustern sollten jedoch nicht überinterpretiert werden.
t-SNE
t-SNE ist ein weiteres nichtlineares Projektionsverfahren, das sich besonders gut zur Darstellung lokaler Cluster eignet. Für die Zwecke dieses Projekts nutzen wir t-SNE, um zu untersuchen, ob semantisch relevante Gruppen – wie beispielsweise Modellfamilien oder „Mensch/KI“-Labels – mit zunehmender Tiefe des Netzwerks sichtbar in Clustern zusammengefasst werden.
Lineare Messköpfe
Wir verwenden lineare Proben, um die qualitativen Ergebnisse zu quantifizieren, die wir mit unseren Methoden zur Dimensionsreduktion beobachten. Für jede Schicht prüfen wir, ob ein einfacher Klassifikator anhand der Aktivierungsvektoren dieser Schicht eine Zielkennzeichnung rekonstruieren kann. Eine hohe Genauigkeit der Probe bedeutet, dass die relevante Unterscheidung bereits in einer linear zugänglichen Richtung des Darstellungsraums kodiert ist.
Die KI-Erkennungsaufgabe
Binäre Genauigkeit
Um zu verstehen, wie die endgültige Klassentrennung im Verlauf des Netzwerks erreicht wird, trainieren wir lineare Probes in jeder Schicht. Wir trainieren mit 500 Beispielen, die gleichmäßig zwischen menschlichen und KI-Beispielen aufgeteilt sind, mit einer 80:20-Aufteilung zwischen Trainings- und Testdaten. Wir stellen fest, dass die Leistung bereits in den frühen Schichten des Netzwerks sehr gut ist: Unmittelbar nach Schicht 2 erreichen wir eine Genauigkeit von 0,83. Dies entspricht unserer Intuition, da „Bag-of-Words“-Modelle oft brauchbare Baseline-Modelle für die KI-Erkennungsaufgabe sind. Im gesamten Netzwerk steigt die Genauigkeit an, bis sie in Schicht 24 ihren Höchstwert von 1,0 erreicht.
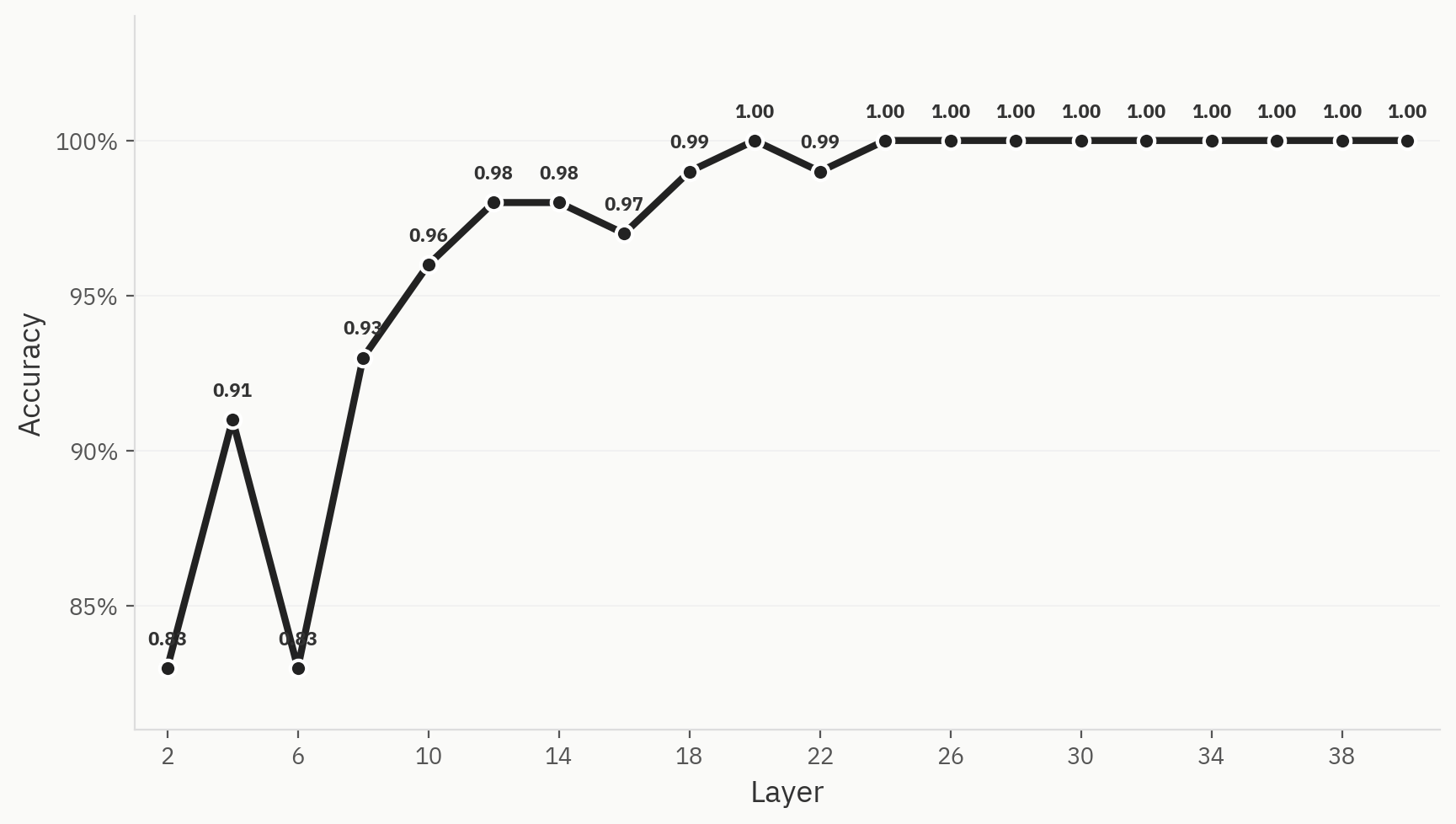
Abb. 3 Diese Trennung ist bei allen drei Methoden zur Dimensionsreduktion deutlich zu erkennen.
LLM-Klassifizierung
In den t-SNE- und UMAP-Diagrammen fiel uns auf, dass sich die Dokumente offenbar nach dem Modell gruppierten, das sie erzeugt hatte. Das war für uns eine Überraschung. Frühere Versionen von Pangram verfügten über einen separaten LLM-Klassifikator, doch diese spezielle Aufgabe war schon lange aufgegeben worden. Bei Pangram 3.3.2 werden im Trainingsprozess keine Labels vergeben, die dem Ursprungsmodell eines KI-Dokuments entsprechen.
Dennoch bildeten sich Cluster rund um die ursprüngliche Modellfamilie. Noch interessanter ist, dass diese Cluster offenbar über alle Ebenen des Netzwerks hinweg entstehen.
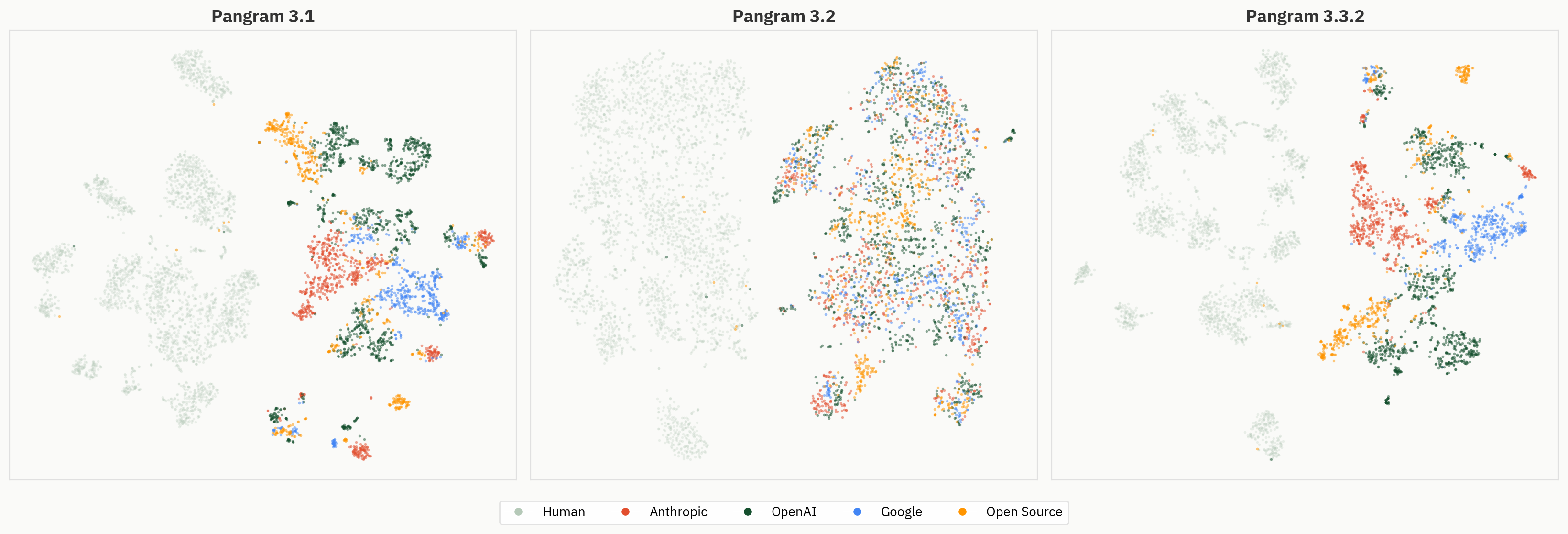
Entstehung von Modellclustern
Färben Sie die gleichen Einbettungen nach Modellfamilie ein, um zu sehen, wie sich die Geometrie auf Anbieterebene über die verschiedenen Ebenen hinweg zeigt.
Abb. 4: Einbettungen der Schichten 2–40, nach Modellfamilie farblich gekennzeichnet. Cluster auf Anbieterebene werden in den späteren Schichten deutlicher sichtbar.
Sonde
Um dieses Phänomen zu quantifizieren, trainieren wir einen Klassifikator für sechs Modellfamilien (Anthropic, OpenAI, Google, Qwen, Llama, DeepSeek) mit jeweils 500 Beispielen pro Modellfamilie und insgesamt 3.000 Beispielen bei einer Aufteilung von 80:20 zwischen Trainings- und Testdaten. Wir stellen fest, dass wir tatsächlich eine Probe trainieren können, die in der Lage ist, die ursprüngliche Modellfamilie eines bestimmten Dokuments allein anhand von Pangram-Aktivierungen zu klassifizieren, wobei die maximale Top-1-Genauigkeit bei 91 % liegt.
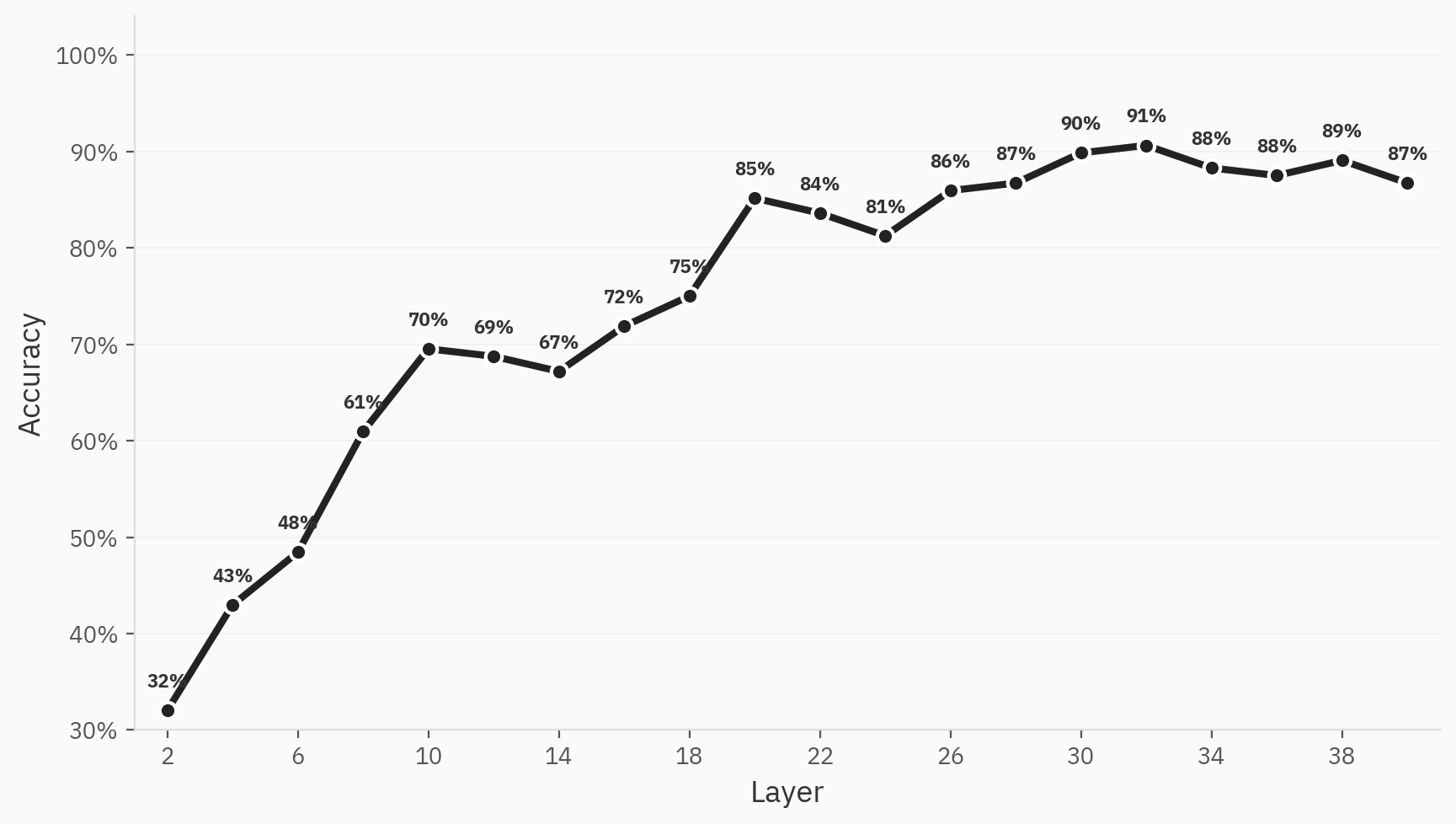
Das Auftreten ist nicht garantiert
Unsere ersten Experimente zur Interpretierbarkeit umfassten Tests mit einer Reihe von Modellen. Zu unserer Überraschung war das Auftreten einer „LLM-Klassifizierungsfähigkeit“ eines der wenigen Ergebnisse dieses Projekts, das sich je nach Modell wesentlich unterschied.
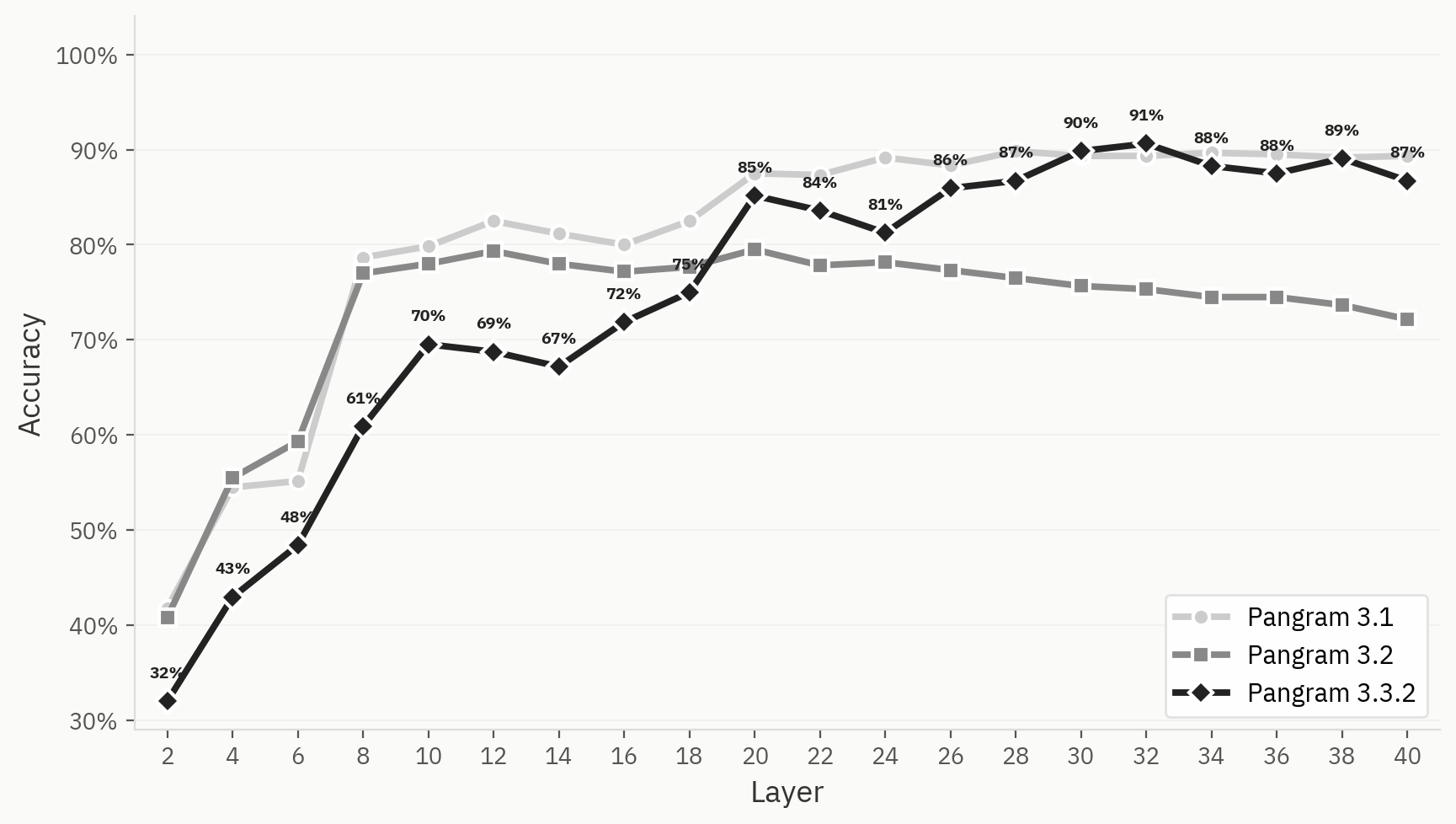
Die folgende Abbildung vergleicht das Clustering-Verhalten von Pangram 3.1, 3.2 und 3.3.2. Obwohl das Modell in unseren internen Signoff-Bewertungen bei der binären Mensch-KI-Aufgabe besser abschneidet als 3.1, sind die Cluster des Modells bei Pangram 3.2 im Allgemeinen weniger klar definiert als bei Pangram 3.1 oder 3.3.2.
Um diesen Unterschied noch deutlicher zu veranschaulichen, vergleichen wir die LLM-Klassifikator-Probe für Pangram 3.1, 3.2 und 3.3.2. Bei allen drei Modellen verbessert sich die Top-1-Genauigkeit in den frühen Schichten, doch die Probe für Pangram 3.2 beginnt nach Schicht 12 abzunehmen, während die Genauigkeit bei Pangram 3.1 und 3.3.2 auf einem hohen Niveau bleibt.
Humanisierer
„Humanizer“ sind eine Klasse von Adversarial-Tools, die darauf ausgelegt sind, KI-generierten Text so zu verändern, dass er KI-Detektoren umgeht. Um zu untersuchen, wo sich humanisierter Text im Aktivierungsraum im Vergleich zu menschlichem und KI-Text positioniert, haben wir einen separaten „Humanizer“-Datensatz erstellt, der aus rund 1.900 Beispielen besteht, die in etwa gleichmäßig auf drei generative Modelle (Claude Sonnet 4.5, Gemini 2.5 Pro und GPT-5), zehn verschiedene Humanizer-Dienste und dieselben Quelldomänen wie der ursprüngliche Interpretierbarkeits-Datensatz verteilt sind. Aufgrund der damit verbundenen Risiken geben wir nicht bekannt, welche Dienste wir verwenden.
Wie das Modell „Humanizer“ auswertet
Bestimmte Beispiele aus unserem „Humanizer“-Datensatz stellen für unser Modell in der Tat eine Herausforderung dar. Hier verwenden wir für die „Mensch/KI“-Aufgabe dieselbe lineare Sonde wie im ursprünglichen Trainingsaufbau, allerdings werden die humanisierten Texte als KI-Text gekennzeichnet. Wir stellen fest, dass humanisierte Texte bereits ab der ersten Schicht durchweg als „menschlicher“ eingestuft werden als ihr direktes KI-Pendant.
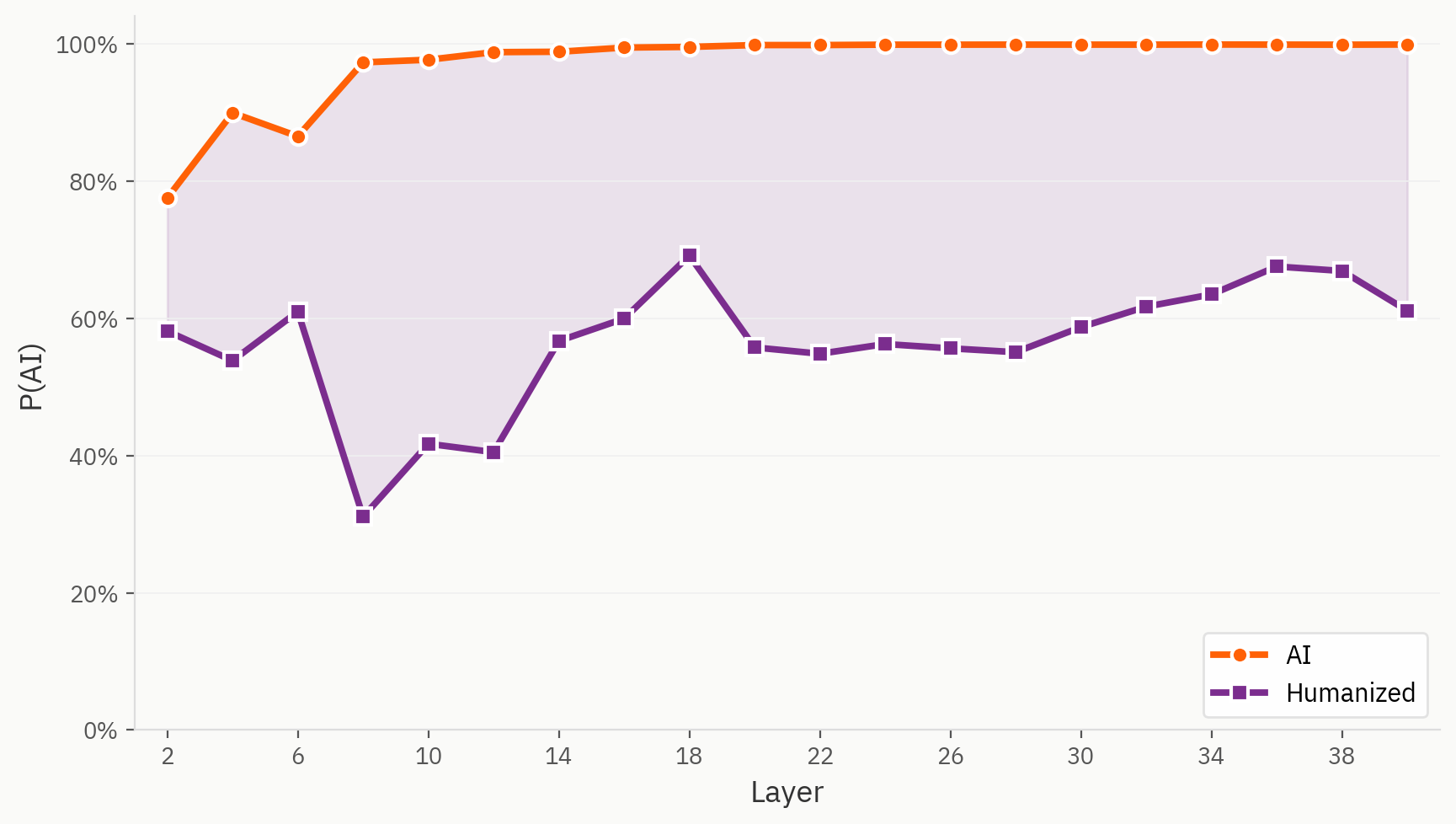
Wo sich Humanizer im Einbettungsraum befinden
Wenn wir jedoch hinter die endgültigen Ergebnisse blicken, finden wir eine weitaus facettenreichere Darstellung humanisierter Texte. Im Folgenden wenden wir unsere Methoden zur Dimensionsreduktion auf die von Menschen verfassten, die KI-generierten und die humanisierten Texte an. Qualitativ lässt sich beobachten, dass Humanisierer tendenziell separate Bereiche des Aktivierungsraums einnehmen und Cluster außerhalb der Bereiche für menschliche und KI-Texte bilden.
Unsere Hypothese lautet, dass das Modell trotz fehlender Klassifizierungen für humanisierten Text in der Lage ist, zwischen humanisiertem, von Menschen verfasstem und KI-Text zu unterscheiden. Bei der endgültigen Auswertung ist das Modell jedoch gezwungen, dieses Signal zu vernachlässigen, und tut dies auf inkonsistente Weise.
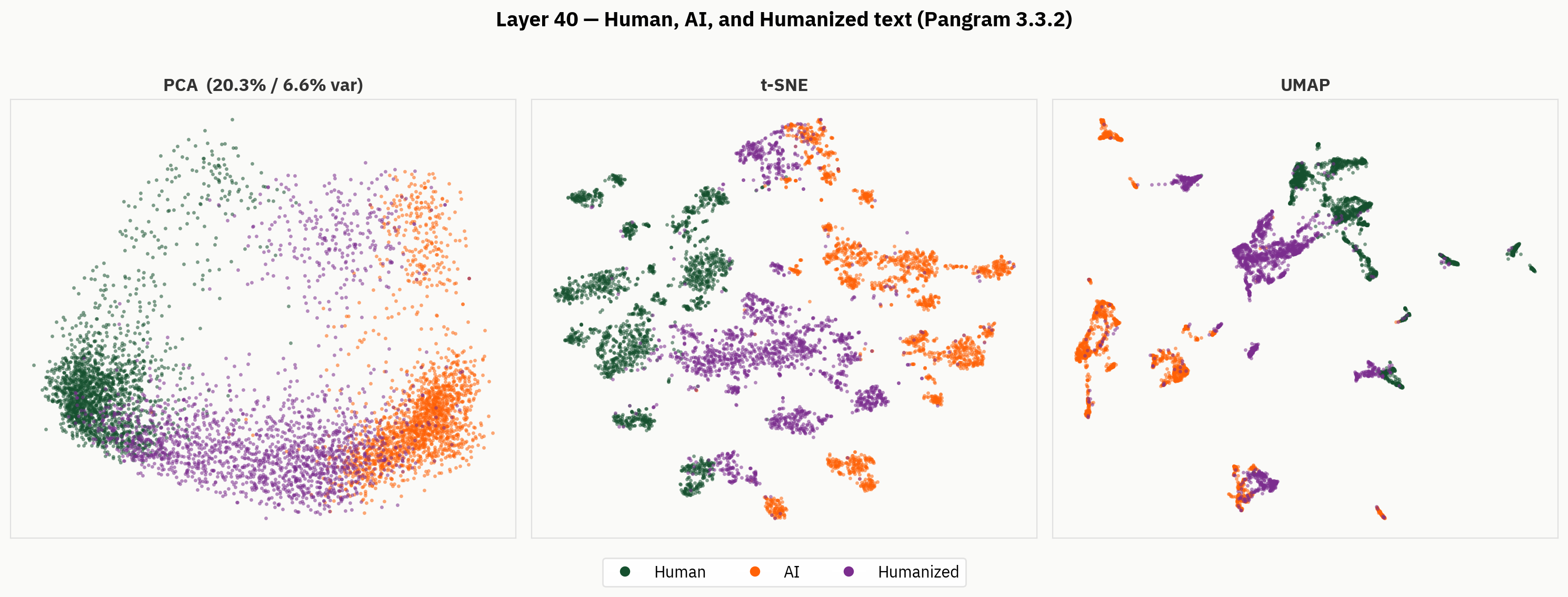
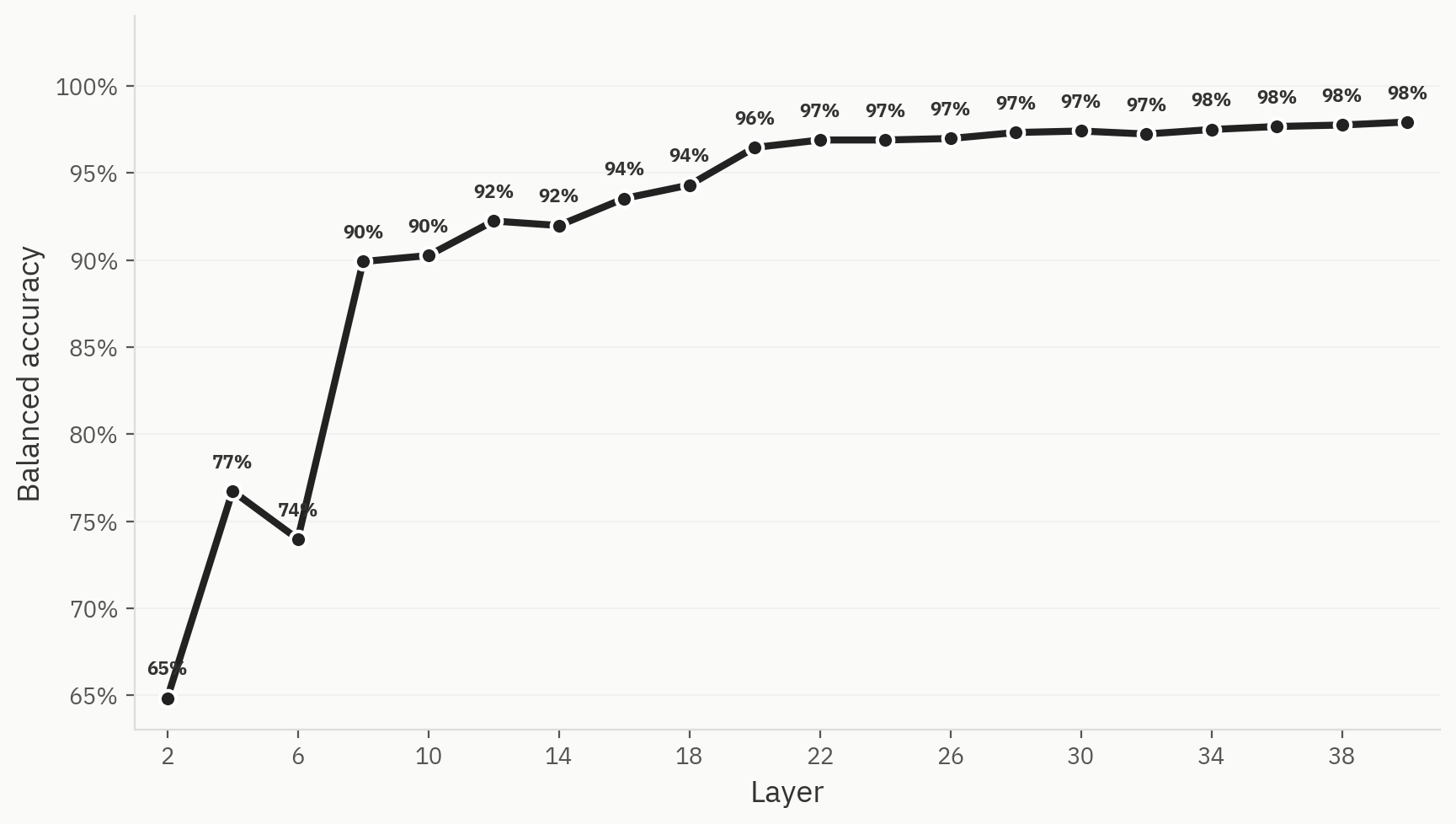
Sonde
Um diese Hypothese zu überprüfen, trainieren wir eine dreigleisige lineare Sonde mit Labels für KI-, menschlich verfasste und humanisierte Texte. Die Sonde erreicht bereits früh im Netzwerk eine hohe Top-1-Genauigkeit und stagniert schließlich bei 98 %.
Fazit
Unsere Arbeit legt nahe, dass die internen Repräsentationen von Pangram strukturierter sind, als es die endgültige binäre Ausgabe allein vermuten lässt. Über alle Schichten hinweg beobachten wir, dass sich von Menschen verfasste und von KI erstellte Dokumente voneinander unterscheiden, dass Informationen zur Modellfamilie zum Vorschein kommen und dass humanisierter Text einen eigenen Bereich im Aktivierungsraum einnimmt. Diese Erkenntnisse sind zwar noch vorläufig, bieten uns jedoch eine nützliche Orientierungshilfe, um zu verstehen, was das Modell lernt, bevor es alle Informationen zu einem einzigen Erkennungswert zusammenfasst.
Dieser Beitrag zeigt zwar nur die ersten Schritte unserer Bemühungen um Interpretierbarkeit, doch intern sind wir von dieser Forschungsrichtung begeistert und daran interessiert.
Unsere Vision hinsichtlich der Interpretierbarkeit und Erklärbarkeit von Pangram-Modellen sieht vor, dass diese:
- Ein besseres internes Verständnis des Modellverhaltens vermitteln.
- Liefern Sie Belege und klarere Erläuterungen zu den einzelnen Pangram-Ergebnissen.
Wenn Sie als Forscher Interesse an Interpretierbarkeit, an der Erforschung der Erkennung künstlicher Intelligenz oder an anderen Aspekten dieser Arbeit haben, wenden Sie sich bitte an elyas@pangram.com.
