KI-Erkennung für ML- und Datenteams
KI-Detektor für ML-Ingenieure und Datenwissenschaftler
Optimieren Sie das Training von großen Sprachmodellen (LLM) und die Datenauswahl. Verhindern Sie den Modellkollaps, indem Sie synthetischen Text aus Ihren Datensätzen für das Vortraining oder die Feinabstimmung mit einer Genauigkeit von 99,98 % und einer API-Leistung mit hohem Durchsatz herausfiltern.
Entwickelt von Forschern von Google, Tesla und der Stanford University. Validiert durch die ICLR und die University of Maryland.
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")e Marken vertrauen uns

















Anwendungsfälle
Trainieren Sie Ihre Modelle
nicht mit fehlerhaften Daten.
Synthetischer Text verunreinigt öffentliche Datensätze. Filtern Sie KI-generierte Inhalte mit der präzisesten KI-Erkennungs -Engine aus Ihren Trainingspipelines heraus, um die Reinheit Ihres Korpus zu gewährleisten.
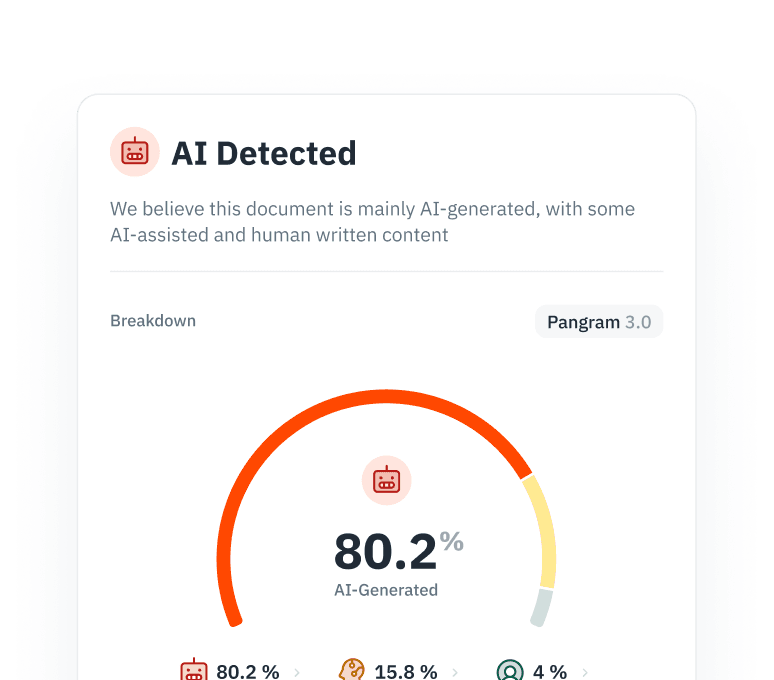
Modellkollaps verhindern
Das wiederholte Trainieren mit KI-generierten Inhalten beeinträchtigt die Modellleistung und die Vielfalt. Identifizieren und filtern Sie KI-generierte Inhalte aus Ihren Scraping-Pipelines, um die Reinheit des Korpus zu gewährleisten.
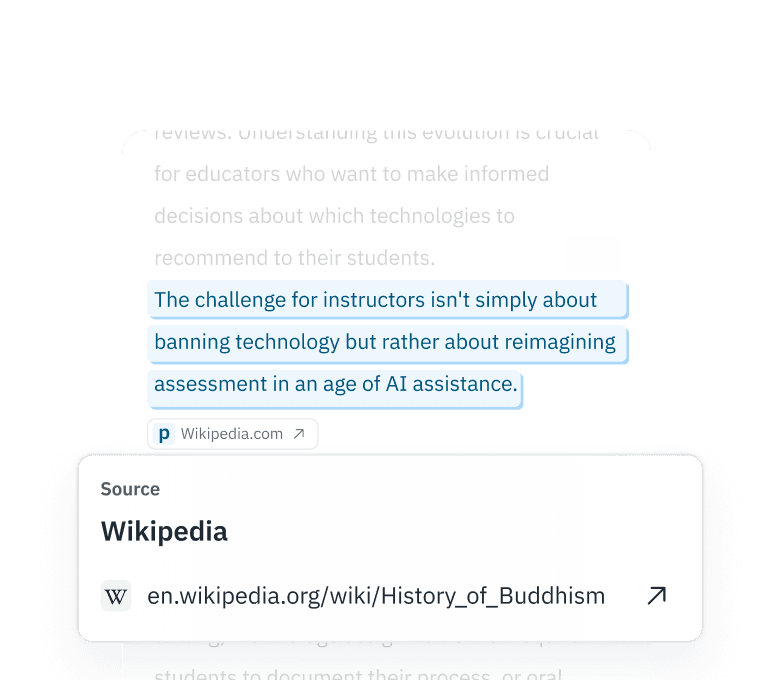
RLHF-Eingaben überprüfen
Stellen Sie sicher, dass Ihre RLHF-Daten (Real-Life Human Feedback) tatsächlich von Menschen stammen. Erkennen Sie, ob Crowd-Worker ChatGPT nutzen, um Antworten für Ihre Feinabstimmungsaufgaben zu generieren.
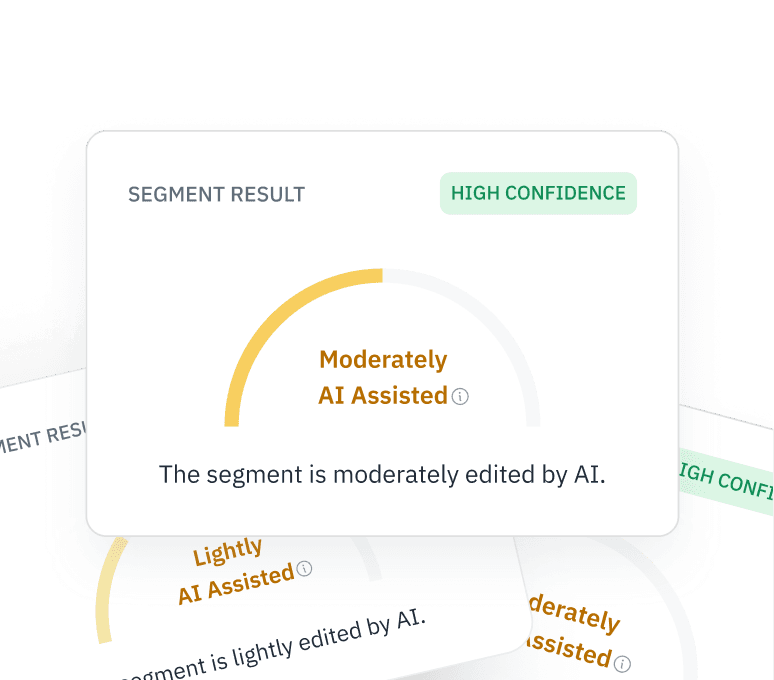
Detaillierte Interpretierbarkeit
Geben Sie sich nicht mit einer binären Einstufung zufrieden. Unsere Premium-API liefert Wahrscheinlichkeitswerte auf Token-Ebene, sodass Sie von Menschen bearbeitete Segmente beibehalten und vollständig synthetische „Fehler“ verwerfen können.
Technischer Ansatz
Ein Modell, auf das Sie
vertrauen können
Entwickelt für Ingenieure, die auf die Zuverlässigkeit ihrer Datenfilterung vertrauen müssen. Unser Modell befasst sich mit Fehlalarmen, Widerstandsfähigkeit gegen angreifende Algorithmen und sich weiterentwickelnden KI-Ergebnissen.

Hard-Negative-Mining
Wir trainieren mit „Hard Negatives“ – also Texten, die stilistisch formell oder repetitiv sind –, um Fehlalarme zu minimieren und sicherzustellen, dass Sie keine wertvollen menschlichen Daten verwerfen.
Robustheit gegenüber Angriffen
Pangram verarbeitet umformulierte oder modifizierte KI-Inhalte. Unsere Modelle wurden auf „Humanizer“ und gegnerische Angriffe trainiert, um verschleierten synthetischen Text zu erkennen.
Zukunftssicherheit
Erkennt Texte aus den neuesten Modellen, darunter GPT-5, Claude 3.5 und Llama 3, und stellt so sicher, dass Ihre Filter dem aktuellen Stand der Technik immer einen Schritt voraus sind.
Integration
Entwickelt für Ihre „
“-Datenpipeline

01
Python-SDK
Installieren Sie pangram-sdk und integrieren Sie die Erkennung mit nur wenigen Zeilen Code in Ihre Airflow- oder Databricks-Pipelines. Optimiert für Verbindungspooling und Fehlerbehandlung.
Dokumente anzeigen →
02
API für Hochdurchsatz-
Verarbeiten Sie riesige Datensätze mit geringer Latenz. Unsere Infrastruktur unterstützt die Stapelverarbeitung und garantiert einen hohen Durchsatz, sodass Millionen von Anfragen für Scraping-Vorgänge in Unternehmen bewältigt werden können.
API-Schlüssel abrufen →
03
Sicherheit und Einhaltung der Vorschriften des „
“
Vollständig nach SOC 2 Typ 2 zertifiziert. Wir bieten private Endpunkte und strenge Richtlinien zur Datenaufbewahrung – wir trainieren niemals mit Ihren firmeneigenen Eingaben.
Mehr erfahren →
Häufig gestellte Fragen
Häufig gestellte Fragen zur KI-Erkennung
Häufige Fragen zur KI-Erkennung für ML-Ingenieure
und Datenwissenschaftler.
Ja. Sie können das pangram-sdk installieren, um die Erkennung mit nur wenigen Zeilen Code in Airflow- oder Databricks-Pipelines zu integrieren. Unsere API ist für Scraping-Vorgänge mit hohem Durchsatz in Unternehmen optimiert und unterstützt Millionen von Anfragen mit geringer Latenz.
Mehr entdecken
KI-Erkennung für
jedes Unternehmens
Für Entwickler
KI-Code-Erkennung für Entwickler und Technikteams. Erkennen Sie von ChatGPT, Copilot und Claude generierten KI-Code in Python, Java, C++ und weiteren Sprachen.
Mehr erfahren →Zur Moderation von Inhalten
KI-gestützte Inhaltsmoderation für Teams im Bereich Vertrauen und Sicherheit. Erkennen Sie KI-generierte Bewertungen, gefälschte Kommentare und synthetische Inhalte in großem Umfang über eine API.
Mehr erfahren →Für Hochschulen
KI-Erkennung für Universitäten und Hochschulen. Überprüfen Sie studentische Arbeiten, prüfen Sie eingereichte Forschungsarbeiten und schützen Sie den Ruf Ihrer Einrichtung.
Mehr erfahren →Bereinigen Sie Ihre Trainingsdaten noch heute
Verhindern Sie den Modellkollaps, überprüfen Sie RLHF-Eingaben und filtern Sie synthetische Inhalte mit einer Genauigkeit von 99,98 % aus Ihren Datensätzen heraus.
