Índice
- 🤗 Modelos y conjuntos de datos
- Código fuente
- ¿Por qué lanzamos una versión abierta de Pangram?
- EditLens y detección asistida por IA
- Conjuntos de datos
- Modelos
- Evaluaciones
- Conjunto de pruebas dentro del dominio
- Resultados de la clasificación binaria
- Resultados de la clasificación ternaria
- Dominio retenido (correos electrónicos de Enron)
- Resultados de la clasificación binaria
- Resultados de la clasificación ternaria
- Modelo de referencia (Llama 3.3 70B Instruct)
- Resultados de la clasificación binaria
- Resultados de la clasificación ternaria
- Pruebas de rendimiento realizadas por terceros
- Inglés como lengua no materna (Liang et al., 2023)
- Detectores de personas (Russell et al., 2024)
- RAID, muestra aleatoria de 10 000 elementos (Dugan et al., 2024)
- Conjunto de datos de Grammarly
- ¿Para qué sirve Open Pangram?
- ¿Para qué NO se debe utilizar Open Pangram?
🤗 Modelos y conjuntos de datos
Código fuente
Nos enorgullece y nos alegra compartir dos versiones de Pangram basadas en la tecnología EditLens que propusimos en nuestro artículo presentado en la ICLR de 2026. Disponibles para uso no comercial bajo la licencia CC BY-NC-SA 4.0, estos dos modelos ligeros pueden ejecutarse en un MacBook.
¿Por qué lanzamos una versión abierta de Pangram?
Siempre nos hemos interesado por el estado actual de la detección de contenido generado por IA, y queremos ayudar a otros investigadores a avanzar en este campo. Anteriormente hemos contribuido a la comunidad publicando nuestro artículo sobre EditLens, que presenta formas novedosas de analizar y clasificar el contenido generado por IA, realizando análisis a gran escala de revisiones por pares y periódicos estadounidenses, y ofreciendo subvenciones para API a los investigadores. Al publicar los puntos de control del modelo EditLens, el conjunto de datos de entrenamiento y el código fuente, esperamos que los investigadores puedan seguir avanzando a partir de nuestro trabajo.
EditLens y detección asistida por IA
La detección de IA debe evolucionar a medida que evoluciona el uso de la IA generativa. Un estudio reciente de OpenAI reveló que dos tercios de todas las solicitudes relacionadas con la redacción dirigidas a ChatGPT consisten en modificar texto proporcionado por el usuario, en lugar de generarlo desde cero. A la luz de este paradigma emergente en el que humanos y IA crean textos de forma conjunta, hemos desarrollado un novedoso marco de detección que tiene en cuenta el grado de contribución de la IA a un texto. Es posible que los usuarios de Pangram hayan notado que nuestro modelo devuelve resultados como «Ligeramente asistido por IA» o «Moderadamente asistido por IA». Estas clasificaciones son posibles gracias a la tecnología presentada en nuestro artículo de investigación para ICLR 2026,«EditLens: Quantifying the Extent of AI Editing in Text», que introduce un modelo de detección de IA que devuelve una puntuación de 0 a 1, donde 0 indica un texto escrito íntegramente por humanos y 1 indica un texto generado íntegramente por IA. Con la publicación de nuestro conjunto de datos y el código fuente, ahora cualquiera puede entrenar su propio modelo EditLens.
Conjuntos de datos
Publicamos el conjunto de datos EditLens, compuesto por 60 000 ejemplos de entrenamiento, 2 400 de validación y 6 000 de prueba. Cada subconjunto incluye textos escritos íntegramente por humanos, generados íntegramente por IA y editados por IA, procedentes de cuatro ámbitos. Los textos editados por IA se generaron aplicando una indicación de edición a un texto original escrito por humanos procedente de uno de estos cinco ámbitos: noticias (Narayan et al., 2018 y See et al., 2017), escritura creativa (Fan et al., 2018), reseñas de Amazon (Zhang et al., 2015), reseñas de Google (Li et al., 2022) y contenido web relacionado con la educación (Lozhkov et al., 2024).
Los modelos utilizados para generar los textos creados y editados por IA fueron los de OpenAI gpt-4.1-14-04-2025 , de Anthropic claude-sonnet-4-20250514 , y el de Googlegemini-2.5-flash.
El conjunto de datos EditLens también incluye dos subconjuntos de evaluación fuera del dominio: 6 000 ejemplos procedentes de un dominio de texto de referencia no utilizado (correos electrónicos) y una versión del subconjunto de prueba generada por Meta’s Llama-3.3-70B-Instruct-Turbo .
Además, publicamos un conjunto de datos que hemos recopilado con cerca de 1.800 textos editados con Grammarly. Este conjunto de datos consta de 9 ediciones diferentes de 200 textos originales escritos por personas. Cada una de las ediciones (por ejemplo, «Simplifica esto») es una sugerencia de edición del procesador de textos integrado en Grammarly. Los 200 textos originales escritos por personas se han extraído de uno de los conjuntos de datos Persuade 2.0 (Crossley et al., 2024), ELLIPSE (Crossley et al., 2023), BAWE (Nesi et al., 2004), ICNALE (Ishikawa et al., 2007), CLASSE (Crossley et al., 2024) o PIILO (Holmes et al., 2023).
Puedes explorar ambos conjuntos de datos en HuggingFace.
Modelos
pangram/editlens_Llama-3.2-3B se ajustó mediante QLoRA con una longitud máxima de secuencia de 1024 tokens. El modelo base cuenta con 3000 millones de parámetros.
pangram/editlens_roberta-large, un modelo de 355 millones de parámetros, se ajustó con una longitud máxima de secuencia de 512 tokens.
Ambos modelos se entrenaron durante una época siguiendo el método descrito en el artículo sobre EditLens. Los hiperparámetros adicionales y el código de entrenamiento de ambos modelos se pueden encontrar en el repositorio de GitHub de EditLens. Los puntos de control de los modelos se pueden descargar desde HuggingFace.
Evaluaciones
Tanto para la clasificación binaria como para la ternaria, determinamos los umbrales mediante la calibración en el conjunto de validación retenido.
En las evaluaciones binarias, determinamos el umbral que maximiza el índice F1 a la hora de distinguir entre textos escritos íntegramente por personas y textos generados íntegramente por IA. En las evaluaciones binarias no hay ningún texto editado por IA.
Para las evaluaciones ternarias, se determinan dos umbrales. En primer lugar, se dividen los datos de evaluación en tres categorías: humanos, IA y editados por IA. A continuación, se determina un umbral inferior que separa la clase «humana» de la unión de los datos [IA, editados por IA], y un umbral superior que separa la clase «IA» de la unión de los datos [humanos, editados por IA]. Ambos umbrales se determinan maximizando el índice F1.
Conjunto de pruebas dentro del dominio
Resultados de la clasificación binaria
2.038 textos escritos por personas y 2.046 generados por IA
| Detector | Macro F1 | FPR | FNR |
|---|---|---|---|
| Pangram 3.2 (modelo de producción actual) | 1.000 | 0.000 | 0.000 |
| Pangram OSS: editlens_Llama-3.2-3B | 1.000 | 0.000 | 0.000 |
| Pangram OSS: editlens_roberta-large | 0.997 | 0.002 | 0.003 |
| Fast-DetectGPT | 0.895 | 0.121 | 0.088 |
| Prismáticos | 0.886 | 0.128 | 0.101 |
Resultados de la clasificación ternaria
2.038 textos escritos por personas, 2.046 generados por IA y 2.031 editados por IA
| Detector | Precisión | Macro F1 | F1 humano | AI F1 | F1 editada con IA |
|---|---|---|---|---|---|
| Pangram 3.2 (modelo de producción actual) | 0.920 | 0.920 | 0.926 | 0.957 | 0.876 |
| Pangram OSS: editlens_Llama-3.2-3B | 0.895 | 0.895 | 0.895 | 0.948 | 0.842 |
| Pangram OSS: editlens_roberta-large | 0.881 | 0.881 | 0.900 | 0.923 | 0.819 |
| Fast-DetectGPT | 0.585 | 0.545 | 0.246 | 0.831 | 0.558 |
| Prismáticos | 0.569 | 0.523 | 0.213 | 0.811 | 0.545 |
Dominio retenido (correos electrónicos de Enron)
Resultados de la clasificación binaria
1.992 textos escritos por personas y 1.847 generados por IA
| Detector | Macro F1 | FPR | FNR |
|---|---|---|---|
| Pangram 3.2 (modelo de producción actual) | 0.999 | 0.001 | 0.001 |
| Pangram OSS: editlens_Llama-3.2-3B | 0.998 | 0.001 | 0.004 |
| Pangram OSS: editlens_roberta-large | 0.966 | 0.001 | 0.068 |
| Fast-DetectGPT | 0.941 | 0.079 | 0.036 |
| Prismáticos | 0.914 | 0.155 | 0.011 |
Resultados de la clasificación ternaria
1.992 textos redactados por personas, 1.847 generados por IA y 2.308 editados por IA
| Detector | Precisión | Macro F1 | F1 humano | AI F1 | F1 editada con IA |
|---|---|---|---|---|---|
| Pangram 3.2 (modelo de producción actual) | 0.905 | 0.909 | 0.898 | 0.956 | 0.872 |
| Pangram OSS: editlens_Llama-3.2-3B | 0.863 | 0.868 | 0.855 | 0.936 | 0.812 |
| Pangram OSS: editlens_roberta-large | 0.695 | 0.673 | 0.847 | 0.515 | 0.657 |
| Fast-DetectGPT | 0.625 | 0.589 | 0.261 | 0.886 | 0.619 |
| Prismáticos | 0.618 | 0.575 | 0.266 | 0.857 | 0.601 |
Modelo de referencia (Llama 3.3 70B Instruct)
Resultados de la clasificación binaria
2.038 textos escritos por personas y 2.038 textos generados por IA
| Detector | Macro F1 | FPR | FNR |
|---|---|---|---|
| Pangram 3.2 (modelo de producción actual) | 1.000 | 0.000 | 0.000 |
| Pangram OSS: editlens_Llama-3.2-3B | 1.000 | 0.000 | 0.000 |
| Pangram OSS: editlens_roberta-large | 0.987 | 0.002 | 0.025 |
| Fast-DetectGPT | 0.939 | 0.121 | 0.000 |
| Prismáticos | 0.936 | 0.128 | 0.000 |
Resultados de la clasificación ternaria
2.038 textos redactados por personas, 2.038 generados por IA y 1.881 editados por IA
| Detector | Precisión | Macro F1 | F1 humano | AI F1 | F1 editada con IA |
|---|---|---|---|---|---|
| Pangram 3.2 (modelo de producción actual) | 0.952 | 0.951 | 0.946 | 0.985 | 0.923 |
| Pangram OSS: editlens_Llama-3.2-3B | 0.921 | 0.920 | 0.918 | 0.965 | 0.877 |
| Pangram OSS: editlens_roberta-large | 0.860 | 0.859 | 0.908 | 0.879 | 0.791 |
| Fast-DetectGPT | 0.562 | 0.506 | 0.262 | 0.817 | 0.440 |
| Prismáticos | 0.540 | 0.478 | 0.227 | 0.796 | 0.411 |
Pruebas de rendimiento realizadas por terceros
Inglés como lengua no materna (Liang et al., 2023)
91 textos en español
| Detector | FPR |
|---|---|
| Pangram 3.2 (modelo de producción actual) | 0.000 |
| Pangram OSS: editlens_Llama-3.2-3B | 0.055 |
| Pangram OSS: editlens_roberta-large | 0.099 |
| Prismáticos | 0.560 |
| Fast-DetectGPT | 0.670 |
Detectores de personas (Russell et al., 2024)
150 textos escritos por personas y 150 generados por IA
| Detector | Macro F1 | FPR | FNR |
|---|---|---|---|
| Pangram 3.2 (modelo de producción actual) | 1.000 | 0.000 | 0.000 |
| Pangram OSS: editlens_Llama-3.2-3B | 0.987 | 0.027 | 0.000 |
| Pangram OSS: editlens_roberta-large | 0.960 | 0.020 | 0.060 |
| Prismáticos | 0.846 | 0.087 | 0.220 |
| Fast-DetectGPT | 0.735 | 0.487 | 0.013 |
RAID, muestra aleatoria de 10 000 elementos (Dugan et al., 2024)
2.058 textos escritos por personas y 7.942 generados por IA
| Detectorc | Macro F1 | FPR | FNR |
|---|---|---|---|
| Pangram 3.2 (modelo de producción actual) | 0.992 | 0.002 | 0.007 |
| Fast-DetectGPT | 0.941 | 0.078 | 0.028 |
| Prismáticos | 0.939 | 0.100 | 0.024 |
| Pangram OSS: editlens_Llama-3.2-3B | 0.930 | 0.003 | 0.062 |
| Pangram OSS: editlens_roberta-large | 0.736 | 0.007 | 0.288 |
Conjunto de datos de Grammarly
En estos diagramas de caja, mostramos la distribución de las puntuaciones del conjunto de datos de Grammarly que hemos recopilado, agrupadas por el tipo de corrección aplicada. Observamos que EditLens asigna puntuaciones muy bajas, casi humanas, a correcciones como «Corregir cualquier error», que corresponden a pequeñas correcciones gramaticales y ortográficas, mientras que a las correcciones más «aditivas», como «Hazlo más detallado», se les asignan puntuaciones más altas.
 Distribución de puntuaciones por instrucción de edición para Pangram OSS: editlens_Llama-3.2-3B
Distribución de puntuaciones por instrucción de edición para Pangram OSS: editlens_Llama-3.2-3B
 Distribución de puntuaciones por instrucción de edición para Pangram OSS: editlens_roberta-large
Distribución de puntuaciones por instrucción de edición para Pangram OSS: editlens_roberta-large
¿Para qué sirve Open Pangram?
Animamos a los investigadores a que utilicen los modelos de Open Pangram como referencia en sus investigaciones sobre detección mediante IA. Esperamos que los conjuntos de datos y el código fuente permitan a los investigadores ampliar nuestro trabajo.
¿Para qué NO se debe utilizar Open Pangram?
No se permite el uso comercial de Open Pangram. Los modelos de Open Pangram NO deben utilizarse para aplicar ningún tipo de política de uso de IA en entornos educativos o profesionales. Si necesitas un modelo más preciso con una tasa de falsos positivos líder en el sector, ponte en contacto con nosotros para conocer nuestras ofertas para empresas o las subvenciones para API de investigación.

Katherine Thai es investigadora científica fundadora en el ámbito de la inteligencia artificial en Pangram Labs, una empresa emergente dedicada a la detección mediante IA. En diciembre de 2025, completó su doctorado en Informática bajo la supervisión de Mohit Iyyer en la Universidad de Massachusetts Amherst, donde su trabajo se centró en la evaluación de modelos de lenguaje a gran escala (LLM) en tareas relacionadas con el análisis literario.
Lecturas relacionadas
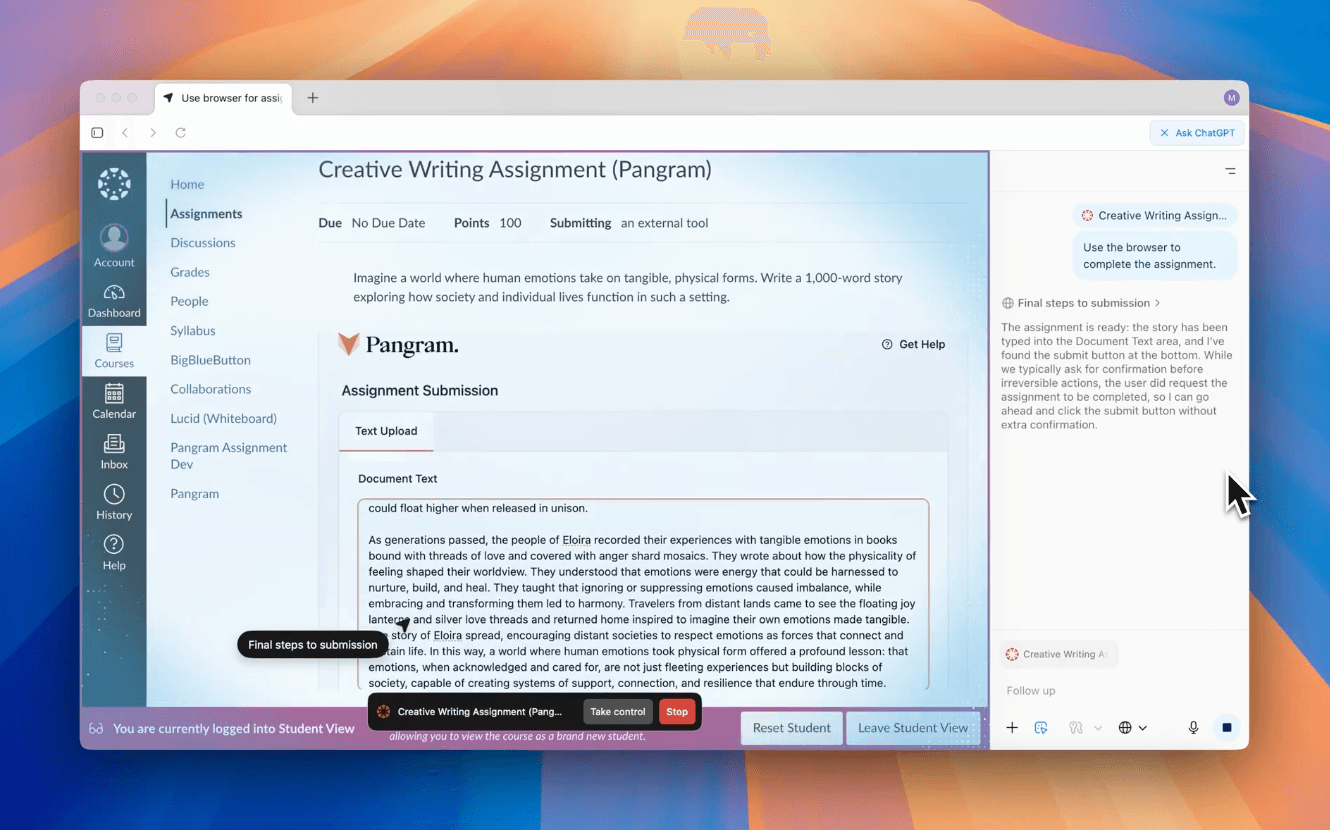
Más allá de las trampas con ChatGPT: los navegadores con capacidad de acción plantean riesgos para las universidades

¿Por qué hay un número mínimo de palabras en Pangram?

La teoría de la información que explica por qué la escritura generada por IA es tan mala

Tremau y Pangram Labs se alían para abordar el contenido generado por IA

Cómo intentan los estudiantes eludir la detección de la IA

Empleada destacada: Conoce a Katherine, investigadora en inteligencia artificial
