
Voir dans l'espace Pangram
Analyse des représentations internes du pangramme 3.3.2
Par Elyas Masrour, Katherine Thai et Bradley Emi
juin 2026
Introduction
Depuis le lancement de ChatGPT en 2022, la rédaction assistée par l’IA s’est développée à un rythme effréné. Les textes générés par l’IA étant désormais omniprésents dans ce que nous lisons, il est devenu évident que certaines formes d’écriture perdent de leur valeur lorsqu’elles sont produites par une machine. Dans le milieu universitaire, les dissertations ont pour but de développer le raisonnement des étudiants. Sur le marché, les avis sur les produits sont précieux car ils reflètent les expériences d’autres personnes.
Pangram est une société de recherche qui développe des modèles de détection par IA de pointe pour répondre à ce problème. Notre produit phare est un modèle de détection de textes générés par IA qui se distingue par des taux de faux positifs parmi les plus bas du secteur, des capacités multilingues et la capacité à distinguer les textes générés par IA de ceux créés avec l'aide de l'IA.
Depuis la publication de notre premier livre blanc en 2024, nous avons eu la chance unique d’observer se succéder les avancées en matière d’IA. Nos chercheurs se sont heurtés à des filtres de contenu trop stricts et ont été confrontés à de nombreux cas de « mode collapse », tout en esquivant des vagues de tirets longs et le mot « delve ».
Notre modèle phare est un LLM (modèle de langage à grande échelle) spécialement optimisé pour cette tâche de classification de séquences. Nous n’utilisons pas de métriques personnalisées telles que la perplexité ou la « burstiness ». Nous ne procédons à aucune extraction manuelle de caractéristiques. Nous proposons toutefois un produit destiné aux clients, appelé « AI Phrases », dans lequel nous fournissons à nos utilisateurs des informations sur les expressions qui apparaissent le plus fréquemment dans les textes générés par l’IA. Mais celles-ci ne sont pas directement utilisées comme caractéristiques pour le modèle. Au bout d’un certain temps, la curiosité prend le dessus. Que voit donc le modèle ?
Pour nous, en tant que chercheurs, cette question revêt une grande importance. Nous sommes fortement motivés à éviter les raccourcis, à corriger les comportements imprévus des modèles et à approfondir notre compréhension de ce problème. Dans cet article, nous présenterons nos premiers travaux sur l'interprétabilité à l'aide d'une analyse au niveau des documents.
Données
Nous avons constitué un ensemble de données d'interprétabilité à partir d'échantillons « held-out » issus de notre ensemble d'apprentissage de production et appartenant au même domaine. L'explorateur interactif présenté sur cette page utilise un sous-ensemble équilibré de 5 000 documents, répartis de manière égale entre les échantillons générés par l'humain et ceux générés par l'IA, sur 20 couches paires. Les échantillons générés par l'IA couvrent les variantes de modèles ci-dessous, issues des six familles de modèles utilisées pour le test du classificateur.
Modèles
- Claude 3.7 Sonnet
- Claude Sonnet 4
- Claude Sonnet 4,5
- Claude Opus 4
- Claude Opus 4.1
- Claude Opus 4.5
- GPT-3.5 Turbo (novembre 2023)
- GPT-3.5 Turbo (janvier 2024)
- GPT-4 (mars 2023)
- GPT-4 (juin 2023)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- Qwen 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
Domaines sources
- Actualités
- Résumés scientifiques
- Avis sur les produits
- Avis sur les entreprises
- Écriture créative sur Reddit
- Reddit ELI5
- Livres (auto-édités)
- Livres (Projet Gutenberg)
- Wikipédia (anglais)
- Wikipédia (multilingue)
- Lang-8 (ESL)
Présentation de Pangram 3.3.2
Pangram 3.3.2 est un modèle de détection de l'IA lancé par Pangram Labs en 2026. Il repose sur le même modèle de base que Pangram 3.3, mais intègre des corrections de bogues ultérieures qui améliorent ses performances. Successeur de Pangram 3.2, Pangram 3.3 a amélioré le taux de rappel pour les sorties des nouveaux modèles de langage à grande échelle (LLM), les textes humanisés et les contenus longs générés par l'IA, tout en réduisant les faux positifs sur les textes rédigés dans un anglais non natif.
Fiche techniqueLire la fiche technique du modèle Pangram 3.3Consultez les détails de la version Pangram 3.3.2.Lire l'articleLes travaux sur l'interprétabilité se poursuivent. Tout au long de cet article, nous appliquons également nos méthodes a posteriori aux pangrammes 3.2 et 3.1.
Méthodes
Activations
L'architecture EditLens est un système de classification par « buckets » qui se résume à un seul score_d'assistance_IA. Dans le cadre de ce projet, nous ne tenons pas compte du résultat final du modèle, mais nous nous concentrons plutôt sur les représentations internes qu’il apprend. Pour les analyser, nous recueillons les activations en effectuant un passage en avant du modèle avec un document d’entrée donné, puis en enregistrant la représentation cachée du modèle à plusieurs couches internes. Pour ce projet, nous avons extrait les activations pour chaque document, à chaque couche paire du réseau.
Réduction de la dimensionnalité
Chaque vecteur d'activation extrait comportait 5 120 dimensions. Afin de mieux comprendre ces représentations, nous avons eu recours à plusieurs techniques de réduction de dimensionnalité.
PCA
L'analyse en composantes principales (ACP) est la projection linéaire la plus simple : elle permet de déterminer les directions de variance maximale dans l'espace d'activation. Dans le cadre de ce projet, nous constatons qu'à l'extrémité du réseau, la majeure partie de la variance est contenue dans les composantes principales 1 et 2 ; c'est pourquoi nous les représentons graphiquement l'une par rapport à l'autre.
UMAP
L'UMAP offre une représentation non linéaire conçue pour préserver la structure de voisinage. Si deux documents sont proches l'un de l'autre dans l'espace interne du modèle, l'UMAP s'efforce de les maintenir proches dans l'espace bidimensionnel. Il convient toutefois de ne pas accorder une importance excessive aux axes et aux distances exactes entre les grappes.
t-SNE
Le t-SNE est une autre méthode de projection non linéaire particulièrement efficace pour mettre en évidence les regroupements locaux. Dans le cadre de ce projet, nous utilisons le t-SNE pour déterminer si les groupes présentant un intérêt sémantique, tels que les familles de modèles ou les étiquettes « humain »/« IA », se regroupent de manière visible à mesure que le réseau s'approfondit.
Capteurs linéaires
Nous utilisons des sondes linéaires pour quantifier les résultats qualitatifs obtenus grâce à nos méthodes de réduction de dimensionnalité. Pour chaque couche, nous cherchons à déterminer si un classificateur simple est capable de récupérer une étiquette cible à partir des vecteurs d’activation de cette couche. Une grande précision de la sonde indique que la distinction pertinente est déjà codée dans une direction linéairement accessible de l’espace de représentation.
La tâche de détection par IA
Précision binaire
Pour comprendre comment la séparation finale des classes s’opère au fil du réseau, nous entraînons des sondes linéaires à chaque couche. Nous effectuons l’entraînement sur 500 échantillons, répartis de manière égale entre les données humaines et celles générées par l’IA, avec une répartition entraînement/test de 80/20. Nous constatons que, même dès les premières couches du réseau, les performances sont déjà élevées : nous atteignons une précision de 0,83 dès la fin de la couche 2. Cela correspond à notre intuition, car les modèles de type « bag-of-words » constituent souvent des références valables pour la tâche de détection de l’IA. Tout au long du réseau, la précision s’améliore jusqu’à atteindre son maximum, soit 1,0, à la couche 24.
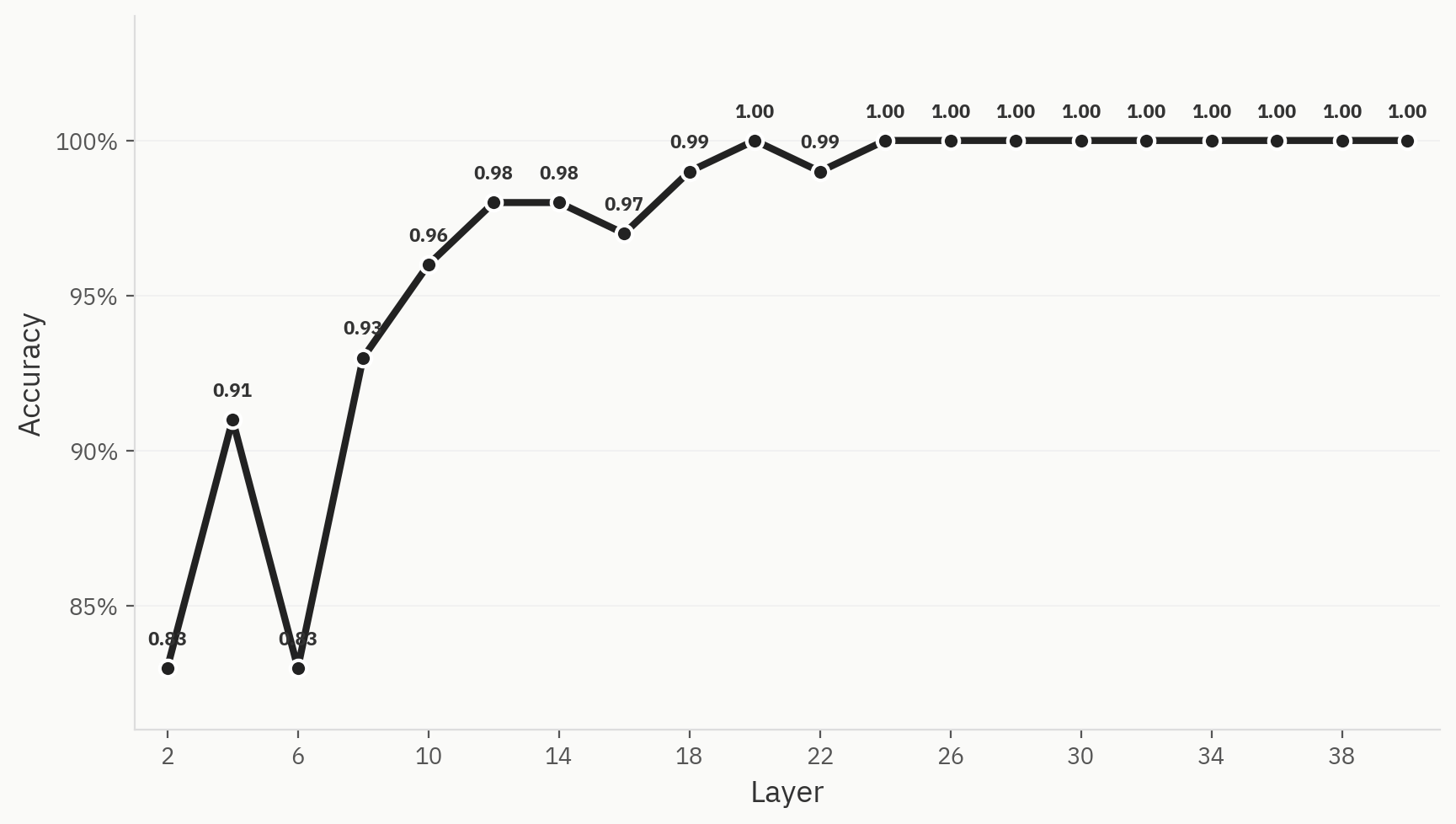
Fig. 3 Cette séparation est clairement visible dans les trois méthodes de réduction de dimensionnalité.
Classification LLM
Sur les graphiques t-SNE et UMAP, nous avons remarqué que les documents semblaient se regrouper en fonction du modèle qui les avait générés. Cela nous a surpris. Les anciennes versions de Pangram comportaient un module de classification LLM distinct, mais cette tâche avait été abandonnée depuis longtemps. Lors de son apprentissage, Pangram 3.3.2 ne reçoit aucune étiquette correspondant au modèle d'origine d'un document généré par l'IA.
Malgré tout, des grappes se sont formées autour de la famille de modèles d'origine. Plus intéressant encore, ces grappes semblent apparaître à tous les niveaux du réseau.
Émergence de grappes de modèles
Colorez les mêmes représentations selon la famille de modèles afin de voir apparaître la géométrie au niveau du fournisseur à travers les couches.
Fig. 4: Représentations des couches 2 à 40, classées par famille de modèles. Les regroupements au niveau des fournisseurs deviennent plus visibles dans les couches suivantes.
Sonde
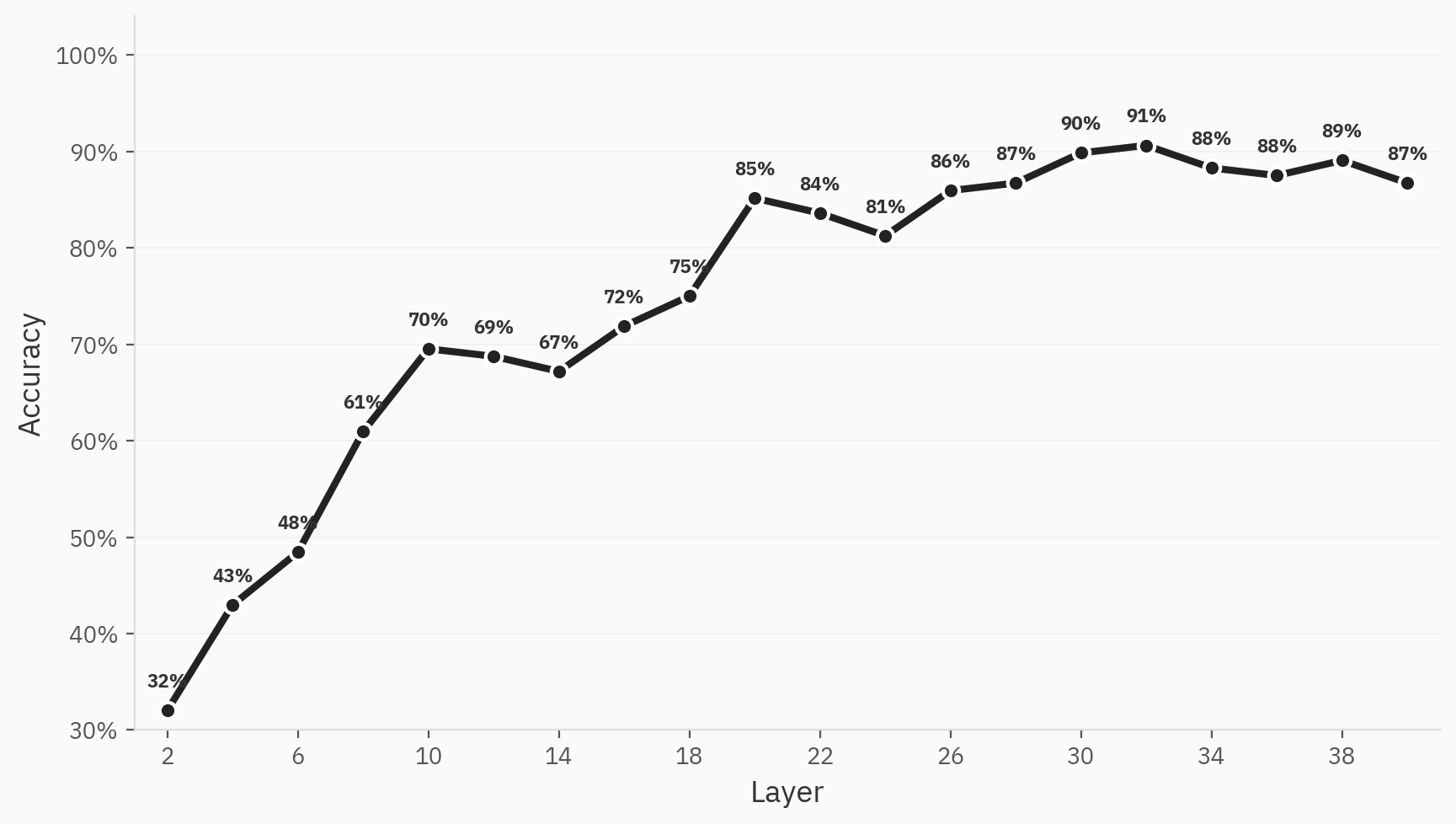
Pour quantifier ce phénomène, nous entraînons un classificateur sur six familles de modèles (Anthropic, OpenAI, Google, Qwen, Llama, DeepSeek) à partir de 500 échantillons par famille de modèles, soit 3 000 échantillons au total, avec une répartition 80/20 entre les données d'entraînement et de test. Nous constatons qu'il est effectivement possible d'entraîner un modèle capable de classer la famille de modèles d'origine d'un document donné en utilisant uniquement les activations Pangram, avec une précision top-1 maximale de 91 %.
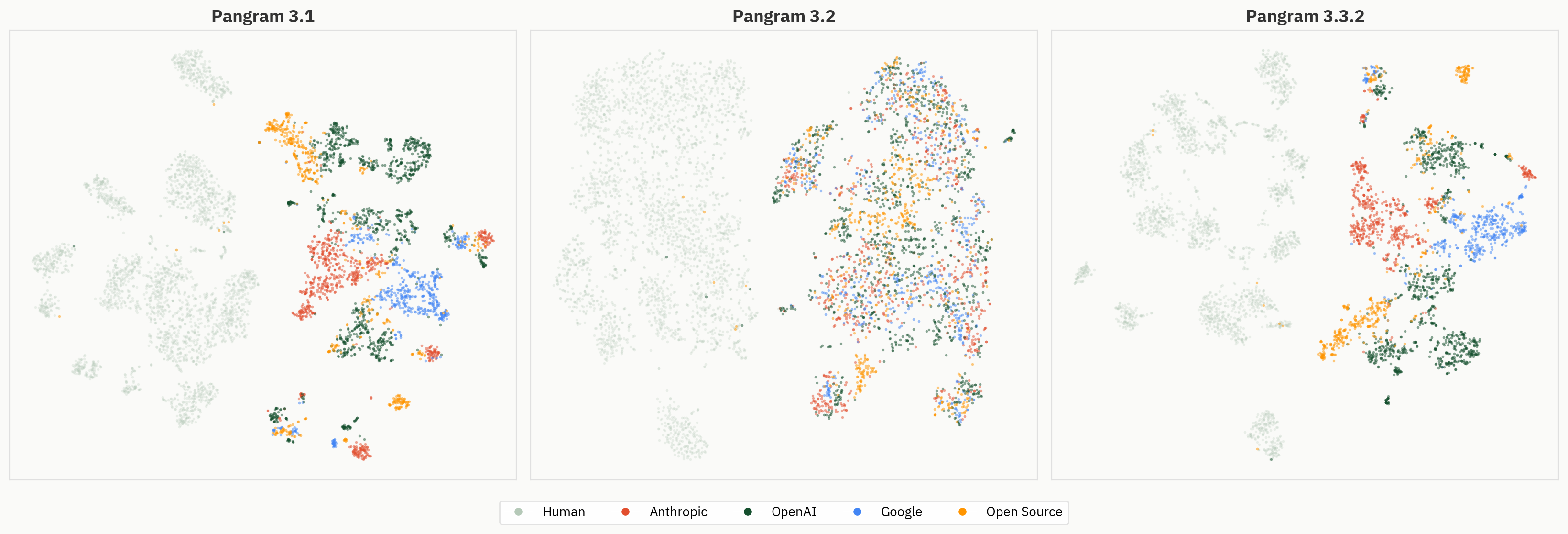
L'émergence n'est pas garantie
Nos premières expériences sur l'interprétabilité ont consisté à tester plusieurs modèles. À notre grande surprise, l'émergence d'une capacité de « classification par LLM » a été l'un des seuls résultats de ce projet à présenter des différences significatives d'un modèle à l'autre.
Le graphique ci-dessous compare le comportement de regroupement des versions 3.1, 3.2 et 3.3.2 de Pangram. Bien que ce modèle ait obtenu de meilleurs résultats que la version 3.1 sur la tâche binaire « humain-IA » lors de nos évaluations internes de validation, les regroupements obtenus avec ce modèle sont globalement moins nets sur Pangram 3.2 que sur Pangram 3.1 ou 3.3.2.
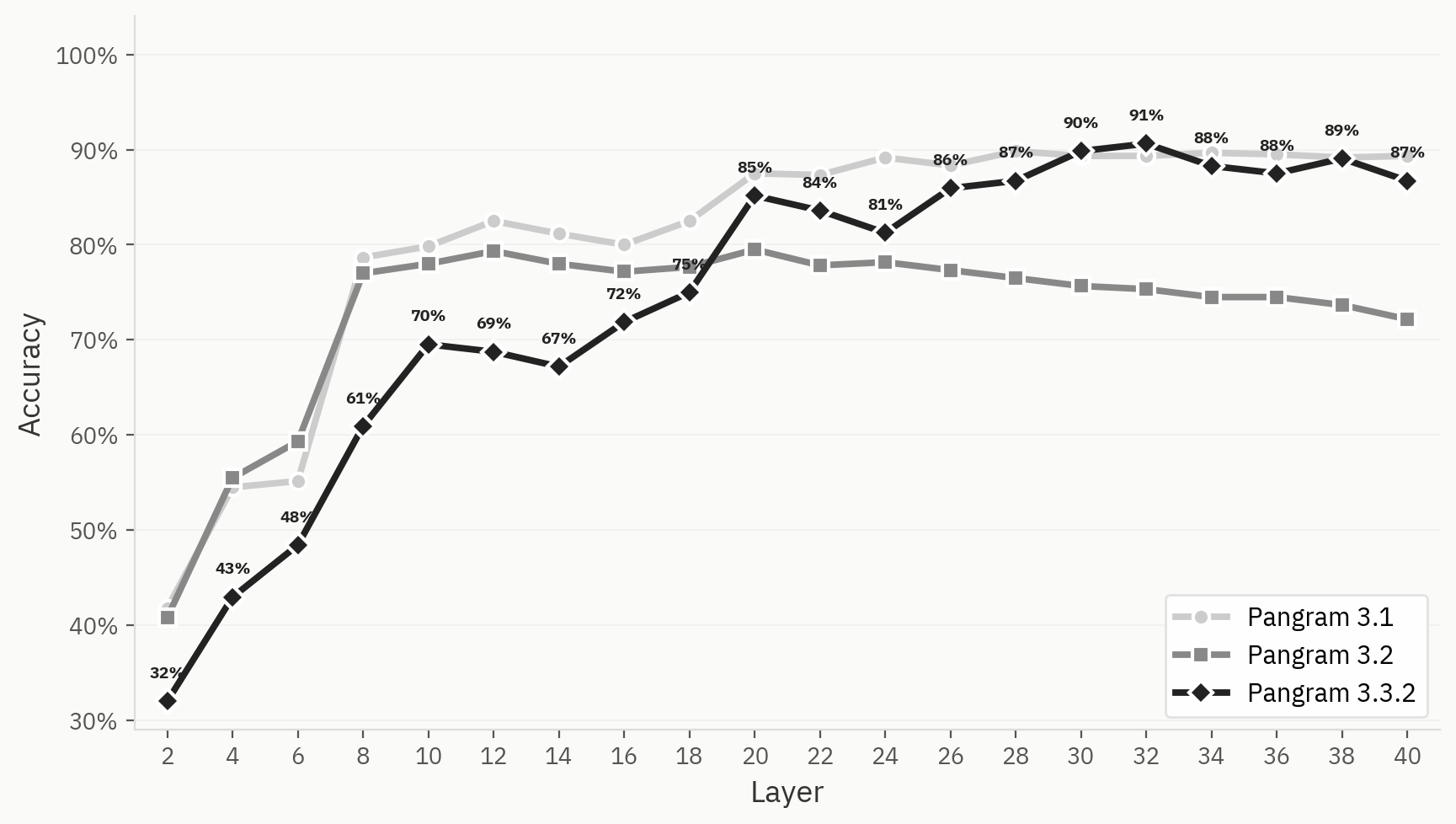
Pour illustrer davantage cette différence, nous comparons la courbe de performance du classificateur LLM sur les pangrammes 3.1, 3.2 et 3.3.2. Les trois pangrammes affichent une amélioration de leur précision top-1 dans les premières couches, mais la courbe de performance du pangramme 3.2 commence à baisser après la couche 12, tandis que celles des pangrammes 3.1 et 3.3.2 restent élevées.
Humanisateurs
Les « humanizers » constituent une catégorie d'outils adversariaux conçus pour modifier les textes générés par l'IA de manière à échapper aux détecteurs d'IA. Afin de déterminer où se situe le texte humanisé par rapport au texte humain et au texte généré par l’IA dans l’espace d’activation, nous avons créé un ensemble de données distinct dédié aux humaniseurs, composé d’environ 1 900 échantillons, répartis de manière à peu près équilibrée entre trois modèles génératifs (Claude Sonnet 4.5, Gemini 2.5 Pro et GPT-5), dix services d’humanisation différents et les mêmes domaines sources que l’ensemble de données d’interprétabilité d’origine. En raison des risques liés à l'adversarial, nous ne divulguons pas les services que nous utilisons.
Comment le modèle identifie les « humanisateurs »
Certains échantillons de notre ensemble de données « humanizer » posent en effet des difficultés à notre modèle. Ici, nous utilisons la même sonde linéaire pour la tâche « humain/IA », à la différence près que le texte humanisé est étiqueté comme provenant de l’IA, comme nous le faisons dans la configuration d’apprentissage d’origine. Nous constatons que, dès la première couche, le texte humanisé est systématiquement interprété comme étant plus « humain » que son équivalent direct issu de l’IA.
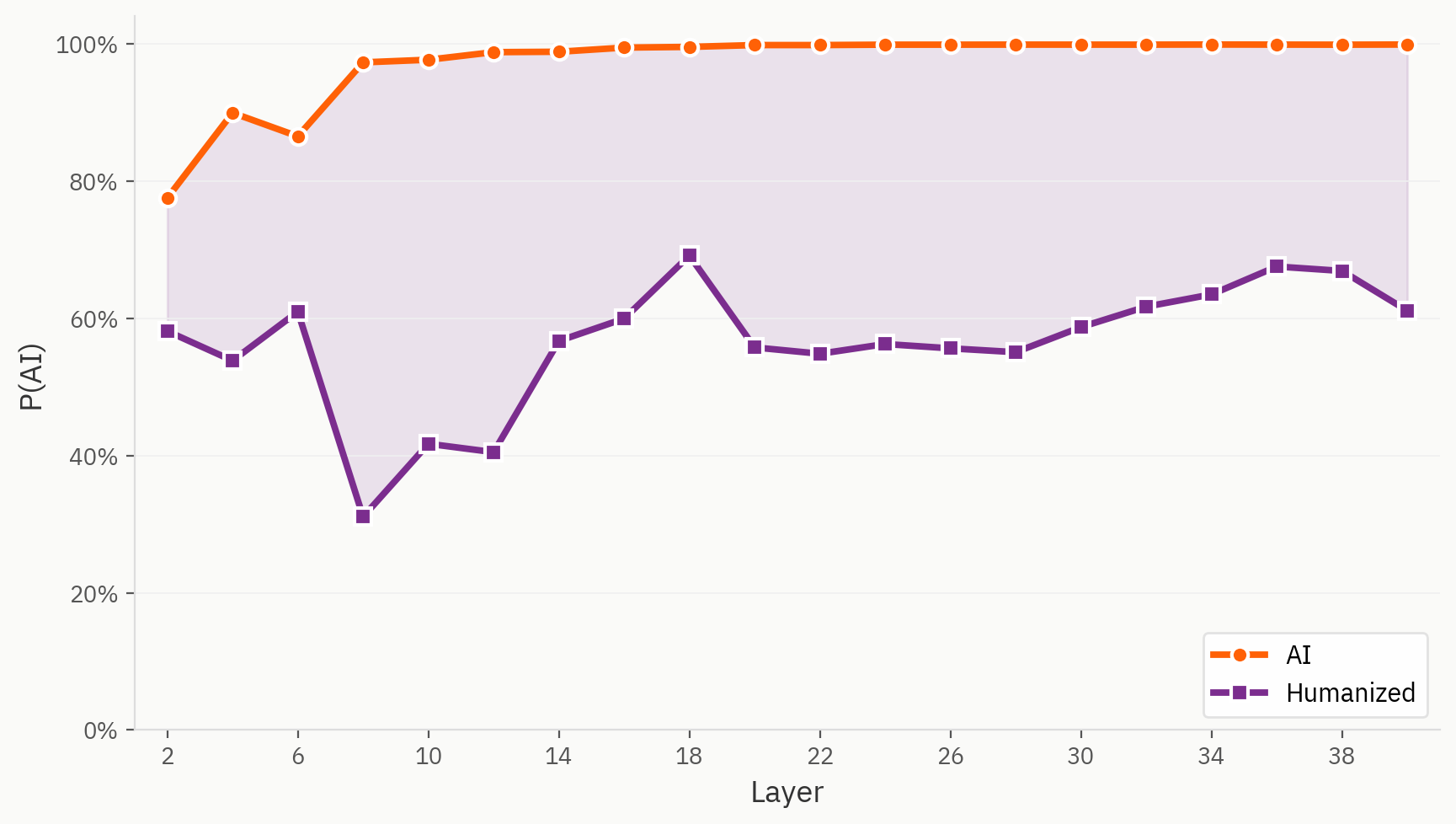
Où se situent les « humaniseurs » dans l'espace d'intégration ?
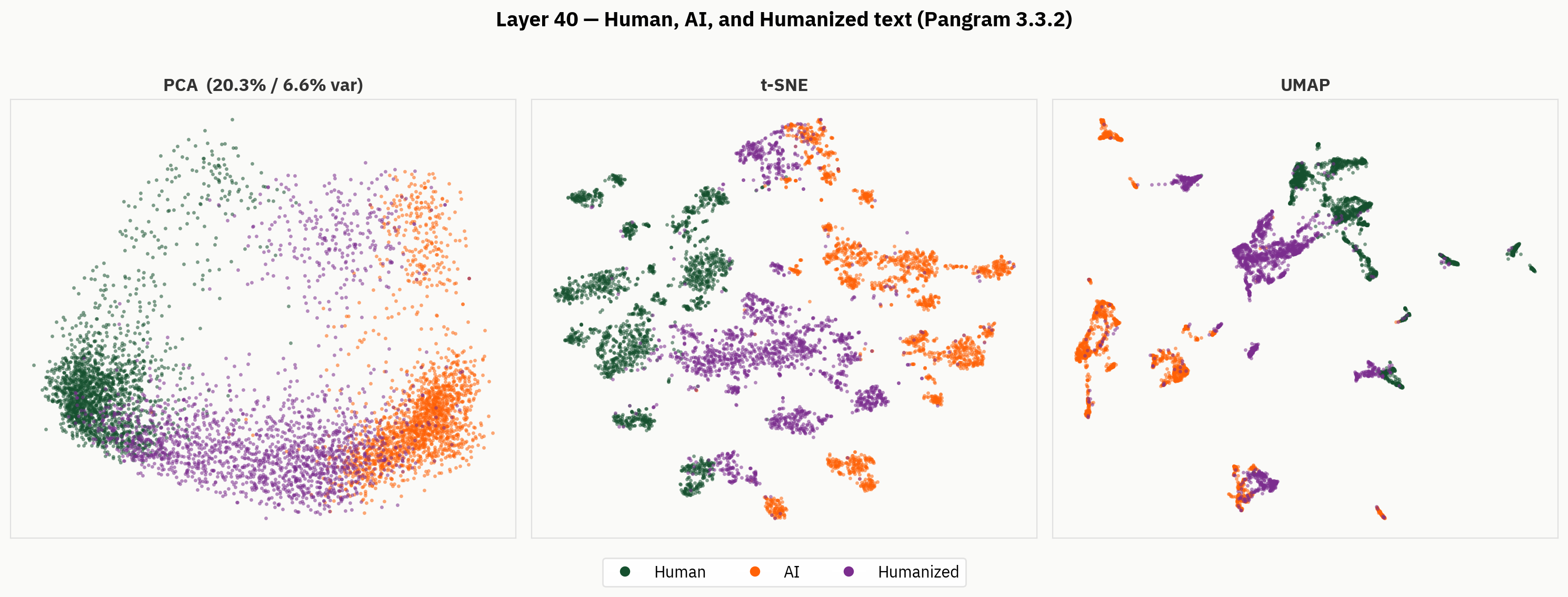
Cependant, lorsque l'on examine les résultats en profondeur, on découvre une représentation bien plus riche du texte humanisé. Ci-dessous, nous appliquons nos méthodes de réduction de dimensionnalité aux textes humains, à ceux générés par l'IA et aux textes humanisés. D'un point de vue qualitatif, on constate que les textes humanisés ont tendance à occuper des zones distinctes de l'espace d'activation et à former des grappes en dehors des régions correspondant aux textes humains et à ceux générés par l'IA.
Notre hypothèse est que, bien qu'il ne dispose pas d'étiquettes pour les textes « humanisés », le modèle est capable de faire la distinction entre les textes « humanisés », les textes rédigés par des humains et ceux générés par l'IA. Cependant, lors de l'interprétation finale, le modèle est contraint de réduire ce signal à une seule catégorie, et il le fait de manière incohérente.
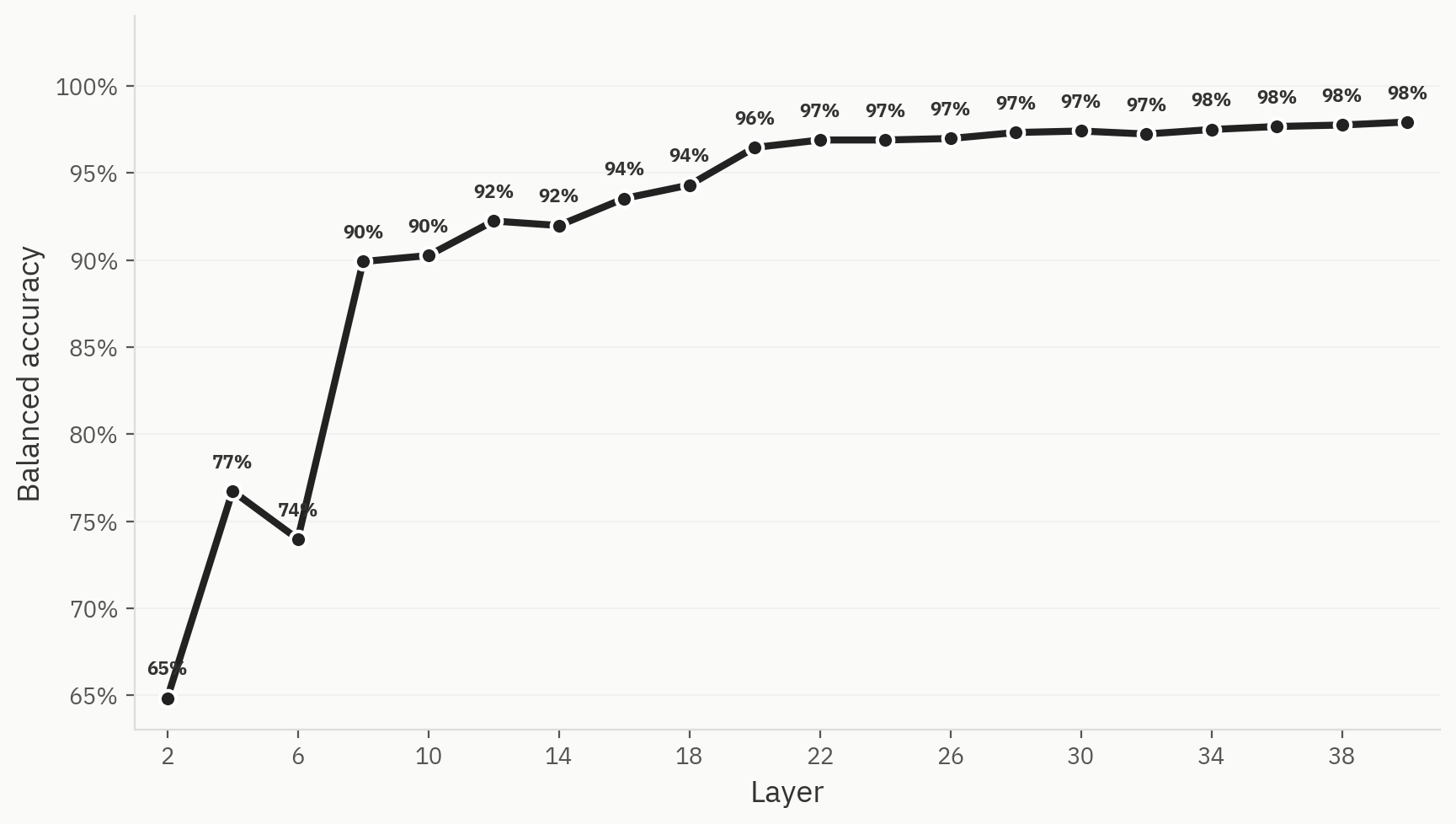
Sonde
Pour valider cette hypothèse, nous entraînons un modèle de sondage linéaire à trois classes avec des étiquettes pour les textes générés par l'IA, les textes humains et les textes humanisés. Le modèle atteint rapidement une précision top-1 élevée dès les premières couches du réseau, puis se stabilise finalement à 98 %.
Conclusion
Nos travaux suggèrent que les représentations internes de Pangram comportent davantage de structure que ne le laisse supposer la simple lecture binaire finale. D’une couche à l’autre, nous observons une distinction entre les documents rédigés par des humains et ceux générés par l’IA, l’émergence d’informations relatives à la famille de modèles, ainsi que le fait que le texte « humanisé » occupe sa propre région dans l’espace d’activation. Ces résultats sont encore préliminaires, mais ils nous fournissent une carte utile pour comprendre ce que le modèle apprend avant de tout réduire à un seul score de détection.
Cet article ne présente que les premières étapes de nos travaux sur l'interprétabilité, mais en interne, nous sommes enthousiastes et intéressés par cette orientation de recherche.
Notre vision en matière d'interprétabilité et d'explicabilité des modèles Pangram est qu'ils permettent :
- Permettre une meilleure compréhension interne du comportement du modèle.
- Fournir des éléments justificatifs et des explications plus claires concernant les résultats individuels du pangramme.
Si vous êtes chercheur et que vous vous intéressez à l'interprétabilité, à la recherche sur la détection de l'IA ou à tout autre aspect de ces travaux, n'hésitez pas à nous contacter à l'adresse elyas@pangram.com.
