Détection par IA pour les équipes d'apprentissage automatique et de données
Détecteur d'IA pour les ingénieurs en apprentissage automatique et les scientifiques des données
Optimisez l'entraînement des modèles de langage à grande échelle (LLM) et la sélection des données. Évitez l'effondrement des modèles en filtrant les textes synthétiques de vos ensembles de données de pré-entraînement ou de réglage fin, avec une précision de 99,98 % et une API à haut débit.
Développé par des chercheurs de Google, Tesla et Stanford. Validé par l'ICLR et l'université du Maryland.
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")
















Cas d'utilisation
Ne formez pas vos modèles
à partir de données de mauvaise qualité.
Les textes synthétiques polluent les ensembles de données publics. Filtrez le contenu généré par l'IA de vos pipelines d'entraînement à l'aide du moteur de détection d'IA le plus précis qui soit afin de préserver la pureté de votre corpus.
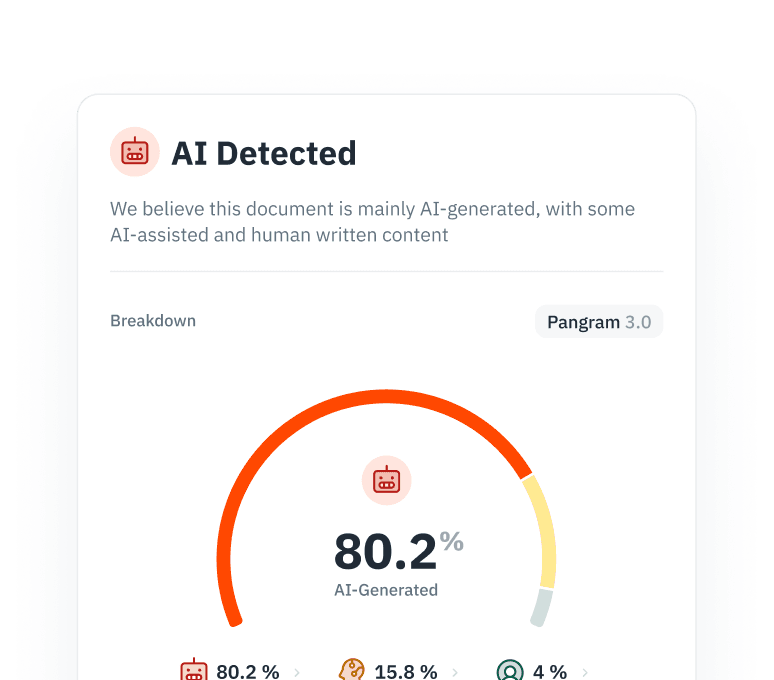
Empêcher l'effondrement du modèle
L'entraînement récursif sur du contenu généré par l'IA nuit aux performances et à la diversité du modèle. Identifiez et filtrez le contenu rédigé par l'IA dans vos pipelines de scraping afin de garantir la pureté du corpus.
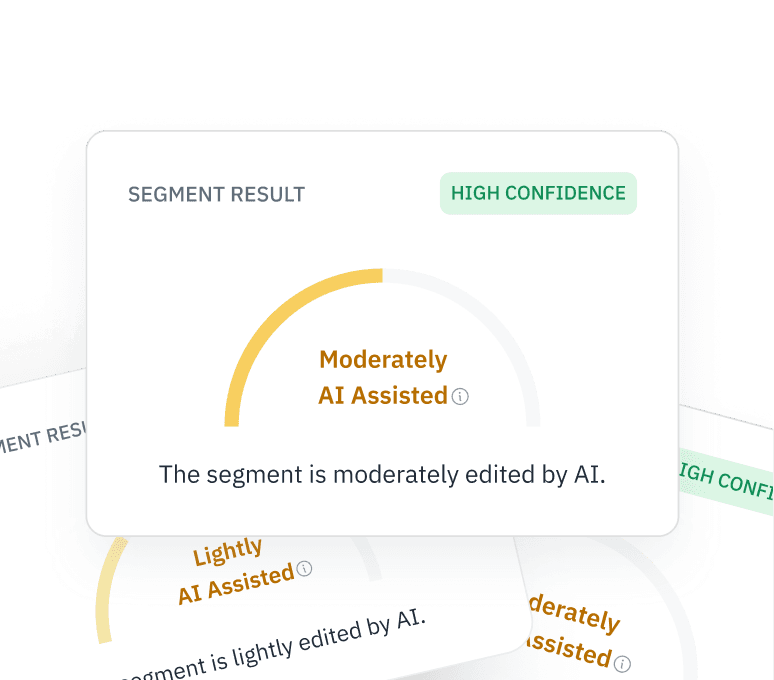
Vérifier les données d'entrée du RLHF
Assurez-vous que vos données de rétroaction humaine (RLHF) proviennent bien d'êtres humains. Vérifiez si les contributeurs en ligne utilisent ChatGPT pour générer des réponses dans le cadre de vos tâches de réglage fin.
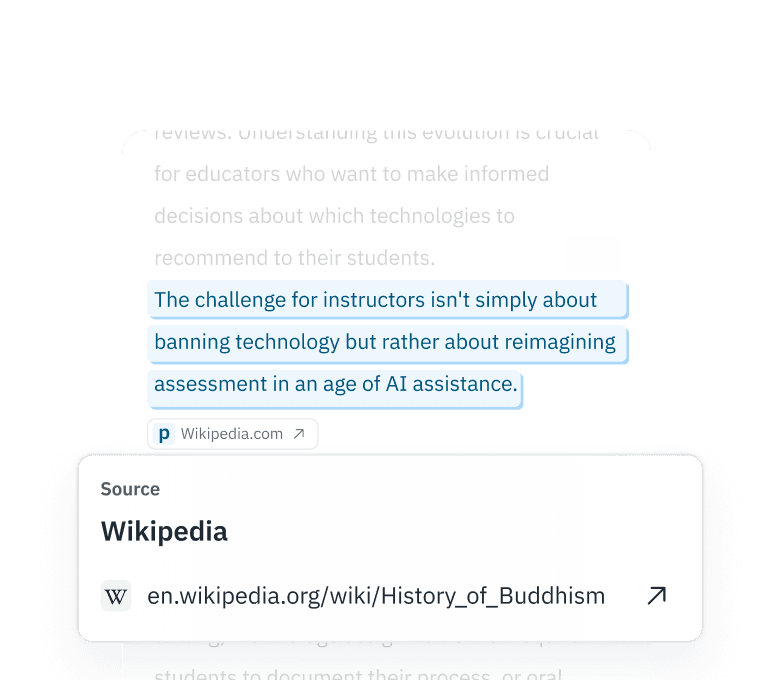
Interprétabilité granulaire
Ne vous contentez pas d'une classification binaire. Notre API Premium fournit des probabilités au niveau des tokens, ce qui vous permet de conserver les segments révisés par des humains tout en écartant les « éléments de mauvaise qualité » entièrement synthétiques.
Approche technique
Un modèle en qui vous pouvez avoir confiance
Conçu pour les ingénieurs qui ont besoin d'avoir confiance dans le filtrage de leurs données. Notre modèle traite les faux positifs, la robustesse face aux attaques adversaires et l'évolution des résultats générés par l'IA.

Exploitation minière « hard negative »
Nous utilisons des « exemples négatifs difficiles » — des textes rédigés par des humains, au style formel ou répétitif — afin de réduire au minimum les faux positifs et de vous éviter de rejeter des données humaines précieuses.
Robustesse face aux attaques adverses
Pangram traite les contenus générés par l'IA qui ont été paraphrasés ou modifiés. Nos modèles sont entraînés à résister aux « humaniseurs » et aux attaques adversaires afin de détecter les textes synthétiques dissimulés.
Anticiper l'avenir
Détecte le texte généré par les derniers modèles, notamment GPT-5, Claude 3.5 et Llama 3, garantissant ainsi que vos filtres restent à la pointe de la technologie.
Intégration
Conçu pour votre pipeline de données d'

01
SDK Python
Installez pangram-sdk et intégrez la détection dans vos pipelines Airflow ou Databricks en quelques lignes de code seulement. Optimisé pour la mise en pool des connexions et la gestion des erreurs.
Consulter les documents →
02
API d'
s à haut débit
Traitez des ensembles de données volumineux avec une faible latence. Notre infrastructure prend en charge le traitement par lots et garantit un débit élevé, permettant de traiter des millions de requêtes pour les opérations de scraping d'entreprise.
Obtenir une clé API →
03
Sécurité et conformité aux normes de l'
Entièrement certifié SOC 2 Type 2. Nous proposons des terminaux privés et appliquons des politiques strictes en matière de conservation des données — nous n'utilisons jamais vos données propriétaires pour l'entraînement de nos modèles.
En savoir plus →
Foire aux questions
FAQ sur la détection par IA
Questions fréquentes sur la détection de l'IA à l'intention des ingénieurs en apprentissage automatique
et des data scientists.
Oui. Vous pouvez installer le pangram-sdk pour intégrer la détection dans les pipelines Airflow ou Databricks en quelques lignes de code seulement. Notre API est optimisée pour les opérations de scraping d'entreprise à haut débit et prend en charge des millions de requêtes avec une faible latence.
En savoir plus
Détection par IA pour
toutes les entreprises
Pour les développeurs
Détection de code généré par l'IA pour les développeurs et les équipes d'ingénieurs. Détectez le code généré par l'IA à partir de ChatGPT, Copilot et Claude en Python, Java, C++ et bien d'autres langages.
En savoir plus →Pour la modération des contenus
Modération de contenu par IA pour les équipes chargées de la confiance et de la sécurité. Détectez à grande échelle les avis générés par l'IA, les faux commentaires et le contenu synthétique via une API.
En savoir plus →Pour les universités
Détection de l'IA pour les universités et l'enseignement supérieur. Vérifiez les devoirs des étudiants, examinez les travaux de recherche et protégez la réputation de votre établissement.
En savoir plus →Nettoyez vos données d'entraînement dès aujourd'hui
Évitez l'effondrement des modèles, vérifiez les données d'entrée RLHF et filtrez le contenu synthétique de vos ensembles de données avec une précision de 99,98 %.
