Indice
- Scheda del modello
- Cosa aspettarsi
- Cosa è migliorato
- Rilevamento dell'humanizer e prompt avversarial
- Rilevamento di brevi post sui social media generati dall'intelligenza artificiale
- Miglioramenti di Claude 4.6
- Cosa ci aspetta
- Matematica, programmazione e scienze generate dall'intelligenza artificiale
- Ulteriore sviluppo degli Humanizer
- Il futuro
Annuncio di Pangram 3.2
Aggiornamento: Pangram 3.3 è ora l'ultima versione disponibile — scopri le novità di Pangram 3.3.
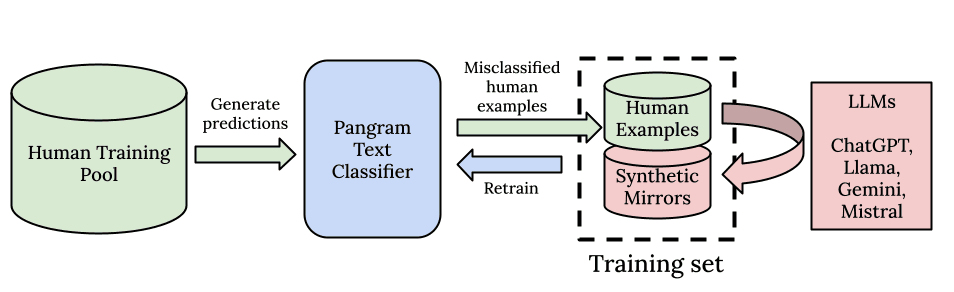
Pangram è lieta di annunciare il lancio di un nuovo modello di rilevamento dell'IA, Pangram 3.2. Come i suoi predecessori, Pangram 3.1 e Pangram 3.0, si basa sull'architettura EditLens descritta nel nostro articolo presentato all'ICLR 2026. Ciò che i nostri utenti possono aspettarsi è un miglioramento incrementale, ma evidente, del numero di veri positivi che il rilevatore è in grado di individuare (il recall), mantenendo lo stesso tasso di falsi positivi, tra i più bassi del settore, garantendo che le false accuse di utilizzo dell'IA rimangano estremamente rare.
Scheda del modello
Seguendo le migliori pratiche relative al rilascio dei modelli di linguaggio di grandi dimensioni (LLM), abbiamo deciso di iniziare a pubblicare le "schede dei modelli" insieme agli aggiornamenti del nostro rilevatore: si tratta, in sostanza, di "etichette nutrizionali" per i modelli di IA. Le nostre schede dei modelli descrivono l'architettura e il framework di addestramento, i dettagli relativi al set di dati di addestramento, i risultati di valutazione rilevanti e le modifiche apportate che potrebbero influire sul comportamento del rilevatore. Descriviamo inoltre le specifiche esatte degli input e degli output del modello, le lingue supportate e le condizioni in cui ci aspettiamo che Pangram funzioni bene e in quali sia più limitato.
Cosa aspettarsi
Probabilmente noterete che Pangram 3.2 è più sensibile rispetto alla versione 3.1. In altre parole, rileverà una maggiore quantità di testi generati dall'IA. Ciò è dovuto ai miglioramenti apportati al rilevamento di Humanizer e di Claude 4.6, alla maggiore sensibilità nel rilevare testi generati dall'IA di lunghezza ridotta, all'aggiunta di ulteriori dati al set di addestramento e all'ottimizzazione degli iperparametri nell'architettura di EditLens.
Cosa è migliorato
Rilevamento dell'humanizer e prompt avversarial
Il miglioramento più significativo apportato a Pangram 3.2 è la sua capacità di individuare testi generati dall'IA ma con un tono umano. Sul nostro set di valutazione interno degli humanizer, abbiamo migliorato il tasso di rilevamento degli humanizer di 4 volte rispetto a Pangram 3.1. Abbiamo inoltre riscontrato un miglioramento di circa 3 volte nella nostra valutazione interna dei "prompt avversariali", ovvero testi generati da un modello linguistico istruito ad aggiungere intenzionalmente errori e a scrivere in uno stile che eluda il rilevamento dell'IA.
Ciò è particolarmente importante nel campo dell'istruzione, dove gli studenti utilizzano sempre più spesso strumenti di "umanizzazione" o cercano di stimolare i modelli linguistici in modo tale da evitare che il testo risultante sembri "troppo generato dall'IA".
Rilevamento di brevi post sui social media generati dall'intelligenza artificiale
Data la grande diffusione del nostro bot su X, che gli utenti hanno utilizzato per verificare la presenza di testi generati dall'intelligenza artificiale nei tweet, negli ultimi tempi ci siamo concentrati intensamente sul miglioramento del rilevamento dei contenuti brevi, della lunghezza di un tweet, presenti online. Abbiamo inoltre ridotto il numero minimo di parole da 75 a 50, poiché riteniamo di aver acquisito maggiore sicurezza nella nostra capacità di distinguere i post generati dall'intelligenza artificiale che contengono tra le 50 e le 75 parole.
A parità di tasso di falsi positivi rispetto a Pangram 3.1, in Pangram 3.2 abbiamo migliorato il tasso di falsi negativi sui brevi post dei social media del 17%.
Miglioramenti di Claude 4.6
Diversi utenti hanno segnalato casi di falsi negativi proprio con Claude Opus 4.6. Abbiamo risolto il problema rigenerando il nostro set di dati includendo i dati relativi a Claude Opus 4.6. Dopo aver effettuato una valutazione sui nostri set di dati di test interni (in particolare sugli esempi più complessi) e aver condotto test di red teaming, siamo ora certi che Pangram sia in grado di rilevare Claude Opus 4.6 così come qualsiasi altro LLM all'avanguardia.
Cosa ci aspetta
Matematica, programmazione e scienze generate dall'intelligenza artificiale
Il codice e i calcoli matematici generati dall'IA non vengono attualmente rilevati con un alto tasso di precisione. Ci stiamo concentrando su questi casi d'uso a causa dell'elevata richiesta da parte dei clienti. Sebbene i calcoli matematici e il codice siano più schematici, e quindi più difficili da rilevare rispetto ai testi generati dall'IA, alcuni dei nostri primi esperimenti stanno dando risultati promettenti.
Ulteriore sviluppo degli Humanizer
Il mercato degli humanizer è in continua evoluzione e negli ultimi mesi è stata lanciata sul mercato una gamma sempre più ampia di questi dispositivi. Stiamo sviluppando tecniche più avanzate per individuarli, che speriamo di poter rendere pubbliche a breve.
Il futuro
Pangram si impegna a rimanere sempre all'avanguardia nel campo del rilevamento tramite intelligenza artificiale. Ci evolviamo costantemente di pari passo con il continuo miglioramento delle capacità dei modelli di linguaggio di grandi dimensioni (LLM).
Stiamo anche assumendo! Dai un'occhiata alla nostra pagina dedicata alle opportunità di lavoro per aiutarci a sviluppare i migliori rilevatori di IA al mondo.

Katherine Thai è la ricercatrice fondatrice specializzata in intelligenza artificiale presso Pangram Labs, una startup che si occupa di rilevamento tramite IA. Ha conseguito il dottorato di ricerca in Informatica sotto la supervisione di Mohit Iyyer presso l’Università del Massachusetts ad Amherst nel dicembre 2025, dove il suo lavoro si è concentrato sulla valutazione dei modelli di linguaggio di grandi dimensioni (LLM) in compiti legati all’analisi letteraria.
Altre letture

Pangram riconosce Llama 4 di Meta?

Qual è il rendimento di Pangram sugli humanizer? (Aggiornato ad agosto 2025)

Guida alla migrazione dell'API Pangram 3.0
Relazione tecnica sul rilevamento di testi generati dall'intelligenza artificiale con elevata precisione

Come individuare l'intelligenza artificiale in Google Docs

L'impegno di Pangram per la protezione dei dati personali
per ricevere i nostri aggiornamenti
